
Rumah >Peranti teknologi >AI >Aplikasi algoritma dalam pembinaan 58 platform potret
Aplikasi algoritma dalam pembinaan 58 platform potret

- WBOYke hadapan
- 2024-05-09 09:01:10600semak imbas

1. Latar belakang pembinaan platform 58 potret
Pertama sekali, izinkan saya berkongsi dengan anda latar belakang pembinaan platform 58 potret.
1. Platform pemprofilan tradisional
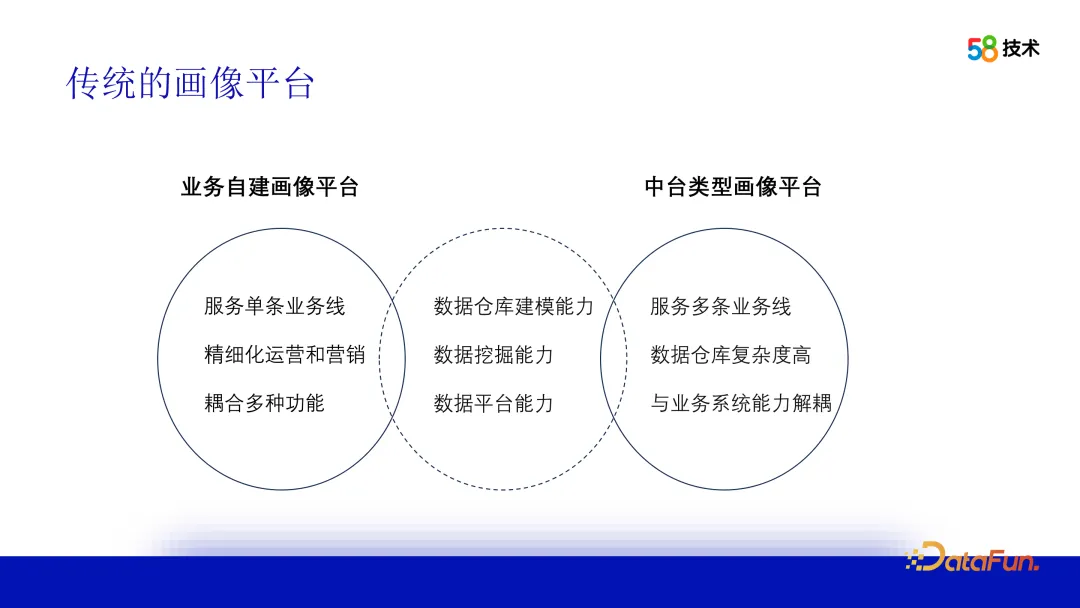
Idea tradisional tidak lagi mencukupi untuk membina platform pemprofilan pengguna bergantung pada keupayaan pemodelan gudang data, menyepadukan data berbilang barisan dan membina data yang tepat juga diperlukan, memahami tingkah laku, minat dan keperluan pengguna, dan menyediakan keupayaan sisi algoritma, akhirnya, ia juga perlu mempunyai keupayaan platform data untuk menyimpan, bertanya dan berkongsi data potret pengguna dengan cekap, dan menyediakan perkhidmatan potret. Perbezaan utama antara platform pemprofilan perniagaan binaan sendiri dan platform pemprofilan pejabat pertengahan ialah platform pemprofilan binaan sendiri menyediakan satu barisan perniagaan dan boleh disesuaikan atas permintaan platform pertengahan pejabat berkhidmat berbilang barisan perniagaan, mempunyai kompleks pemodelan, dan menyediakan lebih banyak keupayaan umum. . beribu-ribu orang berdasarkan potret pengguna Beribu-ribu aspek pengedaran kandungan.
Pengendalian yang diperhalusi: Operasi produk memerlukan platform potret untuk menyediakan fungsi seperti cerapan orang ramai dan pemilihan orang ramai untuk menjalankan aktiviti operasi yang lebih halus untuk kumpulan orang yang berbeza.Pertumbuhan nilai pengguna: Pertumbuhan trafik yang meluas telah berlalu Cara menggunakan platform potret untuk meningkatkan nilai pengguna sedia ada adalah keperluan mendesak.
