
Rumah >Peranti teknologi >AI >Yan Shuicheng mengambil alih dan menubuhkan bentuk muktamad 'model besar multi-modal visual universal'! Pemahaman/penjanaan/segmentasi/penyuntingan bersatu
Yan Shuicheng mengambil alih dan menubuhkan bentuk muktamad 'model besar multi-modal visual universal'! Pemahaman/penjanaan/segmentasi/penyuntingan bersatu

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-04-25 20:04:151183semak imbas
Baru-baru ini, Profesor Yan Shuicheng's team Secara bersama mengeluarkan dan sumber terbuka model bahasa besar berbilang mod visual peringkat piksel universal Vitron.

Laman Utama Projek & Demo: . 72f117 9835987f9028c4cc4df
kod sumber terbuka :https://www.php.cn/link/26d6e896db39edc7d7bdd357d6984c95 Ini ialah model besar multimodal visual am tugas berat yang menyokong daripada Satu siri tugasan visual daripada pemahaman visual kepada penjanaan visual, daripada tahap rendah kepada tahap tinggi, menyelesaikan masalah pemisahan model imej/video yang telah melanda industri model bahasa besar untuk masa yang lama, dan menyediakan pemahaman yang komprehensif dan bersatu dan penjanaan imej statik dan kandungan video dinamik Model besar berbilang mod visual tujuan am peringkat piksel untuk tugasan seperti , pembahagian dan penyuntingan meletakkan asas untuk bentuk muktamad model besar visual tujuan am generasi seterusnya. , dan juga menandakan satu lagi langkah besar ke arah kecerdasan buatan am (AGI) untuk model besar.
Vitron, sebagai model bahasa besar berbilang mod visual peringkat piksel bersatu, mencapai sokongan menyeluruh untuk tugas visual dari peringkat rendah ke peringkat tinggi, boleh mengendalikan tugas visual yang kompleks, dan memahami serta menjana imej dan kandungan video, memberikan pemahaman visual yang kuat dan keupayaan pelaksanaan tugas. Pada masa yang sama, Vitron menyokong operasi berterusan dengan pengguna, membolehkan interaksi manusia-komputer yang fleksibel, menunjukkan potensi besar ke arah model universal multimodal visual yang lebih bersatu.
Kertas kerja, kod dan tunjuk cara berkaitan Vitron semuanya telah didedahkan kepada umum Kelebihan dan potensi uniknya dari segi kelengkapan, inovasi teknologi, interaksi manusia-komputer dan potensi aplikasi bukan sahaja mempromosikan pelbagai mod. pembangunan model besar juga menyediakan hala tuju baharu untuk penyelidikan model besar visual masa hadapan.
Perkembangan semasa model bahasa besar visual (LLM) telah mencapai kemajuan yang memuaskan. Masyarakat semakin percaya bahawa membina model besar multimodal (MLLM) yang lebih umum dan berkuasa akan menjadi satu-satunya cara untuk mencapai kecerdasan buatan am (AGI). Walau bagaimanapun, masih terdapat beberapa cabaran utama dalam proses menuju ke arah model umum pelbagai modal (Generalis). Sebagai contoh, sebahagian besar kerja tidak mencapai pemahaman visual tahap piksel yang terperinci atau tidak mempunyai sokongan bersatu untuk imej dan video. Atau sokongan untuk pelbagai tugas visual tidak mencukupi, dan ia jauh dari model besar sejagat. Untuk mengisi jurang ini, pasukan baru-baru ini bersama-sama mengeluarkan model bahasa besar berbilang mod visual peringkat piksel universal peringkat piksel Vitron sumber terbuka. Vitron menyokong satu siri tugas visual daripada pemahaman visual kepada penjanaan visual, daripada tahap rendah kepada tahap tinggi, termasuk pemahaman komprehensif, penjanaan, pembahagian dan penyuntingan imej statik dan kandungan video dinamik.
