
Rumah >Peranti teknologi >AI >LeCun dimajukan, AI membenarkan orang aphasic bercakap semula! NYU mengeluarkan penyahkod 'neural-speech' baharu
LeCun dimajukan, AI membenarkan orang aphasic bercakap semula! NYU mengeluarkan penyahkod 'neural-speech' baharu

- 王林ke hadapan
- 2024-05-07 18:07:16741semak imbas
Pembangunan antara muka otak-komputer (BCI) dalam bidang penyelidikan dan aplikasi saintifik baru-baru ini mendapat perhatian meluas Orang ramai secara amnya ingin tahu tentang prospek permohonan BCI.
Aphasia yang disebabkan oleh kecacatan pada sistem saraf bukan sahaja sangat menghalang kehidupan harian pesakit, malah mungkin mengehadkan perkembangan kerjaya dan aktiviti sosial mereka. Dengan perkembangan pesat pembelajaran mendalam dan teknologi antara muka otak-komputer, sains moden bergerak ke arah membantu orang aphasic untuk mendapatkan semula kebolehan komunikasi melalui prostesis suara saraf.
Otak manusia telah membuat satu siri perkembangan yang menarik, dan terdapat banyak kejayaan dalam penyahkodan isyarat dalam pertuturan, operasi, dsb. Perlu dinyatakan secara khusus bahawa syarikat Neuralink Elon Musk juga telah membuat kemajuan terobosan dalam bidang ini, dengan perkembangan teknologi antara muka otak mereka yang mengganggu.
Syarikat itu berjaya menanam elektrod dalam otak subjek ujian, membolehkan menaip, permainan dan fungsi lain melalui operasi kursor yang mudah. Ini menandakan satu lagi langkah ke arah penyahkodan neuro-pertuturan/motor yang lebih kompleks. Berbanding dengan teknologi antara muka otak-komputer yang lain, penyahkodan neuro-pertuturan adalah lebih kompleks, dan kerja penyelidikan dan pembangunannya bergantung terutamanya pada sumber data khas-elektrokortikogram (ECoG).
Di atas katil, saya terutamanya menjaga data carta elektrodermal yang diterima semasa proses pemulihan pesakit. Para penyelidik menggunakan elektrod ini untuk mengumpul data mengenai aktiviti otak semasa penyuaraan. Data ini bukan sahaja mempunyai resolusi temporal dan spatial yang tinggi, tetapi juga telah mencapai hasil yang luar biasa dalam penyelidikan penyahkodan pertuturan, yang sangat menggalakkan pembangunan teknologi antara muka otak-komputer. Dengan bantuan teknologi canggih ini, kami dijangka melihat lebih ramai orang yang mengalami gangguan saraf mendapat semula kebebasan untuk berkomunikasi pada masa hadapan.
Satu kejayaan dicapai dalam kajian baru-baru ini yang diterbitkan dalam Nature, yang menggunakan ciri HuBERT terkuantisasi sebagai perwakilan perantaraan pada pesakit dengan peranti implan, digabungkan dengan pensintesis pertuturan yang telah terlatih untuk menukar Ciri ini ditukar kepada pertuturan kaedah bukan sahaja meningkatkan semula jadi pertuturan, tetapi juga mengekalkan ketepatan yang tinggi.
Walau bagaimanapun, ciri HuBERT tidak dapat menangkap ciri akustik unik pembesar suara, dan bunyi yang dihasilkan biasanya merupakan suara pembesar suara bersatu, jadi model tambahan masih diperlukan untuk menukar bunyi universal ini kepada suara pesakit tertentu.
Satu lagi perkara yang perlu diberi perhatian ialah kajian ini dan kebanyakan percubaan terdahulu menggunakan seni bina bukan sebab, yang mungkin mengehadkan penggunaan praktikalnya dalam aplikasi antara muka komputer otak yang memerlukan operasi sebab.
