
Rumah >Peranti teknologi >AI >Xiaohongshu mentafsir pengambilan maklumat daripada mekanisme ingatan dan mencadangkan paradigma baharu untuk mendapatkan EACL Oral
Xiaohongshu mentafsir pengambilan maklumat daripada mekanisme ingatan dan mencadangkan paradigma baharu untuk mendapatkan EACL Oral

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-04-29 16:16:071289semak imbas

Baru-baru ini, kertas kerja "Generative Dense Retrieval: Memory Can Be a Burden" daripada pasukan algoritma carian Xiaohongshu telah diterima sebagai Oral oleh EACL 2024, persidangan antarabangsa dalam bidang pemprosesan bahasa semula jadi, dengan kadar penerimaan sebanyak 11.32% (144/1271 ).
Dalam kertas kerja mereka, mereka mencadangkan paradigma pencarian maklumat novel - Generative Dense Retrieval (GDR). Paradigma ini dapat menyelesaikan dengan baik cabaran yang dihadapi oleh perolehan semula generatif tradisional (GR) apabila memproses set data berskala besar. Ia diilhamkan oleh mekanisme ingatan.
Dalam amalan lepas, GR bergantung pada mekanisme ingatan uniknya untuk mencapai interaksi mendalam antara pertanyaan dan perpustakaan dokumen. Walau bagaimanapun, kaedah yang bergantung pada pengekodan autoregresif model bahasa ini mempunyai had yang jelas apabila memproses data berskala besar, termasuk ciri dokumen berbutir halus kabur, saiz perpustakaan dokumen terhad dan kesukaran dalam kemas kini indeks.
GDR yang dicadangkan oleh Xiaohongshu mengguna pakai idea perolehan semula dua peringkat daripada kasar kepada halus Mula-mula menggunakan kapasiti memori terhad model bahasa untuk merealisasikan pemetaan pertanyaan kepada dokumen, dan kemudian menggunakan mekanisme pemadanan vektor untuk. melengkapkan pemetaan dokumen kepada pemetaan halus. GDR berkesan mengurangkan kelemahan yang wujud GR dengan memperkenalkan mekanisme padanan vektor untuk mendapatkan set padat.
Selain itu, pasukan itu juga mereka bentuk "strategi pembinaan pengecam kluster dokumen mesra ingatan" dan "strategi pensampelan negatif penyesuaian kelompok dokumen" untuk meningkatkan prestasi perolehan kedua-dua peringkat masing-masing. Di bawah berbilang tetapan set data Natural Questions, GDR bukan sahaja menunjukkan prestasi Recall@k SOTA, tetapi juga mencapai kebolehskalaan yang baik sambil mengekalkan kelebihan interaksi yang mendalam, membuka kemungkinan baharu untuk penyelidikan masa hadapan tentang pengambilan maklumat.
1. Latar Belakang
Alat carian teks mempunyai nilai penyelidikan dan aplikasi yang penting. Paradigma carian tradisional, seperti perolehan jarang (SR) berdasarkan padanan perkataan dan perolehan padat (DR) berdasarkan padanan vektor semantik, walaupun masing-masing mempunyai kelebihan tersendiri, dengan peningkatan model bahasa yang telah dilatih, berdasarkan ini The generative retrieval paradigma mula muncul. Permulaan paradigma perolehan semula generatif adalah berdasarkan padanan semantik antara pertanyaan dan dokumen calon. Dengan memetakan pertanyaan dan dokumen ke dalam ruang semantik yang sama, masalah pengambilan semula dokumen calon diubah menjadi pengambilan padat darjah padanan vektor. Paradigma pencarian semula terobosan ini mengambil kesempatan daripada model bahasa yang telah dilatih dan membawa peluang baharu kepada bidang carian teks. Walau bagaimanapun, paradigma pencarian semula generatif masih menghadapi cabaran. Di satu pihak, pra-latihan sedia ada
Semasa proses latihan, model secara autoregresif menjana pengecam dokumen yang berkaitan dengan pertanyaan yang diberikan sebagai konteks. Proses ini membolehkan model menghafal korpus calon. Selepas pertanyaan memasuki model, ia berinteraksi dengan parameter model dan dinyahkod secara autoregresif, yang secara tersirat menghasilkan interaksi mendalam antara pertanyaan dan korpus calon, dan interaksi mendalam ini adalah apa yang SR dan DR kekurangan. Oleh itu, GR boleh menunjukkan prestasi perolehan semula yang cemerlang apabila model dapat menghafal dokumen calon dengan tepat.
