
 Peranti teknologiAI7262 kertas telah diserahkan, ICLR 2024 menjadi popular, dan dua kertas domestik telah dicalonkan untuk kertas tertunggak.
Peranti teknologiAI7262 kertas telah diserahkan, ICLR 2024 menjadi popular, dan dua kertas domestik telah dicalonkan untuk kertas tertunggak.
Sebanyak 5 anugerah kertas cemerlang dan 11 sebutan kehormat telah dipilih pada tahun ini.
ICLR bermaksud Persidangan Antarabangsa mengenai Perwakilan Pembelajaran Tahun ini adalah persidangan ke-12, yang diadakan di Vienna, Austria dari 7 hingga 11 Mei.
Dalam komuniti pembelajaran mesin, ICLR ialah persidangan akademik teratas yang agak "muda" Ia dihoskan oleh gergasi pembelajaran mendalam dan pemenang Anugerah Turing Yoshua Bengio dan Yann LeCun Ia baru sahaja mengadakan sesi pertamanya pada tahun 2013. Walau bagaimanapun, ICLR dengan cepat mendapat pengiktirafan luas daripada penyelidik akademik dan dianggap sebagai persidangan akademik teratas mengenai pembelajaran mendalam.
Persidangan ini menerima sejumlah 7262 kertas kerja yang diserahkan, dan menerima 2260 kertas kerja Kadar penerimaan keseluruhan adalah kira-kira 31%, sama seperti tahun lepas (31.8%). Selain itu, bahagian kertas Spotlights ialah 5% dan bahagian kertas Lisan ialah 1.2%. . R Untuk kertas ICLR terdahulu, dalam kertas pemenang anugerah yang diumumkan baru-baru ini, persidangan itu memilih 5 anugerah tesis cemerlang dan 11 anugerah pencalonan kehormat. Anugerah Kertas Cemerlang 5 bersih / pdf?id=ANvmVS2Yr0


Pengarang: Zahra Kadkhodaie, Florentin Guth, Eero P. Simoncelli, Stéphane Mallat
Artikel umum yang diimport
Kertas: Belajar Simulator Dunia Sebenar Interaktif
Alamat kertas: https://openreview.net/forum?id=sFyTZEqmUY
Alamat kertas: https://openreview.net/forum?id=sFyTZEqmUY
, Institusi Google: Deep, Google MIT Universiti Berta 
- Pengarang: Sherry Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Leslie Kaelbling, Dale Schuurmans, Pieter Abbeel
- Mengagregatkan data merentas pelbagai sumber matlamat untuk melatih model asas jangka panjang . Memandangkan robot yang berbeza mempunyai antara muka sensorimotor yang berbeza, ini menimbulkan cabaran yang ketara kepada latihan merentas set data berskala besar. UniSim
- , merupakan langkah penting ke arah ini dan pencapaian kejuruteraan, memanfaatkan antara muka bersatu berdasarkan penerangan teks persepsi visual dan kawalan untuk mengagregat data dan dengan memanfaatkan kemajuan terkini dalam penglihatan dan bahasa yang Dibangunkan untuk melatih simulator robot . Ringkasnya, artikel ini meneroka UniSim, simulator tujuan umum untuk mempelajari interaksi dunia sebenar melalui model generatif, dan mengambil langkah pertama ke arah membina simulator tujuan umum. Sebagai contoh, UniSim boleh mensimulasikan cara manusia dan ejen berinteraksi dengan dunia dengan mensimulasikan arahan peringkat tinggi seperti "buka laci" dan hasil visual arahan peringkat rendah.
Seperti yang ditunjukkan dalam Rajah 3 di bawah, UniSim boleh mensimulasikan satu siri tindakan yang kaya, seperti mencuci tangan, mengambil mangkuk, memotong lobak merah, dan mengeringkan tangan di bahagian atas sebelah kanan Rajah 3 menunjukkan menekan suis yang berbeza; Rajah 3 menunjukkan dua adegan navigasi.

Adegan navigasi di sebelah kanan bawah Rajah 3
 Thesis: Tidak pernah berlatih dari awal: Perbandingan adil model urutan panjang memerlukan data yang didorong oleh Jonathan Berant, Ankit Gupta
Thesis: Tidak pernah berlatih dari awal: Perbandingan adil model urutan panjang memerlukan data yang didorong oleh Jonathan Berant, Ankit Gupta
Makalah ini menyelidiki keupayaan model ruang negeri yang dicadangkan baru-baru ini dan seni bina pengubah untuk memodelkan kebergantungan jujukan jangka panjang. Anehnya, pengarang mendapati bahawa melatih model pengubah dari awal menyebabkan prestasinya dipandang rendah, dan peningkatan prestasi yang ketara boleh dicapai dengan tetapan pra-latihan dan penalaan halus. Makalah ini cemerlang dalam fokusnya pada kesederhanaan dan pandangan sistematik.