Angka di atas secara komprehensif menggambarkan sokongan fungsi Vitron untuk empat tugas utama berkaitan penglihatan, serta kelebihan utamanya. Vitron juga menyokong operasi berterusan dengan pengguna untuk mencapai interaksi manusia-komputer yang fleksibel. Projek ini menunjukkan potensi besar untuk model am berbilang modal penglihatan yang lebih bersatu, meletakkan asas bagi bentuk muktamad model besar penglihatan am generasi seterusnya.
Kertas, kod dan tunjuk cara berkaitan Vitron kini semuanya terbuka.
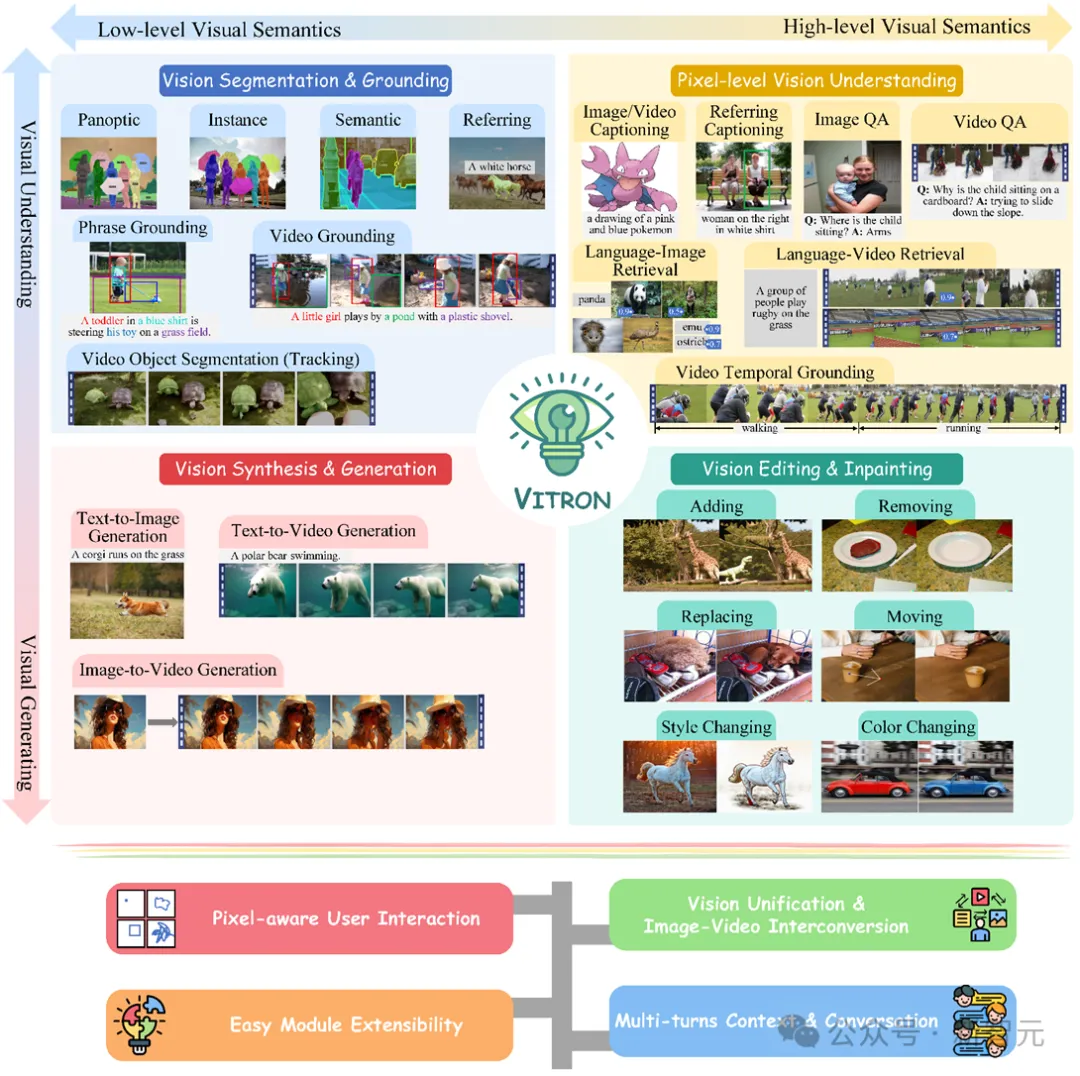
Model bahasa besar multi-modal bersatu muktamad
Dalam beberapa tahun kebelakangan ini, model bahasa besar (LLM) telah menunjukkan keupayaan berkuasa yang belum pernah berlaku sebelum ini, dan ia telah disahkan secara beransur-ansur sebagai laluan teknikal ke AGI. Model bahasa besar multimodal (MLLM) berkembang pesat dalam banyak komuniti dan muncul dengan pantas Dengan memperkenalkan modul yang boleh melakukan persepsi visual, LLM berasaskan bahasa tulen diperluaskan kepada MLLM yang hebat dan cemerlang dalam pemahaman imej. seperti BLIP-2, LLaVA, MiniGPT-4, dsb. Pada masa yang sama, MLLM yang memfokuskan pada pemahaman video juga telah dilancarkan, seperti VideoChat, Video-LLaMA, Video-LLaVA, dsb.
