
Rumah >Peranti teknologi >AI >Di luar GPT-4, model besar pasukan Stanford yang boleh dijalankan pada telefon mudah alih menjadi popular, dengan lebih 2k muat turun semalaman
Di luar GPT-4, model besar pasukan Stanford yang boleh dijalankan pada telefon mudah alih menjadi popular, dengan lebih 2k muat turun semalaman

- 王林ke hadapan
- 2024-04-07 16:19:011520semak imbas
Dalam proses melaksanakan model besar, AI sisi hujung adalah hala tuju yang sangat penting.
Baru-baru ini, Octopus v2 yang dilancarkan oleh penyelidik di Universiti Stanford telah menjadi popular dan telah mendapat perhatian besar daripada komuniti pembangun Model ini telah dimuat turun lebih 2k kali dalam satu malam.
Parameter Octopus v2 2 bilion boleh dijalankan pada telefon pintar, kereta, PC, dll., mengatasi GPT-4 dalam ketepatan dan kependaman serta mengurangkan panjang konteks sebanyak 95%. Tambahan pula, Octopus v2 adalah 36 kali lebih pantas daripada skim Llama7B + RAG. 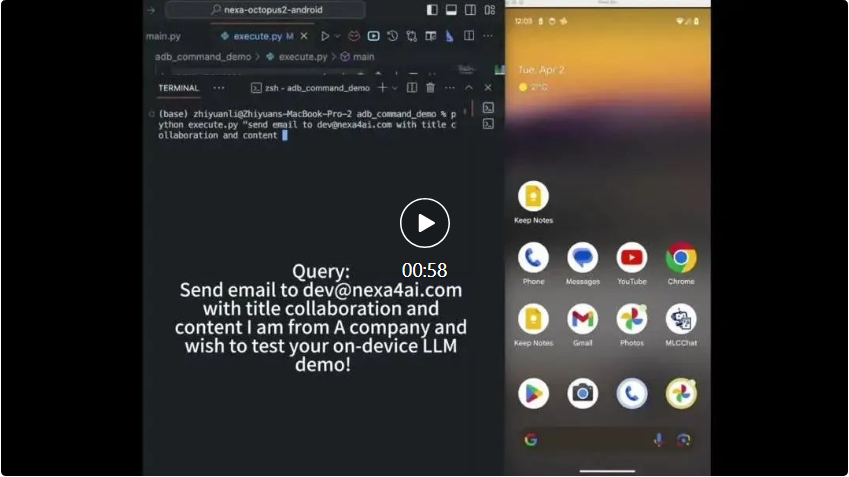

- Gambaran Keseluruhan Model
- Octopus-V2-2B+ ialah model bahasa sumber terbuka dengan 2 bilion parameter, disesuaikan untuk API Android. Ia berjalan lancar pada peranti Android dan meluaskan utilitinya kepada pelbagai aplikasi daripada pengurusan sistem Android kepada orkestrasi berbilang peranti.
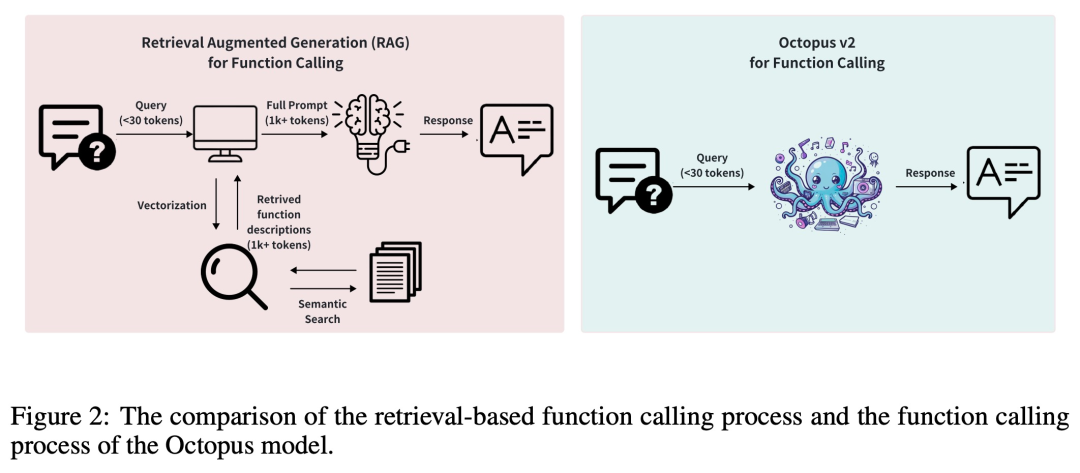
- Biasanya, kaedah Retrieval Augmented Generation (RAG) memerlukan penerangan terperinci tentang parameter fungsi berpotensi (kadangkala memerlukan sehingga puluhan ribu token input). Berdasarkan ini, Octopus-V2-2B memperkenalkan strategi token fungsi unik dalam fasa latihan dan inferens, yang bukan sahaja membolehkannya mencapai tahap prestasi yang setanding dengan GPT-4, tetapi juga meningkatkan kelajuan inferens dengan ketara, mengatasi berasaskan RAG. kaedah ini menjadikannya amat bermanfaat untuk peranti pengkomputeran tepi.