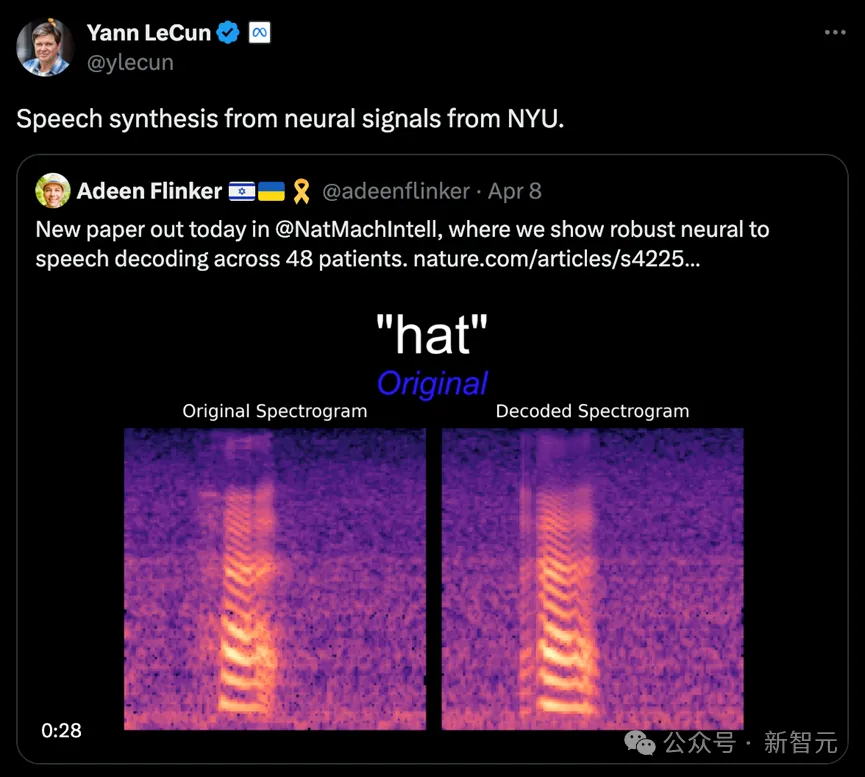
Pada 8 April 2024, New York University VideoLab dan Flinker Lab bersama-sama menerbitkan penyelidikan terobosan dalam majalah "Nature Machine Intelligence".
 Gambar
Gambar
Pautan kertas: https://www.nature.com/articles/s42256-024-00824-8
Penyelidikan kod berkaitan sumber terbuka di https://github.com. neural_speech_decoding
Lagi contoh pertuturan yang dijana di: https://xc1490.github.io/nsd/
Penyelidikan ini, bertajuk "Rangka kerja penyahkodan pertuturan saraf yang memanfaatkan pembelajaran mendalam dan sintesis pertuturan", memperkenalkan sintesis pertuturan yang boleh diubah. .
Pensintesis ini menggabungkan rangkaian saraf konvolusi ringan untuk mengekodkan pertuturan ke dalam satu siri parameter pertuturan yang boleh ditafsir, seperti pic, kenyaringan dan frekuensi forman, dan mensintesis semula pertuturan menggunakan teknik yang boleh dibezakan.
Kajian ini berjaya membina sistem penyahkodan pertuturan saraf yang sangat boleh ditafsir dan boleh digunakan pada set data kecil dengan memetakan isyarat saraf kepada parameter pertuturan khusus ini. Sistem ini bukan sahaja boleh membina semula pertuturan yang berkesetiaan tinggi dan bunyi semula jadi, tetapi juga menyediakan asas empirikal untuk ketepatan tinggi dalam aplikasi antara muka otak-komputer masa hadapan.
Pasukan penyelidik mengumpul data daripada sejumlah 48 subjek dan mencuba penyahkodan pertuturan atas dasar ini, meletakkan asas yang kukuh untuk aplikasi praktikal dan pembangunan teknologi antara muka otak-komputer berketepatan tinggi.
Pemenang Anugerah Turing Lecun turut memajukan kemajuan penyelidikan.
 Gambar
Gambar
Status penyelidikan
Dalam penyelidikan semasa tentang isyarat saraf kepada penyahkodan pertuturan, terdapat dua cabaran teras.
