
Rumah >Peranti teknologi >AI >Siri Ramalan Trajektori |. Apakah versi evolusi HiVT QCNet yang dibincangkan?
Siri Ramalan Trajektori |. Apakah versi evolusi HiVT QCNet yang dibincangkan?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-04-12 18:28:21883semak imbas
Versi HiVT yang telah berkembang (anda boleh membaca artikel ini secara langsung tanpa membaca HiVT terlebih dahulu), dengan prestasi dan kecekapan yang lebih baik.
Artikelnya juga mudah dibaca.
[Siri Ramalan Trajektori] [Nota] HiVT: Pengubah Vektor Hierarki untuk Ramalan Gerakan Berbilang Ejen - Zhihu (zhihu.com)
Pautan asal:
https://openaccess.thecvf.com/content/CVPR papers202/CVPR.com/content/CVPR /Zhou_Query-Centric_Trajectory_Prediction_CVPR_2023_paper.pdf
Abstrak
Terdapat masalah dalam model di mana ejen digunakan sebagai pusat untuk ramalan Apabila tetingkap bergerak, ia perlu diulang ke pusat beberapa kali untuk kemudian ulangi proses pengekodan Ia tidak sesuai untuk kegunaan atas kapal. Oleh itu, kami menggunakan rangka kerja tertumpu pertanyaan untuk pengekodan pemandangan, yang boleh menggunakan semula hasil yang dikira dan tidak bergantung pada sistem koordinat masa global. Pada masa yang sama, kerana ejen yang berbeza berkongsi ciri adegan, proses penyahkodan trajektori ejen boleh diproses lebih selari.
Adegan dikodkan secara kompleks Kaedah penyahkodan semasa masih sukar untuk menangkap maklumat mod, terutamanya untuk ramalan jangka panjang. Untuk menyelesaikan masalah ini, kami mula-mula menggunakan pertanyaan tanpa sauh untuk menjana cadangan trajektori (kaedah pengekstrakan ciri langkah demi langkah), supaya model boleh menggunakan ciri pemandangan dengan lebih baik pada masa yang berbeza. Kemudian terdapat modul pelarasan, yang menggunakan cadangan yang diperoleh pada langkah sebelumnya untuk mengoptimumkan trajektori (berasaskan sauh dinamik). Melalui sauh berkualiti tinggi ini, penyahkod berasaskan pertanyaan kami boleh mengendalikan ciri-ciri mod dengan lebih baik.
Berjaya mendapat kedudukan. Reka bentuk ini juga melaksanakan pengekodan ciri senario dan saluran paip penyahkod berbilang ejen selari.
Pengenalan
Kertas ramalan trajektori semasa mempunyai masalah berikut:
- Untuk pelbagai maklumat adegan heterogen, kecekapan pemprosesan adalah rendah. Dalam tugas pemanduan tanpa pemandu, data distrim ke bingkai model demi bingkai, termasuk peta berketepatan tinggi bervektor dan trajektori sejarah ejen di sekeliling. Kaedah perhatian terfaktor baru-baru ini (perhatian berasingan dalam ruang dan masa) telah meningkatkan pemprosesan maklumat ini ke tahap yang baharu. Tetapi ini memerlukan perhatian untuk setiap elemen adegan Jika adegan itu sangat kompleks, kosnya masih sangat tinggi.
- Apabila masa ramalan meningkat, ketidakpastian ramalan juga meletup. Sebagai contoh, kereta di persimpangan mungkin berjalan lurus atau membelok. Untuk mengelakkan kehilangan kemungkinan kemungkinan, model perlu mendapatkan pengedaran berbilang mod dan bukannya hanya meramalkan mod dengan frekuensi tertinggi. Tetapi terdapat hanya satu gt, dan adalah mustahil untuk melaksanakan pembelajaran yang lebih baik pada pelbagai kemungkinan. Sesetengah kertas mencadangkan kaedah menggunakan berbilang sauh tangan untuk pengawasan Kesan ini bergantung sepenuhnya pada kualiti sauh. Pendekatan ini sangat buruk apabila sauh tidak dapat menutup GT dengan tepat. Terdapat juga pendekatan lain untuk meramalkan berbilang mod secara langsung, mengabaikan masalah keruntuhan mod dan ketidakstabilan latihan.
Untuk menyelesaikan masalah di atas, kami mencadangkan QCNet.
