
Rumah >Peranti teknologi >AI >Bagaimanakah OctopusV3, dengan kurang daripada 1 bilion parameter, boleh dibandingkan dengan GPT-4V dan GPT-4?
Bagaimanakah OctopusV3, dengan kurang daripada 1 bilion parameter, boleh dibandingkan dengan GPT-4V dan GPT-4?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-05-02 16:01:01880semak imbas
Sistem AI berbilang mod dicirikan oleh keupayaan mereka untuk memproses dan mempelajari pelbagai jenis data termasuk bahasa semula jadi, penglihatan, audio, dll., untuk membimbing keputusan tingkah laku mereka. Baru-baru ini, penyelidikan mengenai menggabungkan data visual ke dalam model bahasa yang besar (seperti GPT-4V) telah mencapai kemajuan penting, tetapi cara menukar maklumat imej secara berkesan kepada operasi boleh laku untuk sistem AI masih menghadapi cabaran. Untuk mencapai transformasi maklumat imej, kaedah biasa ialah menukar data imej ke dalam perihalan teks yang sepadan, dan kemudian sistem AI beroperasi berdasarkan penerangan. Ini boleh dilakukan dengan melaksanakan pembelajaran diselia pada set data imej sedia ada, membolehkan sistem AI mempelajari hubungan pemetaan imej-ke-teks secara automatik. Selain itu, kaedah pembelajaran pengukuhan juga boleh digunakan untuk mempelajari cara membuat keputusan berdasarkan maklumat imej dengan berinteraksi dengan persekitaran. Kaedah lain ialah dengan menggabungkan maklumat imej secara langsung dengan model bahasa untuk dibina
Dalam kertas kerja baru-baru ini, penyelidik mencadangkan model berbilang modal yang direka khusus untuk aplikasi AI, memperkenalkan konsep "token berfungsi" .
Tajuk kertas: Octopus v3: Laporan Teknikal untuk Ejen AI Multimodal Sub-bilion Pada peranti
Pautan kertas: https://arxiv.org/pdf/2404.11459.pdf
berat inferens dan inferens- Kod: https://www.nexa4ai.com/apply
 🎚
🎚Perkembangan pesat teknologi kecerdasan buatan telah mengubah sepenuhnya cara interaksi manusia-komputer berlaku, menimbulkan beberapa sistem AI pintar yang boleh melaksanakan tugas yang rumit dan membuat keputusan berdasarkan pelbagai bentuk input seperti bahasa semula jadi dan penglihatan. Sistem ini dijangka mengautomasikan segala-galanya daripada tugas mudah seperti pengecaman imej dan terjemahan bahasa kepada aplikasi kompleks seperti diagnosis perubatan dan pemanduan autonomi. Model bahasa multimodal adalah teras kepada sistem pintar ini, membolehkan mereka memahami dan menjana respons hampir manusia dengan memproses dan menyepadukan data multimodal seperti teks, imej, dan juga audio dan video. Berbanding dengan model bahasa tradisional yang tertumpu terutamanya pada pemprosesan dan penjanaan teks, model bahasa multimodal merupakan lonjakan besar ke hadapan. Dengan menggabungkan maklumat visual, model ini dapat memahami dengan lebih baik konteks dan semantik data input, menghasilkan output yang lebih tepat dan relevan. Keupayaan untuk memproses dan menyepadukan data multimodal adalah penting untuk membangunkan sistem AI multimodal yang boleh memahami tugasan seperti bahasa dan maklumat visual secara serentak, seperti jawapan soalan visual, navigasi imej, analisis sentimen multimodal, dsb.
Salah satu cabaran dalam membangunkan model bahasa multimodal ialah cara mengekod maklumat visual dengan berkesan ke dalam format yang boleh diproses oleh model. Ini biasanya dilakukan dengan bantuan seni bina rangkaian saraf, seperti pengubah visual (ViT) dan rangkaian saraf konvolusi (CNN). Keupayaan untuk mengekstrak ciri hierarki daripada imej digunakan secara meluas dalam tugas penglihatan komputer. Menggunakan seni bina ini sebagai model, seseorang boleh belajar mengekstrak perwakilan yang lebih kompleks daripada data input. Tambahan pula, seni bina berasaskan transformer bukan sahaja mampu menangkap kebergantungan jarak jauh tetapi juga cemerlang dalam memahami hubungan antara objek dalam imej. Sangat popular dalam beberapa tahun kebelakangan ini. Seni bina ini membolehkan model mengekstrak ciri yang bermakna daripada imej input dan menukarnya kepada perwakilan vektor yang boleh digabungkan dengan input teks.
