
Rumah >Peranti teknologi >AI >Untuk menjadikan Transformer pose video pantas, Universiti Peking mencadangkan rangka kerja anggaran pose manusia 3D yang cekap HoT
Untuk menjadikan Transformer pose video pantas, Universiti Peking mencadangkan rangka kerja anggaran pose manusia 3D yang cekap HoT

- 王林ke hadapan
- 2024-04-01 11:31:32923semak imbas
Pada masa ini, Video Pose Transformer (VPT) telah mencapai prestasi paling terkemuka dalam bidang anggaran pose manusia 3D berasaskan video. Dalam tahun-tahun kebelakangan ini, beban kerja pengiraan VPT ini telah menjadi semakin besar, dan beban kerja pengiraan yang besar ini juga telah mengehadkan pembangunan selanjutnya dalam bidang ini. Ia sangat tidak mesra penyelidik dengan sumber pengkomputeran yang tidak mencukupi. Sebagai contoh, melatih model VPT 243 bingkai biasanya mengambil masa beberapa hari, secara serius memperlahankan kemajuan penyelidikan dan menjadi titik kesakitan utama dalam bidang yang perlu diselesaikan dengan segera.
Jadi, bagaimana untuk meningkatkan kecekapan VPT dengan berkesan tanpa hampir kehilangan ketepatan?
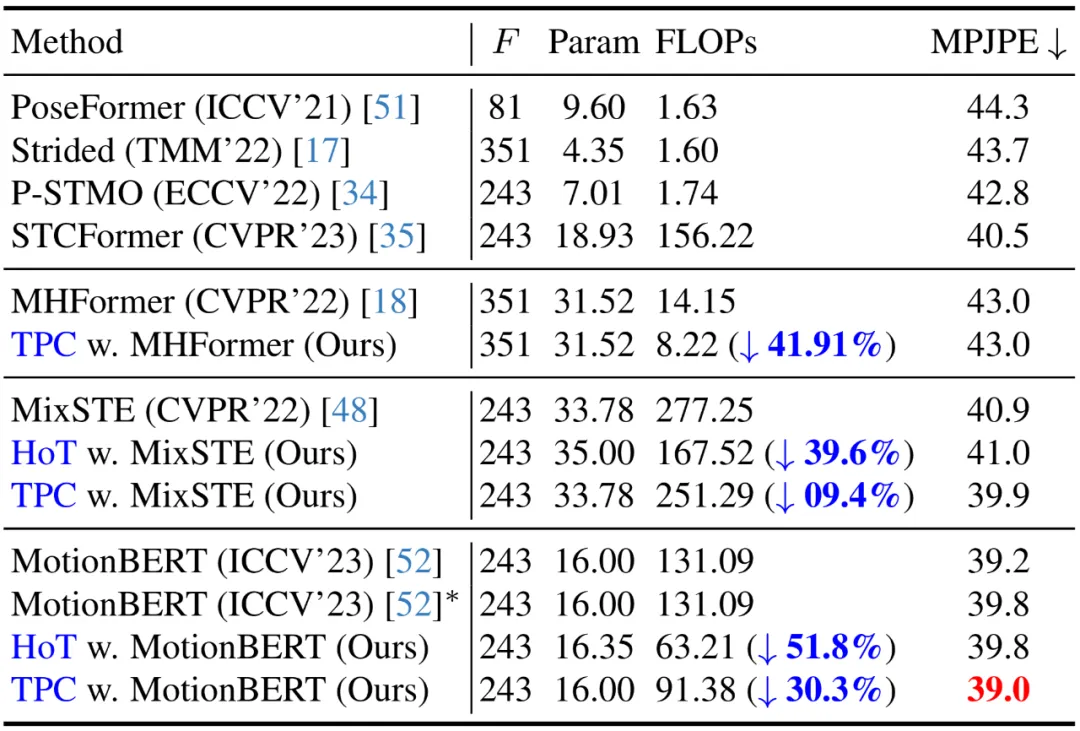
Sebuah pasukan dari Universiti Peking mencadangkan rangka kerja anggaran pose manusia 3D yang cekap HoT berdasarkan Tokenizer jam pasir untuk menyelesaikan masalah keperluan pengkomputeran tinggi bagi Video Pose Transformer (VPT) sedia ada. Rangka kerja boleh pasang dan main dan disepadukan dengan lancar ke dalam model seperti MHFormer, MixSTE dan MotionBERT, mengurangkan pengiraan model sebanyak hampir 40% tanpa kehilangan ketepatan Kod ini telah bersumberkan terbuka.