Seterusnya, penyelidik terutamanya cuba mengembangkan lagi keupayaan MLLM daripada dua dimensi. Di satu pihak, penyelidik cuba mendalami pemahaman MLLM tentang penglihatan, beralih daripada pemahaman peringkat contoh kasar kepada pemahaman terperinci imej peringkat piksel, dengan itu mencapai keupayaan kedudukan wilayah visual (Pembuatan Serantau), seperti GLaMM, PixelLM , NExT-Chat dan MiniGPT-v2 dsb.
Sebaliknya, penyelidik cuba mengembangkan fungsi visual yang boleh disokong oleh MLLM. Beberapa penyelidikan telah mula mengkaji bagaimana MLLM bukan sahaja memahami isyarat visual input, tetapi juga menyokong penjanaan kandungan visual output. Contohnya, MLLM seperti GILL dan Emu boleh menjana kandungan imej secara fleksibel, dan GPT4Video dan NExT-GPT merealisasikan penjanaan video.
Pada masa ini, komuniti kecerdasan buatan telah secara beransur-ansur mencapai kata sepakat bahawa trend masa depan MLLM visual pasti akan berkembang ke arah keupayaan yang sangat bersatu dan lebih kukuh. Walau bagaimanapun, walaupun terdapat banyak MLLM yang dibangunkan oleh komuniti, jurang yang jelas masih wujud.
1 Hampir semua LLM visual sedia ada menganggap imej dan video sebagai entiti yang berbeza dan sama ada hanya menyokong imej atau video sahaja.
Penyelidik menyokong bahawa penglihatan harus merangkumi kedua-dua imej statik dan video dinamik - kedua-duanya adalah komponen teras dunia visual dan malah boleh ditukar ganti dalam kebanyakan senario. Oleh itu, adalah perlu untuk membina rangka kerja MLLM bersatu yang boleh menyokong modaliti imej dan video.
2 Pada masa ini, sokongan MLLM untuk fungsi visual masih tidak mencukupi.
Kebanyakan model hanya mampu memahami, atau paling banyak menghasilkan imej atau video. Penyelidik percaya bahawa MLLM masa depan haruslah model bahasa besar umum yang boleh merangkumi rangkaian tugas dan operasi visual yang lebih luas, mencapai sokongan bersatu untuk semua tugas berkaitan penglihatan dan mencapai keupayaan "satu untuk semua". Ini penting untuk aplikasi praktikal, terutamanya dalam penciptaan visual yang selalunya melibatkan satu siri operasi berulang dan interaktif.
Sebagai contoh, pengguna biasanya mula-mula mula dengan teks dan menukar idea kepada kandungan visual melalui gambar rajah Vincent kemudian menambah butiran melalui penyuntingan imej yang lebih halus dan kemudian menghasilkan video melalui imej kandungan dinamik; akhirnya, lakukan beberapa pusingan interaksi berulang, seperti penyuntingan video, untuk memperhalusi penciptaan.
