
Rumah >Peranti teknologi >AI >58 baris skala kod Llama 3 hingga 1 juta konteks, mana-mana versi yang diperhalusi boleh digunakan
58 baris skala kod Llama 3 hingga 1 juta konteks, mana-mana versi yang diperhalusi boleh digunakan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-05-06 18:10:081356semak imbas
.
Bermula pada 32k, 100k adalah perkara biasa hari ini. Adakah ini sengaja meninggalkan ruang untuk sumbangan kepada komuniti sumber terbuka? Komuniti sumber terbuka pastinya tidak melepaskan peluang ini:
Kini dengan hanya 58 baris kod, mana-mana versi Llama 3 70b yang diperhalusi boleh berskala secara automatik kepada 1048k (satu juta)
konteks.Di belakang ialah LoRA, diekstrak daripada versi Llama 3 70B Instruct yang diperhalusi yang memanjangkan konteks yang baik, Fail hanya 800mb
. 
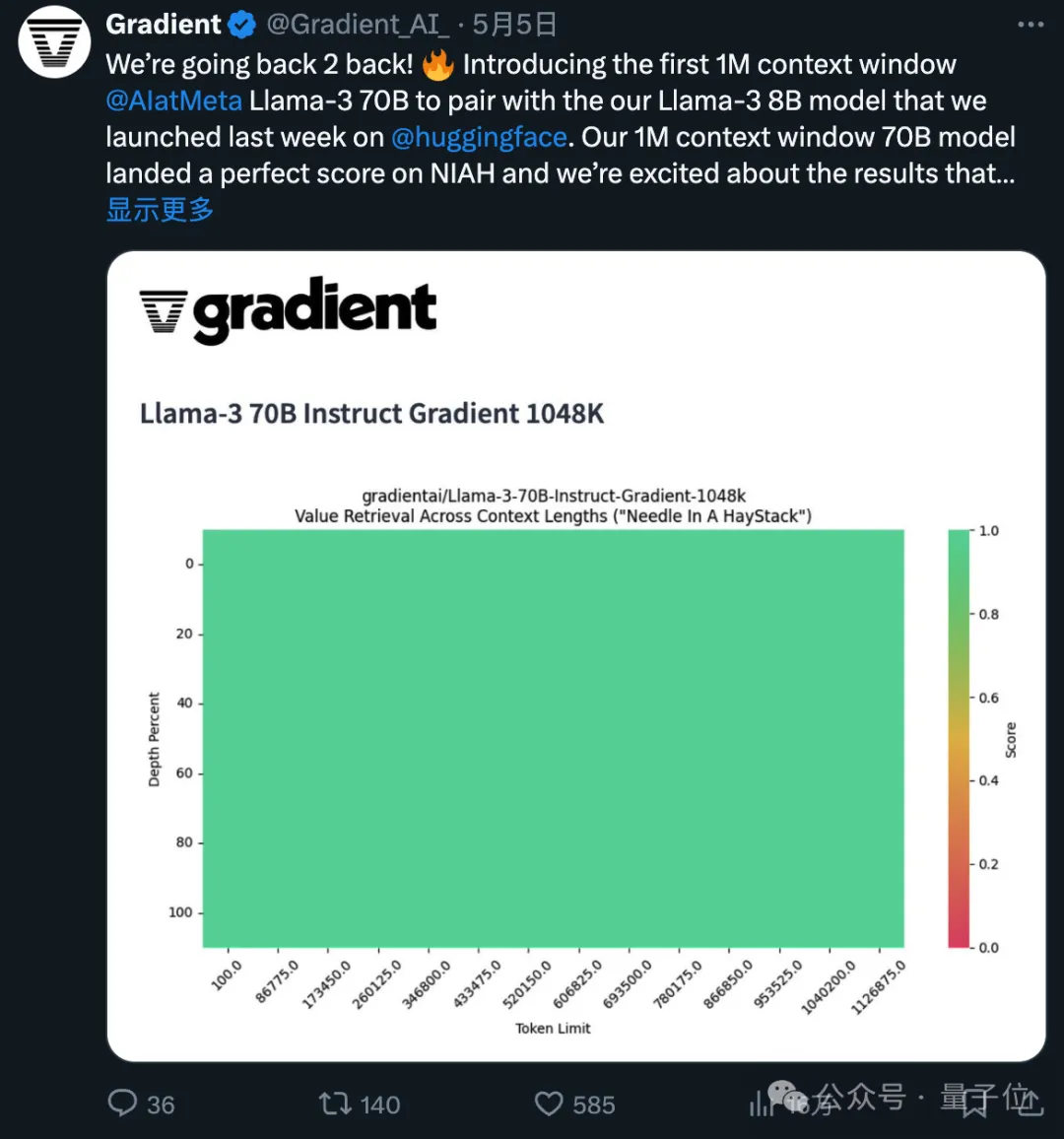
Versi yang diperhalusi bagi konteks 1048k yang digunakan baru sahaja mencapai markah hijau (100% ketepatan) dalam ujian jarum dalam timbunan jerami yang popular.