Kertas: Penemuan Protein dengan Persampelan Walk-Jump Diskret

Alamat kertas: https://openreview.net/forum?id=zMPHKOmQNb
- Alamat kertas: https://openreview.net/forum?id=zMPHKOmQNb
Pengarang: Nathan C. Frey, Dan Berenberg, Karina Zadorozhny, Joseph Kleinhenz, Julien Lafrance-Vanasse, Isidro Hotzel, Yan Wu, Stephen Ra, Richard Bonneau, Kyunghyun Cho, Andreas Loukas, Vladimir Gligorijevic, Saeed Saremi

- Kertas kerja ini menangani masalah reka bentuk antibodi berasaskan jujukan, aplikasi model penjanaan jujukan protein yang tepat pada masanya dan penting.
Untuk tujuan ini, penulis memperkenalkan kaedah pemodelan baharu yang inovatif dan berkesan yang disasarkan khusus kepada masalah pemprosesan data jujukan protein diskret. Di samping mengesahkan kaedah dalam silico, penulis melakukan eksperimen makmal basah yang meluas untuk mengukur pertalian mengikat antibodi in vitro, menunjukkan keberkesanan kaedah yang dihasilkan mereka.
- Kertas: Vision Transformers Perlu Daftar
Pengarang: Timothée Darce t. Maxime Oquab, Julien Mairal, Piotr Bojanowski

- Kertas ini mengenal pasti artifak dalam peta ciri rangkaian pengubah penglihatan, yang dicirikan oleh token norma tinggi di kawasan latar belakang maklumat rendah.
Pengarang mencadangkan andaian utama tentang bagaimana fenomena ini berlaku dan menyediakan penyelesaian yang ringkas tetapi elegan menggunakan token daftar tambahan untuk menangani kesan ini, dengan itu meningkatkan prestasi model dalam pelbagai tugas. Cerapan yang diperoleh daripada kerja ini juga boleh memberi kesan kepada bidang aplikasi lain.
Kertas kerja ini ditulis dengan cemerlang dan memberikan contoh yang baik dalam menjalankan penyelidikan: "Kenal pasti masalah, fahami mengapa ia berlaku, dan kemudian cadangkan penyelesaian - 11 sebutan yang mulia
Selain 5 kertas kerja yang belum selesai." ICLR 2024 juga memilih 11 sebutan kehormat.
Institusi: University of Montreal, University of Oxford
Pengarang: Edward J Hu, Moksh Jain, Ericness Elmoznind Lajodar, Youness Elmoznino Bendarie , Nikolay Malkin
Alamat kertas: https://openreview.net/forum?id=Ouj6p4ca60
- Makalah ini mencadangkan alternatif kepada penyahkodan autoregresif dalam model bahasa besar dari perspektif pendekatan inferens Bayesian. yang boleh memberi inspirasi kepada penyelidikan susulan.
- Kertas: Mengira Nash Equilibria dalam Permainan Bentuk Normal melalui Pengoptimuman Stokastik
- Institusi: DeepMind
- Pengarang: Ian Gemp, Luke Marris, alamat
Ini adalah kertas bertulis yang sangat jelas yang menyumbang secara signifikan untuk menyelesaikan masalah penting untuk membangunkan penyelesai Nash yang cekap dan berskala.
Institusi: Universiti Peking, Institut Penyelidikan Kecerdasan Buatan Zhiyuan Beijing
-
Pengarang: Ying Wei Gai Wei Heng Heng Qi Wei Heng Qi Weiheng
- Alamat kertas: https://openreview.net/forum?id=HSKaGOi7Ar
- Institusi: Meta
- Pengarang: Ricky T. Q. Chen, Yaron Lipman
- alamat: Tinjauan: Meta
- Kertas: Adakah ImageNet bernilai 1 video? Mempelajari pengekod imej yang kukuh daripada 1 video panjang tanpa label
- Institusi: University of Central Florida, Google DeepMind, University of Amsterdam, dsb. Mamshad Nayeem Rizve, Joao Carreira, Yuki M Asano, Yannis Avrithis
- Alamat kertas: https://openreview.net/forum?id=Yen1lGns2o
- Institusi: City University of Hong Kong, Tencent AI Lab, Xi'an Jiaotong University, dsb.