Pertama sekali, kami ingin meningkatkan kelajuan inferens di atas kapal sambil menggunakan perhatian terfaktor yang berkuasa dengan baik. Kaedah pengekodan berpusatkan ejen pada masa lalu jelas tidak berfungsi. Apabila bingkai data seterusnya tiba, tetingkap akan bergerak, tetapi masih terdapat pertindihan besar dengan bingkai sebelumnya, jadi kami berpeluang untuk menggunakan semula ciri ini. Walau bagaimanapun, kaedah berpusatkan ejen perlu dipindahkan ke sistem koordinat ejen, menyebabkannya mengekod semula tempat kejadian. Untuk menyelesaikan masalah ini, kami menggunakan kaedah query-centric: elemen pemandangan mengekstrak ciri dalam sistem koordinat ruang-masa mereka sendiri, tanpa mengira sistem koordinat global (tidak kira di mana ego berada). (Peta berketepatan tinggi boleh digunakan kerana elemen peta mempunyai ID jangka panjang. Peta bukan HD mungkin tidak berguna. Elemen peta mesti dijejaki dalam bingkai sebelumnya dan seterusnya.)
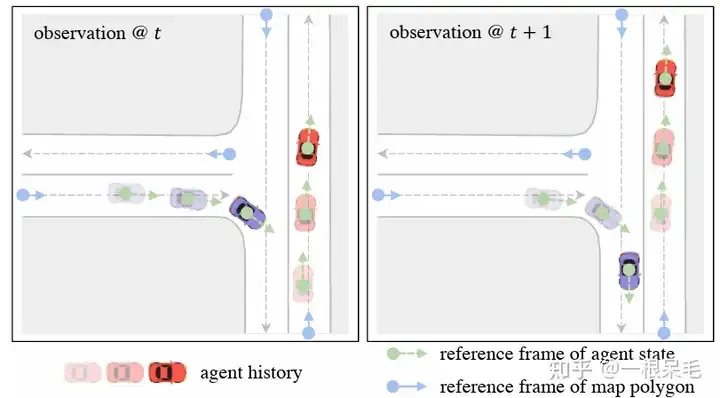
Ini membolehkan kami mengekod diproses sebelum ini Hasilnya digunakan semula, dan ejen secara langsung menggunakan ciri-ciri cache ini, sekali gus menjimatkan kependaman.
Kedua, untuk menggunakan hasil pengekodan pemandangan ini dengan lebih baik untuk ramalan jangka panjang berbilang mod, kami menggunakan pertanyaan tanpa sauh untuk mengekstrak ciri adegan langkah demi langkah (pada kedudukan sebelumnya), supaya setiap penyahkod adalah langkah yang sangat singkat. Pendekatan ini membenarkan pengekstrakan ciri pemandangan untuk memfokus pada lokasi tertentu ejen pada masa hadapan, dan bukannya mengekstrak ciri yang jauh untuk mempertimbangkan lokasi berbilang detik pada masa hadapan. Penambat berkualiti tinggi yang diperoleh dengan cara ini akan dilaraskan dengan baik dalam modul penapisan seterusnya. gabungan bebas sauh dan berasaskan sauhmenggunakan sepenuhnya kelebihan kedua-dua kaedah untuk mencapai ramalan berbilang mod dan jangka panjang.
Pendekatan ini adalah yang pertama untuk meneroka kesinambungan ramalan trajektori untuk mencapai inferens berkelajuan tinggi. Pada masa yang sama, bahagian penyahkod juga mengambil kira tugas ramalan berbilang mod dan jangka panjang.
Pendekatan
Input dan Output

Pada masa yang sama, modul ramalan juga boleh mendapatkan poligon M daripada peta berketepatan tinggi Setiap poligon mempunyai berbilang titik dan maklumat semantik (crosswalk, lorong, dll.).
Modul ramalan menggunakan keadaan ejen di atas dan maklumat peta pada detik T untuk memberikan trajektori ramalan K dengan jumlah panjang T', serta taburan kebarangkaliannya.
Pengekodan Konteks Adegan Berpusatkan Pertanyaan
Langkah pertama secara semula jadi ialah pengekodan tempat kejadian. Perhatian terfaktor yang popular pada masa ini (masing-masing perhatian dalam dimensi masa dan ruang) dilakukan dengan cara ini Secara khusus, terdapat tiga langkah:
- perhatian dimensi masa, kerumitan masa O(A), pendaraban matriks dimensi masa setiap ejen.