- Title: Tokenizer Hourglass untuk Pengiraan Manusia Berbasis Berasaskan Transformer yang cekap Alamat Paper: https://arxiv.org/abs/2311.1202 8
- Alamat kod: https://github.com/NationalGAILab/HoT

selalunya dalam video
Motivasi penyelidikan🜎 diproses menjadi Token Pose kendiri yang mencapai prestasi unggul dengan memproses jujukan video yang panjangnya beratus-ratus bingkai (biasanya 243 hingga 351 bingkai) dan mengekalkan perwakilan jujukan panjang penuh merentas semua lapisan Transformer. Walau bagaimanapun, oleh kerana kerumitan pengiraan mekanisme perhatian kendiri dalam VPT adalah berkadar dengan kuasa dua bilangan Token (iaitu, bilangan bingkai video), model ini tidak dapat dielakkan membawa ketidakcekapan yang besar apabila memproses input video dengan resolusi siri masa yang lebih tinggi. Overhed pengiraan menjadikannya sukar untuk digunakan secara meluas dalam aplikasi praktikal dengan sumber pengkomputeran yang terhad. Di samping itu, cara memproses keseluruhan jujukan ini tidak mengambil kira redundansi dalam jujukan video, terutamanya redundansi antara bingkai berturut-turut di mana perubahan visual tidak jelas, supaya pengulangan maklumat ini bukan sahaja menambah beban pengiraan yang tidak perlu, dan sebahagian besarnya tidak memberikan sumbangan yang besar kepada peningkatan prestasi model.
diproses menjadi Token Pose kendiri yang mencapai prestasi unggul dengan memproses jujukan video yang panjangnya beratus-ratus bingkai (biasanya 243 hingga 351 bingkai) dan mengekalkan perwakilan jujukan panjang penuh merentas semua lapisan Transformer. Walau bagaimanapun, oleh kerana kerumitan pengiraan mekanisme perhatian kendiri dalam VPT adalah berkadar dengan kuasa dua bilangan Token (iaitu, bilangan bingkai video), model ini tidak dapat dielakkan membawa ketidakcekapan yang besar apabila memproses input video dengan resolusi siri masa yang lebih tinggi. Overhed pengiraan menjadikannya sukar untuk digunakan secara meluas dalam aplikasi praktikal dengan sumber pengkomputeran yang terhad. Di samping itu, cara memproses keseluruhan jujukan ini tidak mengambil kira redundansi dalam jujukan video, terutamanya redundansi antara bingkai berturut-turut di mana perubahan visual tidak jelas, supaya pengulangan maklumat ini bukan sahaja menambah beban pengiraan yang tidak perlu, dan sebahagian besarnya tidak memberikan sumbangan yang besar kepada peningkatan prestasi model.
Oleh itu, untuk mencapai VPT yang cekap, artikel ini percaya bahawa dua faktor perlu dipertimbangkan terlebih dahulu:
Medan penerimaan masa hendaklah besar: Walaupun memendekkan secara langsung panjang jujukan input boleh meningkatkan kecekapan VPT, berbuat demikian Ia akan mengurangkan medan penerimaan masa model, dengan itu mengehadkan model untuk menangkap maklumat spatiotemporal yang kaya, mengekang peningkatan prestasi. Oleh itu, mengekalkan medan penerimaan temporal yang besar adalah penting untuk mencapai anggaran yang tepat apabila mengejar strategi reka bentuk yang cekap.