- Wu, Long-Kai Huang, Renzhen Wang, Deyu Meng, dan Ying Wei
- Institusi: University of Illinois di Urbana-Champaign, Microsoft
- Pengarang: Liyuan Zhang, Liyuan, Liyuan, Liyuan Zhang, Jiawei Han, Jianfeng Gao
- Institusi: Universiti Stanford, Universiti Columbia
- Pengarang: Yonatan Oren, Nicole Meister, Niladri S. Faisunori Ladhakaji, Tadhakhimori S. Alamat kertas: https://openreview.net/forum?id=KS8mIvetg2
- Institusi: Google DeepMind
- Pengarang: Jonathan Richens, Tom Everitt
Kertas: Asas mekanistik pergantungan data dan pembelajaran mendadak dalam tugas pengelasan dalam konteks
- Institusi: Universiti Princeton, Universiti Harvard, dll.
- Pengarang: Gautam Reddy Alamat: Gautam Reddy
- Institusi: Granica Computing
- Pengarang: Germain Kolossov, Andrea Montanari, alamat Pulkit Tandon
Kertas: Beyond Weisfeiler-Lehman: Rangka Kerja Kuantitatif untuk Ekspresi GNN
Kertas: Flow Matching on General Geometries
?alamat TL: https://o.
- Kertas kerja ini meneroka masalah pemodelan generatif yang mencabar tetapi penting pada pancarongga geometri am dan mencadangkan algoritma yang praktikal dan cekap. Kertas ini dibentangkan dengan cemerlang dan disahkan sepenuhnya secara eksperimen pada pelbagai tugas.
Makalah ini mencadangkan kaedah penyeliaan kendiri novel , iaitu dengan latihan daripada Belajar daripada video berterusan. Kertas kerja ini menyumbang kedua-dua jenis data baharu dan kaedah untuk belajar daripada data baharu.
Kertas: Pembelajaran Berterusan Meta Disemak Semula: Secara Tersirat Meningkatkan Penghampiran Hessian Dalam Talian melalui Pengurangan VariansPengarang mencadangkan varians pembelajaran meta-berterusan baharu kaedah pengurangan. Kaedah ini berfungsi dengan baik dan bukan sahaja mempunyai kesan praktikal tetapi juga disokong oleh analisis penyesalan.
- Kertas: Model Memberitahu Anda Perkara yang Perlu Dibuang: Mampatan Cache KV Adaptif untuk LLM
Artikel ini memfokuskan pada masalah mampatan cache KV (masalah ini memberi kesan yang besar kepada Transformer- berasaskan LLM), dengan idea mudah yang mengurangkan memori dan boleh digunakan tanpa penalaan halus atau latihan semula yang mahal. Kaedah ini sangat mudah dan telah terbukti sangat berkesan.
- Kertas: Membuktikan Pencemaran Set Ujian dalam Model Bahasa Black-Box
Kertas ini menggunakan kaedah yang mudah dan elegan untuk menguji sama ada set data pembelajaran yang diselia telah dimasukkan dalam model bahasa besar dalam latihan.
Kertas: Ejen teguh belajar model dunia kausalalamatforum: https://Paperid
pOoKI3ouv1Kertas kerja ini membuat kemajuan besar dalam meletakkan asas teori untuk memahami peranan penaakulan kausal dalam keupayaan ejen untuk membuat generalisasi kepada domain baharu, dengan implikasi untuk pelbagai bidang berkaitan.
Ini adalah kajian yang tepat pada masanya dan sangat sistematik yang meneroka hubungan antara pembelajaran dalam konteks dan pembelajaran dalam berat apabila kita mula memahami fenomena ini.
- Kertas: Ke arah teori statistik pemilihan data di bawah pengawasan yang lemah
Kertas kerja ini mewujudkan asas statistik untuk pemilihan subset data dan mengenal pasti kelemahan kaedah pemilihan data yang popular.