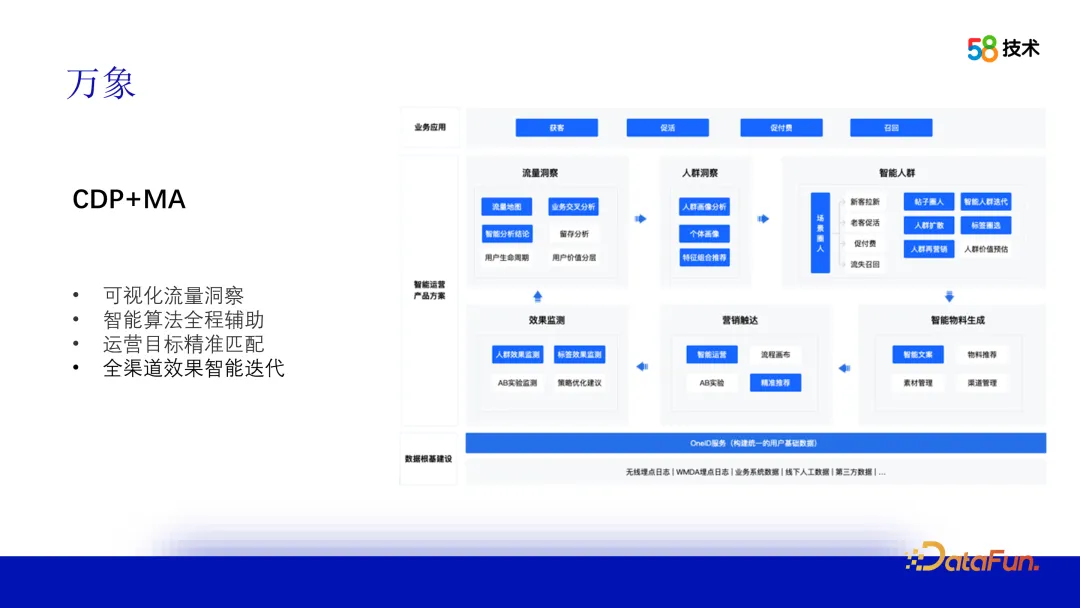
 3. Vientiane
3. Vientiane
- Untuk menyelesaikan keperluan perniagaan semasa dan cabaran persekitaran luaran, kami mencadangkan UA+CDP+MA, satu set penyelesaian platform potret pengguna. Gunakan perkhidmatan OneID untuk membina data potret pengguna asas, menggabungkan trafik dan cerapan orang ramai, menggunakan algoritma untuk menjana orang ramai secara bijak dan memadankan bahan untuk pemasaran yang tepat. Pada masa yang sama, pantau kesan dan kitar semula data untuk mengoptimumkan strategi dan mengulangi orang ramai. Menyediakan penyelesaian pertumbuhan pintar untuk pihak perniagaan untuk mencapai operasi yang tepat dan pertumbuhan perniagaan.
 2. Peranan algoritma dalam pembinaan 58 platform potret
2. Peranan algoritma dalam pembinaan 58 platform potret
Pembinaan bahagian algoritma satu terutamanya dalam 58 aspek pengguna adalah pembinaan dua aspek algoritma. sistem label, Yang lain ialah pembinaan keupayaan platform.
1. Pembinaan sistem tagSistem tag Vientiane merangkumi pelbagai kategori seperti atribut sosial, lokasi geografi, tabiat tingkah laku, atribut keutamaan, stratifikasi pengguna, dll., dengan jumlah lebih daripada 1,500 tag. Kami membahagikannya kepada dua jenis mengikut kaedah pengeluaran:
 Tag fakta: Pelajar Shucang menggunakan statistik atau peraturan untuk membangun dan menghasilkan melalui SQL, dsb.
Tag fakta: Pelajar Shucang menggunakan statistik atau peraturan untuk membangun dan menghasilkan melalui SQL, dsb.
Teg algoritma: Pasukan algoritma memproses dan menghasilkan melalui perlombongan data dan cara lain.
2. Contoh tag algoritma
- Tag algoritma boleh dikelaskan mengikut sumber data dan butiran. Seperti jantina, umur, kecenderungan perniagaan dan label lain, sumber data umumnya adalah data berstruktur, yang sering diproses sebagai tugas klasifikasi, dan model boleh menggunakan XGBoost, DeepFM, dsb. Terdapat juga teg tujuan penyewaan, yang perlu mengenal pasti tujuan pengguna daripada teks siaran yang dilayari pengguna Sumber data jenis teg ini ialah data tidak berstruktur, yang boleh diproses menggunakan klasifikasi teks dan kaedah lain. Dalam teg keutamaan kandungan kami, jika pengguna memilih siaran teratas dalam perniagaan yang berbeza, kami perlu membina proses pengesyoran luar talian untuk menghasilkan teg tersebut.
