
Rumah >Peranti teknologi >AI >Prestasi larian tempatan perkhidmatan Embedding melebihi OpenAI Text-Embedding-Ada-002, yang sangat mudah!
Prestasi larian tempatan perkhidmatan Embedding melebihi OpenAI Text-Embedding-Ada-002, yang sangat mudah!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-04-15 09:01:011372semak imbas
Ollama ialah alat super praktikal yang membolehkan anda menjalankan model sumber terbuka dengan mudah seperti Llama 2, Mistral dan Gemma secara tempatan. Dalam artikel ini, saya akan memperkenalkan cara menggunakan Ollama untuk mengvektorkan teks. Jika anda tidak memasang Ollama secara tempatan, anda boleh membaca artikel ini.
Dalam artikel ini kita akan menggunakan model nomic-embed-text[2]. Ia ialah pengekod teks yang mengatasi prestasi OpenAI text-embedding-ada-002 dan text-embedding-3-small pada konteks pendek dan tugas konteks panjang.
Mulakan perkhidmatan nomic-embed-text
Selepas anda berjaya memasang ollama, gunakan arahan berikut untuk menarik model nomic-embed-text:
ollama pull nomic-embed-text
Selepas berjaya menarik model, masukkan arahan berikut dalam terminal , mulakan perkhidmatan ollama:
ollama serve
Selepas itu, kami boleh menggunakan curl untuk mengesahkan sama ada perkhidmatan benam berjalan seperti biasa:
curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text","prompt": "The sky is blue because of Rayleigh scattering"}'Gunakan perkhidmatan nomic-embed-text
Seterusnya, kami akan memperkenalkan bagaimana untuk menggunakan perkhidmatan langchainjs dan nomic -embed-text, yang melaksanakan operasi pembenaman pada dokumen txt tempatan. Proses yang sepadan ditunjukkan dalam rajah di bawah:
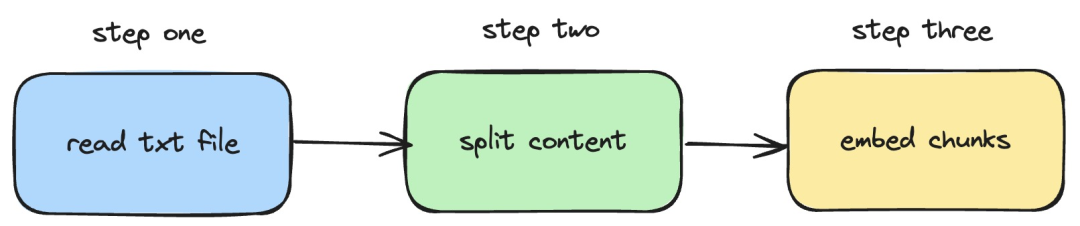 Pictures
Pictures
1 Baca fail txt setempat
import { TextLoader } from "langchain/document_loaders/fs/text";async function load(path: string) {const loader = new TextLoader(path);const docs = await loader.load();return docs;}Dalam kod di atas, kami menentukan fungsi muat, yang secara dalaman menggunakan TextLoader yang disediakan oleh langchainjs. baca Dapatkan dokumen txt tempatan.
2. Pisahkan kandungan txt kepada blok teks
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";import { Document } from "langchain/document";function split(documents: Document[]) {const splitter = new RecursiveCharacterTextSplitter({chunkSize: 500,chunkOverlap: 20,});return splitter.splitDocuments(documents);}Dalam kod di atas, kami menggunakan RecursiveCharacterTextSplitter untuk memotong teks txt yang dibaca dan menetapkan saiz setiap blok teks kepada 500.
3. Laksanakan operasi pembenaman pada blok teks
const EMBEDDINGS_URL = "http://127.0.0.1:11434/api/embeddings";async function embedding(path: string) {const docs = await load(path);const splittedDocs = await split(docs);for (let doc of splittedDocs) {const embedding = await sendRequest(EMBEDDINGS_URL, {model: "nomic-embed-text",prompt: doc.pageContent,});console.dir(embedding.embedding);}}Dalam kod di atas, kami mentakrifkan fungsi pembenaman, di mana fungsi beban dan pembahagi yang ditakrifkan sebelum ini akan dipanggil. Kemudian rentasi blok teks yang dijana dan panggil perkhidmatan pembenaman nomic-embed-text yang dimulakan secara tempatan. Fungsi sendRequest digunakan untuk menghantar permintaan pembenaman Kod pelaksanaannya sangat mudah, iaitu menggunakan API fetch untuk memanggil API REST sedia ada.
async function sendRequest(url: string, data: Record<string, any>) {try {const response = await fetch(url, {method: "POST",body: JSON.stringify(data),headers: {"Content-Type": "application/json",},});if (!response.ok) {throw new Error(`HTTP error! status: ${response.status}`);}const responseData = await response.json();return responseData;} catch (error) {console.error("Error:", error);}}Seterusnya, kami terus mentakrifkan fungsi embedTxtFile, terus memanggil fungsi pembenaman sedia ada di dalam fungsi dan menambah pengendalian pengecualian yang sepadan.
async function embedTxtFile(path: string) {try {embedding(path);} catch (error) {console.dir(error);}}embedTxtFile("langchain.txt")Akhir sekali, kami menggunakan perintah npx esno src/index.ts untuk melaksanakan fail ts setempat dengan cepat. Jika kod dalam index.ts berjaya dilaksanakan, keputusan berikut akan dikeluarkan dalam terminal:
 Pictures
Pictures
Malah, selain menggunakan kaedah di atas, kita juga boleh terus menggunakan [OllamaEmbeddings dalam @ modul langchain/komuniti ](https://js.langchain.com/docs/integrations/text_embedding/ollama "OllamaEmbeddings"), yang secara dalaman merangkum logik untuk memanggil perkhidmatan pembenaman ollama:
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";const embeddings = new OllamaEmbeddings({model: "nomic-embed-text", baseUrl: "http://127.0.0.1:11434",requestOptions: {useMMap: true,numThread: 6,numGpu: 1,},});const documents = ["Hello World!", "Bye Bye"];const documentEmbeddings = await embeddings.embedDocuments(documents);console.log(documentEmbeddings);Kandungan yang diperkenalkan dalam artikel ini melibatkan pembangunan sistem RAG , proses mewujudkan indeks kandungan asas pengetahuan. Jika anda tidak tahu tentang sistem RAG, anda boleh membaca artikel berkaitan.
Rujukan
[1]Ollama: https://ollama.com/
[2]nomic-embed-text: https://ollama.com/library/nomic-embed-text
Atas ialah kandungan terperinci Prestasi larian tempatan perkhidmatan Embedding melebihi OpenAI Text-Embedding-Ada-002, yang sangat mudah!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!