Satu lagi cara untuk mengekod maklumat visual ialah tokenisasi imej, iaitu membahagikan imej kepada unit atau token diskret yang lebih kecil. Pendekatan ini membolehkan model memproses imej dengan cara yang serupa dengan teks, membolehkan penyepaduan yang lebih lancar bagi kedua-dua modaliti. Maklumat token imej boleh dimasukkan ke dalam model bersama-sama dengan input teks, membolehkannya memfokus pada kedua-dua modaliti dan menghasilkan output yang lebih tepat dan kontekstual. Sebagai contoh, model DALL-E yang dibangunkan oleh OpenAI menggunakan varian VQ-VAE (Vector Quantized Variational Autoencoder) untuk melambangkan imej, membolehkan model menjana imej baru berdasarkan penerangan teks. Membangunkan model kecil dan cekap yang boleh bertindak atas pertanyaan dan imej yang dibekalkan pengguna mempunyai implikasi yang mendalam untuk pembangunan sistem AI pada masa hadapan. Model ini boleh digunakan pada peranti terhad sumber seperti telefon pintar dan peranti IoT, mengembangkan skop dan senario aplikasinya. Dengan memanfaatkan kuasa model bahasa multimodal, sistem kecil ini boleh memahami dan menjawab pertanyaan pengguna dengan cara yang lebih semula jadi dan intuitif, sambil mengambil kira konteks visual yang disediakan oleh pengguna. Ini membuka kemungkinan interaksi mesin manusia yang lebih menarik dan diperibadikan, seperti pembantu maya yang memberikan pengesyoran visual berdasarkan pilihan pengguna atau peranti rumah pintar yang melaraskan tetapan berdasarkan ekspresi muka pengguna.
Selain itu, pembangunan sistem AI berbilang modal dijangka akan mendemokrasikan teknologi kecerdasan buatan, memberi manfaat kepada pelbagai pengguna dan industri yang lebih luas. Model yang lebih kecil dan lebih cekap boleh dilatih pada perkakasan dengan kuasa pengkomputeran yang lebih lemah, mengurangkan sumber pengkomputeran dan penggunaan tenaga yang diperlukan untuk penggunaan. Ini boleh membawa kepada aplikasi meluas sistem AI dalam pelbagai bidang seperti penjagaan perubatan, pendidikan, hiburan, e-dagang, dll., akhirnya mengubah cara orang hidup dan bekerja.
Kerja Berkaitan
Model multimodal telah menarik banyak perhatian kerana keupayaannya untuk memproses dan mempelajari pelbagai jenis data seperti teks, imej, audio, dll. Model jenis ini boleh menangkap interaksi kompleks antara modaliti yang berbeza dan menggunakan maklumat pelengkapnya untuk meningkatkan prestasi pelbagai tugas. Model Pra-latihan Vision-Language (VLP) seperti ViLBERT, LXMERT, VisualBERT, dsb. mempelajari penjajaran ciri visual dan teks melalui perhatian merentas mod untuk menjana perwakilan pelbagai mod yang kaya. Seni bina pengubah berbilang modal seperti MMT, ViLT, dsb. telah menambah baik pengubah untuk mengendalikan pelbagai modaliti dengan cekap. Penyelidik juga telah cuba untuk memasukkan modaliti lain seperti audio dan ekspresi muka ke dalam model, seperti model analisis sentimen multimodal (MSA), model multimodal emotion recognition (MER), dsb. Dengan menggunakan maklumat pelengkap modaliti yang berbeza, model multimodal mencapai prestasi dan keupayaan generalisasi yang lebih baik daripada kaedah mod tunggal.
Model bahasa terminal ditakrifkan sebagai model dengan kurang daripada 7 bilion parameter, kerana penyelidik mendapati bahawa walaupun dengan pengkuantitian, adalah sangat sukar untuk menjalankan model 13 bilion parameter pada peranti tepi. Kemajuan terkini dalam bidang ini termasuk Gemma 2B dan 7B Google, Kod Stable 3B Stable Diffusion dan Llama 7B Meta. Menariknya, penyelidikan Meta menunjukkan bahawa, tidak seperti model bahasa besar, model bahasa kecil berprestasi lebih baik dengan seni bina yang mendalam dan sempit. Teknik lain yang berfaedah kepada model terminal termasuk perkongsian benam, perhatian pertanyaan berkumpulan dan perkongsian berat blok segera yang dicadangkan dalam MobileLLM. Penemuan ini menyerlahkan keperluan untuk mempertimbangkan kaedah pengoptimuman dan strategi reka bentuk yang berbeza apabila membangunkan model bahasa kecil untuk aplikasi akhir berbanding model besar.
