
Rumah >Peranti teknologi >AI >Tsinghua Microsoft sumber terbuka alat pemampatan perkataan segera baharu, panjangnya menurun sebanyak 80%! GitHub mendapat 3.1K bintang
Tsinghua Microsoft sumber terbuka alat pemampatan perkataan segera baharu, panjangnya menurun sebanyak 80%! GitHub mendapat 3.1K bintang

- 王林ke hadapan
- 2024-03-26 18:36:02471semak imbas
Dalam pemprosesan bahasa semula jadi, banyak maklumat sebenarnya diulang.
Jika perkataan gesaan boleh dimampatkan dengan berkesan, ia sama dengan mengembangkan panjang konteks yang disokong oleh model sedikit sebanyak.
Kaedah entropi maklumat sedia ada mengurangkan lebihan ini dengan mengalih keluar perkataan atau frasa tertentu.
Walau bagaimanapun, pengiraan berdasarkan entropi maklumat hanya meliputi konteks sehala teks dan mungkin mengabaikan maklumat penting yang diperlukan untuk pemampatan tambahan pula, kaedah pengiraan entropi maklumat tidak sepenuhnya konsisten dengan tujuan sebenar memampatkan segera perkataan.
Untuk menghadapi cabaran ini, penyelidik dari Universiti Tsinghua dan Microsoft bersama-sama mencadangkan proses pemprosesan data baharu yang dipanggil LLMLingua-2. Ia bertujuan untuk mengekstrak pengetahuan daripada model bahasa besar (LLM) dan mencapai pemurnian maklumat dengan memampatkan perkataan segera sambil memastikan maklumat penting tidak hilang.
Projek ini telah memperoleh 3.1k bintang di GitHub
Hasilnya menunjukkan bahawa LLMLingua-2 boleh mengurangkan panjang teks dengan ketara kepada 20%, dengan berkesan mengurangkan masa dan kos pemprosesan.
Selain itu, kelajuan pemprosesan LLMLingua 2 meningkat 3 hingga 6 kali ganda berbanding versi LLMLingua sebelumnya dan teknologi lain yang serupa.

Alamat kertas: https://arxiv.org/abs/2403.12968
Dalam proses ini, teks asal dimasukkan pertama ke dalam model.
Model akan menilai kepentingan setiap perkataan dan memutuskan sama ada untuk mengekalkan atau memadamkannya, di samping mengambil kira hubungan antara perkataan.
Akhir sekali, model akan memilih perkataan yang mempunyai markah tertinggi untuk membentuk perkataan gesaan yang lebih pendek.
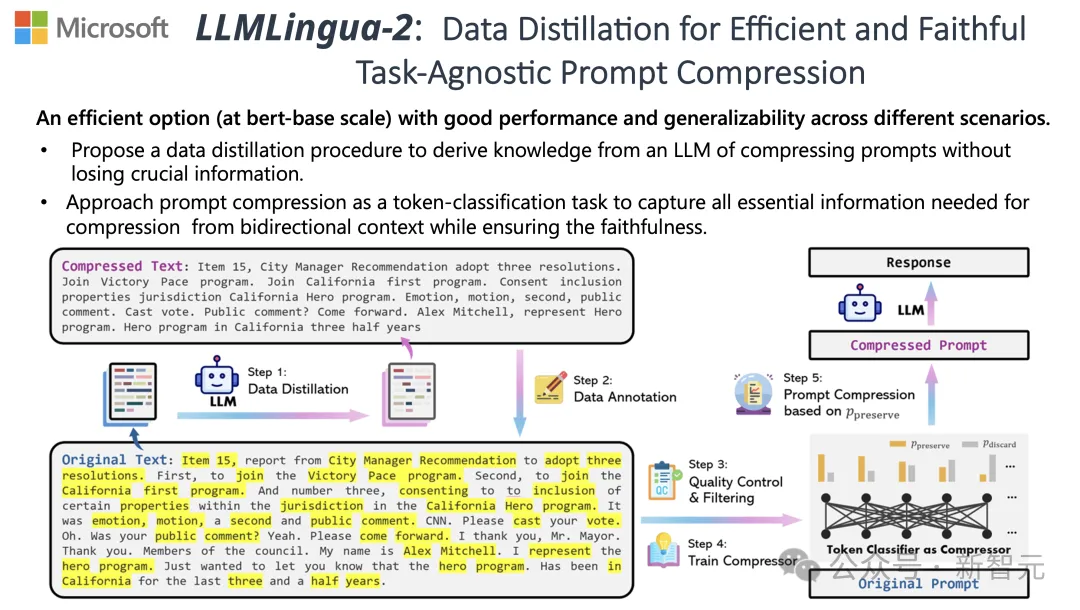
Pasukan menguji model LLMLingua-2 pada berbilang set data termasuk MeetingBank, LongBench, ZeroScrolls, GSM8K dan BBH.