- 3 Ambil teg keutamaan kandungan sebagai contoh untuk menerangkan proses pelabelan
Ambil teg keutamaan kandungan sebagai contoh Untuk menghasilkan teg ini, proses pengesyoran luar talian perlu diwujudkan. Menghadapi berjuta-juta atau lebih siaran, kami mula-mula menjalankan saringan awal melalui peringkat penarikan semula, menggunakan kaedah popular, peraturan, penapisan kolaboratif dan kaedah lain, seperti rangkaian saraf konvolusi (LightGCN) dan model menara berkembar (DSSM) dalam rajah tersebut. Kemudian, berdasarkan catatan yang ditarik balik, pendekatan Pointwise digunakan untuk mengisih model CTR. Output akhir ialah siaran N Teratas yang paling diminati pengguna. Dalam aplikasi praktikal, mengambil senario tolak sebagai contoh, atribut utama boleh diekstrak daripada siaran 1 Teratas untuk menjana salinan diperibadikan. Pada masa yang sama, halaman pendaratan boleh menjadi halaman butiran siaran 1 Teratas atau halaman senarai siaran N Teratas.

Apabila menghasilkan teg keutamaan kandungan, dengan mengambil kira ciri geografi dan kategori perniagaan tempatan 58, pengguna biasanya hanya berminat dengan siaran dari wilayah atau kategori tertentu dalam pengesyoran. Oleh itu, apabila mengimbas kembali vektor (seperti menggunakan model EGES), mungkin terdapat sejumlah besar siaran luar tapak atau bukan kategori. Untuk menyelesaikan masalah ini, kami mewakili maklumat bandar dalam perenambelasan, gantikan 0 dengan -1, dan kemudian sambung pengekodan ini terus ke dalam vektor yang dijana sebelum ini. Ini boleh memastikan siaran di bandar yang sama atau untuk tujuan yang sama disertakan dalam persamaan pengiraan mempunyai persamaan yang paling besar di antara mereka, sekali gus meningkatkan ketepatan ingatan semula dan pengesyoran.
Dalam peringkat pengisihan, maklumat berbilang modal, termasuk kandungan teks, digunakan untuk meningkatkan ketepatan pengesyoran. Sebagai contoh, tajuk jawatan, sebagai ciri teks, boleh diwakili dengan membenamkan menggunakan model pra-latihan seperti BERT dan M3E. Walau bagaimanapun, ini menimbulkan cabaran kepada sumber pengkomputeran kerana jumlah siaran yang banyak. Untuk menyelesaikan masalah ini, kami menggunakan Spark NLP, perpustakaan pemprosesan bahasa semula jadi berdasarkan Pembelajaran Mesin Apache Spark. Walaupun tiada model BERT Cina dalam perpustakaan asli, melalui beberapa transformasi, kami berjaya menerapkannya pada inferens luar talian berskala besar.
