
Rumah >Peranti teknologi >AI >Penjelasan terperinci tentang pengekodan kedudukan putaran RoPE yang biasa digunakan dalam model bahasa besar: mengapa ia lebih baik daripada pengekodan kedudukan mutlak atau relatif?
Penjelasan terperinci tentang pengekodan kedudukan putaran RoPE yang biasa digunakan dalam model bahasa besar: mengapa ia lebih baik daripada pengekodan kedudukan mutlak atau relatif?

- 王林ke hadapan
- 2024-04-01 20:19:01779semak imbas
Sejak kertas "Attention Is All You Need" diterbitkan pada 2017, seni bina Transformer telah menjadi asas kepada bidang pemprosesan bahasa semula jadi (NLP). Reka bentuknya sebahagian besarnya kekal tidak berubah selama bertahun-tahun, dengan 2022 menandakan perkembangan besar dalam bidang dengan pengenalan Pengekodan Kedudukan Putar (RoPE).
Pembenaman kedudukan diputar ialah teknologi pembenaman kedudukan NLP yang paling canggih. Model bahasa berskala besar yang paling popular seperti Llama, Llama2, PaLM dan CodeGen sudah menggunakannya. Dalam artikel ini, kita akan menyelami apa itu pengekodan kedudukan bergilir dan cara ia menggabungkan dengan kemas kelebihan benam kedudukan mutlak dan relatif.
Keperluan untuk pengekodan kedudukan
Untuk memahami kepentingan RoPE, mari kita semak dahulu mengapa pengekodan kedudukan adalah penting. Model pengubah, dengan reka bentuk yang wujud, tidak mengambil kira susunan token input.
Sebagai contoh, frasa seperti "anjing mengejar babi" dan "babi mengejar anjing", walaupun ia mempunyai makna yang berbeza, dianggap tidak dapat dibezakan kerana ia dilihat sebagai set token yang tidak tertib. Untuk mengekalkan maklumat jujukan dan maksudnya, perwakilan diperlukan untuk menyepadukan maklumat kedudukan ke dalam model.
Pengekodan Kedudukan Mutlak
Untuk mengekod kedudukan dalam ayat, alat lain diperlukan menggunakan vektor dengan dimensi yang sama, di mana setiap vektor mewakili kedudukan dalam ayat. Sebagai contoh, nyatakan vektor khusus untuk perkataan kedua dalam ayat. Oleh itu, setiap kedudukan ayat mempunyai vektor yang unik. Input kepada lapisan Transformer kemudiannya dibentuk dengan menggabungkan perkataan embeddings dengan embeddings kedudukan sepadannya.
Terdapat dua cara utama untuk menjana benam ini:
- Belajar daripada data: Di sini, vektor kedudukan dipelajari semasa latihan, sama seperti parameter model lain. Kami mempelajari vektor unik untuk setiap kedudukan (mis. dari 1 hingga 512). Ini memperkenalkan had - panjang jujukan maksimum adalah terhad. Jika model hanya mempelajari kedudukan 512, ia tidak boleh mewakili jujukan lebih lama daripada kedudukan itu.
- Fungsi Sinus: Kaedah ini melibatkan penggunaan fungsi sinus untuk membina benam unik untuk setiap kedudukan. Walaupun butiran pembinaan ini rumit, ia pada asasnya menyediakan pembenaman kedudukan yang unik untuk setiap kedudukan dalam jujukan. Kajian empirikal menunjukkan bahawa pembelajaran dan menggunakan fungsi sinus daripada data boleh memberikan prestasi yang setanding dalam model dunia sebenar. . vektor kedudukan, yang sememangnya tidak boleh mewakili kedudukan melebihi had ini.
Kebebasan benaman lokasi: Setiap benaman lokasi adalah bebas daripada benaman lokasi lain. Ini bermakna dari perspektif model, perbezaan antara kedudukan 1 dan 2 adalah sama dengan perbezaan antara kedudukan 2 dan 500. Tetapi sebenarnya, kedudukan 1 dan 2 sepatutnya lebih berkait rapat daripada kedudukan 500, yang jauh lebih jauh. Kekurangan kedudukan relatif ini mungkin menghalang keupayaan model untuk memahami nuansa struktur bahasa.