Walaupun model ini bersaiz kecil, ia mencapai peningkatan prestasi yang ketara dalam ujian penanda aras dan membuktikan prestasinya dalam model bahasa besar yang berbeza (dari GPT-3.5 hingga Mistral-7B) dan bahasa (dari bahasa Inggeris kepada bahasa Cina) mempunyai keupayaan generalisasi yang sangat baik. .
Petua Pengguna:
Sila mampatkan teks yang diberikan menjadi ungkapan pendek supaya anda (GPT-4) boleh memulihkan teks asal setepat mungkin. Berbeza daripada pemampatan teks biasa, saya memerlukan anda mengikut lima syarat berikut:
1 Hanya keluarkan perkataan yang tidak penting itu. 2. Pastikan susunan perkataan asal tidak berubah.
3. Pastikan perbendaharaan kata asal tidak berubah.
4. Jangan gunakan sebarang singkatan atau emotikon.
5. Jangan tambah sebarang perkataan atau simbol baharu.
Sila mampatkan teks asal sebanyak mungkin sambil mengekalkan sebanyak mungkin maklumat. Jika anda faham, sila mampatkan teks berikut: {Teks untuk dimampatkan}
Teks yang dimampatkan ialah: [...]
Hasilnya menunjukkan bahawa dalam Soal Jawab, penulisan abstrak dan penaakulan logik Dalam pelbagai tugas bahasa, LLMLlingua-2 dengan ketara mengatasi model LLMLingua asal dan strategi konteks terpilih yang lain.
Perlu dinyatakan bahawa kaedah pemampatan ini sama-sama berkesan untuk model bahasa besar yang berbeza (dari GPT-3.5 hingga Mistral-7B) dan bahasa yang berbeza (dari bahasa Inggeris ke bahasa Cina).
Selain itu, penggunaan LLMLingua-2 boleh dicapai dengan hanya dua baris kod.
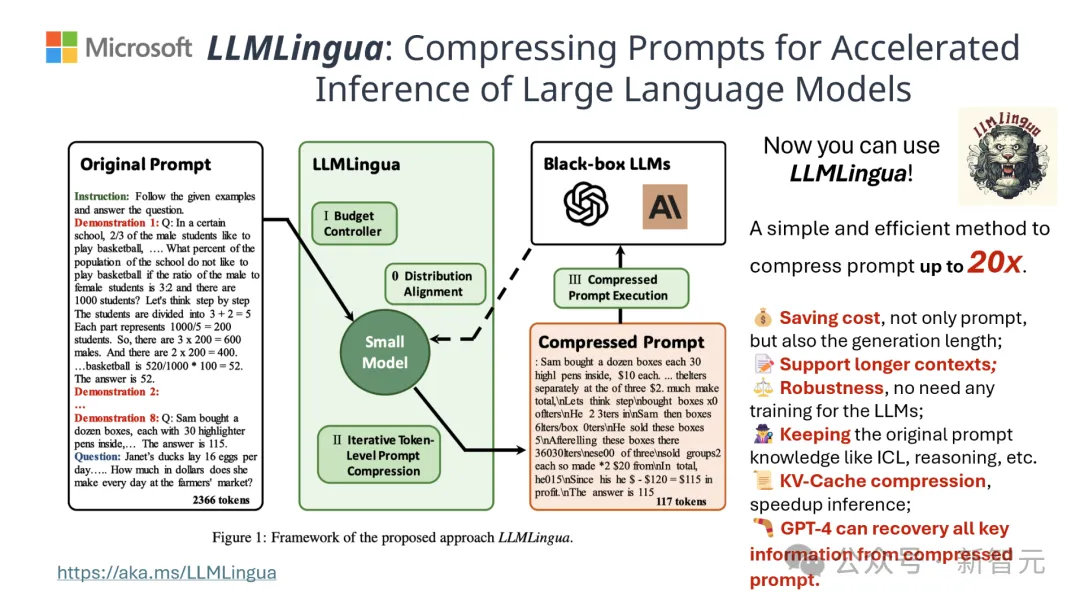
Pada masa ini, model itu telah disepadukan ke dalam rangka kerja RAG LangChain dan LlamaIndex yang digunakan secara meluas.