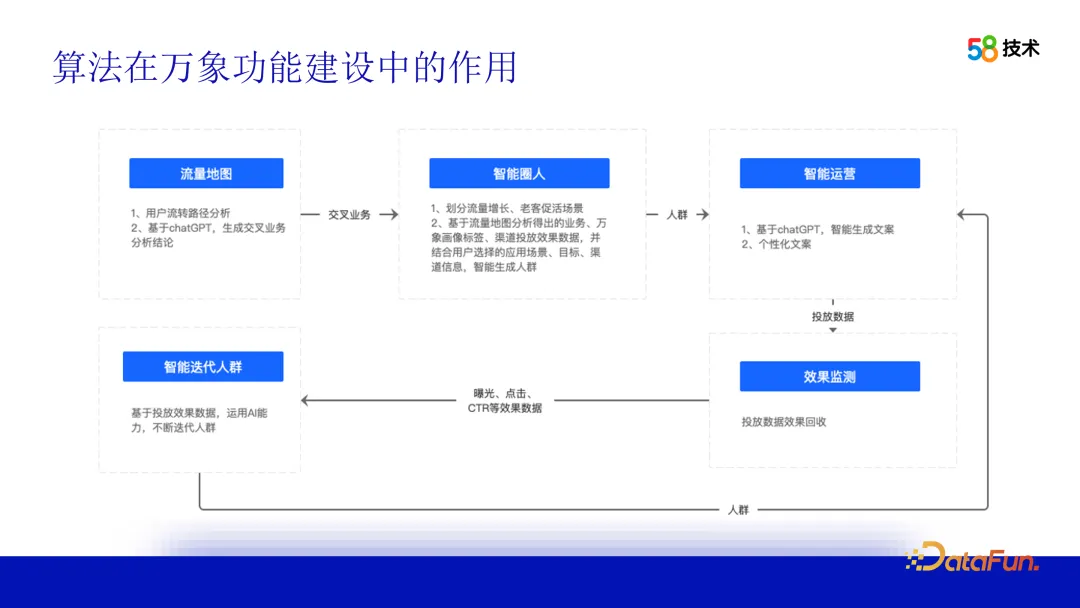
Algoritma juga memainkan peranan teras dalam pembinaan berfungsi platform potret pengguna 58 bandar. Mengambil kebolehan operasi pintar sebagai contoh, kami menggunakan peta trafik untuk mengenal pasti korelasi antara perniagaan yang berbeza dan memberikan cadangan atau kesimpulan operasi untuk pihak perniagaan. Berdasarkan cadangan ini, pihak perniagaan boleh terus menjana pakej orang ramai pengendali melalui fungsi bulatan pintar dan menyambungkannya ke saluran yang sepadan untuk penghantaran. Kesan penghantaran boleh dipantau melalui platform dan dioptimumkan secara berulang berdasarkan data kesan untuk meningkatkan kesan operasi secara berterusan.
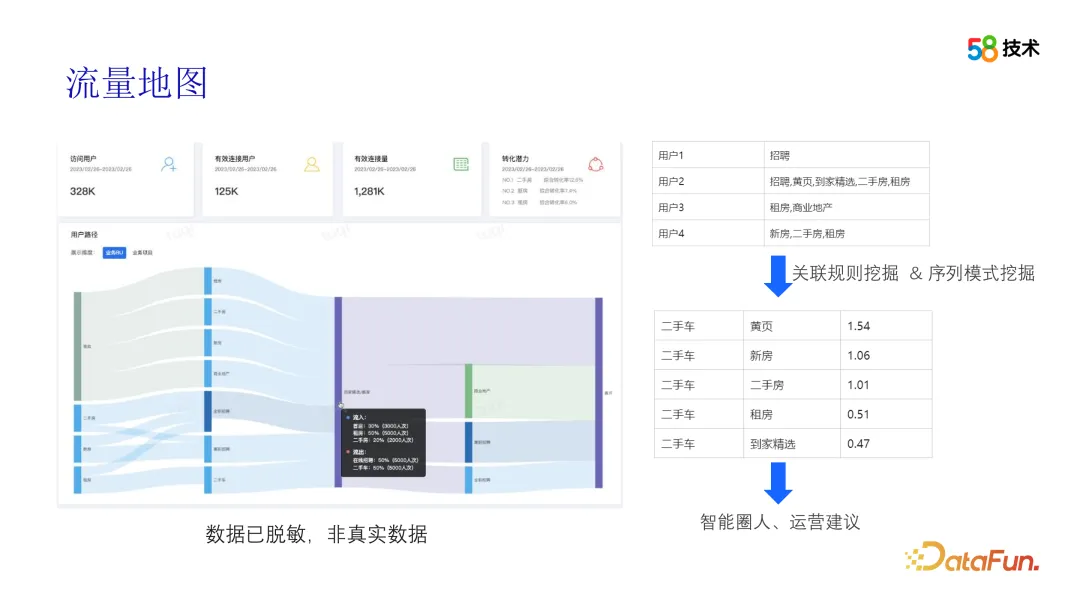
Bagaimana algoritma berfungsi? Seterusnya, kami akan memperkenalkannya dalam beberapa bahagian. Yang pertama ialah peta lalu lintas. Kami menggunakan teknologi perlombongan data dan visualisasi data OLAP untuk menjalankan analisis mendalam tentang gelagat penyemakan imbas pengguna 58APP antara perniagaan yang berbeza. Dengan menganalisis dan memproses data ini, laluan aliran pengguna antara perniagaan yang berbeza boleh dipaparkan, memberikan pasukan operasi pandangan intuitif tentang tingkah laku pengguna. Dalam proses ini, algoritma bukan sahaja boleh membantu kami mengenal pasti corak tingkah laku pengguna, tetapi juga mencungkil korelasi antara perniagaan yang berbeza melalui analisis korelasi dan teknologi lain. Perkaitan ini memberikan kami cadangan operasi yang berharga dan menyokong pasukan operasi dalam operasi silang.