Dataset
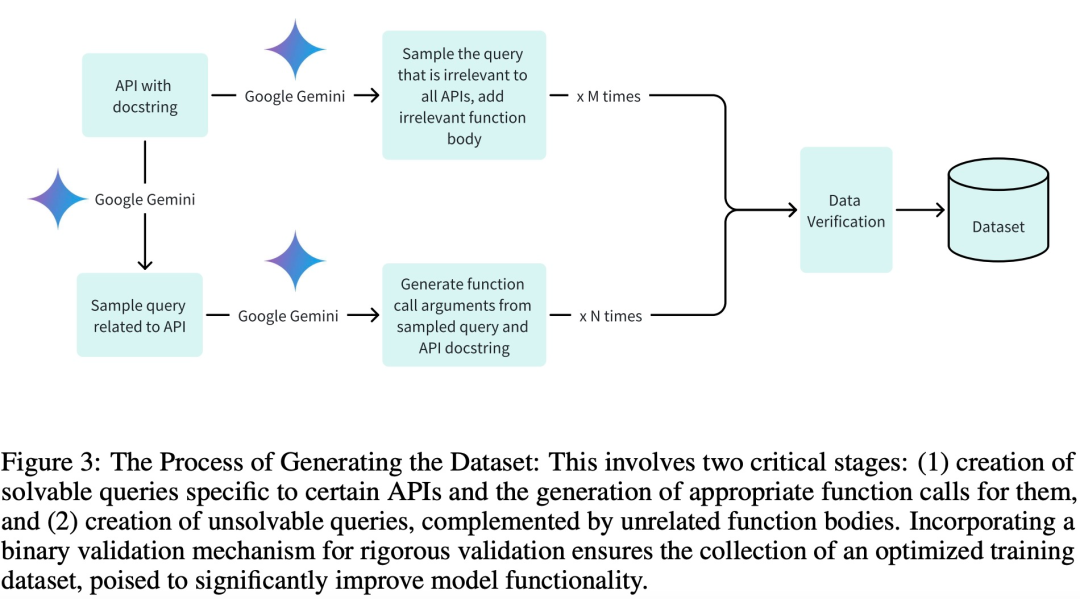
Untuk menggunakan set data berkualiti tinggi untuk fasa latihan, pengesahan dan ujian, dan terutamanya untuk mencapai latihan yang cekap, pasukan penyelidik mencipta set data dengan tiga peringkat utama: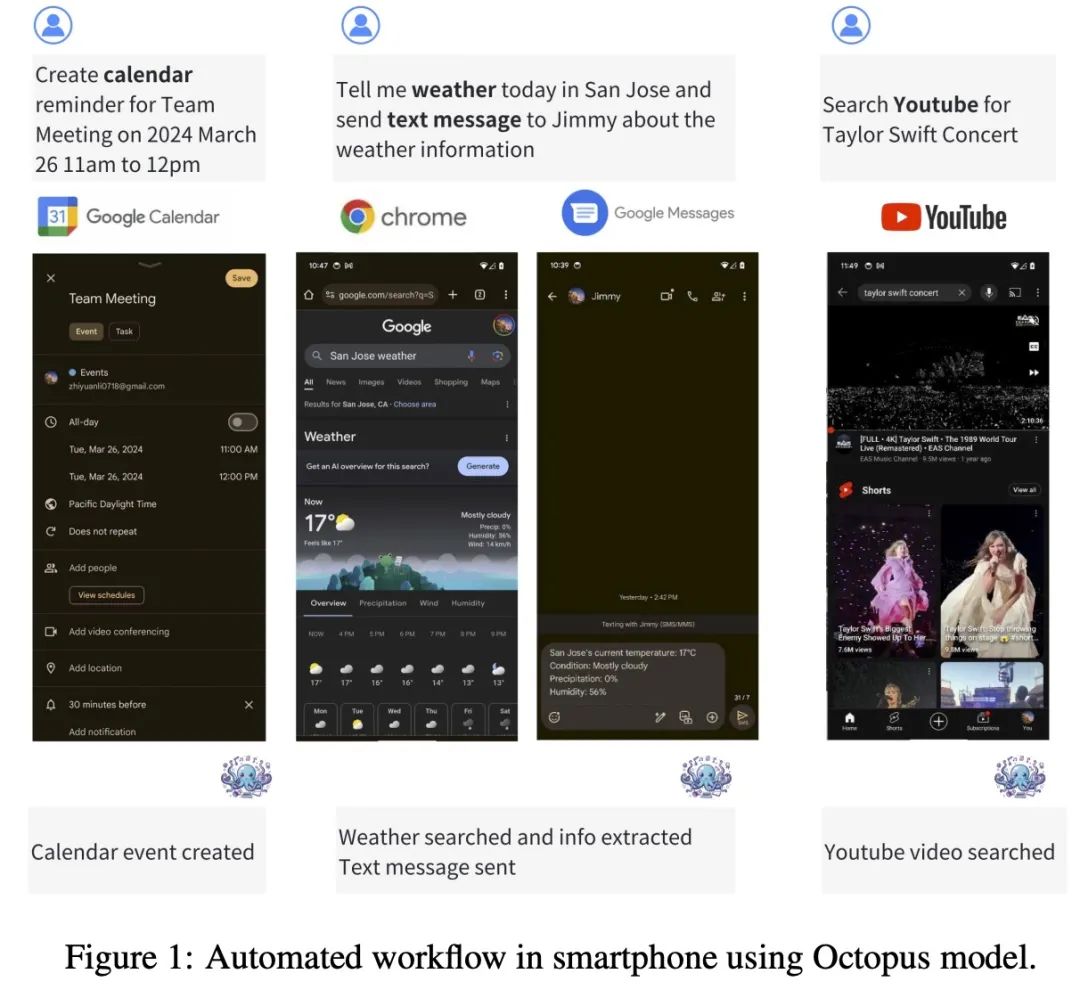
Menjana pertanyaan dan hujah panggilan Fungsi berkaitan mereka;
Pasukan penyelidik menulis 20 penerangan API Android untuk model latihan. Berikut ialah contoh penerangan API Android:
def get_trending_news (category=None, region='US', language='en', max_results=5):"""Fetches trending news articles based on category, region, and language.Parameters:- category (str, optional): News category to filter by, by default use None for all categories. Optional to provide.- region (str, optional): ISO 3166-1 alpha-2 country code for region-specific news, by default, uses 'US'. Optional to provide.- language (str, optional): ISO 639-1 language code for article language, by default uses 'en'. Optional to provide.- max_results (int, optional): Maximum number of articles to return, by default, uses 5. Optional to provide.Returns:- list [str]: A list of strings, each representing an article. Each string contains the article's heading and URL. """Pembangunan dan latihan model
Kajian ini menggunakan model Google Gemma-2B sebagai model pra-latihan dalam rangka kerja, dan menggunakan dua kaedah latihan berbeza: latihan model penuh dan latihan model LoRA.