-
Lewahan video perlu dialih keluar: Disebabkan persamaan tindakan antara bingkai bersebelahan, video selalunya mengandungi sejumlah besar maklumat berlebihan. Di samping itu, penyelidikan sedia ada telah menunjukkan bahawa dalam seni bina Transformer, apabila lapisan semakin mendalam, perbezaan antara Token menjadi lebih kecil dan lebih kecil. Oleh itu, boleh disimpulkan bahawa menggunakan Token Pose penuh dalam lapisan dalam Transformer akan memperkenalkan pengiraan berlebihan yang tidak perlu, dan pengiraan berlebihan ini akan mempunyai sumbangan terhad kepada keputusan anggaran akhir.
Berdasarkan dua pemerhatian ini, penulis mencadangkan untuk memangkas Token Pose Transformer dalam untuk mengurangkan lebihan bingkai video sambil meningkatkan kecekapan keseluruhan VPT. Walau bagaimanapun, ini menimbulkan cabaran baharu: operasi pemangkasan membawa kepada pengurangan bilangan Token Pada masa ini, model tidak boleh menganggarkan secara langsung bilangan hasil anggaran pose tiga dimensi yang sepadan dengan jujukan video asal. Ini kerana, dalam model VPT tradisional, setiap Token biasanya sepadan dengan satu bingkai dalam video, dan urutan yang tinggal selepas pemangkasan tidak akan mencukupi untuk menutup semua bingkai video asal Ini bermasalah apabila menganggarkan tiga dimensi pose manusia semua bingkai dalam video menjadi halangan yang ketara. Oleh itu, untuk mencapai VPT yang cekap, satu lagi faktor penting perlu diambil kira: - Taakulan Seq2seq: Sistem anggaran pose manusia 3D sebenar