Yang pertama ialah had volum data: untuk melatih model penyahkodan neural-ke-pertuturan yang diperibadikan, jumlah masa data yang tersedia untuk setiap pesakit biasanya hanya kira-kira sepuluh minit, yang sangat terhad untuk model pembelajaran mendalam yang bergantung pada sejumlah besar data latihan.
Kedua, kepelbagaian pertuturan manusia yang tinggi juga meningkatkan kerumitan pemodelan. Walaupun orang yang sama menyebut dan mengeja perkataan yang sama berulang kali, faktor seperti kelajuan pertuturannya, intonasi dan pic mungkin berubah, yang menambahkan kesukaran tambahan kepada pembinaan model.
Dalam percubaan awal, penyelidik terutamanya menggunakan model linear untuk menyahkod isyarat saraf kepada pertuturan. Model jenis ini tidak memerlukan sokongan set data yang besar dan mempunyai kebolehtafsiran yang kuat, tetapi ketepatannya biasanya rendah.
Baru-baru ini, dengan kemajuan teknologi pembelajaran mendalam, terutamanya aplikasi rangkaian neural konvolusi (CNN) dan rangkaian neural berulang (RNN), penyelidik telah mencapai kemajuan dalam mensimulasikan perwakilan terpendam perantaraan pertuturan dan meningkatkan kualiti yang disintesis. pertuturan.
Sebagai contoh, beberapa kajian menyahkod aktiviti korteks serebrum ke dalam pergerakan mulut dan kemudian menukarnya kepada pertuturan Walaupun kaedah ini lebih berkuasa dalam prestasi penyahkodan, suara yang dibina semula selalunya tidak terdengar cukup semula jadi.
Selain itu, beberapa kaedah baharu cuba menggunakan vocoder Wavenet dan rangkaian adversarial generatif (GAN) untuk membina semula pertuturan bunyi semula jadi Walaupun kaedah ini boleh meningkatkan keaslian bunyi, ia masih terhad dalam ketepatan.
Rangka Kerja Model Utama
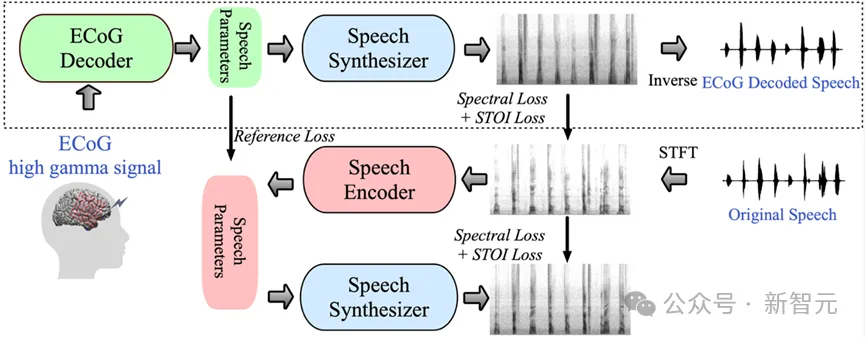
Dalam kajian ini, pasukan penyelidik menunjukkan rangka kerja penyahkodan yang inovatif daripada isyarat electroencephalogram (ECoG) kepada pertuturan. Mereka membina ruang perwakilan terpendam berdimensi rendah yang dijana oleh model pengekodan dan penyahkodan pertuturan ringan menggunakan isyarat pertuturan sahaja.
Rangka kerja ini mengandungi dua bahagian teras: pertama, penyahkod ECoG, yang bertanggungjawab untuk menukar isyarat ECoG kepada satu siri parameter pertuturan akustik yang boleh difahami, seperti pic, sama ada ia disebut, kenyaringan dan frekuensi forman, dsb. ; kedua, ialah bahagian pensintesis pertuturan yang bertanggungjawab untuk menukar parameter ini kepada spektrogram.