- perhatian silang ejen dan peta, kerumitan masa O(ATM), pada setiap saat, pendaraban matriks ejen dan elemen peta
- perhatian antara ejen dan ejen, kerumitan masa O(T) , pada setiap saat, ejen dan matriks ejen didarabkan
Berbanding dengan kaedah sebelumnya untuk memampatkan ciri dalam dimensi masa kepada momen semasa, dan kemudian berinteraksi antara ejen dan ejen, ejen dan peta, kaedah ini adalah untuk setiap saat. pada masa lalu. Untuk berinteraksi, anda boleh mendapatkan lebih banyak maklumat, seperti evolusi interaksi antara ejen dan peta pada setiap saat.
Tetapi kelemahannya ialah kerumitan padu akan menjadi sangat besar apabila pemandangan menjadi lebih kompleks dan bilangan elemen bertambah. Matlamat kami adalah untuk menggunakan perhatian terfaktor ini dengan baik tanpa membiarkan kerumitan masa meletup dengan begitu mudah.
Cara mudah untuk difikirkan adalah dengan menggunakan hasil bingkai sebelumnya, kerana dalam dimensi masa, sebenarnya terdapat bingkai T-1 yang diulang sepenuhnya. Tetapi kerana kita perlu memutar dan menterjemahkan ciri ini kepada kedudukan dan orientasi bingkai semasa ejen, kita tidak boleh hanya menggunakan hasil operasi bingkai sebelumnya.
Untuk menyelesaikan masalah sistem koordinat, pendekatan berpusatkan pertanyaan diguna pakai untuk mempelajari ciri-ciri elemen adegan tanpa bergantung pada koordinat globalnya. Pendekatan ini mewujudkan sistem koordinat spatio-temporal tempatan untuk setiap elemen pemandangan, dan mengekstrak ciri dalam sistem koordinat ini Walaupun ego pergi ke tempat lain, ciri yang diekstrak secara tempatan akan kekal tidak berubah. Sistem koordinat spatio-temporal tempatan ini secara semula jadi mempunyai kedudukan asal dan arah Maklumat kedudukan ini digunakan sebagai kunci, dan ciri yang diekstrak digunakan sebagai nilai untuk memudahkan operasi perhatian seterusnya. Keseluruhan pendekatan dibahagikan kepada langkah-langkah berikut:
Sistem Koordinat Ruang Masa Tempatan
Untuk ciri ejen i pada masa t, pilih kedudukan dan orientasi pada masa ini sebagai sistem rujukan. Untuk elemen peta, titik permulaan elemen ini digunakan sebagai bingkai rujukan. Kaedah pemilihan sistem rujukan sedemikian boleh mengekalkan ciri yang diekstrak tidak berubah selepas ego bergerak.
Pembenaman Elemen Pemandangan
Untuk ciri vektor lain dalam setiap elemen, perwakilan koordinat kutub diperolehi dalam sistem rujukan di atas. Ia kemudiannya ditukar kepada ciri Fourier untuk mendapatkan isyarat frekuensi tinggi. Selepas menggabungkan ciri semantik, MLP memperoleh ciri tersebut. Untuk elemen peta, untuk memastikan susunan titik dalaman tidak relevan, perhatian dilakukan terlebih dahulu dan kemudian pengumpulan dilakukan. Akhir sekali, ciri ejen ialah [A, T, D], dan ciri peta ialah [M, D]. Ciri-ciri yang diekstrak dengan cara ini boleh menjadikan ego boleh digunakan di mana-mana sahaja.
Pembenaman Fourier: Buat pembenaman teragih normal, sepadan dengan pemberat pelbagai frekuensi, darabkan jumlah input dengan 2Π, dan akhirnya ambil cos dan sin sebagai ciri. Pemahaman intuitif haruslah menganggap input sebagai isyarat dan menyahkod isyarat kepada berbilang isyarat asas (isyarat berbilang frekuensi). Ini boleh menangkap isyarat frekuensi tinggi dengan lebih baik adalah sangat penting untuk ketepatan keputusan. Perlu diingat bahawa tidak disyorkan untuk menggunakan data yang bising kerana ia akan tersilap menangkap isyarat frekuensi tinggi yang salah. (Rasanya agak overfit, tidak terlalu umum tetapi tidak terlalu tepat)
Pembenaman Kedudukan Spatial-Temporal Relative

Perhatian Diri untuk Pengekodan Peta

Pengekodan



Perlu diingat bahawa ciri-ciri yang diperolehi melalui kaedah di atas mempunyai invarians spatiotemporal, iaitu, tidak kira ke mana ego pergi pada bila-bila masa, ciri di atas tidak berubah kerana tiada terjemahan atau putaran berdasarkan maklumat kedudukan semasa. Oleh kerana hanya terdapat bingkai data baharu berbanding bingkai sebelumnya, tidak perlu mengira ciri momen sebelumnya, jadi jumlah kerumitan pengiraan dibahagikan dengan T. . Tidak boleh dipercayai kerana ketidakpastian akan meletup di kemudian hari. Oleh itu, model ini menggunakan kaedah pertanyaan tanpa sauh kasar terlebih dahulu, dan kemudian memperhalusi kaedah asas sauh untuk output ini.