seharusnya dapat melakukan penaakulan pantas melalui seq2seq, iaitu, menganggarkan pose manusia 3D bagi semua bingkai daripada video input sekaligus. Oleh itu, untuk mencapai penyepaduan yang lancar dengan rangka kerja VPT sedia ada dan mencapai inferens yang cepat, adalah perlu untuk memastikan integriti jujukan Token, iaitu, untuk memulihkan Token penuh yang sama dengan bilangan bingkai video input.
Berdasarkan tiga pertimbangan di atas, penulis mencadangkan rangka kerja anggaran pose manusia tiga dimensi yang cekap berdasarkan struktur jam pasir, ⏳ Hourglass Tokenizer (HoT). Secara umum, kaedah ini mempunyai dua sorotan utama:
- Simple Baseline, rangka kerja universal dan cekap berdasarkan Transformer
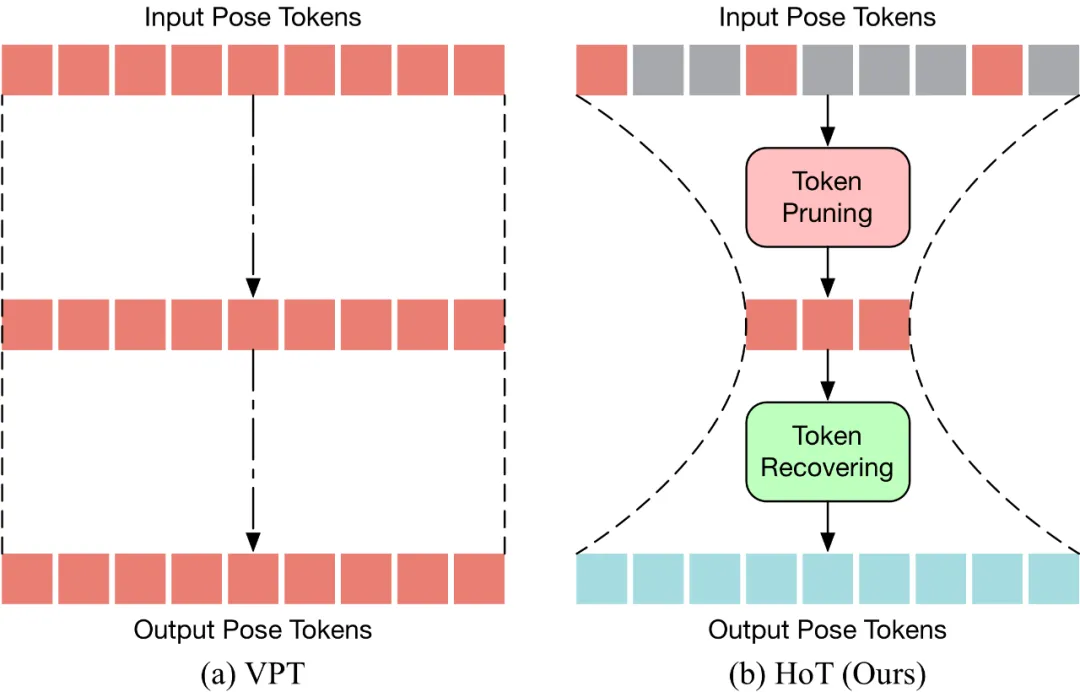
HoT ialah palam anggaran 3D Transformer yang cekap pertama berdasarkan pose manusia rangka kerja dan bermain. Seperti yang ditunjukkan dalam rajah di bawah, VPT tradisional menggunakan paradigma "segi empat tepat", iaitu, mengekalkan panjang penuh Token Pose dalam semua lapisan model, yang membawa kos pengiraan yang tinggi dan lebihan ciri. Berbeza daripada VPT tradisional, prun pertama HoT untuk membuang token berlebihan, dan kemudian memulihkan keseluruhan jujukan token (kelihatan seperti "jam pasir"), supaya hanya sejumlah kecil token dikekalkan di lapisan tengah Transformer, dengan itu berkesan meningkatkan kecekapan model. HoT juga menunjukkan kepelbagaian yang sangat tinggi ia bukan sahaja boleh disepadukan dengan lancar ke dalam model VPT konvensional, sama ada VPT berdasarkan seq2seq atau seq2frame, ia juga boleh disesuaikan dengan pelbagai strategi pemangkasan dan pemulihan Token. Kecekapan dan ketepatan