Dengan membina pensintesis pertuturan yang boleh dibezakan, para penyelidik dapat melatih penyahkod ECoG sambil turut mengoptimumkan pensintesis pertuturan untuk bersama-sama mengurangkan ralat dalam pembinaan semula spektrogram. Kebolehtafsiran yang kukuh bagi ruang terpendam berdimensi rendah ini, digabungkan dengan parameter pertuturan rujukan yang dijana oleh pengekod pertuturan pra-terlatih ringan, menjadikan keseluruhan rangka kerja penyahkodan pertuturan saraf cekap dan boleh disesuaikan, menyelesaikan masalah kekurangan data dalam bidang ini dengan berkesan.
Selain itu, rangka kerja ini bukan sahaja boleh menjana pertuturan semula jadi yang sangat dekat dengan pembesar suara, tetapi juga menyokong pemasukan berbilang seni bina model pembelajaran mendalam dalam bahagian penyahkod ECoG dan boleh melakukan operasi sebab akibat.
Pasukan penyelidik memproses data ECoG bagi 48 pesakit neurosurgeri dan menggunakan pelbagai seni bina pembelajaran mendalam (termasuk konvolusi, rangkaian saraf berulang dan Transformer) untuk mencapai penyahkodan ECoG.
Model ini telah menunjukkan ketepatan yang tinggi dalam eksperimen, terutamanya yang menggunakan seni bina konvolusi ResNet. Rangka kerja penyelidikan ini bukan sahaja mencapai ketepatan yang tinggi melalui operasi sebab dan kadar pensampelan yang agak rendah (selang 10mm), tetapi juga menunjukkan keupayaan untuk menyahkod pertuturan secara berkesan dari kedua-dua hemisfera kiri dan kanan otak, dengan itu memperluaskan skop aplikasi saraf. penyahkodan pertuturan Ke bahagian kanan otak.
 Gambar
Gambar
Salah satu inovasi teras penyelidikan ini ialah pembangunan pensintesis pertuturan yang boleh dibezakan, yang sangat meningkatkan kecekapan sintesis semula pertuturan dan boleh mensintesis audio yang hampir kepada ketepatan tinggi. bunyi .
Reka bentuk pensintesis pertuturan ini diilhamkan oleh sistem vokal manusia dan membahagikan pertuturan kepada dua bahagian: Suara (terutamanya digunakan untuk simulasi vokal) dan Unvoice (terutamanya digunakan untuk simulasi konsonan).
Di bahagian Suara, isyarat frekuensi asas mula-mula digunakan untuk menjana harmonik, dan kemudian melalui penapis yang terdiri daripada pembentuk F1 hingga F6 untuk mendapatkan ciri spektrum vokal.
Untuk bahagian Unvoice, spektrum yang sepadan dijana dengan melakukan penapisan khusus pada hingar putih. Parameter yang boleh dipelajari mengawal nisbah pencampuran dua bahagian pada setiap titik masa.
Akhir sekali, spektrum pertuturan akhir dijana dengan melaraskan isyarat kelantangan dan menambah hingar latar.
Berdasarkan pensintesis pertuturan ini, pasukan penyelidik mereka bentuk rangka kerja sintesis semula pertuturan dan rangka kerja penyahkodan pertuturan saraf yang cekap. Untuk struktur bingkai terperinci, sila rujuk Rajah 6 artikel asal.