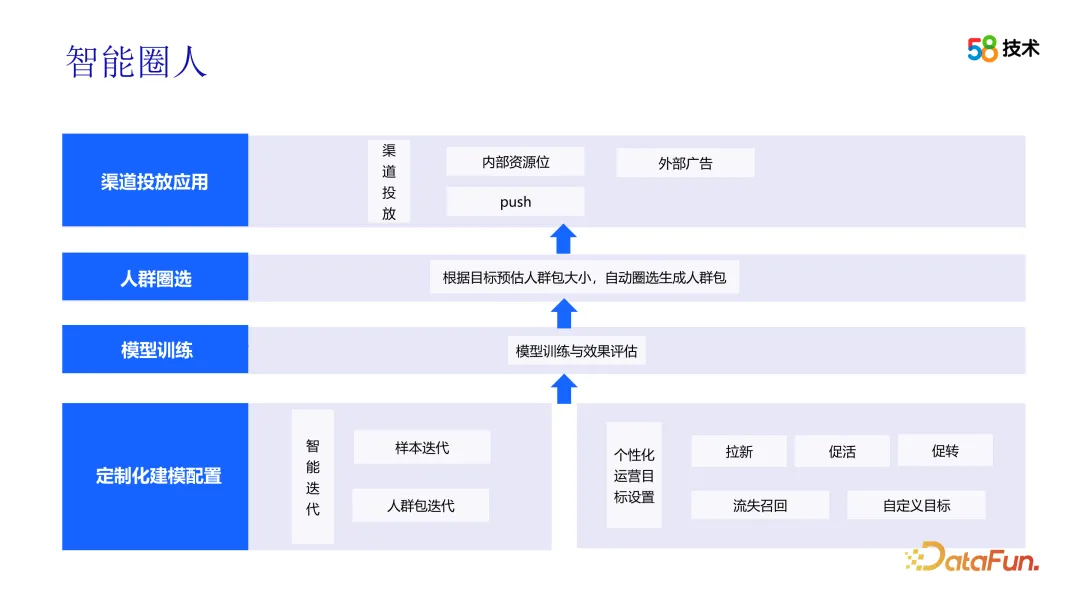
Selepas mendapat cadangan operasi, pasukan operasi boleh menggunakan fungsi bulatan pintar untuk memilih kumpulan sasaran. Untuk mencapai matlamat ini, pasukan operasi perlu terlebih dahulu mengkonfigurasi matlamat operasi yang diperibadikan dan menjelaskan sama ada matlamatnya adalah untuk menarik pelanggan baharu, mempromosikan aktiviti atau mempromosikan penukaran, dsb. Seterusnya, anda perlu menetapkan kesan yang diingini, termasuk saiz pakej orang ramai dan kesan penghantaran yang dijangkakan. Selain itu, pasukan operasi juga perlu memilih saluran penyampaian yang sesuai untuk memastikan kumpulan sasar dapat menerima maklumat aktiviti operasi yang berkaitan.