Pengekodan kedudukan relatif
- Kedudukan relatif tidak menumpukan pada kedudukan mutlak nota dalam ayat, tetapi pada jarak antara pasangan not. Kaedah ini tidak menambah vektor kedudukan terus kepada vektor perkataan. Sebaliknya, mekanisme perhatian diubah untuk memasukkan maklumat kedudukan relatif.
- T5 (Pengubah Pemindahan Teks ke Teks) ialah model terkenal yang menggunakan pembenaman kedudukan relatif. T5 memperkenalkan cara yang halus untuk mengendalikan maklumat kedudukan:
T5 menggunakan pincang (nombor titik terapung) untuk mewakili setiap pengimbangan kedudukan yang mungkin. Sebagai contoh, bias B1 mungkin mewakili jarak relatif antara mana-mana dua token yang berselang satu kedudukan, tanpa mengira kedudukan mutlaknya dalam ayat.
Integrasi dalam lapisan perhatian kendiri: Matriks bias kedudukan relatif ini ditambahkan pada hasil darab matriks pertanyaan dan matriks kunci dalam lapisan perhatian kendiri. Ini memastikan bahawa penanda pada jarak relatif yang sama sentiasa diwakili oleh berat sebelah yang sama, tanpa mengira kedudukannya dalam jujukan.
Skalabilitas:
- Kelebihan ketara pendekatan ini ialah kebolehskalaannya. Ia boleh dilanjutkan kepada urutan panjang sewenang-wenangnya, yang mempunyai kelebihan yang jelas berbanding pembenaman kedudukan mutlak.
- Had pengekodan kedudukan relatif
Walaupun ia menarik secara teori, pengekodan kedudukan relatif amat bermasalah
- Tidak cekap pengiraan: matriks pengekodan kedudukan berpasangan mesti dibuat dan kemudian sejumlah besar operasi tensor dilakukan untuk mendapatkan pengekodan kedudukan relatif setiap langkah. Terutama untuk urutan yang lebih panjang. Ini disebabkan terutamanya oleh langkah pengiraan tambahan dalam lapisan perhatian kendiri, di mana matriks kedudukan ditambahkan pada matriks kunci pertanyaan.
- Kerumitan penggunaan cache nilai kunci: Memandangkan setiap token tambahan mengubah pembenaman setiap token lain, ini merumitkan penggunaan berkesan cache nilai kunci dalam Transformer. Satu keperluan untuk menggunakan cache KV ialah pengekodan kedudukan bagi perkataan yang telah dijana tidak berubah apabila menjana perkataan baharu (pengekodan kedudukan mutlak menyediakan) jadi pengekodan kedudukan relatif tidak sesuai untuk inferens kerana pembenaman setiap token akan berubah dengan setiap perubahan baharu dengan langkah masa.
Disebabkan kerumitan kejuruteraan ini, pengekodan kedudukan belum diterima pakai secara meluas, terutamanya dalam model bahasa yang lebih besar.
Pengekodan Kedudukan Putaran (RoPE)?
RoPE mewakili cara baharu pengekodan maklumat lokasi. Kedua-dua kaedah mutlak dan kaedah relatif dalam kaedah tradisional mempunyai batasannya. Pengekodan kedudukan mutlak memberikan vektor unik kepada setiap kedudukan, yang mudah tetapi tidak berskala dengan baik dan tidak dapat menangkap kedudukan relatif secara berkesan memfokuskan pada jarak antara penanda, meningkatkan pemahaman model tentang hubungan penanda, tetapi menjadikan reka bentuk model menjadi rumit; .
RoPE bijak menggabungkan kelebihan kedua-duanya. Mengekodkan maklumat lokasi dengan cara yang membolehkan model memahami lokasi mutlak penanda dan jarak relatifnya. Ini dicapai melalui mekanisme putaran, di mana setiap kedudukan dalam urutan diwakili oleh putaran dalam ruang benam. Keanggunan RoPE terletak pada kesederhanaan dan kecekapannya, yang membolehkan model memahami dengan lebih baik nuansa sintaks dan semantik bahasa.
