
Rumah >Peranti teknologi >AI >Google mengambil tindakan untuk membetulkan 'amnesia' model besar! Mekanisme perhatian maklum balas membantu anda 'mengemas kini' konteks, dan era memori tanpa had untuk model besar akan datang.
Google mengambil tindakan untuk membetulkan 'amnesia' model besar! Mekanisme perhatian maklum balas membantu anda 'mengemas kini' konteks, dan era memori tanpa had untuk model besar akan datang.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-04-17 15:40:01532semak imbas
Editor |. Yi Feng
Dihasilkan oleh 51CTO Technology Stack (WeChat ID: blog51cto)
Google akhirnya mengambil tindakan! Kami tidak lagi mengalami "amnesia" model besar.
TransformerFAM dilahirkan, berjanji untuk menjadikan model besar mempunyai memori tanpa had!
Tanpa berlengah lagi, mari kita lihat "keberkesanan" TransformerFAM:
 Gambar
Gambar
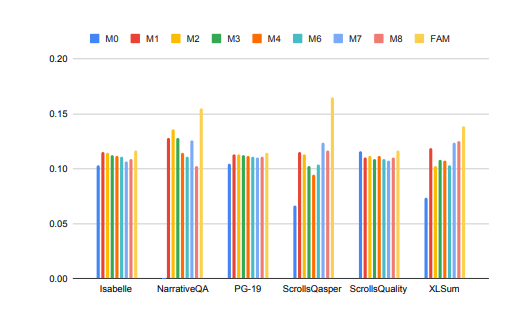
Prestasi model besar dalam memproses tugas konteks panjang telah dipertingkatkan dengan ketara!
Dalam gambar di atas, tugasan seperti Isabelle dan NarrativeQA memerlukan model untuk memahami dan memproses sejumlah besar maklumat kontekstual dan memberikan jawapan atau ringkasan yang tepat kepada soalan khusus. Dalam semua tugas, model yang dikonfigurasikan dengan FAM mengatasi semua konfigurasi BSWA yang lain, dan dapat dilihat bahawa di luar satu titik tertentu, peningkatan bilangan segmen memori BSWA tidak dapat terus meningkatkan keupayaan ingatannya.
Nampaknya dalam perjalanan ke teks panjang dan perbualan panjang, "tidak dapat dilupakan" FAM, model besar, memang ada sesuatu.
Penyelidik Google memperkenalkan FAM, seni bina Transformer novel - Memori Perhatian Maklum Balas. Ia menggunakan gelung maklum balas untuk membolehkan rangkaian memberi perhatian kepada prestasi driftnya sendiri, menggalakkan kemunculan memori kerja dalaman Transformer, dan membolehkannya mengendalikan jujukan yang sangat panjang.
Ringkasnya, strategi ini agak serupa dengan strategi kami untuk memerangi "amnesia" model besar secara buatan: masukkan gesaan sekali lagi sebelum setiap perbualan dengan model besar. Cuma pendekatan FAM lebih maju Apabila model memproses blok data baharu, ia akan menggunakan maklumat yang diproses sebelum ini (iaitu, FAM) sebagai konteks yang dikemas kini secara dinamik dan menyepadukannya ke dalam proses pemprosesan semasa semula.
Dengan cara ini, anda boleh menangani masalah "melupakan perkara" dengan baik. Lebih baik lagi, walaupun terdapat pengenalan mekanisme maklum balas untuk mengekalkan ingatan kerja jangka panjang, FAM direka untuk mengekalkan keserasian dengan model pra-latihan tanpa memerlukan pemberat tambahan. Jadi secara teori, ingatan berkuasa model besar tidak menjadikannya membosankan atau menggunakan lebih banyak sumber pengkomputeran.
Jadi, bagaimana TransformerFAM yang begitu hebat ditemui? Apakah teknologi yang berkaitan?