Walaupun mekanisme ingatan GR tidak sempurna. Melalui percubaan perbandingan antara model DR klasik (AR2) dan model GR (NCI), kami mengesahkan bahawa mekanisme ingatan akan membawa sekurang-kurangnya tiga cabaran utama:
1) Ciri dokumen yang halus:
Kami masing-masing Kebarangkalian NCI dan AR2 membuat ralat apabila menyahkod setiap bit pengecam dokumen daripada kasar kepada halus telah dikira. Untuk AR2, kami mendapati pengecam yang sepadan dengan dokumen yang paling berkaitan untuk pertanyaan tertentu melalui pemadanan vektor, dan kemudian mengira langkah ralat pertama pengecam untuk mendapatkan kadar ralat penyahkodan langkah demi langkah yang sepadan dengan AR2. Seperti yang ditunjukkan dalam Jadual 1, NCI berprestasi baik pada separuh pertama penyahkodan, manakala kadar ralat lebih tinggi pada separuh kedua, dan sebaliknya berlaku untuk AR2. Ini menunjukkan bahawa NCI boleh melengkapkan pemetaan kasar ruang semantik dokumen calon dengan lebih baik melalui pangkalan data memori keseluruhan. Walau bagaimanapun, memandangkan ciri yang dipilih semasa proses latihan ditentukan oleh carian, pemetaan butiran halusnya sukar diingat dengan tepat, jadi ia berprestasi buruk dalam pemetaan butiran halus.

2) Saiz perpustakaan dokumen adalah terhad:
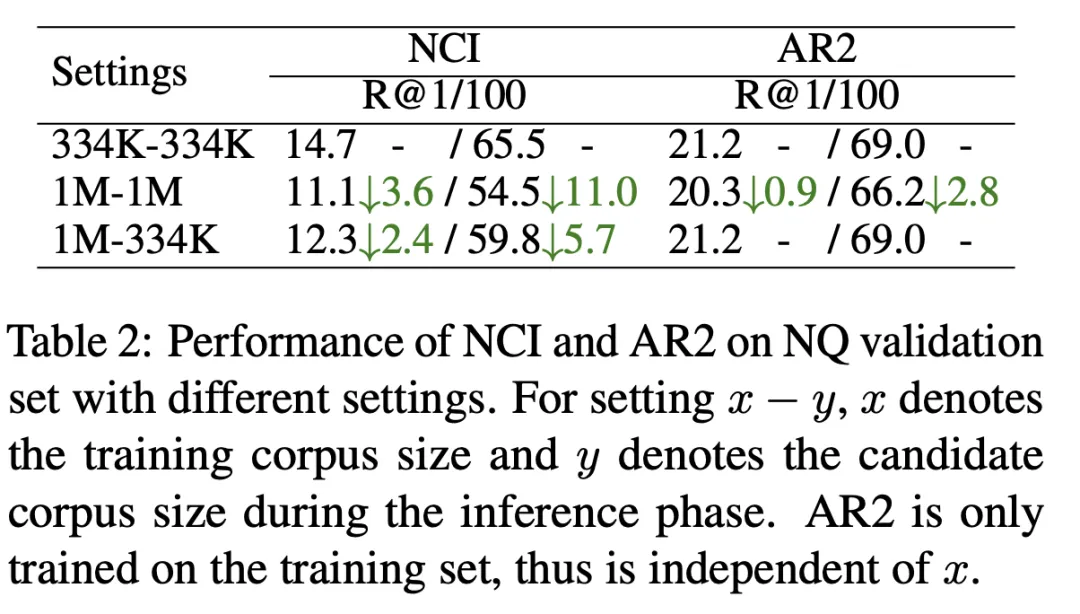
Seperti yang ditunjukkan dalam Jadual 2, kami melatih model NCI dengan saiz perpustakaan dokumen calon 334K (baris pertama) dan saiz dokumen calon 1M (baris kedua). Diuji dengan penunjuk R@k. Keputusan menunjukkan NCI turun 11 mata pada R@100, berbanding AR2 yang hanya turun 2.8 mata. Untuk meneroka sebab prestasi NCI menurun dengan ketara apabila saiz pustaka dokumen calon bertambah, kami terus menguji keputusan ujian model NCI yang dilatih pada pustaka dokumen 1M apabila menggunakan 334K sebagai perpustakaan dokumen calon (baris ketiga). Berbanding dengan baris pertama, beban NCI untuk menghafal lebih banyak dokumen membawa kepada penurunan ketara dalam prestasi ingatannya, menunjukkan bahawa kapasiti memori terhad model mengehadkan keupayaannya untuk menghafal perpustakaan dokumen calon berskala besar.