 Keseluruhan struktur rangkaian
Keseluruhan struktur rangkaian
Mode2Scene dan Mode2Mode Attention
Mode2Scene menggunakan struktur DETR dalam kedua-dua langkah: pertanyaan ialah mod trajektori K (langkah cadangan kasar secara langsung dijana secara rawak, dan langkah cadangan diperhalusi ciri langkah sebagai input), dan kemudian lakukan perhatian silang berbilang pada ciri pemandangan (sejarah ejen, peta, ejen sekeliling).
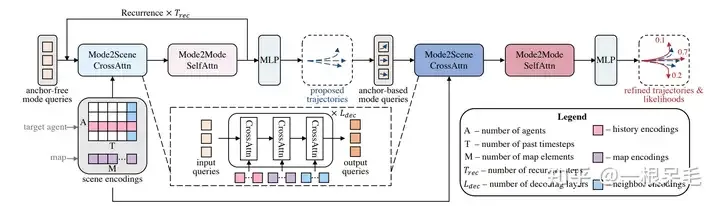 Struktur DETR
Struktur DETR
Mode2Mode melakukan perhatian diri di kalangan mod K, cuba merealisasikan kepelbagaian antara mod, supaya tidak mengumpulkan kesemuanya.
Bingkai Rujukan Pertanyaan ModUntuk meramalkan trajektori berbilang ejen secara selari, pengekodan adegan dikongsi oleh berbilang ejen. Oleh kerana ciri pemandangan adalah semua ciri yang berkaitan dengan dirinya sendiri, anda masih perlu beralih kepada perspektif ejen jika anda ingin menggunakannya. Untuk pertanyaan mod, lokasi dan maklumat orientasi ejen akan dilampirkan. Sama seperti operasi pengekodan kedudukan relatif sebelumnya, maklumat kedudukan relatif elemen pemandangan dan ejen juga akan dibenamkan sebagai kunci dan nilai. (Secara intuitif, ia adalah perhatian wajaran setiap mod ejen terhadap penggunaan maklumat berdekatan) 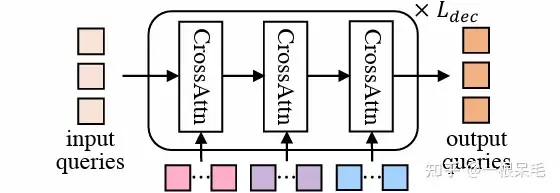
Cadangan Trajektori Tanpa Anchor
Kali pertama ialah kaedah bebas sauh, menggunakan pertanyaan yang boleh dipelajari untuk mencipta secara relatif rendah kualiti Cadangan trajektori akan menghasilkan sejumlah K cadangan. Memandangkan perhatian silang digunakan untuk mengekstrak ciri daripada maklumat pemandangan, sauh yang agak kecil dan berkesan boleh dijana dengan cekap untuk digunakan dalam penapisan kedua. Perhatian diri menjadikan setiap cadangan lebih pelbagai secara keseluruhan.
Pemurnian Trajektori Berasaskan Anchor
Walaupun kaedah bebas anchor agak mudah, ia juga mempunyai masalah latihan yang tidak stabil dan kemungkinan mod runtuh. Pada masa yang sama, mod yang dijana secara rawak juga perlu dapat berfungsi dengan baik untuk ejen yang berbeza dalam keseluruhan adegan Ini agak sukar, dan mudah untuk menjana cadangan trajektori yang tidak selaras dengan kinematik atau trafik. Jadi kami terfikir untuk melakukan pembetulan berasaskan sauh yang lain. Offset diramalkan berdasarkan cadangan (ditambahkan pada cadangan asal untuk mendapatkan trajektori yang disemak semula), dan kebarangkalian setiap trajektori baharu diramalkan.
