
- masyarakat
- Belajar
- Perpustakaan Alatan
- Masa lapang
Rumah > Soal Jawab > teks badan
Saya menulis sekeping kod kecil untuk merangkak gambar dalam blog Taman Blog Kod ini berkesan untuk beberapa pautan, tetapi beberapa pautan melaporkan ralat sebaik sahaja ia dirangkak.
#coding=utf-8
import urllib
import re
from lxml import etree
#解析地址
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#获取地址并建树
url = "http://www.cnblogs.com/fnng/archive/2013/05/20/3089816.html"
html = getHtml(url)
html = html.decode("utf-8")
tree = etree.HTML(html)
#保存图片至本地
reg = r'src="(.*?)" alt'
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl, '%s.jpg' % x)
x += 1Seperti yang ditunjukkan dalam gambar, imej boleh dirangkak dengan betul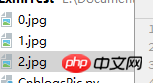
Jika anda menukar url kepada
url = "http://www.cnblogs.com/baronzhang/p/6861258.html"Kemudian ralat akan dilaporkan serta-merta

Sila selesaikan, terima kasih!
我想大声告诉你2017-05-18 10:47:39
Mesej ralat sudah sangat jelas Jika anda melihat pada kod sumber halaman web, imej pertama yang dipadankan adalah dalam format GIF, dan ia masih laluan relatif, jadi anda tidak boleh memuat turunnya, jadi ia menggesa IOerror, walaupun. jika anda telah memuat turunnya, kerana anda menetapkan format sebagai JPG, anda tidak boleh membukanya. Jadi anda hanya perlu menilai dan menapis
for imgurl in imglist:
if "gif" not in imgurl:
urllib.urlretrieve(imgurl, '%s.jpg' % x)
x += 1
Lihat apa yang saya tambah Sudah tentu, ini hanyalah penilaian yang paling mudah, tetapi ia boleh memastikan bahawa program kedua anda tidak akan melaporkan ralat, dan ia juga memberi anda idea!