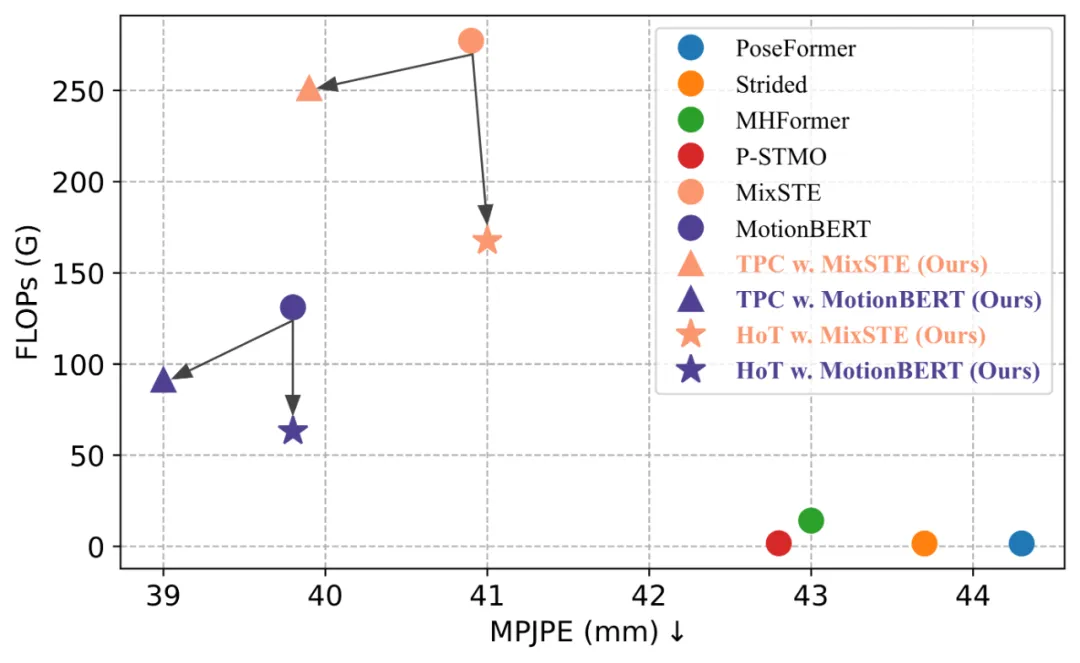
Hot mendedahkan bahawa mengekalkan urutan pose penuh adalah berlebihan, dan menggunakan sebilangan kecil bingkai perwakilan pose token secara serentak dapat mencapai tinggi Kecekapan dan prestasi tinggi. Berbanding dengan model VPT tradisional, HoT bukan sahaja meningkatkan kecekapan pemprosesan dengan ketara, tetapi juga mencapai hasil yang sangat kompetitif atau lebih baik. Sebagai contoh, ia boleh mengurangkan FLOP MotionBERT sebanyak hampir 50% tanpa mengorbankan prestasi, sambil mengurangkan FLOP MixSTE sebanyak hampir 40% dengan hanya penurunan prestasi sedikit sebanyak 0.2%. Rangka kerja keseluruhan HoT yang dicadangkan oleh
- kaedah model
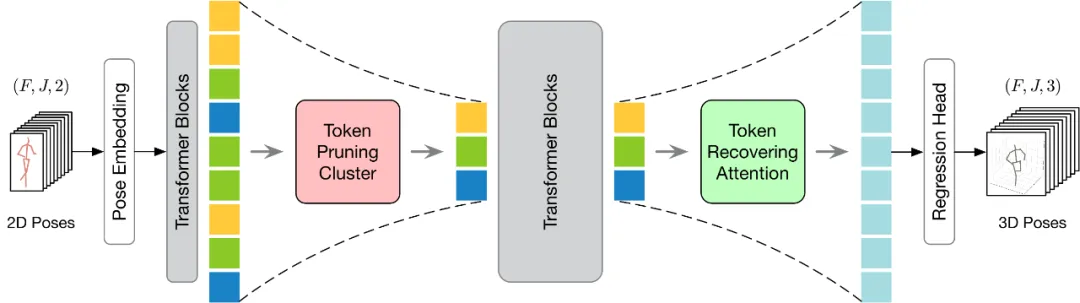
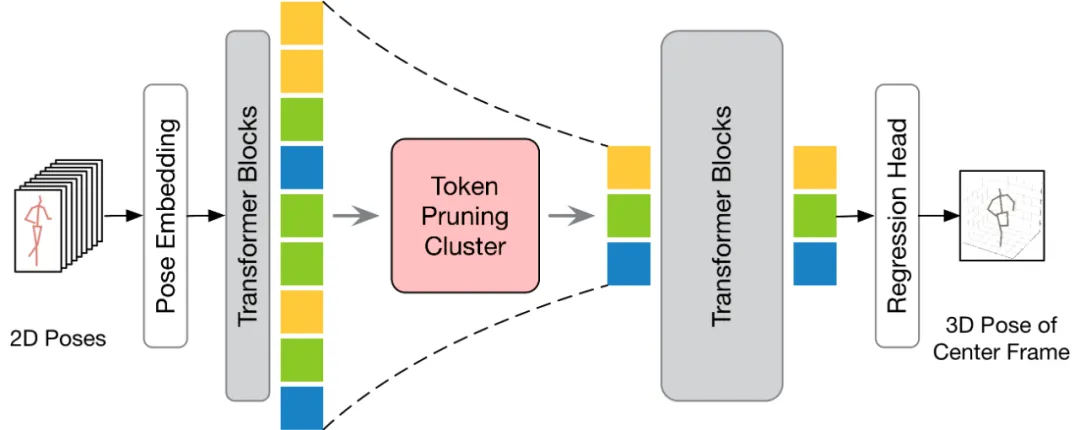
ditunjukkan dalam rajah di bawah. Untuk melaksanakan pemangkasan dan pemulihan Token dengan lebih berkesan, artikel ini mencadangkan dua modul: Kluster Pemangkasan Token (TPC) dan Perhatian Pemulihan Token (TRA). Antaranya, modul TPC secara dinamik memilih sebilangan kecil token perwakilan dengan kepelbagaian semantik yang tinggi sambil mengurangkan lebihan bingkai video. Modul TRA memulihkan maklumat spatiotemporal terperinci berdasarkan token terpilih, dengan itu memanjangkan output rangkaian kepada resolusi temporal penuh yang asal untuk inferens pantas.
