
Rumah >Peranti teknologi >AI >Model besar berbilang modal pertama Yuanxiang XVERSE-V ialah sumber terbuka, menyegarkan senarai model besar berwibawa, dan menyokong sebarang input nisbah aspek
Model besar berbilang modal pertama Yuanxiang XVERSE-V ialah sumber terbuka, menyegarkan senarai model besar berwibawa, dan menyokong sebarang input nisbah aspek

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-04-28 16:43:08803semak imbas
83% daripada maklumat yang diperoleh manusia berasal daripada penglihatan Model grafik dan teks berbilang modal yang besar boleh melihat maklumat dunia sebenar yang lebih kaya dan lebih tepat, membina kecerdasan kognitif yang lebih komprehensif, dan dengan itu mengambil langkah yang lebih besar ke arah AGI (Kecerdasan Am Buatan). .
Yuanxiang hari ini mengeluarkan model besar berbilang mod XVERSE-V, yang menyokong input imej dengan sebarang nisbah aspek dan mendahului dalam penilaian arus perdana. Model ini adalah sumber terbuka sepenuhnya dan percuma tanpa syarat untuk kegunaan komersial, dan terus mempromosikan R&D dan inovasi aplikasi sebilangan besar perusahaan kecil dan sederhana, penyelidik dan pembangun.  XVERSE-V mempunyai prestasi cemerlang, mengatasi model sumber terbuka seperti Yi-VL-34B, OmniLMM-12B pintar menghadap dinding dan DeepSeek-VL-7B dalam pelbagai penilaian berbilang modal yang berwibawa, dan dalam penilaian keupayaan komprehensif MBench Ia melebihi model sumber tertutup yang terkenal seperti Google GeminiProVision, Alibaba Qwen-VL-Plus dan Claude-3V Sonnet.
XVERSE-V mempunyai prestasi cemerlang, mengatasi model sumber terbuka seperti Yi-VL-34B, OmniLMM-12B pintar menghadap dinding dan DeepSeek-VL-7B dalam pelbagai penilaian berbilang modal yang berwibawa, dan dalam penilaian keupayaan komprehensif MBench Ia melebihi model sumber tertutup yang terkenal seperti Google GeminiProVision, Alibaba Qwen-VL-Plus dan Claude-3V Sonnet. 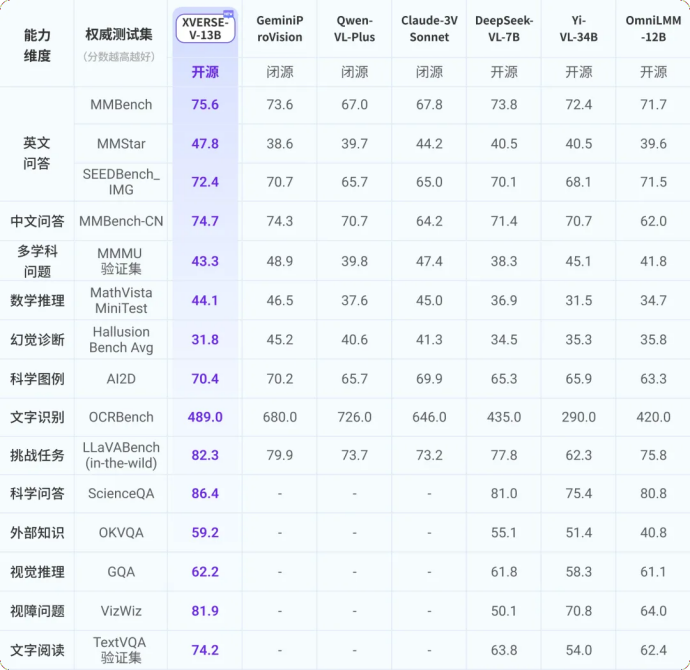 Rajah. Penilaian menyeluruh model besar berbilang mod
Rajah. Penilaian menyeluruh model besar berbilang mod
Gabungan perwakilan imej definisi tinggi global dan tempatan
Perwakilan imej model berbilang mod tradisional hanya mempunyai keseluruhannya, XVERSE-V secara inovatif mengguna pakai strategi penyepaduan keseluruhan dan bahagian , menyokong memasukkan imej dengan sebarang nisbah aspek. Dengan mengambil kira maklumat gambaran keseluruhan global dan maklumat terperinci setempat, ia boleh mengenal pasti dan menganalisis ciri halus dalam imej, melihat dengan lebih jelas dan memahami dengan lebih tepat. E Nota: Concate* menunjukkan bahawa kaedah pemprosesan dilakukan mengikut lajur 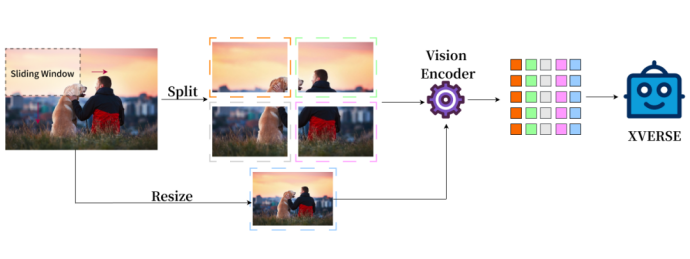
 Model boleh digunakan dalam pelbagai bidang, termasuk pengecaman peta panorama, imej satelit dan analisis pengimbasan peninggalan budaya purba.