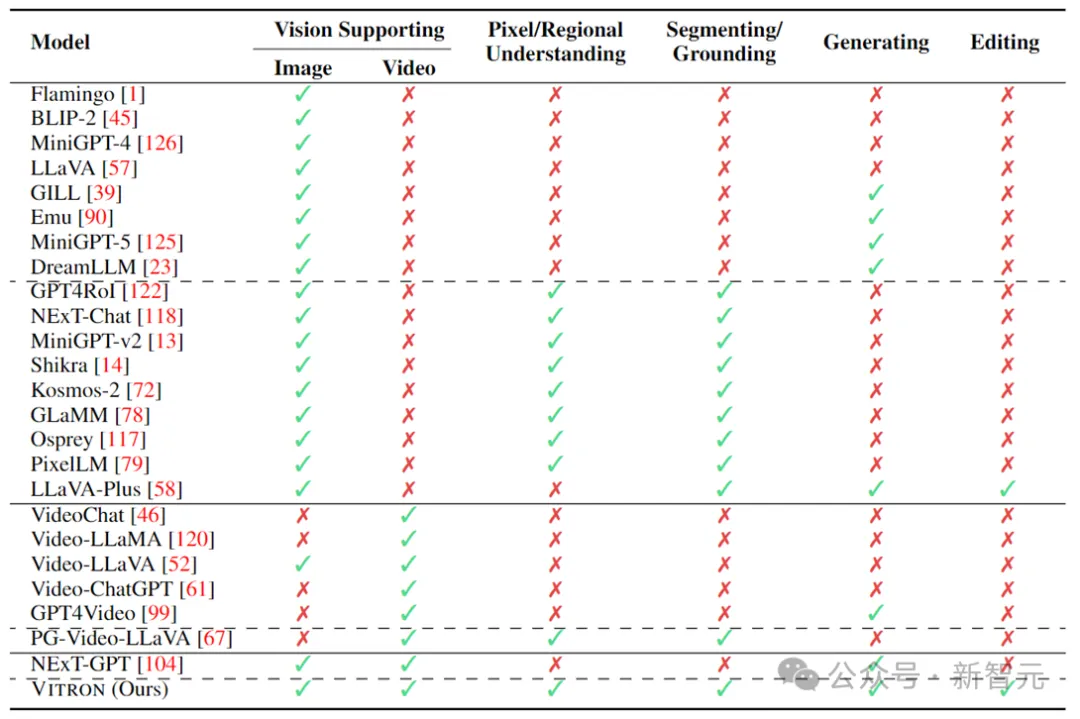
Jadual di atas hanya meringkaskan keupayaan MLLM visual sedia ada (hanya mewakili beberapa model dan liputan tidak lengkap). Untuk merapatkan jurang ini, pasukan mencadangkan Vitron, MLLM visual peringkat piksel umum.
Seni bina sistem Vitron: tiga modul utama
Rangka kerja keseluruhan Vitron ditunjukkan dalam rajah di bawah. Vitron menggunakan seni bina yang serupa dengan MLLM berkaitan sedia ada, termasuk tiga bahagian penting: 1) modul pengekodan visual & bahasa bahagian hadapan, 2) modul pemahaman dan penjanaan teks LLM pusat, dan 3) respons pengguna dan panggilan modul belakang untuk kawalan visual modul.