Modul pemangkasan dan pengelompokan token
Artikel ini percaya bahawa adalah sukar untuk memilih sebilangan kecil Token Pose dengan maklumat yang kaya untuk perkiraan tiga dimensi manusia.
Untuk menyelesaikan masalah ini, artikel ini percaya bahawa kuncinya ialah memilih token perwakilan dengan kepelbagaian semantik yang tinggi, kerana token tersebut boleh mengekalkan maklumat yang diperlukan sambil mengurangkan redundansi video. Berdasarkan konsep ini, artikel ini mencadangkan modul Kluster Pemangkasan Token (TPC) yang ringkas dan berkesan yang tidak memerlukan parameter tambahan. Teras modul ini adalah untuk mengenal pasti dan mengalih keluar token yang memberikan sumbangan semantik yang kecil, dan fokus pada token tersebut yang boleh memberikan maklumat penting untuk anggaran pose manusia tiga dimensi terakhir. Dengan menggunakan algoritma pengelompokan, TPC secara dinamik memilih pusat gugusan sebagai token perwakilan, dengan itu menggunakan ciri-ciri pusat gugusan untuk mengekalkan semantik kaya bagi data asal. Struktur TPC ditunjukkan dalam rajah di bawah Ia pertama kali mengumpulkan Token Pose masukan dalam dimensi ruang, dan kemudian menggunakan persamaan ciri Token terkumpul untuk mengelompokkan Token input dan memilih pusat kluster token perwakilan.
Modul Perhatian Pemulihan Token
Modul TPC secara berkesan mengurangkan bilangan Token Pose Walau bagaimanapun, penurunan dalam resolusi masa yang disebabkan oleh operasi pemangkasan mengehadkan VPT untuk inferens seq2seq yang pantas. Oleh itu, Token perlu dipulihkan. Pada masa yang sama, dengan mengambil kira faktor kecekapan, modul pemulihan harus direka bentuk agar ringan untuk meminimumkan kesan ke atas kos pengiraan model keseluruhan.
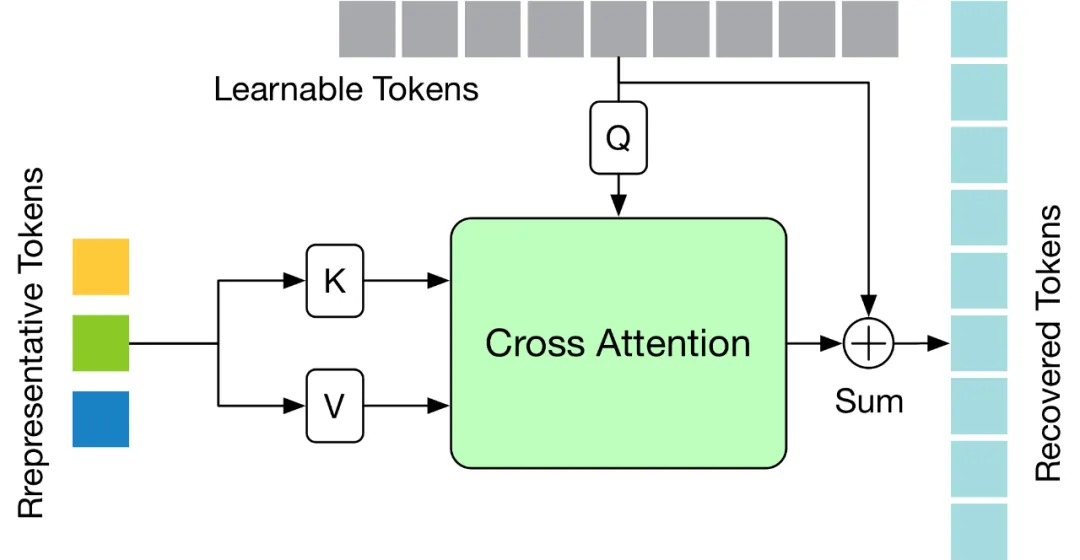
Untuk menyelesaikan cabaran di atas, artikel ini mereka bentuk modul Token Memulihkan Perhatian (TRA) ringan, yang boleh memulihkan maklumat spatiotemporal terperinci berdasarkan Token yang dipilih. Dengan cara ini, resolusi temporal rendah yang disebabkan oleh operasi pemangkasan diperluaskan dengan berkesan kepada resolusi temporal urutan lengkap asal, membolehkan rangkaian menganggarkan jujukan pose manusia tiga dimensi bagi semua bingkai sekaligus, dengan itu mencapai penaakulan seq2seq yang pantas. Struktur modul
TRA ditunjukkan dalam rajah di bawah Ia menggunakan Token wakil dalam lapisan terakhir Transformer dan Token yang boleh dipelajari dimulakan kepada sifar untuk memulihkan urutan Token yang lengkap melalui mekanisme perhatian silang yang mudah.