3) Kesukaran kemas kini indeks:
Apabila dokumen baharu perlu ditambah ke perpustakaan calon, pengecam dokumen perlu dikemas kini dan model perlu dilatih semula -menghafal semua dokumen. Jika tidak, pemetaan lapuk (pertanyaan kepada pengecam dokumen dan pengecam dokumen kepada dokumen) akan mengurangkan prestasi perolehan semula dengan ketara.
Masalah di atas menghalang penggunaan GR dalam senario sebenar. Atas sebab ini, selepas analisis, kami percaya bahawa mekanisme pemadanan DR mempunyai hubungan pelengkap dengan mekanisme ingatan, jadi kami mempertimbangkan untuk memasukkannya ke dalam GR untuk mengekalkan mekanisme ingatan sambil menindas kelemahannya. Kami mencadangkan paradigma baharu Generative Dense Retrieval (GDR):
- Kami mereka bentuk rangka kerja perolehan semula dua peringkat keseluruhan daripada kasar kepada halus, menggunakan mekanisme memori untuk mencapai padanan antara kelompok (pertanyaan kepada Pemetaan kelompok dokumen ), dan padanan intra-kluster (pemetaan kluster dokumen kepada dokumen) diselesaikan melalui mekanisme padanan vektor.
- Untuk membantu model menghafal perpustakaan dokumen calon, kami telah membina strategi pembinaan pengecam kluster dokumen yang mesra ingatan untuk mengawal kebutiran pembahagian kluster dokumen berdasarkan kapasiti memori model dan menambah baik padanan antara kluster kesan.
- Dalam fasa latihan, kami mencadangkan strategi pensampelan negatif penyesuaian untuk kelompok dokumen berdasarkan ciri-ciri perolehan dua peringkat, yang meningkatkan berat sampel negatif dalam kelompok dan meningkatkan kesan padanan dalam kelompok. . pemetaan berikut:
Dalam proses ini, kebarangkalian penjanaan CID ialah:
di mana 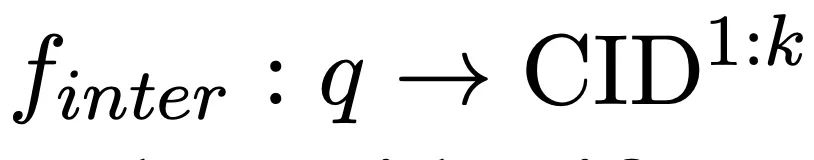
embedding dijanakan semuanya
adalah satu yang dijana oleh perwakilan pertanyaan Dimensi pengekod. Kebarangkalian ini juga disimpan sebagai skor padanan antara kelompok dan mengambil bahagian dalam operasi seterusnya. Berdasarkan ini, kami menggunakan kehilangan rentas entropi standard untuk melatih model: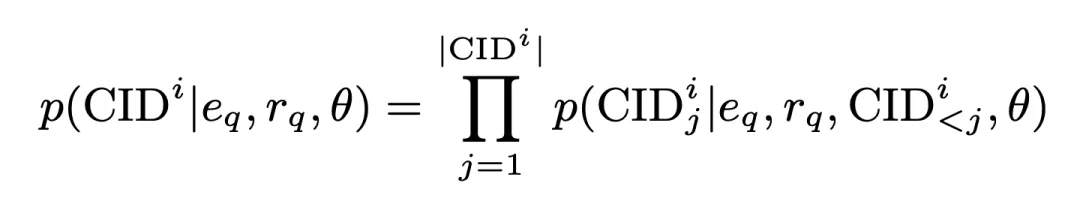