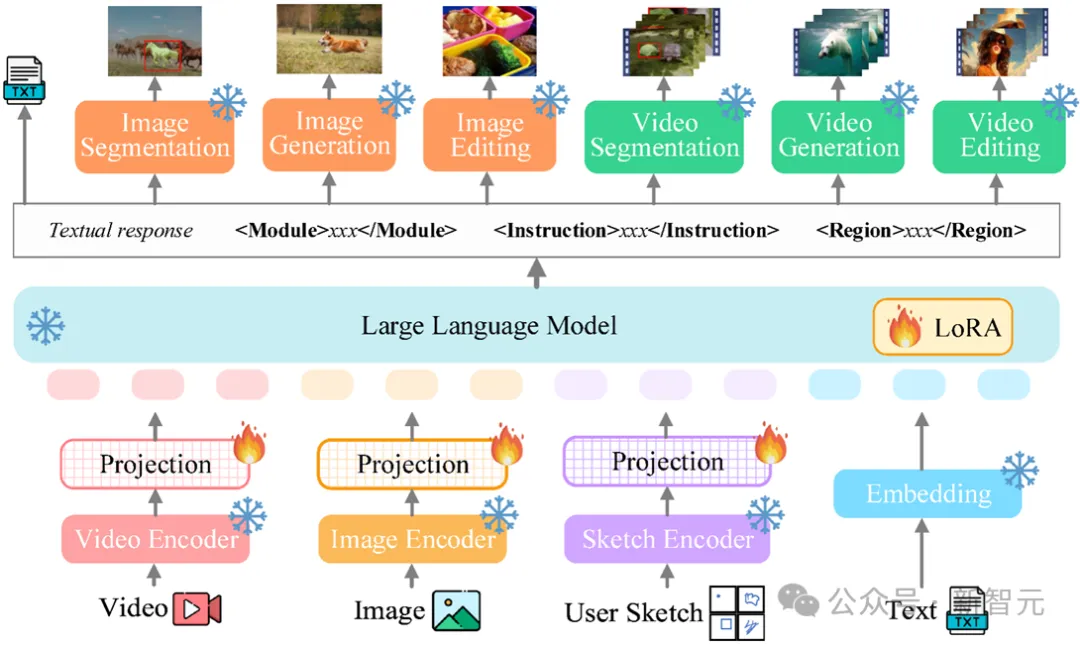
Modul bahagian hadapan: Pengekodan Visual-Linguistik
Untuk melihat imej dan isyarat mod video, encoder video pengguna dan menyokong imej input yang disisipkan halus Pengekod kotak/lakaran wilayah.
Modul pusat: Teras LLM
Vitron menggunakan Vicuna (7B, v1.5) untuk mencapai pemahaman, penaakulan, membuat keputusan dan pelbagai pusingan interaksi pengguna.
Modul belakang: Respons pengguna dan panggilan modul
Vitron mengguna pakai strategi panggilan tertumpu teks dan menyepadukan beberapa imej luar rak (SoTA) yang berkuasa dan canggih untuk modul pemprosesan imej dan video melaksanakan pelbagai tugas terminal visual dari tahap rendah hingga tinggi. Dengan mengguna pakai kaedah panggilan penyepaduan modul bertumpu teks, Vitron bukan sahaja mencapai penyatuan sistem, tetapi juga memastikan kecekapan penjajaran dan kebolehskalaan sistem.
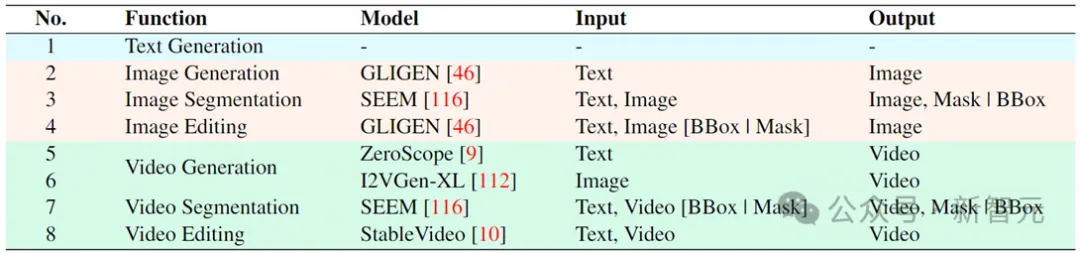
Tiga peringkat utama latihan model Vitron
Berdasarkan seni bina di atas, Vitron dilatih dan diperhalusi untuk memberikan pemahaman visual yang kuat dan keupayaan pelaksanaan tugas. Latihan model terutamanya merangkumi tiga peringkat berbeza.