Hasil penyelidikan
1. Hasil penyahkodan pertuturan dengan sebab-akibat temporal
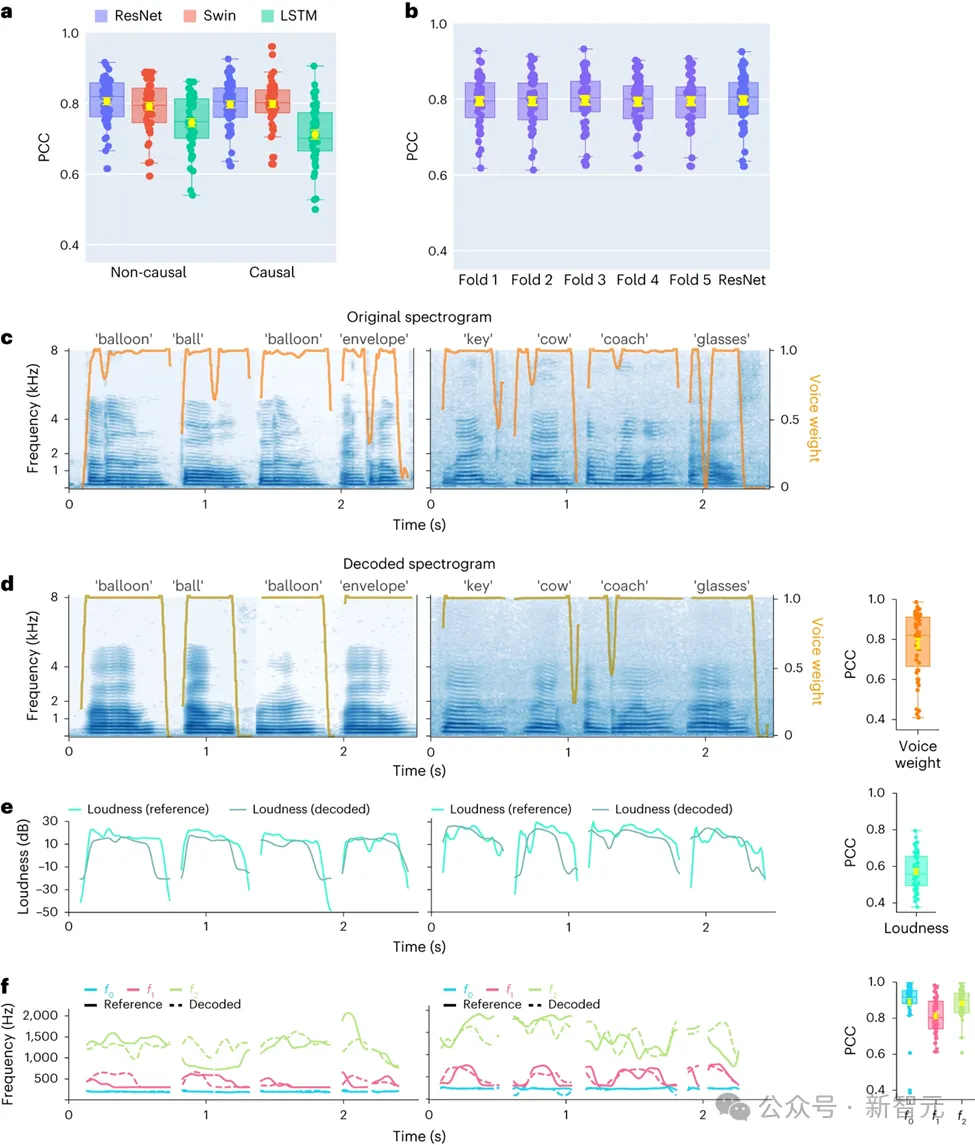
Dalam kajian ini, para penyelidik terlebih dahulu membandingkan secara langsung seni bina model yang berbeza, termasuk rangkaian konvolusi (ResNet), rangkaian Neural berulang (LSTM) dan rangkaian Neural berulang (LSTM) 3D Swin) untuk menilai perbezaan mereka dalam prestasi penyahkodan pertuturan.
Perlu diperhatikan bahawa model ini boleh melakukan operasi sebab atau sebab pada siri masa.
 Gambar
Gambar
Dalam aplikasi antara muka otak-komputer (BCI), sebab-musabab model penyahkodan adalah sangat penting: model kausal hanya menggunakan isyarat saraf masa lalu dan semasa dan untuk menjana pertuturan, kesan Model ini juga merujuk isyarat saraf masa depan, yang tidak boleh dilaksanakan dalam amalan.
Oleh itu, fokus kajian adalah untuk membandingkan prestasi model yang sama semasa melakukan operasi sebab dan bukan sebab. Keputusan menunjukkan bahawa walaupun versi kausal model ResNet mempunyai prestasi yang setanding dengan versi bukan kausal, tanpa perbezaan prestasi yang ketara antara kedua-duanya.