2.2 Pemadanan intra-kluster berdasarkan mekanisme pemadanan vektor
Kami seterusnya mendapatkan semula dokumen calon daripada kluster dokumen calon dan melengkapkan intra-kluster padanan kelompok:
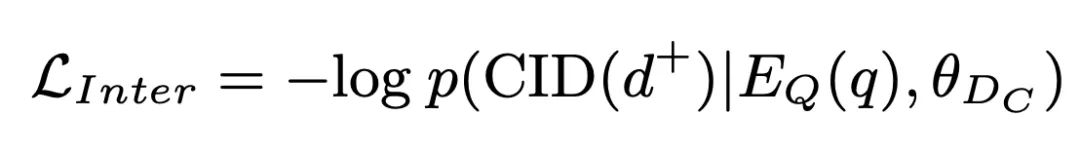
Dalam proses ini, kehilangan NLL digunakan untuk melatih model:
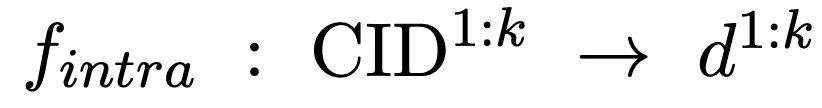
Akhir sekali, kami mengira nilai wajaran skor padanan antara kelompok dan skor padanan intra-kluster dokumen dan mengisihnya, dan pilih K Teratas sebagai dokumen berkaitan yang diambil:

di mana beta ditetapkan dalam percubaan kami Tetapkan kepada 1.
2.3 Strategi pembinaan pengecam kluster dokumen mesra memori
Untuk menggunakan sepenuhnya kapasiti memori terhad model untuk mencapai interaksi mendalam antara pertanyaan dan perpustakaan dokumen calon, kami mencadangkan kluster dokumen mesra memori strategi pembinaan pengecam. Strategi ini mula-mula menggunakan kapasiti memori model sebagai penanda aras untuk mengira had atas bilangan dokumen dalam kelompok:
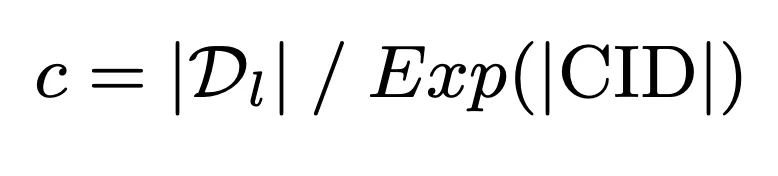
Atas dasar ini, pengecam gugusan dokumen dibina lagi melalui algoritma K-means untuk pastikan beban ingatan model tidak melebihi Kapasiti ingatannya:

2.4 Dokumen strategi pensampelan negatif adaptif kelompok
GDR Rangka kerja pengambilan dua peringkat dalam kumpulan menentukan bahawa sampel negatif gugusan bahagian yang lebih besar dalam proses pemadanan intra-kluster. Untuk tujuan ini, kami menggunakan pembahagian kluster dokumen sebagai penanda aras dalam peringkat kedua latihan untuk secara eksplisit meningkatkan berat sampel negatif dalam kluster, dengan itu memperoleh keputusan padanan intra-kluster yang lebih baik:
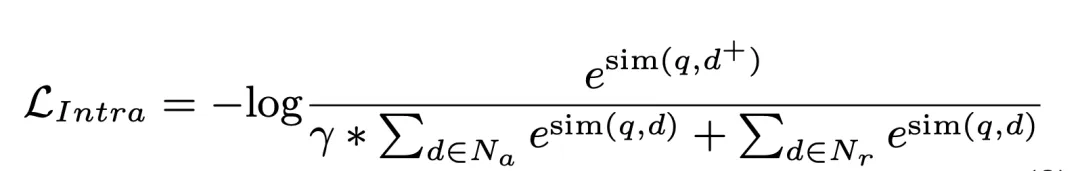
3. Eksperimen
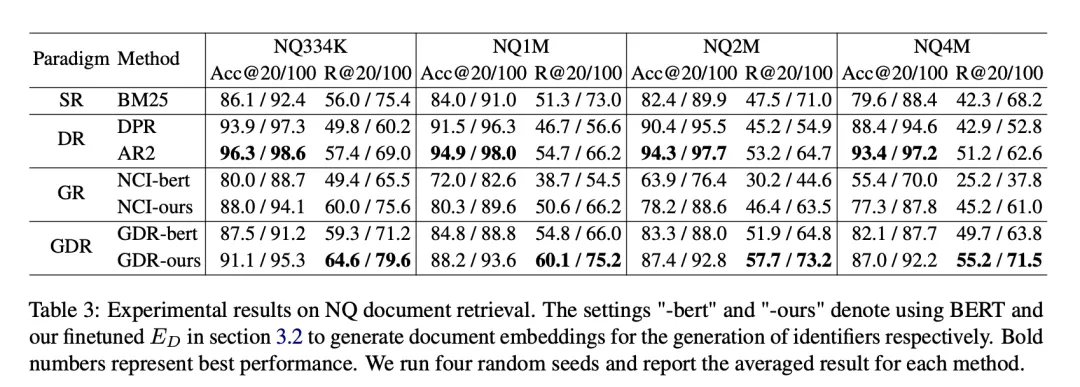