Langkah 1: Pembelajaran penjajaran keseluruhan visual-verbal. Ciri bahasa visual input dipetakan ke dalam ruang ciri bersatu, dengan itu membolehkannya memahami isyarat berbilang modal input dengan berkesan. Ini ialah pembelajaran penjajaran visual-linguistik berbutir kasar yang membolehkan sistem memproses isyarat visual masuk secara keseluruhan secara berkesan. Para penyelidik menggunakan pasangan kapsyen imej (CC3M), pasangan kapsyen video (Webvid) dan pasangan kapsyen wilayah (RefCOCO) sedia ada untuk latihan.
Langkah 2: Arahan penentuan kedudukan visual spatiotemporal berbutir halus. Sistem ini menggunakan modul luaran untuk melaksanakan pelbagai tugas visual tahap piksel, tetapi LLM sendiri tidak menjalani latihan visual yang terperinci, yang akan menghalang sistem daripada mencapai pemahaman visual tahap piksel sebenar. Untuk tujuan ini, penyelidik mencadangkan latihan penalaan halus arahan kedudukan visual spatiotemporal yang halus Idea terasnya adalah untuk membolehkan LLM mencari ruang butiran halus imej dan ciri temporal khusus video.
Langkah 3: Perhalusi hujung output pada panggilan arahan. Peringkat kedua latihan yang diterangkan di atas memberikan LLM dan pengekod bahagian hadapan keupayaan untuk memahami penglihatan pada tahap piksel. Langkah terakhir ini, penalaan halus arahan untuk seruan perintah, bertujuan untuk melengkapkan sistem dengan keupayaan untuk melaksanakan arahan dengan tepat, membolehkan LLM menjana teks seruan yang sesuai dan betul. Memandangkan tugas penglihatan terminal yang berbeza mungkin memerlukan arahan panggilan yang berbeza, untuk menyatukan ini, penyelidik mencadangkan untuk menyeragamkan output respons LLM ke dalam format teks berstruktur, yang termasuk:
1) Output respons pengguna, balas terus kepada Masukkan pengguna
2) Nama modul untuk menunjukkan fungsi atau tugas yang akan dilaksanakan.
3) Panggil arahan untuk mencetuskan meta-arahan modul tugas.
4) Rantau (output pilihan) yang menentukan ciri visual berbutir halus yang diperlukan untuk tugas tertentu, seperti dalam penjejakan video atau pengeditan visual, di mana modul hujung belakang memerlukan maklumat ini. Untuk wilayah, berdasarkan pemahaman tahap piksel LLM, kotak sempadan yang diterangkan mengikut koordinat akan dikeluarkan.
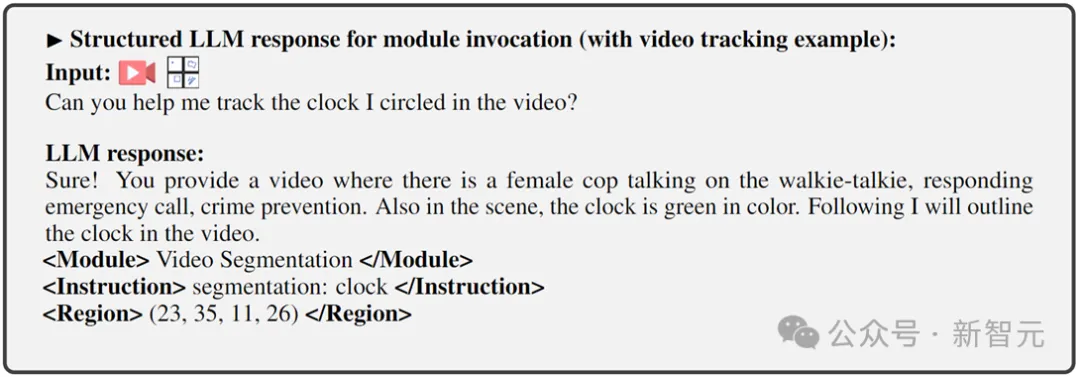
Eksperimen penilaian
Penyelidik menjalankan penilaian percubaan yang meluas ke atas 22 set data penanda aras biasa dan 12 tugas penglihatan imej/video berdasarkan Vitron. Vitron menunjukkan keupayaan kukuh dalam empat kumpulan tugas visual utama (segmentasi, pemahaman, penjanaan kandungan dan penyuntingan), sementara pada masa yang sama ia mempunyai keupayaan interaksi manusia-komputer yang fleksibel. Berikut secara perwakilan menunjukkan beberapa hasil perbandingan kualitatif:
Pembahagian Penglihatan
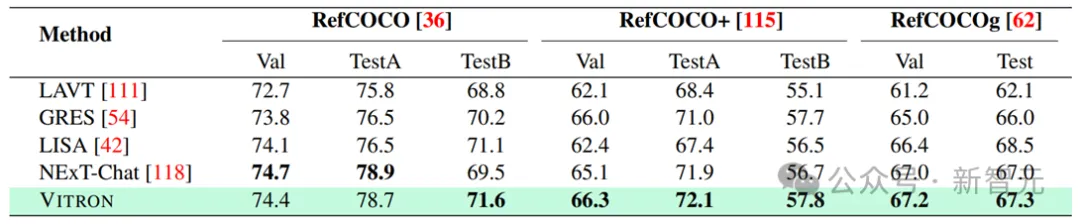
Keputusan pembahagian imej yang merujuk imej
Fiksi Under

Keputusan daripada kefahaman ungkapan merujuk imej.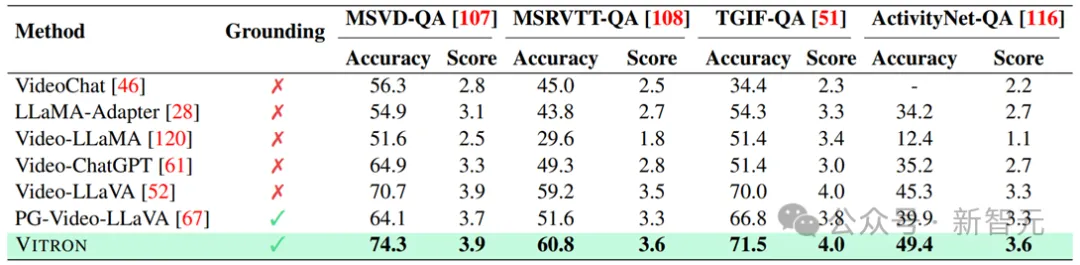
Keputusan pada QA video - kepada-Penjanaan video
Pengeditan Penglihatan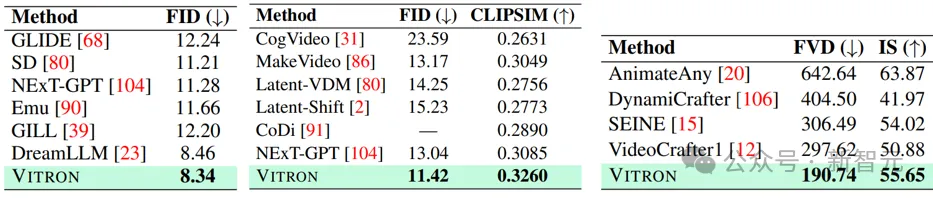
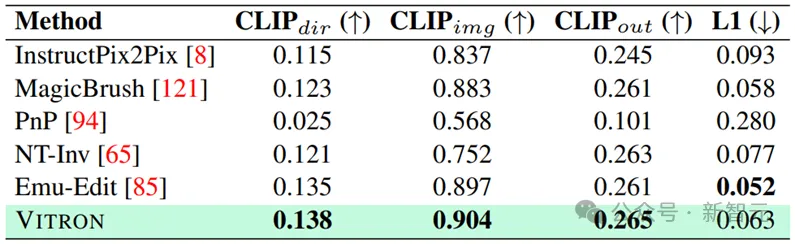 hasil pengeditan.
hasil pengeditan.