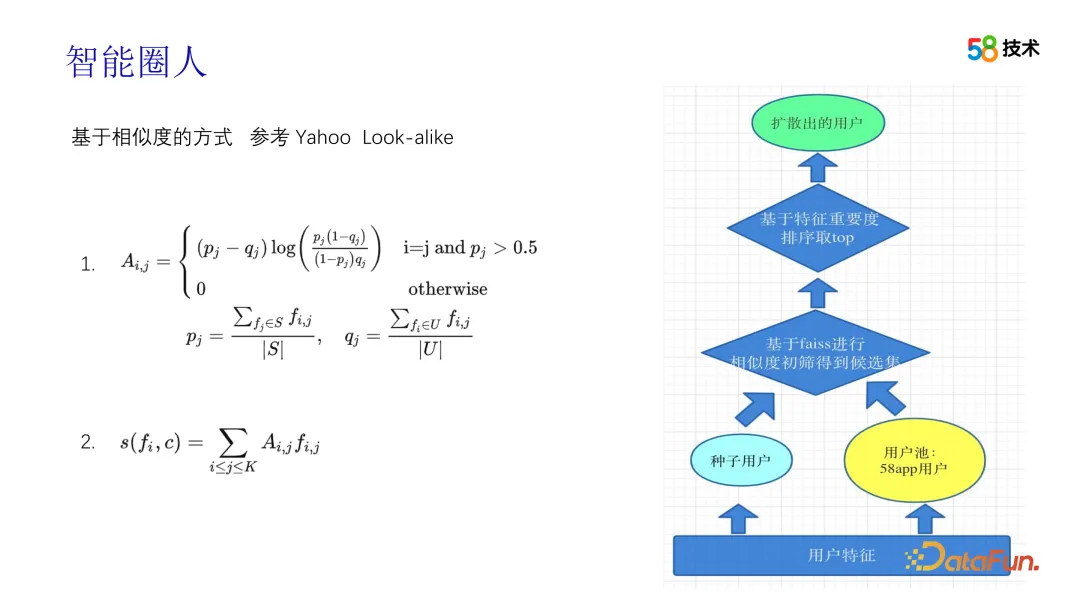
Proses penjanaan pakej orang ramai adalah kotak hitam untuk pasukan operasi. Untuk menangani isu ini, kami menyediakan lebih banyak penjelasan dan penerangan tentang prinsip dan langkah algoritma supaya pasukan operasi dapat memahami dan menggunakan teknologi dengan lebih baik. Pada masa yang sama, kami menyediakan lebih banyak alat dan antara muka visual untuk membantu pasukan operasi melihat dan menganalisis ciri dan kesan paket orang ramai secara intuitif.
Dalam proses menjana paket orang ramai, kami terutamanya menggunakan teknologi Serupa. Kami telah melalui beberapa peringkat dalam evolusi teknologi ini Pada peringkat awal, kami belajar daripada penyelesaian Yahoo dan membahagikan keluaran pakej orang ramai ke dalam modul panggil balik dan pengisihan. Modul penarikan balik mula-mula membina vektor ciri semua pengguna, kemudian menggunakan minHash dan teknologi pencincangan sensitif tempatan untuk memampatkan vektor ciri, dan mencapai perolehan semula yang serupa dengan k-NN melalui kaedah yang serupa dengan pengelompokan dan baldi, dan dengan cepat mengira hubungan antara benih pengguna dan Berdasarkan persamaan berpasangan antara kumpulan calon, topN dipilih sebagai kumpulan panggil balik untuk setiap pengguna benih. Dalam peringkat pengisihan, Nilai Maklumat mula-mula digunakan untuk menapis ciri, kemudian markah dikira berdasarkan ciri yang ditapis, dan akhirnya markah diisih untuk akhirnya menghasilkan pakej orang ramai. Sepanjang proses, algoritma memainkan peranan penting dalam memastikan ketepatan dan keberkesanan pakej orang ramai.
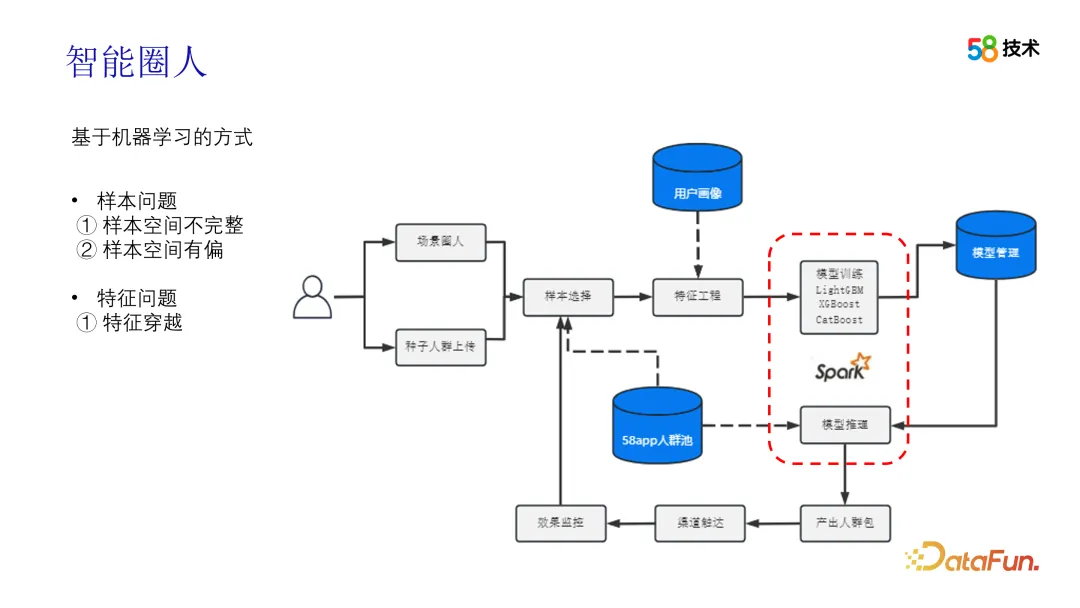
Selain penyelesaian berasaskan persamaan, kaedah berasaskan pembelajaran mesin juga mempunyai hasil yang baik. Dalam aplikasi praktikal, pengguna boleh memulakan permintaan melalui orang bulatan pemandangan atau muat naik orang ramai benih. Perbezaannya ialah sama ada kumpulan benih dimuat naik oleh pengguna atau dilombong secara automatik oleh kami. Selepas mendapat populasi benih, iaitu sampel positif, kita perlu memilih sampel negatif Kita boleh menggunakan pensampelan negatif rawak global yang ganas, atau kita boleh menggunakan algoritma seperti pembelajaran PU atau TSA untuk melengkapkan pemilihan sampel negatif. Seterusnya