Model boleh digunakan dalam pelbagai bidang, termasuk pengecaman peta panorama, imej satelit dan analisis pengimbasan peninggalan budaya purba.

 Muat turun percuma model besar
Muat turun percuma model besar
•Muka Berpeluk: https://huggingface.co/xverse/XVERSE-V-13B
:ModelScope ://modelscope.cn/models/xverse/XVERSE-V-13B•Github: https://github.com/xverse-ai/XVERSE-V-13B•Untuk pertanyaan, sila hantar: opensource@xverse .cnYuanxiang terus membina penanda aras sumber terbuka domestik, dengansumber terbuka terawal di China dengan parameter maksimum 65B
, sumber terbuka terawal di dunia dengan konteks terpanjang 256K, dan MoEnternational canggih model, dan menerajui negara dalam penilaian SuperCLUE. Pelancaran model KPM kali ini mengisi jurang dalam sumber terbuka domestik dan melonjakkannya ke peringkat terkemuka antarabangsa. Dari segi aplikasi komersial, model besar Yuanxiang adalah salah satu model pertama di Guangdong yang mendapat pendaftaran negara, dan boleh menyediakan perkhidmatan kepada seluruh masyarakat. Model Besar Yuanxiang telah menjalankan kerjasama dan penerokaan aplikasi yang mendalam dengan beberapa produk Tencent sejak tahun lepas, termasuk
QQ Music, Huya Live, Karaoke Nasional, Tencent Cloud, dll., untuk mencipta produk inovatif dan terkemuka untuk bidang tersebut. budaya, hiburan, pelancongan dan pengalaman pengguna. Prestasi cemerlang dalam aplikasi praktikal berbilang arah
Model ini bukan sahaja berprestasi baik dalam keupayaan asas, tetapi juga berprestasi baik dalam senario aplikasi sebenar. Mempunyai keupayaan untuk memahami dalam senario yang berbeza dan dapat mengendalikan keperluan yang berbeza seperti grafik maklumat, dokumen, senario kehidupan sebenar, soalan matematik, dokumen saintifik, penukaran kod, dsb. •
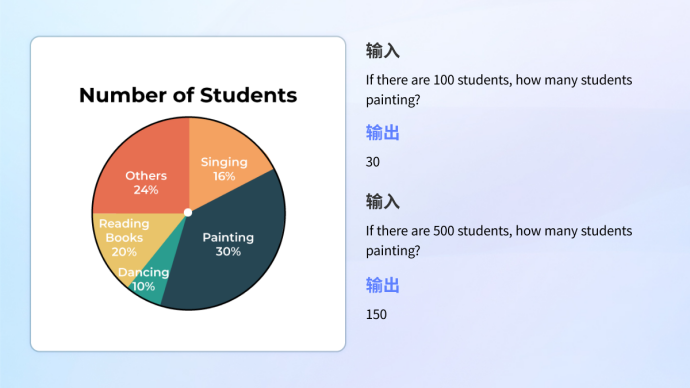
Carta pemahamanSama ada pemahaman grafik maklumat yang menggabungkan grafik dan teks yang kompleks, atau analisis dan pengiraan carta tunggal, model boleh mengendalikannya dengan mudah. 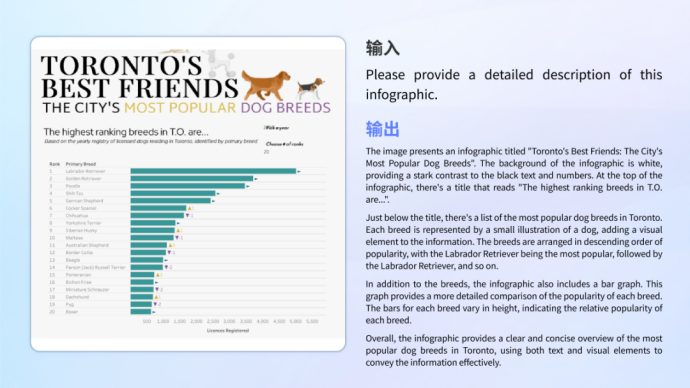
•Adegan sebenar cacat penglihatan
Dalam set ujian adegan cacat penglihatan sebenar VizWiz, XVERSE-V menunjukkan prestasi yang baik, mengatasi hampir semua sumber terbuka arus perdana seperti InternVL-Chat-V1.5 dan DeepSeek-VL 7B Multimodal model besar. Set ujian ini mengandungi lebih daripada 31,000 soalan dan jawapan visual daripada pengguna cacat penglihatan sebenar, yang boleh menggambarkan dengan tepat keperluan sebenar dan masalah remeh pengguna, dan membantu orang cacat penglihatan mengatasi cabaran visual sebenar harian mereka.测试 Contoh ujian Vizwiz 
• •
Xverse-V mempunyai keupayaan berbilang modal sambil mengekalkan keupayaan penjanaan teks yang kukuh.