Begitu juga, versi kausal dan bukan kausal model Swin mempunyai prestasi yang sama, tetapi versi kausal LSTM berprestasi jauh lebih rendah daripada versi bukan kausalnya. Kajian ini juga menunjukkan purata ketepatan penyahkodan (jumlah bilangan 48 sampel) untuk beberapa parameter pertuturan utama, termasuk berat bunyi (parameter yang membezakan vokal daripada konsonan), kenyaringan, frekuensi asas f0, forman pertama f1 dan Forman kedua f2.
Membina semula parameter pertuturan ini dengan tepat, terutamanya kekerapan asas, berat bunyi dan dua pembentuk pertama, adalah penting untuk mencapai penyahkodan pertuturan yang tepat dan pembiakan semula jadi suara peserta.
Hasil penyelidikan menunjukkan bahawa kedua-dua model bukan sebab dan sebab boleh memberikan kesan penyahkodan yang munasabah, yang memberikan inspirasi positif untuk penyelidikan dan aplikasi berkaitan masa hadapan.
2. Penyelidikan mengenai penyahkodan pertuturan dan kadar pensampelan ruang bagi isyarat saraf otak kiri dan kanan
Dalam kajian terbaru, penyelidik meneroka lagi perbezaan prestasi dalam penyahkodan pertuturan antara hemisfera otak kiri dan kanan.
Secara tradisinya, kebanyakan penyelidikan tertumpu pada hemisfera kiri, yang berkait rapat dengan fungsi pertuturan dan bahasa.
 Gambar
Gambar
Walau bagaimanapun, pemahaman kita tentang keupayaan hemisfera otak kanan untuk menyahkod maklumat lisan adalah terhad. Untuk meneroka bidang ini, pasukan penyelidik membandingkan prestasi penyahkodan hemisfera kiri dan kanan peserta, mengesahkan kebolehlaksanaan menggunakan hemisfera kanan untuk pemulihan pertuturan.
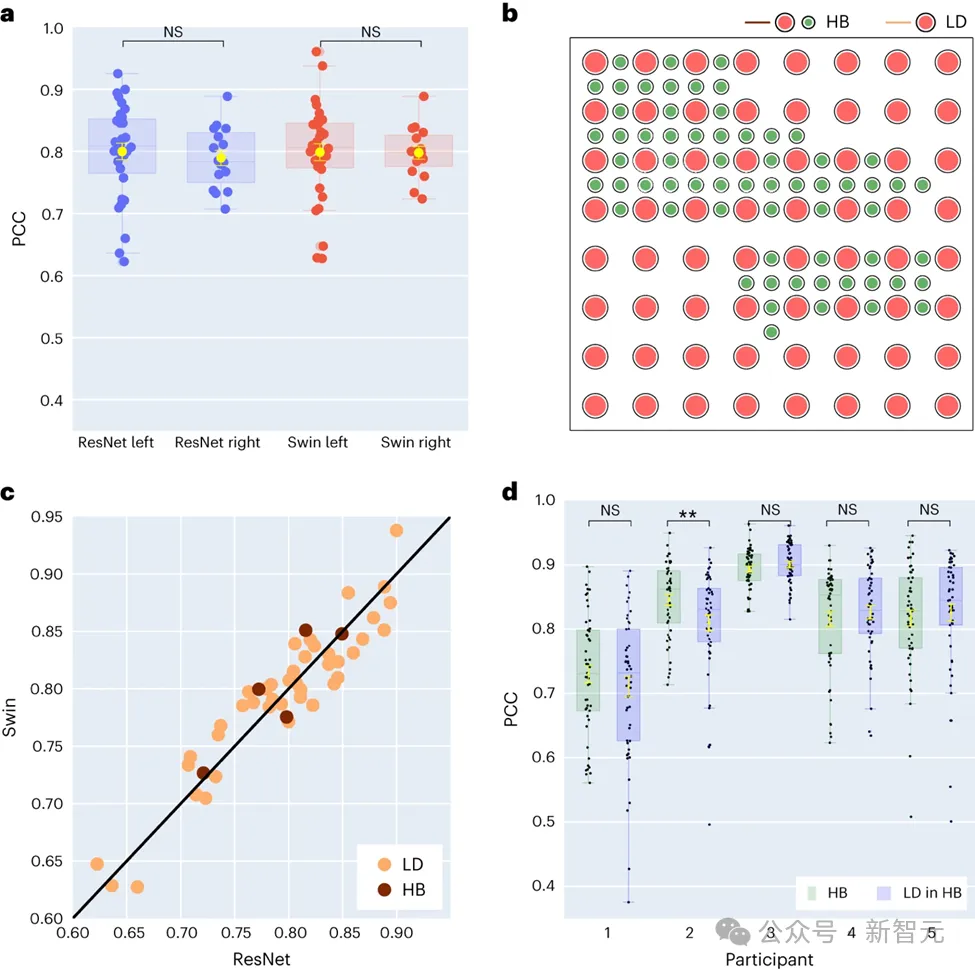
Di antara 48 subjek yang dikumpul dalam kajian, 16 mempunyai isyarat ECoG dari otak kanan. Dengan membandingkan prestasi penyahkod ResNet dan Swin, penyelidik mendapati bahawa hemisfera kanan juga boleh menyahkod pertuturan dengan berkesan, dan kesannya serupa dengan hemisfera kiri. Penemuan ini menyediakan pilihan pemulihan bahasa yang mungkin untuk pesakit yang mengalami kerosakan pada bahagian kiri otak yang telah kehilangan fungsi bahasa.