Digunakan pada VPT sedia ada
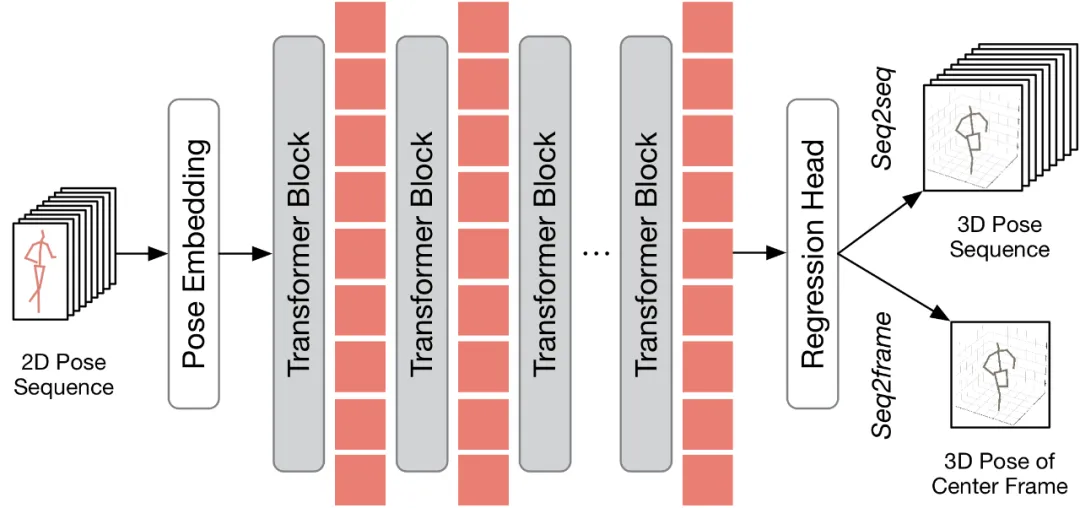
Sebelum membincangkan cara menggunakan kaedah yang dicadangkan kepada VPT sedia ada, kertas kerja ini terlebih dahulu meringkaskan seni bina VPT sedia ada. Seperti yang ditunjukkan dalam rajah di bawah, seni bina VPT terutamanya terdiri daripada tiga komponen: modul benam pose digunakan untuk mengekod maklumat spatial dan temporal urutan pose, Transformer berbilang lapisan digunakan untuk mempelajari perwakilan spatiotemporal global, dan modul kepala regresi digunakan untuk mengembalikan hasil postur manusia output tiga dimensi.
