Gabungan model besar dan pangkalan data AI telah menjadi senjata ajaib untuk mengurangkan kos dan meningkatkan kecekapan model besar dan menjadikan data besar benar-benar pintar.

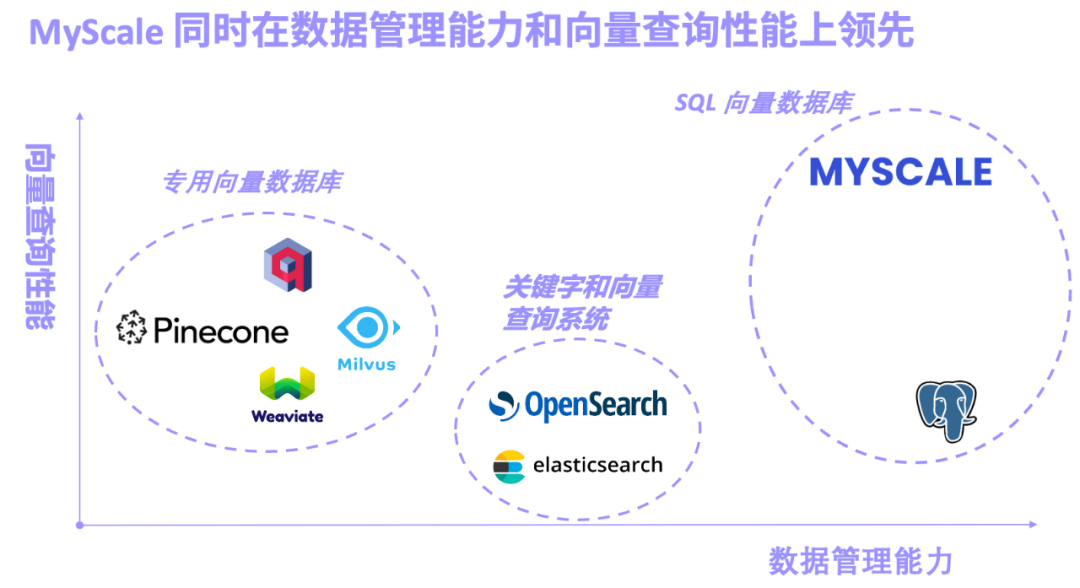
Gelombang Model Besar (LLM) telah melonjak selama lebih dari setahun, terutamanya model yang diwakili oleh outlet GPT-4, Gemini-1.5, Claude-3, dll. Pada landasan LLM, beberapa penyelidikan menumpukan pada peningkatan parameter model, dan ada yang gila tentang pelbagai mod... Antaranya, keupayaan LLM untuk memproses panjang konteks telah menjadi penunjuk penting untuk menilai model Konteks yang lebih kukuh bermakna model tersebut Mempunyai prestasi perolehan yang lebih kukuh. Sebagai contoh, keupayaan sesetengah model memproses sehingga 1 juta token dalam satu nafas telah membuatkan ramai penyelidik berfikir sama ada kaedah RAG (Retrieval-Augmented Generation) masih diperlukan? Sesetengah orang berpendapat bahawa RAG akan dibunuh oleh model konteks panjang, tetapi pandangan ini telah disangkal oleh ramai penyelidik dan arkitek. Mereka percaya bahawa dalam satu pihak, struktur data adalah kompleks, berubah dengan kerap, dan banyak data mempunyai dimensi masa yang penting, yang mungkin terlalu rumit untuk LLM. Sebaliknya, adalah tidak realistik untuk meletakkan semua data heterogen besar perusahaan dan industri ke dalam tetingkap konteks. Gabungan model besar dan pangkalan data AI menyuntik maklumat profesional, tepat dan masa nyata ke dalam sistem AI generatif, dengan banyak mengurangkan ilusi dan meningkatkan kepraktisan sistem. Pada masa yang sama, kaedah LLM berpusatkan data juga boleh mengambil kesempatan daripada pengurusan data besar-besaran dan keupayaan pertanyaan pangkalan data AI untuk mengurangkan dengan ketara kos latihan model besar dan penalaan halus, dan menyokong penalaan sampel kecil dalam senario berbeza sistem. Ringkasnya, Gabungan model besar dan pangkalan data AI bukan sahaja mengurangkan kos dan meningkatkan kecekapan untuk model besar, tetapi juga menjadikan data besar benar-benar pintar. Selepas beberapa tahun pembangunan dan lelaran, MyScaleDB akhirnya menjadi sumber terbuka RAG membolehkan LLM mengekstrak maklumat dengan tepat daripada pangkalan pengetahuan berskala besar dan menjana Jawapan tepat masa, profesional dan tepat. Seiring dengan ini, pangkalan data vektor, fungsi teras sistem RAG, juga telah berkembang pesat Menurut konsep reka bentuk pangkalan data vektor, kita boleh membahagikannya secara kasar kepada tiga kategori: pangkalan data vektor khusus, sistem pengambilan semula yang menggabungkan kata kunci dan vektor. dan pangkalan data vektor SQL.