 Saya harus mengatakan bahawa kelajuan kemajuan sumber terbuka adalah eksponen. .
Saya harus mengatakan bahawa kelajuan kemajuan sumber terbuka adalah eksponen. .
 LoRA yang sepadan datang daripada pembangun
LoRA yang sepadan datang daripada pembangun
Eric Hartford
Dengan membandingkan perbezaan antara model yang diperhalusi dan versi asal, perubahan parameter diekstrak. 
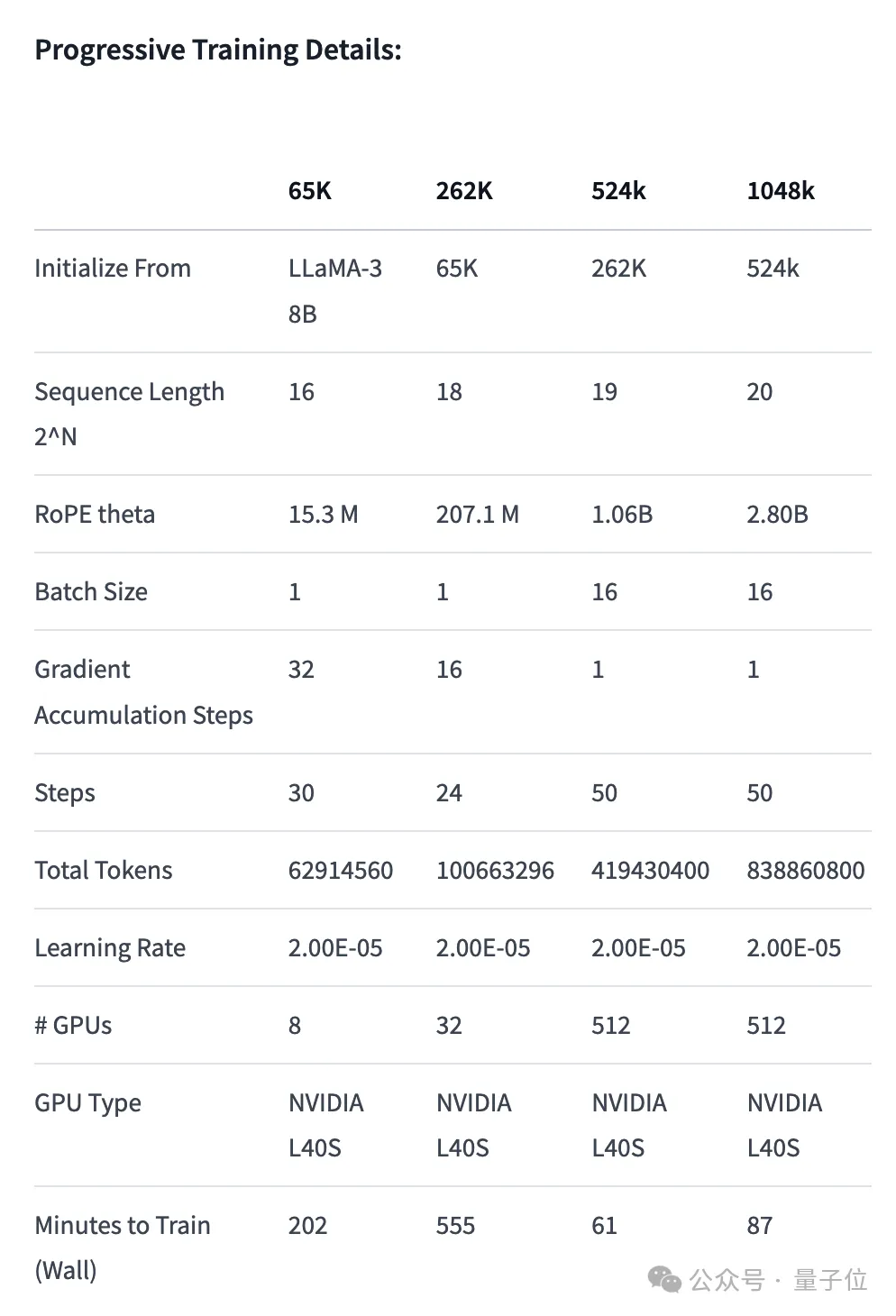
Pertama sekali, pasukan Gradient meneruskan latihan berdasarkan Llama 3 70B Instruct asal dan memperoleh Llama-3-70B-Instruct-Gradient-1048k. Kaedah khusus adalah seperti berikut:

Laraskan pengekodan kedudukan: Gunakan interpolasi sedar NTK untuk memulakan penjadualan optimum RoPE theta dan mengoptimumkannya untuk mengelakkan kehilangan maklumat lanjutan frekuensi tinggi length
 Latihan Progresif:
Latihan Progresif:
- Perlu diambil perhatian bahawa parallelization berlapis pasukan melalui topologi rangkaian tersuai untuk menggunakan lebih baik kluster GPU berskala besar digunakan untuk menangani kesesakan rangkaian yang disebabkan oleh memindahkan banyak blok KV antara peranti.