Modul ini juga menggunakan bentuk DETR Pertanyaan setiap mod diekstrak menggunakan cadangan langkah sebelumnya Secara khusus, GRU kecil digunakan untuk membenamkan setiap sauh (langkah ke hadapan), dan ia digunakan sehingga akhir. Satu ciri pada seketika berfungsi sebagai pertanyaan. Pertanyaan berasaskan sauh ini boleh memberikan maklumat spatial tertentu, menjadikannya lebih mudah untuk menangkap maklumat berguna semasa perhatian. 
Objektif Latihan
Sama seperti HiVT (rujuk analisis HiVT), menggunakan pengedaran Laplace. Secara terang-terangan, setiap saat dalam setiap mod dimodelkan sebagai taburan Laplace (rujuk taburan Gaussian umum, di mana min dan var mewakili kedudukan titik ini dan ketidakpastiannya). Dan detik-detik itu dianggap sebagai bebas (terus berlipat ganda). Π mewakili kebarangkalian mod yang sepadan.Kehilangan terdiri daripada 3 bahagian
terutamanya dibahagikan kepada dua bahagian:kehilangan klasifikasi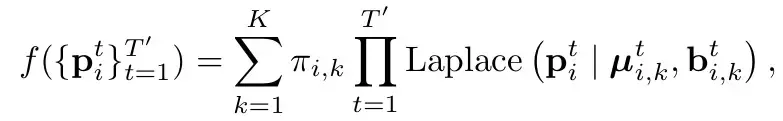 dan
dan
.
Kehilangan klasifikasi merujuk kepada kehilangan kebarangkalian yang diramalkan Apa yang perlu diperhatikan di sini ialah perlu untuk 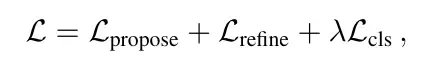 mengganggu pulangan kecerunan
mengganggu pulangan kecerunan
Terdapat dua kerugian regresi, satu kehilangan cadangan peringkat pertama, dan satu lagi kehilangan penapisan peringkat kedua. Pendekatan pemenang-ambil-semua diguna pakai, iaitu, hanya kehilangan mod yang paling hampir dengan gt dikira, dan kerugian regresi kedua-dua peringkat dikira. Untuk kestabilan latihan, pulangan kecerunan juga terganggu dalam dua peringkat, supaya pembelajaran cadangan hanya mempelajari cadangan, dan menghalusi hanya belajar menghaluskan.
EksperimenArgoverse2 asas SOTA (* menunjukkan teknik ensemble digunakan)
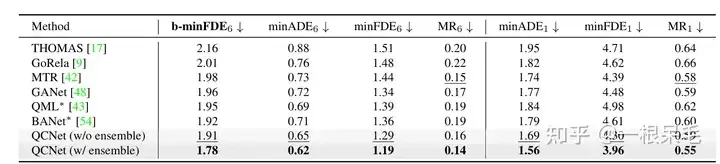 Perbezaan antara b-minFDE dan minFDE ialah ia didarab dengan pekali tambahan yang berkaitan dengan kebarangkaliannya sasaran mahu FDE menjadi yang terkecil Semakin tinggi kebarangkalian trajektori itu, semakin baik.
Perbezaan antara b-minFDE dan minFDE ialah ia didarab dengan pekali tambahan yang berkaitan dengan kebarangkaliannya sasaran mahu FDE menjadi yang terkecil Semakin tinggi kebarangkalian trajektori itu, semakin baik.
Mengenai teknik ensemble, saya rasa ianya agak menipu: anda boleh rujuk pengenalan dalam BANet, yang diperkenalkan secara ringkas di bawah.
Langkah terakhir menjana trajektori ialah menyambungkan berbilang submodel (dekoder) dengan struktur yang sama pada masa yang sama, yang akan memberikan beberapa set ramalan Contohnya, terdapat 7 submodel, setiap satu dengan 6 ramalan, 42 kesemuanya . Kemudian gunakan kmeans untuk melakukan pengelompokan (menggunakan titik koordinat terakhir sebagai standard pengelompokan Sasaran ialah 6 kumpulan, 7 item dalam setiap kumpulan, dan kemudian lakukan purata wajaran dalam setiap kumpulan untuk mendapatkan trajektori baharu).