Data data yang digunakan dalam eksperimen ialah Soalan Semulajadi (NQ), yang mengandungi 58K pasangan latihan (pertanyaan dan dokumen berkaitan) dan pasangan pengesahan 6K, disertai pustaka dokumen calon 21M. Setiap pertanyaan mempunyai berbilang dokumen berkaitan, yang meletakkan keperluan yang lebih tinggi pada prestasi penarikan semula model. Untuk menilai prestasi GDR pada asas dokumen dengan saiz yang berbeza, kami membina tetapan berbeza seperti NQ334K, NQ1M, NQ2M dan NQ4M dengan menambah petikan yang tinggal daripada korpus 21M penuh kepada NQ334K. GDR menjana CID pada setiap set data secara berasingan untuk mengelakkan maklumat semantik perpustakaan dokumen calon yang lebih besar daripada bocor ke dalam korpus yang lebih kecil. Kami mengguna pakai BM25 (pelaksanaan Anserini) sebagai garis dasar SR, DPR dan AR2 sebagai garis dasar DR, dan NCI sebagai garis dasar GR. Metrik penilaian termasuk R@k dan Acc@k.
3.1 Keputusan percubaan utama
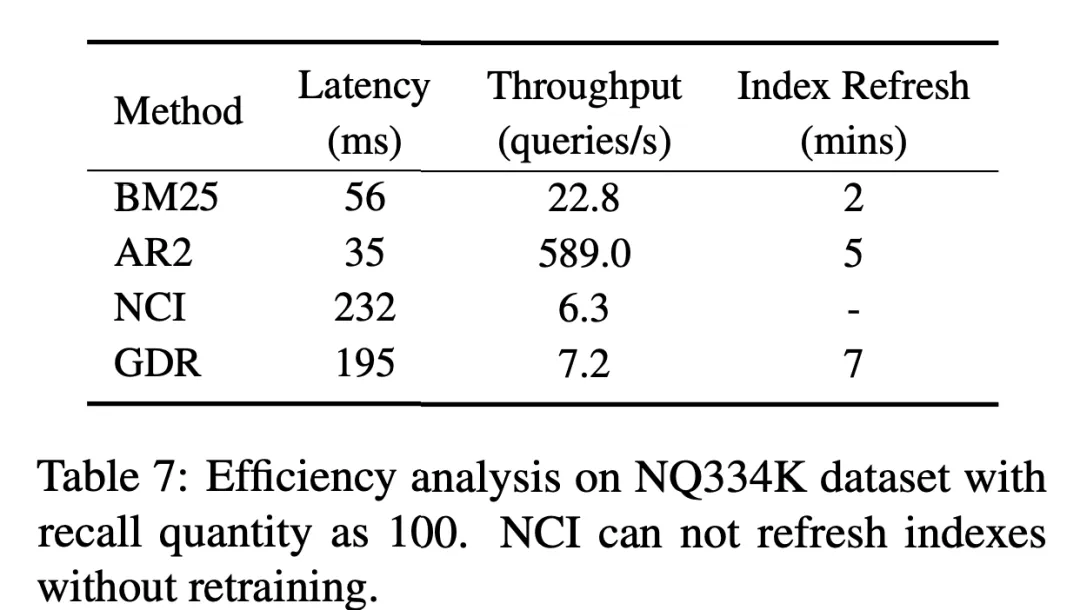
Pada set data NQ, GDR meningkat secara purata sebanyak 3.0 pada metrik R@k dan menduduki tempat kedua pada metrik Acc@k. Ini menunjukkan bahawa GDR memaksimumkan kelebihan mekanisme ingatan dalam interaksi mendalam dan mekanisme pemadanan dalam diskriminasi ciri berbutir halus melalui proses mendapatkan semula kasar kepada halus. . kadar penurunan dalam ketiga-tiga arah pengembangan melebihi 15.25%. Sebaliknya, GDR mencapai purata kadar pengurangan R@100 sebanyak 3.50%, yang serupa dengan SR dan DR dengan memfokuskan kandungan memori pada volum tetap ciri berbutir kasar korpus. . dokumen mesra Strategi pembinaan pengecam kluster boleh mengurangkan beban memori dengan ketara, sekali gus membawa kepada prestasi perolehan semula yang lebih baik. Di samping itu, Jadual 4 menunjukkan bahawa strategi pensampelan negatif adaptif kluster dokumen yang digunakan dalam latihan GDR meningkatkan keupayaan padanan terperinci dengan menyediakan lebih banyak isyarat diskriminatif dalam kelompok dokumen. . dan pada masa yang sama, melalui Pengekod dokumen mengekstrak perwakilan vektor dan mengemas kini indeks vektor, dengan itu melengkapkan pengembangan pantas dokumen baharu. Seperti yang ditunjukkan dalam Jadual 6, dalam penetapan penambahan