Sila rujuk kertas untuk kandungan dan butiran eksperimen yang lebih terperinci.
Future Direction Outlook
En général, ce travail démontre le grand potentiel du développement d'un grand modèle général visuel multimodal unifié, établissant une nouvelle forme pour la prochaine génération de recherche sur les grands modèles visuels et franchissant cette direction. Bien que le système Vitron proposé par l’équipe présente de fortes capacités générales, il présente néanmoins ses propres limites. Les chercheurs suivants énumèrent quelques pistes qui pourraient être explorées davantage à l’avenir.
Architecture système
Le système Vitron utilise toujours une approche semi-union, semi-agent pour appeler des outils externes. Bien que cette méthode basée sur les appels facilite l'expansion et le remplacement de modules potentiels, cela signifie également que les modules back-end de cette structure de pipeline ne participent pas à l'apprentissage conjoint des modules front-end et de base LLM.
Cette limitation n'est pas propice à l'apprentissage global du système, ce qui signifie que la limite supérieure de performance des différentes tâches visuelles sera limitée par le module back-end. Les travaux futurs devraient intégrer divers modules de tâches de vision dans une unité unifiée. Parvenir à une compréhension et une production unifiées d’images et de vidéos tout en prenant en charge les capacités de génération et d’édition via un paradigme génératif unique reste un défi. Actuellement, une approche prometteuse consiste à combiner la tokenisation persistante en termes de modularité pour améliorer l'unification du système sur différentes entrées et sorties et diverses tâches.
Interactivité utilisateur
Contrairement aux modèles précédents qui se concentraient sur une tâche à vision unique (par exemple, Stable Diffusion et SEEM), Vitron vise à faciliter une interaction profonde entre LLM et les utilisateurs, similaire à l'industrie au sein du DALL d'OpenAI. -Série E, Midjourney, etc. Atteindre une interactivité utilisateur optimale est l’un des objectifs principaux de ce travail.
Vitron exploite le LLM basé sur la langue existante, combiné à des ajustements pédagogiques appropriés pour atteindre un certain niveau d'interactivité. Par exemple, le système peut répondre de manière flexible à tout message attendu saisi par l'utilisateur et produire des résultats d'opération visuels correspondants sans exiger que l'entrée de l'utilisateur corresponde exactement aux conditions du module principal. Cependant, ce travail présente encore de nombreuses marges d'amélioration en termes de renforcement de l'interactivité. Par exemple, en s'inspirant du système Midjourney à source fermée, quelle que soit la décision prise par LLM à chaque étape, le système doit fournir activement des commentaires aux utilisateurs pour garantir que ses actions et décisions sont cohérentes avec les intentions des utilisateurs.
Capacités modales
Actuellement, Vitron intègre un modèle 7B Vicuna, qui peut avoir certaines limitations sur sa capacité à comprendre le langage, les images et les vidéos. Les orientations futures de l'exploration pourraient consister à développer un système complet de bout en bout, par exemple en élargissant l'échelle du modèle pour parvenir à une compréhension plus approfondie et plus complète de la vision. En outre, des efforts devraient être faits pour permettre au LLM d’unifier pleinement la compréhension des modalités de l’image et de la vidéo.
Atas ialah kandungan terperinci Yan Shuicheng mengambil alih dan menubuhkan bentuk muktamad 'model besar multi-modal visual universal'! Pemahaman/penjanaan/segmentasi/penyuntingan bersatu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Git如何查看远程仓库地址
- git常用的六个命令是什么
- Apakah standard ieee802 membahagikan model hierarki rangkaian kawasan tempatan
- Syorkan perisian penyuntingan video percuma
- Bagaimana untuk menetapkan VideoStudio x10 untuk memasuki antara muka penyuntingan video apabila ia bermula - Bagaimana untuk menetapkan VideoStudio x10 untuk memasuki antara muka penyuntingan video apabila ia bermula