- Pangkalan data vektor khusus yang diwakili oleh Pinecone/Weaviate/Milvus direka dan dibina untuk mendapatkan semula vektor dari awal Prestasi mendapatkan semula vektor adalah sangat baik, tetapi fungsi pengurusan data umum adalah lemah.
- Sistem perolehan kata kunci dan vektor yang diwakili oleh Elasticsearch/OpenSearch digunakan secara meluas dalam pengeluaran kerana fungsi pencarian kata kunci yang lengkap Walau bagaimanapun, ia menduduki banyak sumber sistem dan ketepatan pertanyaan bersama serta prestasi kata kunci dan vektor tidak memuaskan. Orang ramai mendapat apa yang mereka mahu.
- Pangkalan data vektor SQL yang diwakili oleh pgvector (pemalam carian vektor untuk PostgreSQL) dan pangkalan data AI MyScale adalah berdasarkan SQL dan mempunyai fungsi pengurusan data yang berkuasa. Walau bagaimanapun, disebabkan oleh kelemahan storan baris PostgreSQL dan batasan algoritma vektor, pgvector mempunyai ketepatan yang rendah dalam pertanyaan vektor kompleks.
MyScale AI Database (MyScaleDB) adalah berdasarkan pangkalan data storan lajur SQL berprestasi tinggi, algoritma indeks vektor berprestasi tinggi dan berketumpatan data tinggi yang dibangunkan, dan pertanyaan bersama SQL dan vektor untuk pengambilan dan penyimpanan Enjin telah melalui penyelidikan dan pembangunan serta pengoptimuman yang mendalam Ia merupakan produk pangkalan data vektor SQL pertama di dunia yang prestasi komprehensif dan prestasi kosnya melebihi pangkalan data vektor khusus.
Terima kasih kepada penggilap pangkalan data SQL jangka panjang dalam senario data berstruktur besar-besaran, MyScaleDB menyokong kedua-dua vektor besar dan data berstruktur
, termasuk penyimpanan dan penyimpanan yang cekap bagi pelbagai jenis data seperti rentetan, JSON, ruang dan siri masa. Pertanyaan, dan akan melancarkan fungsi carian jadual dan kata kunci terbalik yang berkuasa dalam masa terdekat untuk meningkatkan lagi ketepatan sistem RAG dan menggantikan sistem seperti Elasticsearch.
Selepas hampir 6 tahun pembangunan dan beberapa lelaran versi, MyScaleDB baru-baru ini telah menjadi sumber terbuka Semua pembangun dan pengguna perusahaan dialu-alukan untuk membintangi GitHub dan membuka cara baharu menggunakan SQL untuk membina aplikasi AI peringkat pengeluaran. Alamat projek: https://github.com/myscale/myscaledbSerasi sepenuhnya dengan SQL, mempertingkatkan ketepatan dan mengurangkan kosDengan bantuan data yang lengkap
Dengan bantuan dengan kemampuan SQL berkuasa dan cekap Dengan keupayaan penyimpanan data dan pertanyaan yang berstruktur, vektor dan heterogen, MyScaleDB dijangka menjadi pangkalan data
AI pertama yang benar-benar berorientasikan model besar dan data besar.
