
- masyarakat
- Belajar
- Perpustakaan Alatan
- Masa lapang
Rumah > Soal Jawab > teks badan
Saya mahu menangkap profil rumah secara berasingan dan menyimpannya dalam kamus sebagai lajur bebas, tetapi tiada cara untuk mengekstrak terus elemen sebaris menggunakan gelung for.
Ini kod saya:
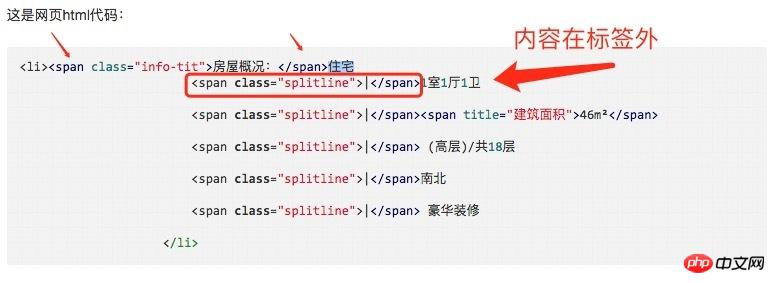
soup.select('.house-info li')[1].text.strip()Ini ialah kod html halaman web:
<li><span class="info-tit">房屋概况:</span>住宅
<span class="splitline">|</span>1室1厅1卫
<span class="splitline">|</span><span title="建筑面积">46m²</span>
<span class="splitline">|</span> (高层)/共18层
<span class="splitline">|</span>南北
<span class="splitline">|</span> 豪华装修
</li>曾经蜡笔没有小新2017-05-18 10:54:42
Sebenarnya, ia sangat mudah. Anda boleh lihat ada corak dalam pemisah |
something = '''<li><span class="info-tit">房屋概况:</span>住宅 <span class="splitline">|</span>1室1厅1卫<span class="splitline">|</span><span title="建筑面积">46m²</span><span class="splitline">|</span> (高层)/共18层
<span class="splitline">|</span>南北
<span class="splitline">|</span> 豪华装修
</li>''';
soup = BeautifulSoup(something, 'lxml')
plaintext = soup.select('li')[0].get_text().strip()Jika anda mempunyai sebarang pertanyaan, sila hubungi.
给我你的怀抱2017-05-18 10:54:42
Gambaran Keseluruhan Rumah:
46m²
滿天的星座2017-05-18 10:54:42
Dalam kes anda, saya fikir ia adalah paling mudah untuk menggunakan gelung for ditambah ungkapan biasa, jika semua templat dibetulkan seperti ini

黄舟2017-05-18 10:54:42
用pyquery吧
daripada pyquery import PyQuery sebagai Q
Q(teks).cari('.info-rumah li').teks()