Penyelidikan ini juga melibatkan kesan ketumpatan pensampelan elektrod pada kesan penyahkodan pertuturan. Kajian terdahulu kebanyakannya menggunakan grid elektrod berketumpatan tinggi (0.4 mm), manakala ketumpatan grid elektrod yang biasa digunakan dalam amalan klinikal adalah lebih rendah (1 cm).
Lima peserta dalam kajian ini menggunakan grid elektrod jenis hibrid (HB), yang kebanyakannya berketumpatan rendah tetapi dengan beberapa elektrod tambahan ditambah. Persampelan berketumpatan rendah digunakan untuk baki empat puluh tiga peserta.
Hasilnya menunjukkan bahawa prestasi penyahkodan pensampelan hibrid (HB) ini adalah serupa dengan pensampelan berketumpatan rendah (LD) tradisional, menunjukkan bahawa model boleh mempelajari maklumat pertuturan secara berkesan daripada ketumpatan grid elektrod korteks serebrum yang berbeza. Penemuan ini menunjukkan bahawa ketumpatan pensampelan elektrod yang biasa digunakan dalam tetapan klinikal mungkin mencukupi untuk menyokong aplikasi antara muka otak-komputer masa hadapan.
3 Penyelidikan tentang sumbangan kawasan otak yang berbeza di otak kiri dan kanan kepada penyahkodan pertuturan
Penyelidik juga meneroka peranan kawasan berkaitan pertuturan dalam otak dalam proses penyahkodan pertuturan, yang mungkin mempunyai implikasi. untuk otak kiri dan kanan pada masa hadapan Implan hemisfera peranti pemulihan pertuturan adalah sangat penting. Untuk menilai kesan kawasan otak yang berbeza pada penyahkodan pertuturan, pasukan penyelidik menggunakan analisis oklusi.
Dengan membandingkan model kausal dan bukan sebab bagi penyahkod ResNet dan Swin, kajian mendapati bahawa dalam model bukan sebab, peranan korteks pendengaran adalah lebih penting. Keputusan ini menyerlahkan keperluan untuk menggunakan model kausal dalam aplikasi penyahkodan pertuturan masa nyata yang tidak boleh bergantung pada isyarat neurofeedback masa hadapan.