Keserasian asli SQL dan vektorSejak kelahiran SQL setengah abad yang lalu, walaupun terdapat gelombang NoSQL, data besar, dll., pangkalan data SQL yang sentiasa berkembang masih menduduki pangkalan data SQL yang sentiasa berkembang. Perkongsian pasaran pengurusan data, malah sistem perolehan semula dan data besar seperti Elasticsearch dan Spark telah menyokong antara muka SQL secara berturut-turut. Walaupun pangkalan data vektor khusus telah dioptimumkan dan sistem direka untuk vektor, antara muka pertanyaan mereka biasanya tidak mempunyai penyeragaman dan tidak mempunyai bahasa pertanyaan lanjutan. Ini mengakibatkan keupayaan generalisasi antara muka yang lemah Contohnya, antara muka pertanyaan Pinecone tidak termasuk menyatakan medan yang hendak diambil, apatah lagi fungsi pangkalan data biasa seperti halaman dan pengagregatan. Keupayaan generalisasi antara muka yang lemah bermakna ia kerap berubah, meningkatkan kos pembelajaran. Pasukan MyScale percaya bahawa sistem SQL dan vektor yang dioptimumkan secara sistematik boleh mengekalkan sokongan SQL yang lengkap sambil memastikan prestasi tinggi dalam pengambilan vektor, dan hasil penilaian sumber terbuka mereka telah menunjukkan ini sepenuhnya.
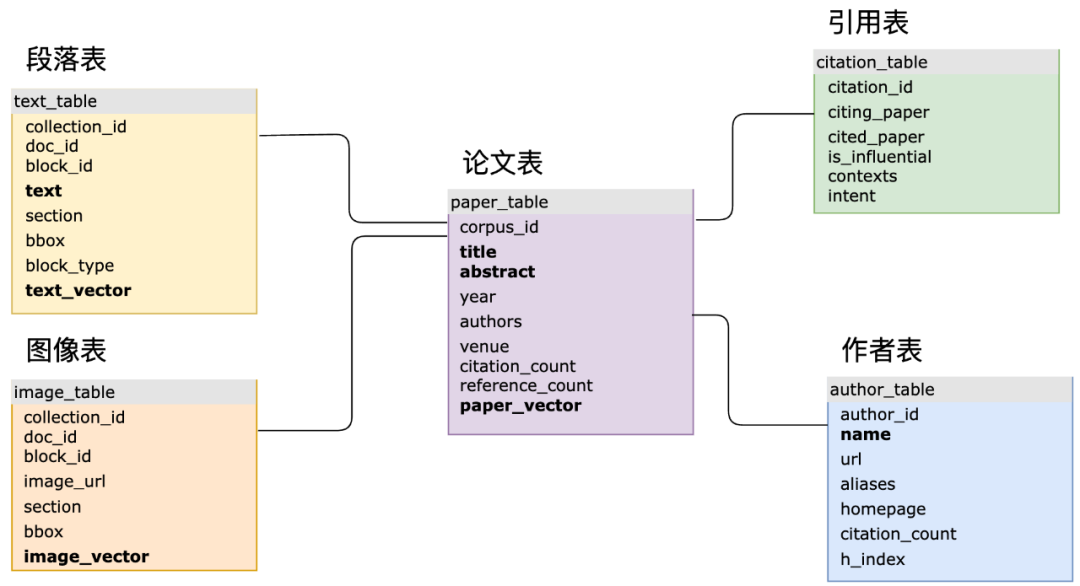
Dalam senario aplikasi AI kompleks sebenar, gabungan SQL dan vektor boleh meningkatkan fleksibiliti pemodelan data dan memudahkan proses pembangunan. Contohnya, dalam projek Science Navigator yang bekerjasama antara pasukan MyScale dan Institut Kecerdasan Saintifik Beijing, MyScaleDB digunakan untuk mendapatkan semula data kesusasteraan saintifik yang besar dan melaksanakan jawapan soalan pintar Terdapat lebih daripada 10 struktur jadual SQL utama, yang kebanyakannya ditubuhkan vektor. Dan indeks jadual terbalik, dan gunakan kunci utama dan kunci asing untuk membuat perkaitan. Dalam pertanyaan sebenar, sistem juga akan melibatkan pertanyaan bersama data berstruktur, vektor dan kata kunci, serta pertanyaan berkaitan beberapa jadual. Pemodelan dan korelasi ini sukar dicapai dalam pangkalan data vektor khusus, yang juga akan membawa kepada lelaran sistem akhir yang perlahan, pertanyaan yang tidak cekap dan penyelenggaraan yang sukar.