1 Dari cabaran itu, mengapa TransformerFAM boleh membantu model besar "ingat lebih"?
Konsep Sliding Window Attention (SWA) adalah penting kepada reka bentuk TransformerFAM.
Dalam model Transformer tradisional, kerumitan perhatian diri meningkat secara kuadratik apabila panjang jujukan meningkat, yang mengehadkan keupayaan model untuk mengendalikan jujukan panjang.
“Dalam filem Memento (2000), watak utama mengalami amnesia anterograde, yang bermaksud dia tidak dapat mengingati apa yang berlaku dalam tempoh 10 minit yang lalu, tetapi ingatan jangka panjangnya masih utuh dan dia perlu Melukis maklumat penting pada badan. untuk mengingati mereka adalah serupa dengan keadaan semasa model bahasa besar (LLM)," tulis kertas itu.
 Tangkapan skrin daripada filem "Memento", gambar-gambar itu datang dari Internet
Tangkapan skrin daripada filem "Memento", gambar-gambar itu datang dari Internet
Perhatian Tetingkap Gelongsor (Perhatian Tetingkap Gelongsor), ia adalah mekanisme perhatian yang dipertingkatkan untuk memproses data urutan panjang. Ia diilhamkan oleh teknik tingkap gelongsor dalam sains komputer. Apabila berurusan dengan tugas pemprosesan bahasa semula jadi (NLP), SWA membenarkan model memfokuskan hanya pada tetingkap bersaiz tetap bagi urutan input pada setiap langkah masa, dan bukannya keseluruhan jujukan. Oleh itu, kelebihan SWA ialah ia dapat mengurangkan usaha pengiraan dengan ketara.
 Gambar
Gambar
Tetapi SWA mempunyai had kerana rentang perhatiannya terhad oleh saiz tetingkap, yang mengakibatkan model tidak dapat mempertimbangkan maklumat penting di luar tingkap.
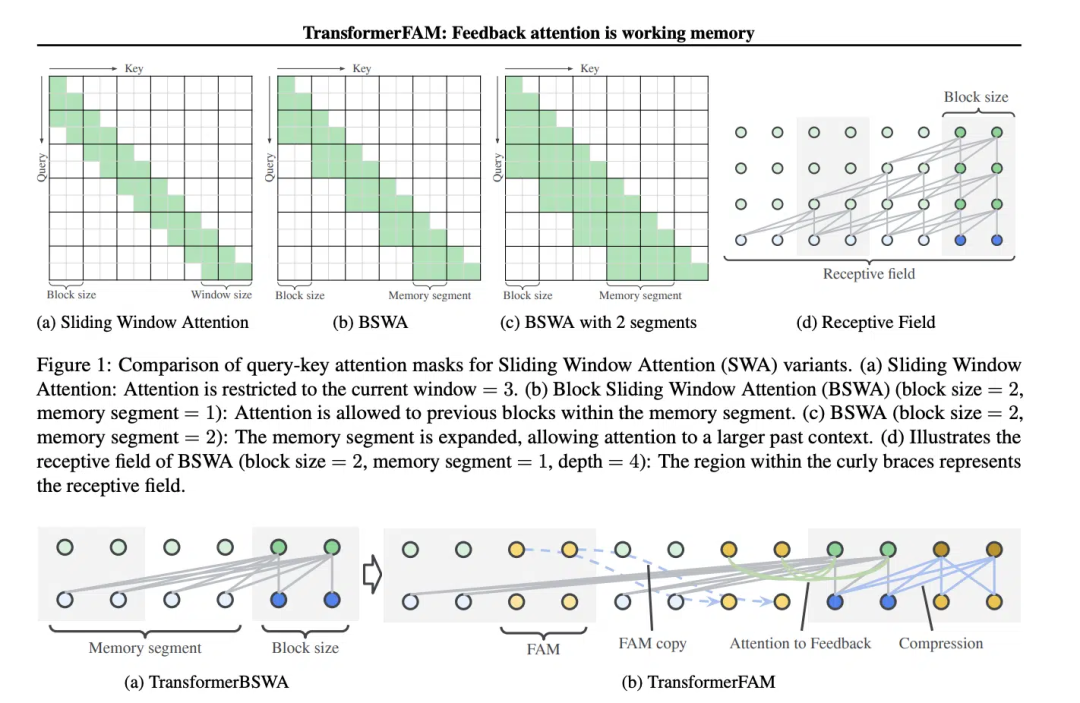
TransformerFAM mencapai perhatian bersepadu, kemas kini peringkat blok, pemampatan maklumat dan storan konteks global dengan menambahkan pengaktifan maklum balas untuk memasukkan semula perwakilan konteks ke dalam setiap blok perhatian tetingkap gelongsor.