Mengikut bilangan bingkai keluaran, VPT sedia ada boleh dibahagikan kepada dua proses inferens: seq2frame dan seq2seq. Dalam saluran paip seq2seq, output ialah semua bingkai video input, jadi resolusi pemasaan panjang penuh asal perlu dipulihkan. Seperti yang ditunjukkan dalam rajah rangka kerja HoT, kedua-dua modul TPC dan TRA dibenamkan dalam VPT. Dalam proses seq2frame, output ialah pose 3D bingkai tengah video. Oleh itu, di bawah proses ini, modul TRA tidak diperlukan dan hanya modul TPC disepadukan dalam VPT. Rangka kerjanya ditunjukkan dalam rajah di bawah. . Keputusan menunjukkan bahawa dengan menggunakan kaedah yang dicadangkan pada VPT sedia ada, kaedah ini dapat mengurangkan FLOP dengan ketara dan meningkatkan FPS dengan ketara sambil mengekalkan bilangan parameter model hampir tidak berubah. Di samping itu, berbanding dengan model asal, kaedah yang dicadangkan pada dasarnya adalah sama dalam prestasi atau boleh mencapai prestasi yang lebih baik.
Artikel ini juga membandingkan strategi pemangkasan Token yang berbeza, termasuk pemangkasan skor perhatian, pensampelan seragam, dan strategi pemangkasan gerakan yang memilih Token k teratas dengan jumlah gerakan yang lebih besar Ia boleh dilihat bahawa TPC yang dicadangkan memperoleh prestasi terbaik.
Artikel ini juga membandingkan strategi pemulihan Token yang berbeza, termasuk interpolasi jiran terdekat dan interpolasi linear Ia dapat dilihat bahawa TRA yang dicadangkan mencapai prestasi terbaik. . Untuk mengesahkan keberkesanan kaedah ini, penulis menggunakannya pada tiga model VPT terkini: MHForme, MixSTE dan MotionBERT, dan bandingkan dengan mereka dari segi kuantiti parameter, FLOP dan MPJPE.
Seperti yang ditunjukkan dalam jadual di bawah, kaedah ini mengurangkan jumlah pengiraan model SOTA VPT dengan ketara sambil mengekalkan ketepatan asal. Keputusan ini bukan sahaja mengesahkan keberkesanan dan kecekapan tinggi kaedah ini, tetapi juga mendedahkan bahawa terdapat lebihan pengiraan dalam model VPT sedia ada, dan lebihan ini menyumbang sedikit kepada prestasi anggaran akhir, malah mungkin membawa kepada kemerosotan prestasi. Di samping itu, kaedah ini boleh menghapuskan pengiraan yang tidak perlu ini sambil mencapai prestasi yang sangat kompetitif atau lebih baik.
Kod berjalan
Pengarang juga menyediakan larian demo (https://github.com/NationalGAILab/HoT), yang mengintegrasikan pengesan manusia YOLOv3, pengesan sikap dua dimensi HRNet, HoT. Penambah pose MixSTE 2D hingga 3D. Muat turun sahaja model pra-latihan yang disediakan oleh pengarang, masukkan video pendek yang mengandungi orang dan anda boleh terus mengeluarkan demo anggaran pose manusia 3D dengan satu baris kod. . Transforme (VPT) , HoT), yang merupakan rangka kerja pemangkasan dan pemulihan Token pasang-dan-main untuk anggaran pose manusia 3D berasaskan Transformer yang cekap daripada video. Kajian mendapati bahawa mengekalkan urutan pose penuh dalam VPT adalah tidak perlu dan menggunakan sebilangan kecil bingkai perwakilan Token Pose boleh mencapai ketepatan dan kecekapan yang tinggi. Sebilangan besar percubaan telah mengesahkan keserasian tinggi dan kebolehgunaan meluas kaedah ini. Ia boleh disepadukan dengan mudah ke dalam pelbagai model VPT biasa, sama ada VPT berdasarkan seq2seq atau seq2frame, dan boleh menyesuaikan diri dengan berkesan kepada pelbagai strategi pemangkasan dan pemulihan token, yang menunjukkan potensi besarnya. Penulis mengharapkan HoT untuk memacu pembangunan VPT yang lebih kuat dan lebih pantas.
Atas ialah kandungan terperinci Untuk menjadikan Transformer pose video pantas, Universiti Peking mencadangkan rangka kerja anggaran pose manusia 3D yang cekap HoT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!