🎜🎜Gambar rajah skema struktur jadual utama NScience Navigator (lajur badan tebal membentuk indeks vektor atau indeks terbalik)
sokongan berstruktur, vektor dan kata kunci serta pertanyaan bersama data lain dalam sistem RA yang sebenar ketepatan dan kesan mendapatkan semula adalah halangan utama yang menyekat pelaksanaannya. Ini memerlukan pangkalan data AI untuk menyokong pertanyaan bersama data berstruktur, vektor dan kata kunci secara cekap untuk meningkatkan ketepatan pengambilan semula secara menyeluruh.
Sebagai contoh, dalam senario kewangan, pengguna perlu menanyakan pustaka dokumen "Berapakah hasil daripada pelbagai perniagaan global syarikat tertentu pada 2023?", "Syarikat tertentu", "2023" dan lain-lain berstruktur maklumat meta tidak boleh ditangkap Vektor dengan baik dan mungkin tidak dapat dilihat secara langsung dalam perenggan yang sepadan. Melakukan pengambilan vektor secara langsung pada keseluruhan pangkalan data akan memperoleh sejumlah besar maklumat hingar dan mengurangkan ketepatan akhir sistem. Sebaliknya, nama syarikat, tahun, dsb. biasanya boleh diperolehi sebagai meta-maklumat dokumen Kami boleh menggunakan WHERE tahun=2023 DAN syarikat ILIKE "%%" sebagai syarat penapis pertanyaan vektor untuk. mengesan dengan tepat Maklumat berkaitan diperolehi, yang meningkatkan kebolehpercayaan sistem dengan banyak. Dalam kewangan, pembuatan, penyelidikan saintifik dan senario lain, pasukan MyScale telah melihat kuasa pemodelan data heterogen dan pertanyaan yang berkaitan Dalam banyak senario, ketepatan malah telah bertambah baik daripada
60% kepada
Walaupun produk pangkalan data tradisional secara beransur-ansur menyedari kepentingan pertanyaan vektor dalam era AI dan telah mula menambah keupayaan vektor pada pangkalan data, masih terdapat masalah ketara dengan ketepatan pertanyaan bersama mereka. Sebagai contoh, dalam senario pertanyaan penapisan, apabila nisbah penapisan ialah 0.1, QPS Elasticsearch akan turun kepada kira-kira 5 sahaja, manakala PostgresSQL (menggunakan pemalam pgvector) mempunyai ketepatan perolehan hanya kira-kira 50% apabila nisbah penapisan adalah 0.01, menjadikan pertanyaan tidak stabil Ketepatan/prestasi sangat menyekat senario aplikasinya. Dan
MyScale hanya menggunakan 36% daripada kos pgvector dan 12% daripada kos ElasticSearch, dan boleh mencapai
pertanyaan berprestasi tinggi dan berketepatan tinggi dalam pelbagai senario dengan nisbah penapisan yang berbeza. 场 Dalam perkadaran penapisan yang berbeza, myscale menggunakan kos yang rendah untuk mencapai pertanyaan berketepatan tinggi dan berprestasi tinggi
Keseimbangan prestasi dan kos dalam adegan sebenar Disebabkan kepentingan dan perhatian yang tinggi dalam aplikasi model besar. semakin banyak pasukan telah melabur dalam trek pangkalan data vektor. Tumpuan awal semua orang adalah untuk meningkatkan QPS dalam senario carian vektor tulen, tetapi carian vektor tulen masih jauh dari mencukupi! Dalam senario sebenar, pemodelan data, fleksibiliti dan ketepatan pertanyaan, dan mengimbangi ketumpatan data, prestasi pertanyaan dan kos adalah isu yang lebih penting.