ialah peringkat pemilihan ciri, yang dibahagikan kepada dua pilihan Salah satunya adalah menyediakan ciri yang dipilih secara manual terlebih dahulu Selepas kejuruteraan ciri tetap, model seperti DeepFM boleh digunakan untuk melengkapkan latihan dan anggaran CTR, dan TopN dipilih sebagai. pakej orang ramai berdasarkan CTR Pilihan lain ialah menggunakan semua teg sebagai ciri, memilih dan menghapuskan ciri secara automatik melalui nilai dan korelasi IV, kemudian gunakan rangka kerja AutoML untuk melengkapkan latihan kejuruteraan dan model ciri, dan akhirnya melakukan inferens pada 58App kumpulan orang ramai dan keluaran berdasarkan pakej TopN Crowd, sambung ke saluran untuk menghubungi, dan akhirnya kumpulkan data kesan penghantaran untuk melengkapkan lelaran pemilihan sampel.
Terdapat beberapa perkara yang patut diberi perhatian dalam skema di atas Yang pertama ialah lelaran sampel Apabila memulihkan data kesan, bukan sahaja data pendedahan perlu disaring, tetapi juga data yang tidak terdedah, iaitu, Bias Pendedahan, perlu. untuk diproses debias. Pada masa yang sama, kesan selepas lelaran perlu dinilai dan disahkan di luar talian untuk memastikan kesan lelaran. Selain itu, masalah traversal juga perlu diambil kira dari segi ciri terutamanya dalam babak baharu yang mana faktor masa pemilihan ciri perlu diambil kira.
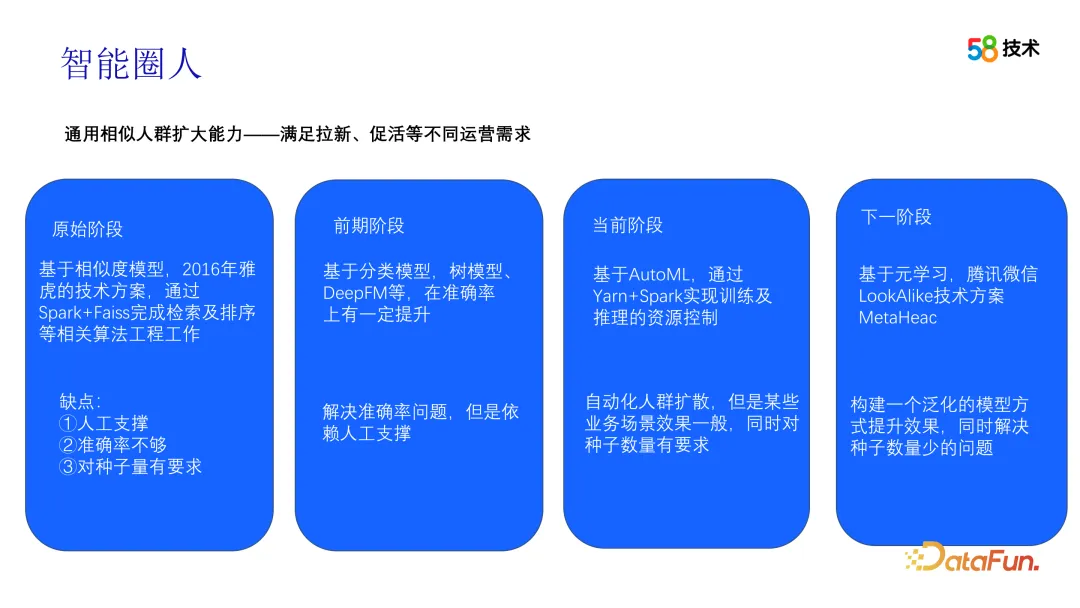
Memandangkan semakin banyak data terkumpul dalam senario operasi, kami mula cuba menggunakan data ini untuk menjalankan percubaan luar talian untuk mengoptimumkan pelan lelaran kami. Salah satunya ialah kaedah Look-alike berdasarkan Tencent WeChat, yang menggunakan kaedah meta-pembelajaran. Secara khususnya, kaedah ini membina model umum, melengkapkan pembinaan model dalam peringkat luar talian, dan kemudian menggunakan sejumlah kecil set data untuk melatih model tersuai dan melaksanakan kerja inferens dalam peringkat dalam talian. Kaedah ini boleh menyelesaikan masalah overfitting model apabila saiz sampel agak kecil. Penyebaran berbilang senario dan berbilang sasaran juga merupakan salah satu arahan lelaran kami yang seterusnya.
3. 58 kes aplikasi platform potret
1. Peletakan sumber diperibadikan