Kaedah Octopus
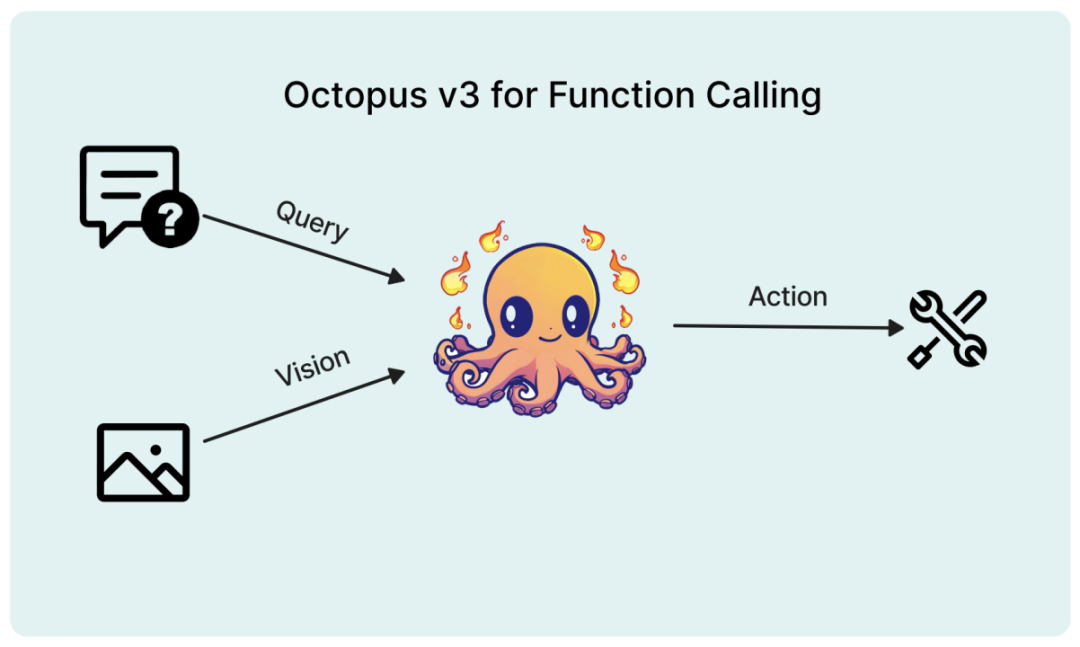
Teknologi utama yang digunakan dalam pembangunan model Octopus v3. Dua aspek utama pembangunan model multimodal ialah menyepadukan maklumat imej dengan input teks dan mengoptimumkan keupayaan model untuk meramalkan tindakan.
Pengekodan maklumat visual
Terdapat banyak kaedah pengekodan maklumat visual dalam pemprosesan imej, dan pembenaman lapisan tersembunyi biasanya digunakan. Sebagai contoh, pembenaman lapisan tersembunyi model VGG-16 digunakan untuk tugas pemindahan gaya. Model CLIP OpenAI menunjukkan keupayaan untuk menyelaraskan teks dan pembenaman imej, memanfaatkan pengekod imejnya untuk membenamkan imej. Kaedah seperti ViT menggunakan teknologi yang lebih maju seperti tokenisasi imej. Para penyelidik menilai pelbagai teknik pengekodan imej dan mendapati kaedah model CLIP adalah yang paling berkesan. Oleh itu, kertas kerja ini menggunakan model berasaskan CLIP untuk pengekodan imej.
Token fungsional
Sama seperti tokenisasi yang digunakan pada bahasa dan imej semula jadi, fungsi tertentu juga boleh dirangkumkan sebagai token berfungsi. Para penyelidik memperkenalkan strategi latihan untuk token ini, menggunakan teknologi model bahasa semula jadi untuk memproses perkataan yang tidak kelihatan. Kaedah ini serupa dengan word2vec dan memperkayakan semantik token melalui konteksnya. Contohnya, model bahasa peringkat tinggi pada mulanya mungkin bergelut dengan istilah kimia yang kompleks seperti PEGylation dan Endosomal Escape. Tetapi melalui pemodelan bahasa kausal, terutamanya dengan latihan pada set data yang mengandungi istilah ini, model boleh mempelajari istilah ini. Begitu juga, token berfungsi juga boleh dipelajari melalui strategi selari, dengan model Octopus v2 menyediakan platform yang berkuasa untuk proses pembelajaran sedemikian. Penyelidikan menunjukkan bahawa ruang takrifan token berfungsi adalah tidak terhingga, membenarkan mana-mana fungsi tertentu diwakili sebagai token.