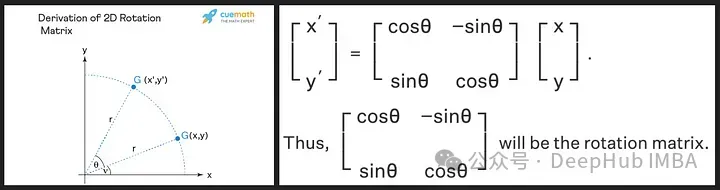
Matriks putaran diperoleh daripada sifat trigonometri sinus dan kosinus yang kita pelajari di sekolah menengah, menggunakan matriks 2D sepatutnya cukup untuk mendapatkan teori matriks putaran seperti yang ditunjukkan di bawah!

Kita lihat bahawa matriks putaran mengekalkan saiz (atau panjang) vektor asal, seperti yang ditunjukkan oleh "r" dalam imej di atas, satu-satunya perkara yang berubah ialah sudut dengan paksi-x.
RoPE memperkenalkan konsep baru. Daripada menambah vektor kedudukan, ia menggunakan putaran pada vektor perkataan. Sudut putaran (θ) adalah berkadar dengan kedudukan perkataan dalam ayat. Vektor pada kedudukan pertama diputarkan oleh θ, vektor pada kedudukan kedua diputar sebanyak 2θ, dan seterusnya. Pendekatan ini mempunyai beberapa faedah:
- Kestabilan vektor: Menambah penanda pada akhir ayat tidak menjejaskan vektor perkataan permulaan, yang bermanfaat untuk caching yang cekap.
- Pemeliharaan kedudukan relatif: Jika dua perkataan mengekalkan jarak relatif yang sama dalam konteks yang berbeza, vektornya akan diputar dengan jumlah yang sama. Ini memastikan bahawa sudut, serta hasil darab titik antara vektor ini, kekal malar
Formula matriks RoPE
Pelaksanaan teknikal RoPE melibatkan matriks putaran. Dalam kes 2D, persamaan dalam kertas mengandungi matriks putaran yang memutarkan vektor sebanyak Mθ darjah, di mana M ialah kedudukan mutlak dalam ayat. Putaran ini digunakan pada vektor pertanyaan dan vektor kunci dalam mekanisme perhatian kendiri Transformer.
Untuk dimensi yang lebih tinggi, vektor dibahagikan kepada blok 2D, dan setiap pasangan diputar secara berasingan. Ini boleh dianggap sebagai dimensi n berputar dalam ruang. Nampaknya kaedah ini rumit untuk dilaksanakan, tetapi ini tidak boleh dilaksanakan dengan cekap dalam perpustakaan seperti PyTorch dengan hanya kira-kira sepuluh baris kod.