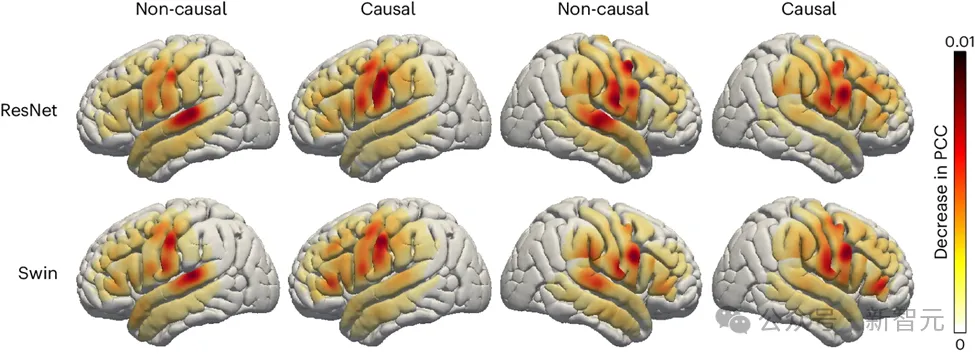 gambar
gambar
Selain itu, kajian juga menunjukkan bahawa sumbangan korteks sensorimotor terutamanya kawasan perut kepada penyahkodan pertuturan adalah sama sama ada di hemisfera kiri atau kanan otak. Penemuan ini menunjukkan bahawa menanam prostesis neurologi di hemisfera kanan untuk memulihkan pertuturan mungkin merupakan pilihan yang berdaya maju, memberikan pandangan penting tentang strategi rawatan masa depan.
Kesimpulan (Tinjauan Menginspirasi)
Pasukan penyelidik membangunkan jenis baharu pensintesis pertuturan boleh dibezakan yang menggunakan rangkaian saraf konvolusi ringan untuk mengekod pertuturan ke dalam satu siri parameter yang boleh ditafsir, seperti ketinggian fonetik, kenyaringan, frekuensi forman , dsb., dan gunakan pensintesis boleh dibezakan yang sama untuk mensintesis semula pertuturan.
Dengan memetakan isyarat saraf kepada parameter ini, penyelidik telah membina sistem penyahkodan pertuturan saraf yang sangat boleh ditafsir dan boleh digunakan pada set data kecil, yang mampu menjana pertuturan bunyi semula jadi.
Sistem ini menunjukkan tahap kebolehulangan yang tinggi di kalangan 48 peserta, dapat memproses data dengan ketumpatan pensampelan spatial yang berbeza, dan dapat memproses isyarat EEG secara serentak dari hemisfera otak kiri dan kanan, menunjukkan keupayaannya untuk melakukan pertuturan Hebat. potensi untuk penyahkodan.
Walaupun terdapat kemajuan yang ketara, para penyelidik juga menunjukkan beberapa batasan semasa model, seperti proses penyahkodan bergantung pada data latihan pertuturan yang dipasangkan dengan rakaman ECoG, yang mungkin tidak berkenaan dengan orang yang mengalami afasia.
Pada masa hadapan, pasukan penyelidik berharap dapat mewujudkan seni bina model yang boleh mengendalikan data bukan grid dan menggunakan data EEG berbilang pesakit dan pelbagai mod dengan lebih berkesan. Dengan kemajuan berterusan teknologi perkakasan dan perkembangan pesat teknologi pembelajaran mendalam, penyelidikan dalam bidang antara muka otak-komputer masih di peringkat awal, tetapi seiring dengan berlalunya masa, visi antara muka otak-komputer dalam filem fiksyen sains akan beransur-ansur. menjadi kenyataan.
Rujukan:
https://www.nature.com/articles/s42256-024-00824-8
Pengarang pertama artikel ini: Xupeng Chen (xc1490),@Rannyu.edu Pengarang yang sepadan: Adeen Flinker
Untuk perbincangan lanjut tentang kausaliti dalam penyahkodan pertuturan saraf, sila rujuk kertas lain oleh pengarang:
https://www.pnas.org/doi/10.1073/pnas.2300255120
Atas ialah kandungan terperinci LeCun dimajukan, AI membenarkan orang aphasic bercakap semula! NYU mengeluarkan penyahkod 'neural-speech' baharu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!