Latihan berbilang peringkat
Untuk membangunkan sistem AI berbilang modal berprestasi tinggi, penyelidik mengguna pakai seni bina model yang menyepadukan model bahasa kausal dan pengekod imej. Proses latihan model ini dibahagikan kepada beberapa peringkat. Pertama, model bahasa kausal dan pengekod imej dilatih secara berasingan untuk mewujudkan model asas. Selepas itu, kedua-dua komponen digabungkan dan diselaraskan serta dilatih untuk menyegerakkan keupayaan pemprosesan imej dan teks. Atas dasar ini, kaedah Octopus v2 digunakan untuk menggalakkan pembelajaran token berfungsi. Dalam fasa latihan terakhir, token berfungsi ini yang berinteraksi dengan persekitaran memberikan maklum balas untuk pengoptimuman model selanjutnya. Oleh itu, pada peringkat akhir, pengkaji mengamalkan pembelajaran pengukuhan dan memilih satu lagi model bahasa besar sebagai model ganjaran. Kaedah latihan berulang ini meningkatkan keupayaan model untuk memproses dan menyepadukan maklumat pelbagai mod.
Penilaian Model
Bahagian ini memperkenalkan keputusan percubaan model dan membandingkannya dengan kesan penyepaduan model GPT-4V dan GPT-4. Dalam eksperimen perbandingan, para penyelidik mula-mula menggunakan GPT-4V (gpt-4-turbo) untuk memproses maklumat imej. Data yang diekstrak kemudiannya dimasukkan ke dalam rangka kerja GPT-4 (gpt-4-turbo-preview), yang mengkontekstualisasikan semua penerangan fungsi dan menggunakan pembelajaran beberapa pukulan untuk meningkatkan prestasi. Dalam demonstrasi, penyelidik menukar 10 API telefon pintar yang biasa digunakan kepada token berfungsi dan menilai prestasi mereka, seperti yang diperincikan dalam bahagian seterusnya.
Perlu diingat bahawa walaupun artikel ini hanya menunjukkan 10 token berfungsi, model ini boleh melatih lebih banyak token untuk mencipta sistem AI yang lebih umum. Para penyelidik mendapati bahawa untuk API terpilih, model dengan kurang daripada 1 bilion parameter dilakukan sebagai AI multimodal yang setanding dengan gabungan GPT-4V dan GPT-4.