Penyelesaian Masalah Pendidikan
Model ini mempunyai pelbagai rizab pengetahuan dan keupayaan penaakulan logik, dan boleh mengenali imej untuk menjawab soalan dalam disiplin yang berbeza.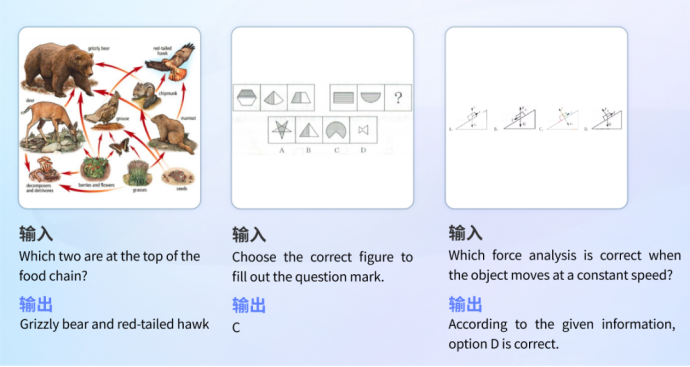
Jawapan Ensiklopedia
Model ini menyimpan pengetahuan tentang pelbagai topik seperti sejarah, budaya, teknologi dan keselamatan.
Penulisan kod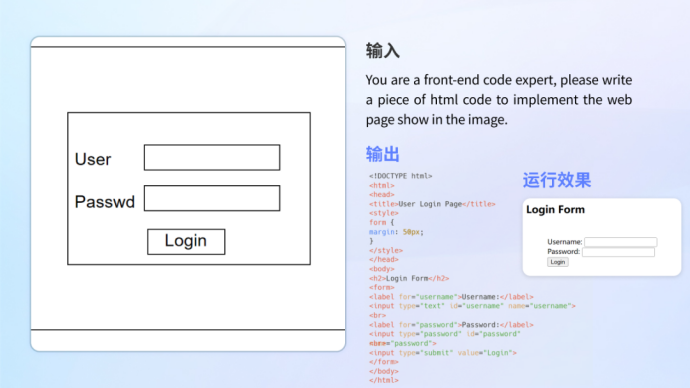
Pemandu autonomi
Pemahaman dan pengiktirafan emosi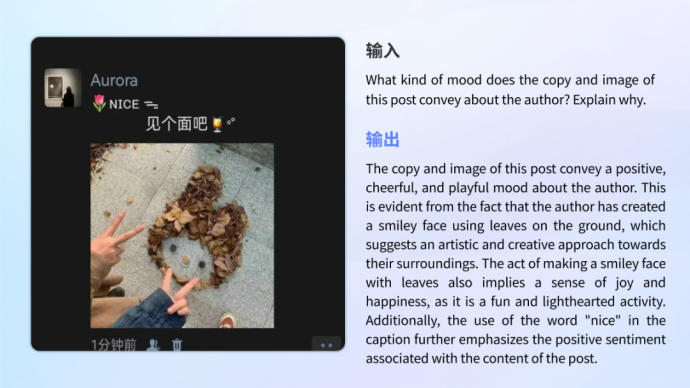
Atas ialah kandungan terperinci Model besar berbilang modal pertama Yuanxiang XVERSE-V ialah sumber terbuka, menyegarkan senarai model besar berwibawa, dan menyokong sebarang input nisbah aspek. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!