dokumen baharu pada korpus calon, R@100 NCI menurun sebanyak 18.3 mata peratusan, manakala prestasi GDR hanya menurun sebanyak 1.9 mata peratusan. Ini menunjukkan bahawa GDR mengurangkan skalabiliti sukar mekanisme memori dengan memperkenalkan mekanisme padanan dan mengekalkan kesan ingatan yang baik tanpa melatih semula model.
3.5 Limitasi
Terhad oleh ciri-ciri penjanaan autoregresif model bahasa, walaupun GDR memperkenalkan mekanisme pemadanan vektor pada peringkat kedua, yang mencapai peningkatan kecekapan perolehan yang ketara berbanding GR, tetapi berbanding DR Masih terdapat banyak ruang untuk penambahbaikan bersama SR. Kami mengharapkan lebih banyak penyelidikan pada masa hadapan untuk membantu mengurangkan masalah kelewatan yang disebabkan oleh pengenalan mekanisme ingatan ke dalam rangka kerja pengambilan semula.
4 Kesimpulan
Dalam kajian ini, kami meneroka dengan mendalam kesan pedang bermata dua mekanisme ingatan dalam pencarian maklumat: dalam satu pihak, mekanisme ini mencapai interaksi mendalam antara pertanyaan dan calon perpustakaan dokumen; Ia menggantikan kekurangan pengambilan semula secara intensif, kapasiti memori terhad model dan kerumitan pengemaskinian indeks menjadikannya sukar untuk menangani perpustakaan dokumen calon yang berskala besar dan dinamik. Untuk menyelesaikan masalah ini, kami secara inovatif menggabungkan mekanisme memori dan mekanisme pemadanan vektor secara hierarki, supaya kedua-duanya boleh memaksimumkan kekuatan mereka, mengelakkan kelemahan mereka dan saling melengkapi.
Kami mencadangkan paradigma perolehan teks baharu, Generative Dense Retrieval (GDR). GDR Paradigma ini melakukan pencarian semula dua peringkat daripada kasar kepada halus untuk pertanyaan yang diberikan Pertama, mekanisme memori secara autoregresif menjana pengecam gugusan dokumen untuk memetakan pertanyaan kepada gugusan dokumen, dan kemudian mekanisme pemadanan vektor mengira hubungan antara. pertanyaan dan dokumen Kesamaan melengkapkan pemetaan kelompok dokumen kepada dokumen.