Dalam latihan model lengkap, kajian ini menggunakan pengoptimum AdamW, kadar pembelajaran ditetapkan kepada 5e-5, bilangan langkah memanaskan badan ditetapkan kepada 10, dan penjadual kadar pembelajaran linear digunakan. Latihan model LoRA menggunakan konfigurasi pengoptimuman dan kadar pembelajaran yang sama seperti latihan model penuh, kedudukan LoRA ditetapkan kepada 16 dan LoRA digunakan pada modul berikut: q_proj, k_proj, v_proj, o_proj, up_proj, down_proj. Antaranya, parameter alfa LoRA ditetapkan kepada 32.
Untuk kedua-dua kaedah latihan, bilangan zaman ditetapkan kepada 3. Gunakan kod berikut untuk menjalankan model Octopus-V2-2B pada satu GPU.
from transformers import AutoTokenizer, GemmaForCausalLMimport torchimport timedef inference (input_text):start_time = time.time ()input_ids = tokenizer (input_text, return_tensors="pt").to (model.device)input_length = input_ids ["input_ids"].shape [1]outputs = model.generate (input_ids=input_ids ["input_ids"], max_length=1024,do_sample=False)generated_sequence = outputs [:, input_length:].tolist ()res = tokenizer.decode (generated_sequence [0])end_time = time.time ()return {"output": res, "latency": end_time - start_time}model_id = "NexaAIDev/Octopus-v2"tokenizer = AutoTokenizer.from_pretrained (model_id)model = GemmaForCausalLM.from_pretrained (model_id, torch_dtype=torch.bfloat16, device_map="auto")input_text = "Take a selfie for me with front camera"nexa_query = f"Below is the query from the users, please call the correct function and generate the parameters to call the function.\n\nQuery: {input_text} \n\nResponse:"start_time = time.time () print ("nexa model result:\n", inference (nexa_query)) print ("latency:", time.time () - start_time,"s")
 Penilaian
Penilaian
Octopus-V2-2B bukan sahaja berprestasi baik dalam kelajuan, tetapi juga dalam ketepatan, mengatasi "Llama7B + RAG solution" dalam ketepatan panggilan fungsi sebanyak 31%. Octopus-V2-2B mencapai ketepatan panggilan fungsi yang setanding dengan GPT-4 dan RAG + GPT-3.5. Pembaca yang berminat boleh membaca teks asal kertas untuk mengetahui lebih lanjut tentang kandungan penyelidikan. 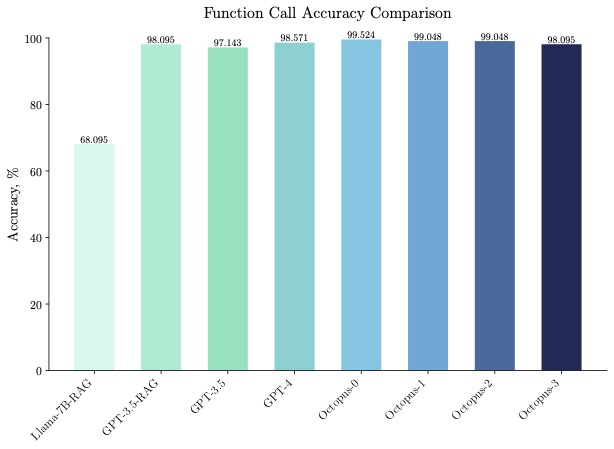
Atas ialah kandungan terperinci Di luar GPT-4, model besar pasukan Stanford yang boleh dijalankan pada telefon mudah alih menjadi popular, dengan lebih 2k muat turun semalaman. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Peraturan baharu untuk bulan Oktober ada di sini! Melibatkan papan tanda lalu lintas jalan baharu, industri kecerdasan buatan, dsb.
- Robot juga boleh merasakan: Universiti Stanford membina kulit elektronik yang boleh berkomunikasi dengan otak
- Memfokuskan pada ekosistem perniagaan digital dan industri metaverse, Lujiazui Digital Intelligence World berusaha untuk mencipta kluster industri elemen data
- [Trend Weekly] Trend Pembangunan Industri Kecerdasan Buatan Global: OpenAI menyerahkan permohonan tanda dagangan 'GPT-5' kepada Pejabat Paten A.S.
- Xiaoyu Yilian muncul di Ekspo Industri Pintar Antarabangsa China