- Akhirnya, kelajuan latihan model meningkat sebanyak 33 kali ganda. Dalam penilaian prestasi perolehan teks yang panjang, hanya dalam versi yang paling sukar, ralat cenderung berlaku apabila "jarum" disembunyikan di tengah-tengah teks.
- Selepas mempunyai model yang diperhalusi dengan konteks lanjutan, gunakan alat sumber terbuka Mergekit untuk membandingkan model yang ditala halus dan model asas, dan mengekstrak perbezaan dalam parameter untuk menjadi LoRA.
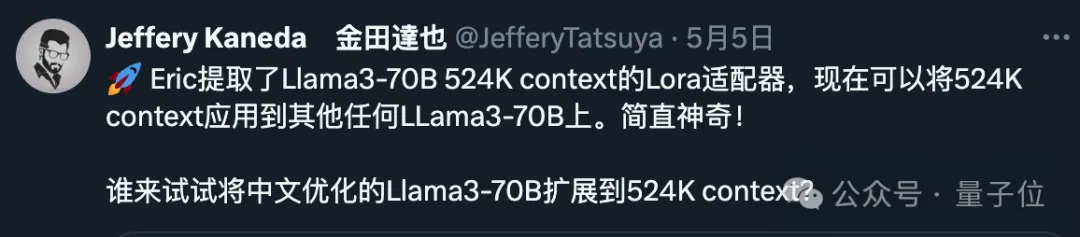
Versi 524k LoRA: https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-524k-adapter
1048k versi LoRA: https:/cohugging cognitivecomputations/Llama-3-70B-Gradient-1048k-adapter
Gabung kod: https://gist.github.com/ehartford/731e3f7079db234fa1b98a09
Atas ialah kandungan terperinci 58 baris skala kod Llama 3 hingga 1 juta konteks, mana-mana versi yang diperhalusi boleh digunakan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!