Dalam senario RAG, prestasi pertanyaan vektor tulen mempunyai lebihan 10x, vektor menduduki sumber yang besar, kekurangan fungsi pertanyaan bersama, prestasi dan ketepatan yang lemah sering menjadi norma dalam pangkalan data vektor proprietari semasa. MyScaleDB komited untuk meningkatkan prestasi komprehensif pangkalan data AI dalam senario data besar sebenar Penanda Aras Pangkalan Data Vektor MyScalenya juga merupakan yang pertama dalam industri untuk membandingkan prestasi komprehensif dan keberkesanan kos sistem pangkalan data vektor arus perdana dalam senario pertanyaan yang berbeza dengan. skala lima juta vektor sistem penilaian sumber terbuka, semua orang dialu-alukan untuk memberi perhatian dan membangkitkan isu. Pasukan MyScale berkata bahawa masih terdapat banyak ruang untuk pengoptimuman pangkalan data AI dalam senario aplikasi sebenar, dan mereka juga berharap untuk terus menggilap produk dan menambah baik sistem penilaian dalam amalan.
Alamat projek Penanda Aras Pangkalan Data Vektor MyScale: https://github.com/myscale/vector-db-benchmarkOutlook: Model besar yang disokong pangkalan data AI Pembelajaran mesin + data besar telah memacu kejayaan Internet dan sistem maklumat generasi terdahulu Dalam era model besar, pasukan MyScale juga komited untuk mencadangkan generasi baharu model besar + penyelesaian data besar. Dengan
pangkalan data SQL + vektor berprestasi tinggi sebagai sokongan padu, MyScaleDB menyediakan keupayaan utama pemprosesan data berskala besar, pertanyaan pengetahuan, pemerhatian, analisis data dan pembelajaran sampel kecil, membina AI dan gelung tertutup data, menjadi seterusnya A penjanaan model besar + asas utama platform Ejen data besar. Pasukan MyScale telah pun meneroka pelaksanaan penyelesaian ini dalam penyelidikan saintifik, kewangan, industri, perubatan dan bidang lain. Dengan perkembangan pesat teknologi, beberapa deria kecerdasan buatan am (AGI) dijangka muncul dalam tempoh 5-10 tahun akan datang. Mengenai isu ini, kita tidak boleh tidak berfikir: Adakah model besar yang statik, maya dan berdaya saing dengan manusia diperlukan, atau adakah terdapat penyelesaian lain yang lebih komprehensif? Data tidak diragukan lagi merupakan pautan penting antara model besar, dunia dan pengguna Visi pasukan MyScale adalah untuk menggabungkan model besar dan data besar secara organik untuk mencipta sistem AI yang lebih profesional, masa nyata dan cekap dalam kerjasama, tetapi juga. penuh dengan kemesraan dan nilai manusia. Atas ialah kandungan terperinci Teks panjang tidak boleh membunuh RAG: vektor SQL+ memacu model besar dan paradigma baharu data besar, pangkalan data MyScale AI adalah sumber terbuka secara rasmi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!