Pautan rujukan: https://blog.iclr.cc/2024/05/06/iclr-2024-outstanding-paper-awards/🎜🎜🎜Atas ialah kandungan terperinci 7262 kertas telah diserahkan, ICLR 2024 menjadi popular, dan dua kertas domestik telah dicalonkan untuk kertas tertunggak.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

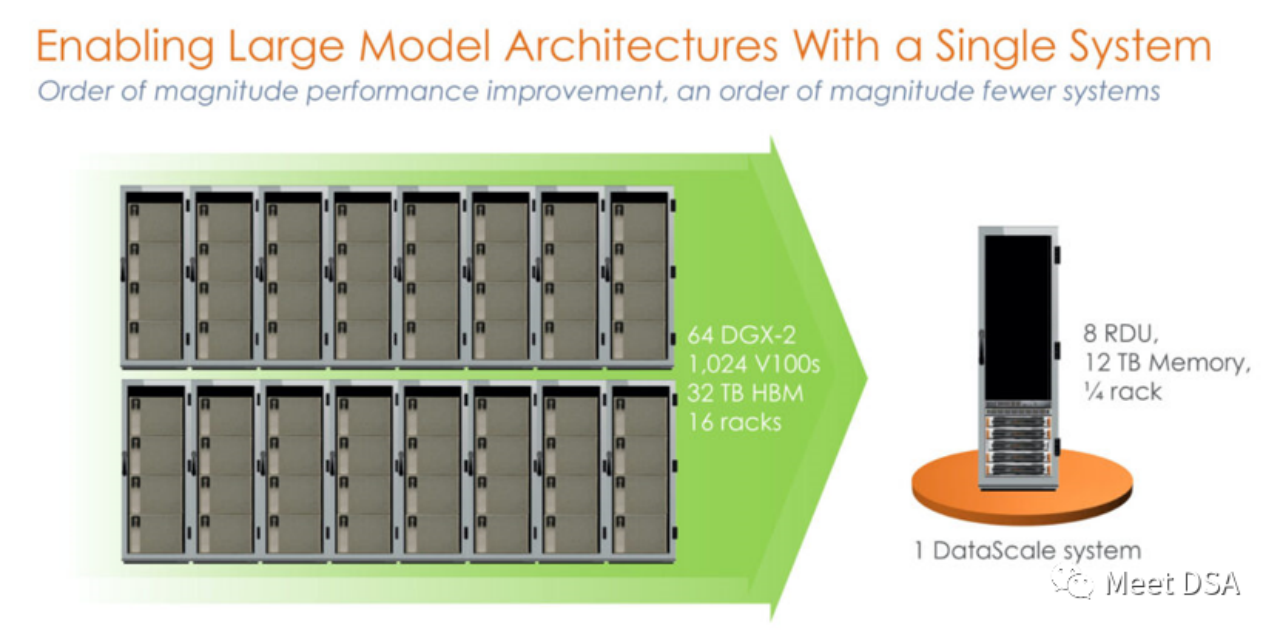 DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM
DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM你可能听过以下犀利的观点:1.跟着NVIDIA的技术路线,可能永远也追不上NVIDIA的脚步。2.DSA或许有机会追赶上NVIDIA,但目前的状况是DSA濒临消亡,看不到任何希望另一方面,我们都知道现在大模型正处于风口位置,业界很多人想做大模型芯片,也有很多人想投大模型芯片。但是,大模型芯片的设计关键在哪,大带宽大内存的重要性好像大家都知道,但做出来的芯片跟NVIDIA相比,又有何不同?带着问题,本文尝试给大家一点启发。纯粹以观点为主的文章往往显得形式主义,我们可以通过一个架构的例子来说明Sam
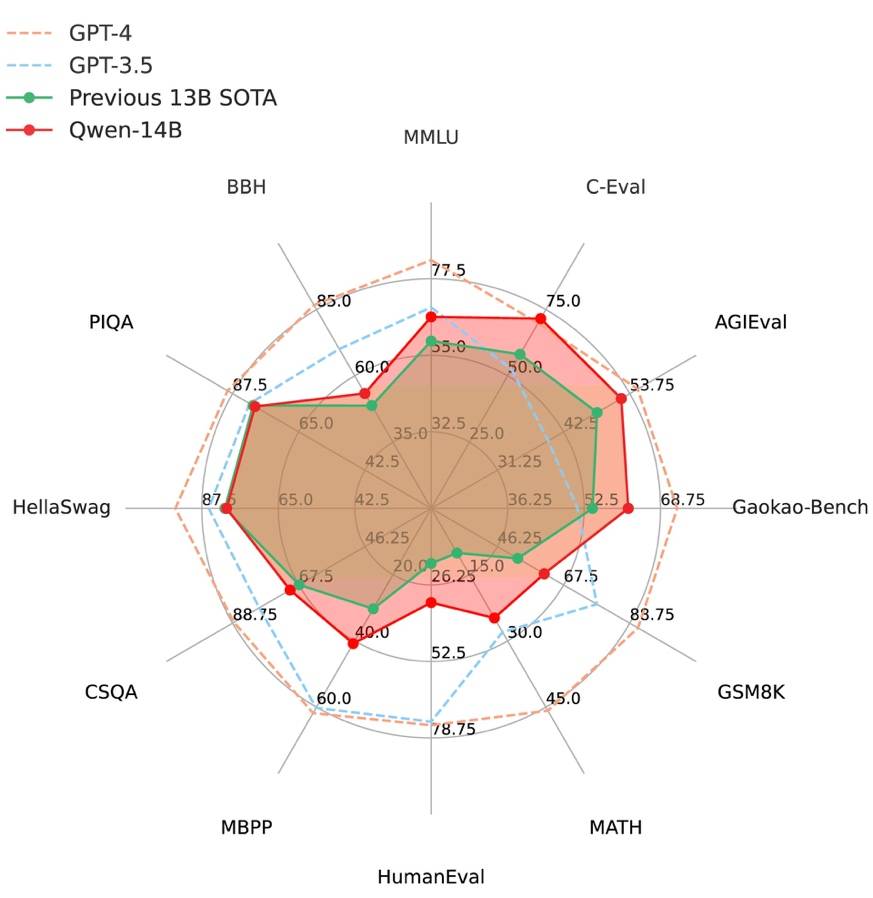 阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM
阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM2021年9月25日,阿里云发布了开源项目通义千问140亿参数模型Qwen-14B以及其对话模型Qwen-14B-Chat,并且可以免费商用。Qwen-14B在多个权威评测中表现出色,超过了同等规模的模型,甚至有些指标接近Llama2-70B。此前,阿里云还开源了70亿参数模型Qwen-7B,仅一个多月的时间下载量就突破了100万,成为开源社区的热门项目Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推
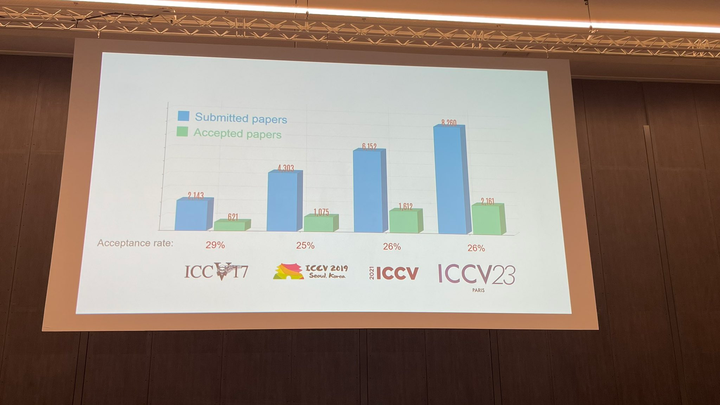 ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM
ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM在法国巴黎举行了国际计算机视觉大会ICCV(InternationalConferenceonComputerVision)本周开幕作为全球计算机视觉领域顶级的学术会议,ICCV每两年召开一次。ICCV的热度一直以来都与CVPR不相上下,屡创新高在今天的开幕式上,ICCV官方公布了今年的论文数据:本届ICCV共有8068篇投稿,其中有2160篇被接收,录用率为26.8%,略高于上一届ICCV2021的录用率25.9%在论文主题方面,官方也公布了相关数据:多视角和传感器的3D技术热度最高在今天的开
 百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM
百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM8月31日,文心一言首次向全社会全面开放。用户可以在应用商店下载“文心一言APP”或登录“文心一言官网”(https://yiyan.baidu.com)进行体验据报道,百度计划推出一系列经过全新重构的AI原生应用,以便让用户充分体验生成式AI的理解、生成、逻辑和记忆等四大核心能力今年3月16日,文心一言开启邀测。作为全球大厂中首个发布的生成式AI产品,文心一言的基础模型文心大模型早在2019年就在国内率先发布,近期升级的文心大模型3.5也持续在十余个国内外权威测评中位居第一。李彦宏表示,当文心
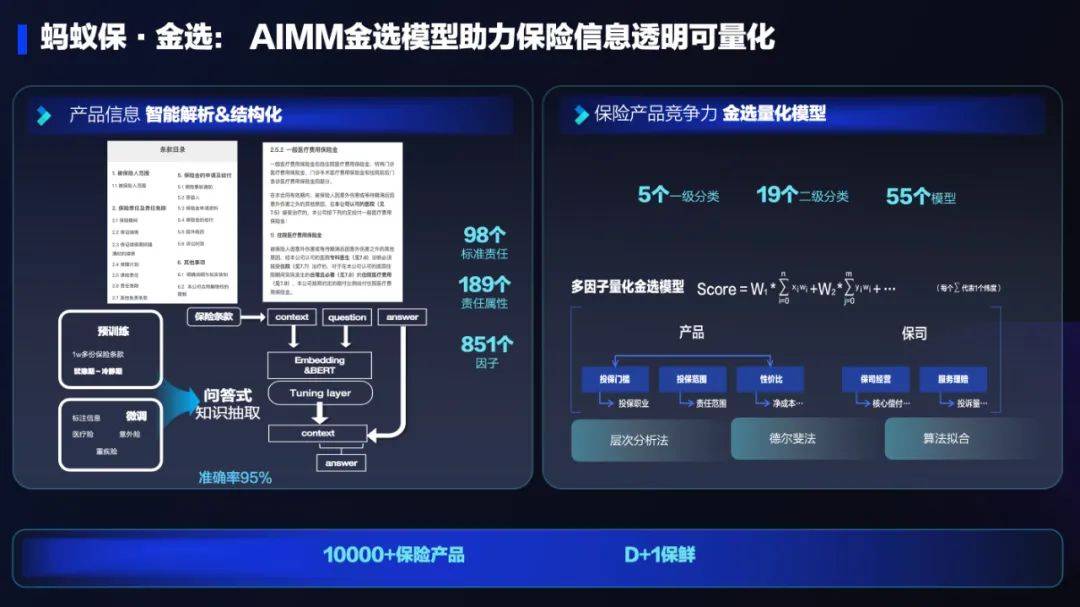 AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM
AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM保险行业对于社会民生和国民经济的重要性不言而喻。作为风险管理工具,保险为人民群众提供保障和福利,推动经济的稳定和可持续发展。在新的时代背景下,保险行业面临着新的机遇和挑战,需要不断创新和转型,以适应社会需求的变化和经济结构的调整近年来,中国的保险科技蓬勃发展。通过创新的商业模式和先进的技术手段,积极推动保险行业实现数字化和智能化转型。保险科技的目标是提升保险服务的便利性、个性化和智能化水平,以前所未有的速度改变传统保险业的面貌。这一发展趋势为保险行业注入了新的活力,使保险产品更贴近人民群众的实际
 复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM
复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM随着智慧司法的兴起,智能化方法驱动的智能法律系统有望惠及不同群体。例如,为法律专业人员减轻文书工作,为普通民众提供法律咨询服务,为法学学生提供学习和考试辅导。由于法律知识的独特性和司法任务的多样性,此前的智慧司法研究方面主要着眼于为特定任务设计自动化算法,难以满足对司法领域提供支撑性服务的需求,离应用落地有不小的距离。而大型语言模型(LLMs)在不同的传统任务上展示出强大的能力,为智能法律系统的进一步发展带来希望。近日,复旦大学数据智能与社会计算实验室(FudanDISC)发布大语言模型驱动的中
 致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM
致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM不得不说,Llama2的「二创」项目越来越硬核、有趣了。自Meta发布开源大模型Llama2以来,围绕着该模型的「二创」项目便多了起来。此前7月,特斯拉前AI总监、重回OpenAI的AndrejKarpathy利用周末时间,做了一个关于Llama2的有趣项目llama2.c,让用户在PyTorch中训练一个babyLlama2模型,然后使用近500行纯C、无任何依赖性的文件进行推理。今天,在Karpathyllama2.c项目的基础上,又有开发者创建了一个启动Llama2的演示操作系统,以及一个
 快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM
快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM杭州第19届亚运会不仅是国际顶级体育盛会,更是一场精彩绝伦的中国科技盛宴。本届亚运会中,快手StreamLake与杭州电信深度合作,联合打造智慧观赛新体验,在击剑赛事的转播中,全面应用了快手StreamLake六自由度技术,其中“子弹时间”也是首次应用于击剑项目国际顶级赛事。中国电信杭州分公司智能亚运专班组长芮杰表示,依托快手StreamLake自研的4K3D虚拟运镜视频技术和中国电信5G/全光网,通过赛场内部署的4K专业摄像机阵列实时采集的高清竞赛视频,


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

Dreamweaver CS6
Alat pembangunan web visual