termasuk penempatan tetingkap sumber peribadi dan sepanduk, dll. , semua menggunakan fungsi sepadan platform potret pengguna 58 Contohnya, operasi harga menggunakan keupayaan pemilihan label platform potret untuk menjana pakej orang ramai dan menolak kandungan khusus untuk mereka, melengkapkan pemurnian beribu-ribu orang.
2 Tolakan diperibadikan
Platform potret kami juga disambungkan sepenuhnya dengan platform tolak 58 pelajar boleh membuat kumpulan melalui pemilihan bulatan Vientiane atau Serupa, mengkonfigurasi penulisan salinan yang diperibadikan dan mencapai mereka melalui pengguna push untuk mencapai tujuan operasi. .
3. Pengesyoran carian
Pengesyoran carian ialah aplikasi yang paling biasa berdasarkan potret pengguna. 58 Kedua-dua perniagaan kereta baharu dan kereta terpakai tidak mempunyai kakitangan algoritma, tetapi mereka juga ingin membuat beberapa aplikasi yang diperibadikan, jadi mereka telah menyambungkan teg keutamaan kandungan yang dinyatakan di atas. Teg TopN keutamaan kandungan digunakan dalam kawasan sumber seperti pengesyoran kereta baharu dan pengesyoran berkaitan di halaman utama. Dalam kedudukan carian kereta terpakai, label ini juga digunakan dalam gesaan kotak carian dan siri kereta yang berkaitan pada halaman penemuan carian. Berbanding dengan kaedah penggunaan peraturan sebelum ini, mengakses teg keutamaan kandungan sebagai penyelesaian pada peringkat awal projek juga telah mencapai hasil yang baik.
4. Tinjauan dan Ringkasan
Platform potret semasa 58 sudah mempunyai keupayaan platform potret biasa dalam industri, dan melalui berkat algoritma, ia telah mencapai operasi pintar dan keupayaan lain. Ia bukan sahaja menambah baik kesan operasi bahagian perniagaan, tetapi juga menyediakan pengguna dengan perkhidmatan yang diperibadikan sambil turut membawa pengalaman pengguna yang lebih baik. Seterusnya, kami akan bekerjasama secara mendalam dengan pihak perniagaan untuk meneroka lebih banyak senario aplikasi, meringkaskan dan memperhalusi, mengoptimumkan dan berinovasi semasa proses kerjasama, dan meningkatkan teknologi untuk memenuhi pelbagai keperluan dan cabaran Kami berharap untuk mencipta penyelesaian yang lebih baik untuk pengguna dan perusahaan. Nilai yang hebat.
Atas ialah kandungan terperinci Aplikasi algoritma dalam pembinaan 58 platform potret. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!