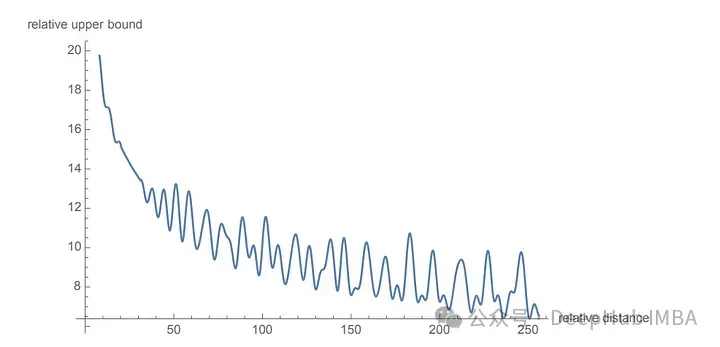
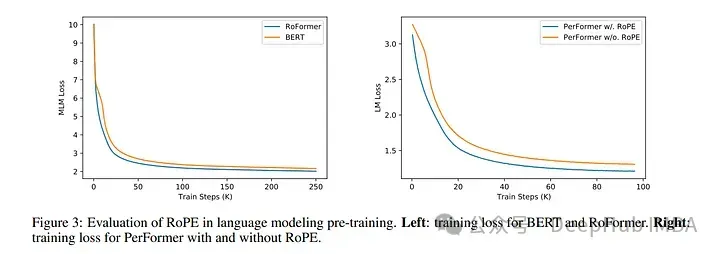
import torch import torch.nn as nn class RotaryPositionalEmbedding(nn.Module): def __init__(self, d_model, max_seq_len): super(RotaryPositionalEmbedding, self).__init__() # Create a rotation matrix. self.rotation_matrix = torch.zeros(d_model, d_model, device=torch.device("cuda")) for i in range(d_model): for j in range(d_model): self.rotation_matrix[i, j] = torch.cos(i * j * 0.01) # Create a positional embedding matrix. self.positional_embedding = torch.zeros(max_seq_len, d_model, device=torch.device("cuda")) for i in range(max_seq_len): for j in range(d_model): self.positional_embedding[i, j] = torch.cos(i * j * 0.01) def forward(self, x): """Args:x: A tensor of shape (batch_size, seq_len, d_model). Returns:A tensor of shape (batch_size, seq_len, d_model).""" # Add the positional embedding to the input tensor. x += self.positional_embedding # Apply the rotation matrix to the input tensor. x = torch.matmul(x, self.rotation_matrix) return x为了旋转是通过简单的向量运算而不是矩阵乘法来执行。距离较近的单词更有可能具有较高的点积,而距离较远的单词则具有较低的点积,这反映了它们在给定上下文中的相对相关性。
使用 RoPE 对 RoBERTa 和 Performer 等模型进行的实验表明,与正弦嵌入相比,它的训练时间更快。并且该方法在各种架构和训练设置中都很稳健。
最主要的是RoPE是可以外推的,也就是说可以直接处理任意长的问题。在最早的llamacpp项目中就有人通过线性插值RoPE扩张,在推理的时候直接通过线性插值将LLAMA的context由2k拓展到4k,并且性能没有下降,所以这也可以证明RoPE的有效性。
代码如下:
import transformers old_init = transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ def ntk_scaled_init(self, dim, max_position_embeddings=2048, base=10000, device=None): #The method is just these three linesmax_position_embeddings = 16384a = 8 #Alpha valuebase = base * a ** (dim / (dim-2)) #Base change formula old_init(self, dim, max_position_embeddings, base, device) transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ = ntk_scaled_init
总结
旋转位置嵌入代表了 Transformer 架构的范式转变,提供了一种更稳健、直观和可扩展的位置信息编码方式。
RoPE不仅解决了LLM context过长之后引起的上下文无法关联问题,并且还提高了训练和推理的速度。这一进步不仅增强了当前的语言模型,还为 NLP 的未来创新奠定了基础。随着我们不断解开语言和人工智能的复杂性,像 RoPE 这样的方法将有助于构建更先进、更准确、更类人的语言处理系统。
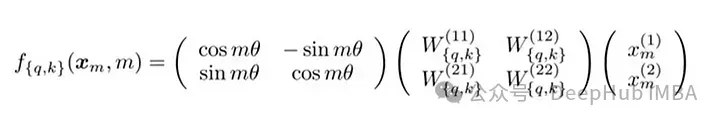
Atas ialah kandungan terperinci Penjelasan terperinci tentang pengekodan kedudukan putaran RoPE yang biasa digunakan dalam model bahasa besar: mengapa ia lebih baik daripada pengekodan kedudukan mutlak atau relatif?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Replika domestik pertama model R&D ChatGPT, model bahasa besar kerjasama strategik 360 dan Zhipu AI
- Contoh Pemprosesan Bahasa Semulajadi dalam Python: Terjemahan Mesin
- Pengiktirafan entiti yang dinamakan dan teknologi pengekstrakan perhubungan dan aplikasi dalam pemprosesan bahasa semula jadi berasaskan Java
- Cara menggunakan bahasa Go untuk pemprosesan bahasa semula jadi
- Pemprosesan bahasa semula jadi sepintas lalu