Strategi pembinaan pengecam kluster dokumen mesra memori memastikan beban memori model tidak melebihi kapasiti memorinya dan meningkatkan kesan padanan antara kelompok. Strategi pensampelan negatif adaptif kluster dokumen meningkatkan isyarat latihan untuk membezakan sampel negatif dalam kluster dan meningkatkan kesan padanan dalam kluster. Percubaan meluas telah membuktikan bahawa GDR boleh mencapai prestasi perolehan semula yang sangat baik pada perpustakaan dokumen calon berskala besar, dan boleh menangani kemas kini perpustakaan dokumen dengan cekap.
Sebagai percubaan yang berjaya untuk menyepadukan kelebihan kaedah perolehan semula tradisional, paradigma perolehan intensif generatif mempunyai kelebihan prestasi ingatan yang baik, kebolehskalaan yang kukuh dan prestasi yang mantap dalam senario dengan perpustakaan dokumen calon yang besar. Apabila model bahasa besar terus bertambah baik dalam pemahaman dan keupayaan penjanaan mereka, prestasi pencarian intensif generatif akan dipertingkatkan lagi, membuka dunia yang lebih luas untuk mendapatkan maklumat.
Alamat kertas: https://www.php.cn/link/9e69fd6d1c5d1cef75ffbe159c1f322e
Pengarang- intro
- Yuan Peiwen
sekarang Ph.D. Belajar di Institut Teknologi Beijing, bekerja sebagai pelatih dalam pasukan carian komuniti Xiaohongshu, dan menerbitkan banyak kertas pengarang pertama dalam NeurIPS, ICLR, AAAI, EACL, dll. Arah penyelidikan utama ialah penaakulan dan penilaian model bahasa yang besar, dan perolehan maklumat. -
王星霖
Kini belajar di Beijing Institute of Technology, seorang pelatih di Xiaohongshu Community Search Group, menerbitkan beberapa kertas kerja dalam EACL, NeurdIPS Teknologi Antarabangsa, EACL dan NeurdIPS. Cabaran DSTC11 Memenangi tempat kedua dalam trek penilaian. Arah penyelidikan utama ialah penaakulan dan penilaian model bahasa yang besar, dan perolehan maklumat. -
Feng Shaoxiong
bertanggungjawab untuk penarikan semula vektor carian komuniti Xiaohongshu. Lulus dari Institut Teknologi Beijing dengan Ph.D., beliau telah menerbitkan beberapa kertas kerja dalam persidangan/jurnal teratas dalam bidang pembelajaran mesin dan pemprosesan bahasa semula jadi seperti ICLR, AAAI, ACL, EMNLP, NAACL, EACL, KBS, dll. . Arah penyelidikan utama termasuk penilaian model bahasa besar, penyulingan inferens, perolehan semula generatif, penjanaan dialog domain terbuka, dsb. -
Daoxuan
Ketua pasukan carian transaksi Xiaohongshu. Lulus dari Universiti Zhejiang dengan Ph.D., beliau telah menerbitkan beberapa kertas kerja pengarang pertama di persidangan teratas dalam bidang pembelajaran mesin seperti NeurIPS dan ICML, dan telah menjadi penyemak untuk banyak persidangan/jurnal teratas untuk masa yang lama. Perniagaan utama meliputi carian kandungan, carian e-dagang, carian siaran langsung, dsb. -
Zeng Shu
lulus dari Jabatan Elektronik Universiti Tsinghua dengan ijazah sarjana kini bertanggungjawab untuk memanggil semula dan carian menegak dalam carian komuniti Xiaohongshu dan arah teknikal yang lain.
Atas ialah kandungan terperinci Xiaohongshu mentafsir pengambilan maklumat daripada mekanisme ingatan dan mencadangkan paradigma baharu untuk mendapatkan EACL Oral. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Semakan model bahasa berskala besar yang baru dikeluarkan: ulasan paling komprehensif dari T5 hingga GPT-4, dikarang bersama oleh lebih daripada 20 penyelidik domestik
- Pengarang kertas menjadi popular Bilakah model bahasa besar seperti ChatGPT boleh menjadi pengarang bersama kertas kerja?
- Jangan panik jika anda menyemak kertas anda 100 kali! Meta mengeluarkan model bahasa penulisan baharu PEER: rujukan akan ditambah
- Alibaba Cloud membuka ujian model bahasa berskala besar 'Tongyi Qianwen'
- CTO Baidu Wang Haifeng: Model bahasa besar membawa fajar kecerdasan buatan umum