Selain itu, kebolehskalaan model dalam artikel ini membolehkan kemasukan pelbagai token berfungsi, membolehkan penciptaan sistem AI yang sangat khusus sesuai untuk medan atau senario tertentu. Kesesuaian ini menjadikan pendekatan kami sangat berharga dalam industri seperti penjagaan kesihatan, kewangan dan perkhidmatan pelanggan, di mana penyelesaian dipacu AI boleh meningkatkan kecekapan dan pengalaman pengguna dengan ketara.
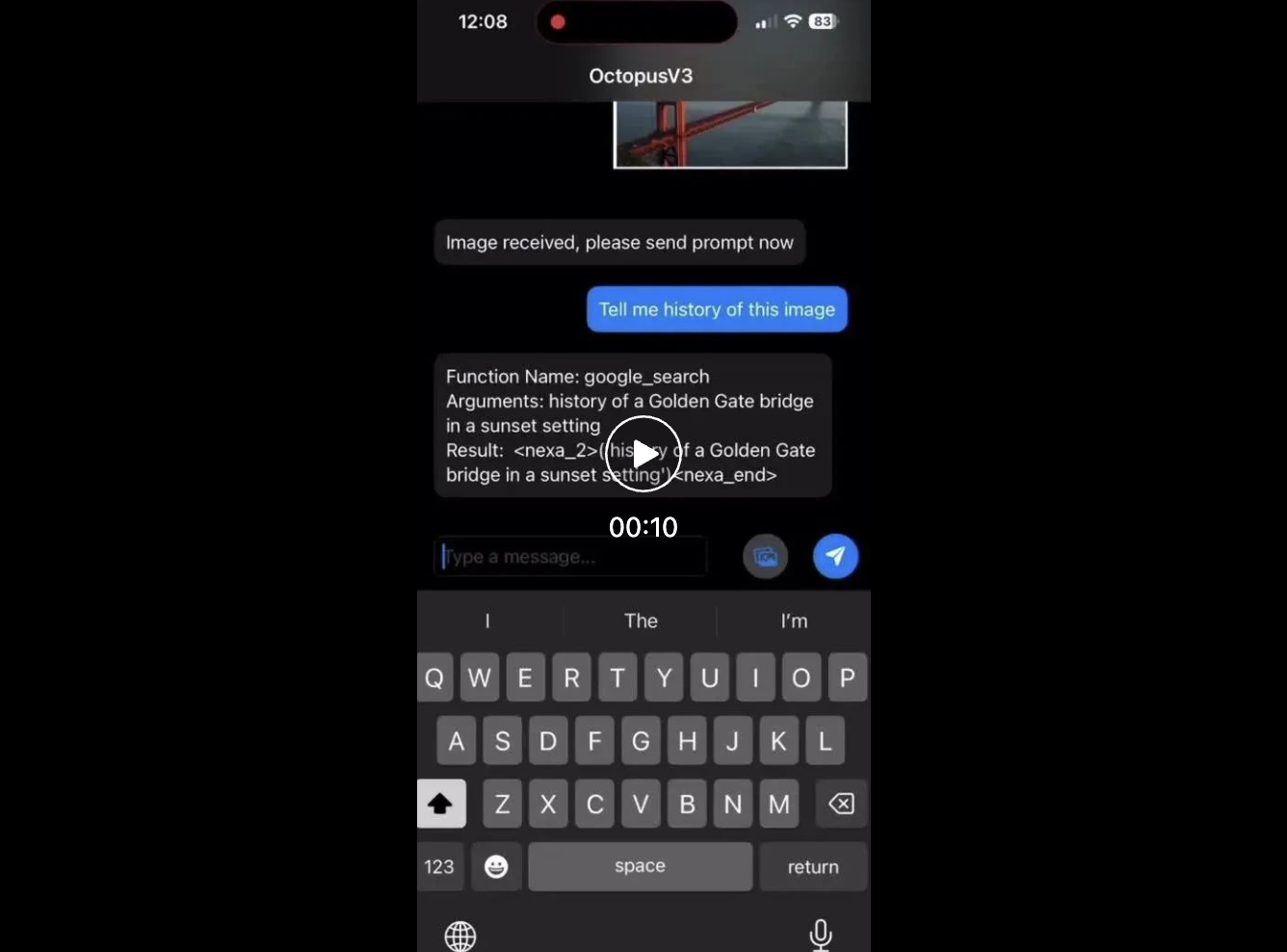
Di antara semua nama fungsi di bawah, Octopus hanya mengeluarkan token berfungsi seperti
Hantar E-mel

Hantar SMS

Carian Google


Kitar Semula Pintar

Hilang dan Ditemui

Reka Bentuk Dalaman

Instacart Shopping

DoorDash Delivery

Pet Care
Berdasarkan Octopus v2, model yang dikemas kini menggabungkan maklumat teks dan visual , satu langkah ke hadapan yang ketara daripada pendahulunya, pendekatan teks sahaja. Kemajuan ketara ini membolehkan pemprosesan serentak data bahasa visual dan semula jadi, membuka jalan untuk aplikasi yang lebih luas. Token berfungsi yang diperkenalkan dalam Octopus v2 boleh disesuaikan dengan pelbagai bidang, seperti industri perubatan dan automotif. Dengan penambahan data visual, potensi token berfungsi diperluaskan lagi kepada bidang seperti pemanduan autonomi dan robotik. Selain itu, model berbilang modal dalam artikel ini membolehkan anda benar-benar mengubah peranti seperti Raspberry Pi kepada perkakasan pintar seperti Rabbit R1 dan Humane AI Pin, menggunakan model titik akhir dan bukannya penyelesaian berasaskan awan.
Token berfungsi pada masa ini diberi kuasa Penyelidik menggalakkan pembangun untuk mengambil bahagian dalam rangka kerja artikel ini dan berinovasi secara bebas di bawah premis mematuhi perjanjian lesen. Dalam penyelidikan masa depan, penyelidik berhasrat untuk membangunkan rangka kerja latihan yang boleh menampung modaliti data tambahan seperti audio dan video. Di samping itu, penyelidik mendapati bahawa input visual boleh menyebabkan kependaman yang besar dan sedang mengoptimumkan kelajuan inferens.
Atas ialah kandungan terperinci Bagaimanakah OctopusV3, dengan kurang daripada 1 bilion parameter, boleh dibandingkan dengan GPT-4V dan GPT-4?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!