Kaedah pemberat adalah seperti berikut Ia adalah b-minFDE bagi trajektori semasa dan gt, dan c ialah kebarangkalian bagi trajektori semasa Berat dikira dalam setiap kumpulan, dan kemudian koordinat trajektori ditimbang dan dijumlahkan mendapatkan trajektori baru. (Rasanya agak rumit, kerana c sebenarnya kebarangkalian trajektori ini dalam output submodel, yang agak tidak konsisten dengan jangkaan apabila digunakan dalam pengelompokan)
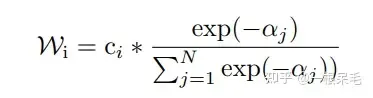 Dan kebarangkalian trajektori baru selepas operasi ini juga sukar untuk dikira dengan tepat, kaedah di atas tidak boleh digunakan, jika tidak, jumlah kebarangkalian tidak semestinya 1. Nampaknya kita hanya boleh mengira kebarangkalian dalam kelompok dengan berat yang sama.
Dan kebarangkalian trajektori baru selepas operasi ini juga sukar untuk dikira dengan tepat, kaedah di atas tidak boleh digunakan, jika tidak, jumlah kebarangkalian tidak semestinya 1. Nampaknya kita hanya boleh mengira kebarangkalian dalam kelompok dengan berat yang sama.
Argoverse1 juga jauh di hadapan
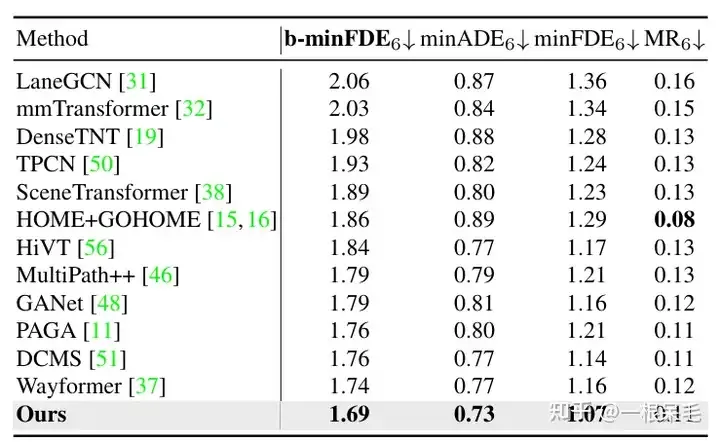 Penyelidikan tentang pengekodan adegan: Jika hasil pengekodan adegan sebelumnya digunakan semula, masa kesimpulan boleh dikurangkan dengan banyak. Bilangan interaksi perhatian terfaktor antara ejen dan maklumat adegan meningkat, dan kesan ramalan juga akan menjadi lebih baik, tetapi kependaman juga meningkat dengan mendadak, yang perlu ditimbang.
Penyelidikan tentang pengekodan adegan: Jika hasil pengekodan adegan sebelumnya digunakan semula, masa kesimpulan boleh dikurangkan dengan banyak. Bilangan interaksi perhatian terfaktor antara ejen dan maklumat adegan meningkat, dan kesan ramalan juga akan menjadi lebih baik, tetapi kependaman juga meningkat dengan mendadak, yang perlu ditimbang.
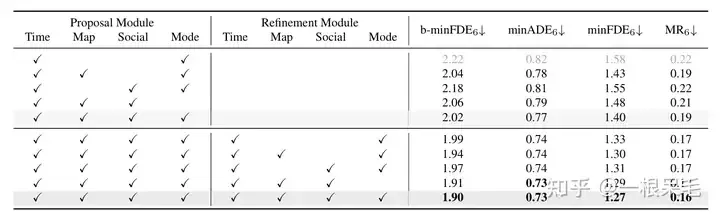
 Penyelidikan tentang pelbagai operasi: Membuktikan kepentingan menapis dan kepentingan perhatian berfaktor dalam pelbagai interaksi, kedua-duanya amat diperlukan.
Penyelidikan tentang pelbagai operasi: Membuktikan kepentingan menapis dan kepentingan perhatian berfaktor dalam pelbagai interaksi, kedua-duanya amat diperlukan.
Atas ialah kandungan terperinci Siri Ramalan Trajektori |. Apakah versi evolusi HiVT QCNet yang dibincangkan?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!