Dalam TransformerFAM, penambahbaikan dicapai melalui gelung maklum balas. Khususnya, apabila memproses blok jujukan semasa, model bukan sahaja memfokuskan pada elemen dalam tetingkap semasa, tetapi juga memperkenalkan semula maklumat kontekstual yang telah diproses sebelum ini (iaitu, "pengaktifan maklum balas") sebelumnya ke dalam mekanisme perhatian sebagai input tambahan. Dengan cara ini, walaupun tetingkap perhatian model meluncur ke atas jujukan, ia dapat mengekalkan ingatan dan pemahaman maklumat sebelumnya.
Jadi, selepas penambahbaikan ini, TransformerFAM memberi LLM potensi untuk mengendalikan urutan panjang yang tidak terhingga!
Kedua, dengan model memori kerja yang besar, terus bergerak ke arah AGI
TransformerFAM telah menunjukkan prospek positif dalam penyelidikan, yang sudah pasti akan meningkatkan prestasi AI dalam memahami dan menjana tugasan teks yang panjang, seperti pemprosesan dokumen Ringkasan, penjanaan cerita , Soal Jawab dan kerja lain.
 Gambar
Gambar
Pada masa yang sama, sama ada pembantu pintar atau teman emosi, AI dengan ingatan tanpa had kedengaran lebih menarik.
Menariknya, reka bentuk TransformerFAM diilhamkan oleh mekanisme ingatan dalam biologi, yang bertepatan dengan simulasi kecerdasan semula jadi yang diusahakan oleh AGI. Kertas kerja ini adalah percubaan untuk mengintegrasikan konsep daripada neurosains—ingatan kerja berasaskan perhatian—ke dalam bidang pembelajaran mendalam.
TransformerFAM memperkenalkan memori kerja ke dalam model besar melalui gelung maklum balas, membolehkan model itu bukan sahaja mengingati maklumat jangka pendek, tetapi juga mengekalkan ingatan maklumat penting dalam urutan jangka panjang.
Melalui imaginasi yang berani, penyelidik mencipta jambatan antara dunia sebenar dan konsep abstrak. Memandangkan pencapaian inovatif seperti TransformerFAM terus muncul, kesesakan teknologi akan ditembusi lagi dan lagi, dan masa depan yang lebih bijak dan saling berkait perlahan-lahan berlaku kepada kami.
Untuk mengetahui lebih lanjut tentang AIGC, sila layari:
51CTO AI.x Community
https://www.51cto.com/aigc/
Atas ialah kandungan terperinci Google mengambil tindakan untuk membetulkan 'amnesia' model besar! Mekanisme perhatian maklum balas membantu anda 'mengemas kini' konteks, dan era memori tanpa had untuk model besar akan datang.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 让谷歌浏览器Google Chrome支持eWebEditor的方法
- 数据库的三种数据模型分别是什么
- Apakah singkatan Forum Komuniti Pembangun Google China?
- Ketua Pegawai Eksekutif Li Auto Li Xiang secara terbuka mengakui kesilapannya: Membetulkan salah faham sistem amaran perhatian Mercedes-Benz
- Bagaimanakah saya boleh menggunakan div untuk menarik perhatian pengguna tanpa melimpahi tetingkap?