Kaedah pelaksanaan
Untuk mengatasi masalah yang dihadapi oleh kaedah pemampatan teks berasaskan entropi maklumat sedia ada, LLMLingua-2 mengamalkan strategi pengekstrakan data yang inovatif.
Strategi ini mencapai pemampatan teks yang cekap tanpa kehilangan kandungan utama dan mengelakkan penambahan maklumat yang salah dengan mengekstrak maklumat penting daripada model bahasa besar seperti GPT-4.
Petua Reka Bentuk
Untuk menggunakan sepenuhnya potensi pemampatan teks GPT-4, kuncinya terletak pada cara menetapkan arahan pemampatan yang tepat.
Iaitu, semasa memampatkan teks, arahkan GPT-4 untuk hanya mengalih keluar perkataan yang kurang penting dalam teks asal, sambil mengelakkan pengenalan mana-mana perkataan baharu dalam proses.
Tujuan ini adalah untuk memastikan teks yang dimampatkan mengekalkan keaslian dan integriti teks asal sebanyak mungkin.

Anotasi dan Penapisan
Penyelidik telah membangunkan algoritma anotasi data novel menggunakan pengetahuan yang diekstrak daripada model bahasa besar seperti GPT-4.
Algoritma ini boleh melabelkan setiap perkataan dalam teks asal dan dengan jelas menunjukkan perkataan yang mesti dikekalkan semasa proses pemampatan.
Untuk memastikan kualiti tinggi set data yang dibina, mereka juga mereka bentuk dua mekanisme pemantauan kualiti khusus untuk mengenal pasti dan menghapuskan sampel data yang berkualiti rendah.

Compressor
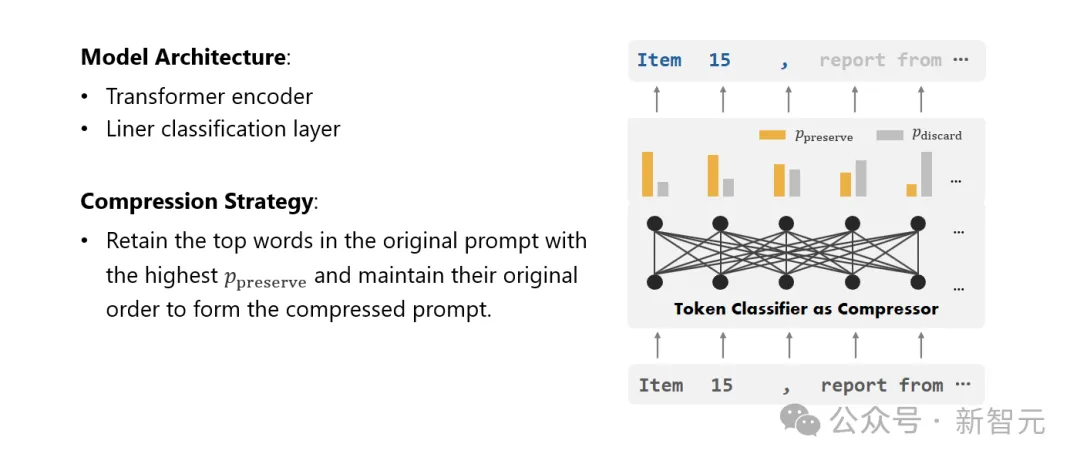
Akhir sekali, penyelidik mengubah masalah pemampatan teks menjadi tugas mengklasifikasikan setiap perbendaharaan kata (Token) dan menggunakan Transformer yang berkuasa sebagai ekstrak ciri.
Alat ini memahami konteks teks untuk menangkap maklumat yang penting untuk pemampatan teks dengan tepat.
Dengan melatih set data yang dibina dengan teliti, model penyelidik dapat mengira nilai kebarangkalian berdasarkan kepentingan setiap perkataan untuk memutuskan sama ada perkataan itu harus dikekalkan dalam teks mampat terakhir atau harus ditinggalkan.
Penilaian Prestasi
Para penyelidik menguji prestasi LLMLingua-2 pada pelbagai tugas, termasuk pembelajaran konteks, ringkasan teks, penjanaan dialog, soal jawab penjanaan berbilang dan dokumen tunggal, dan soal jawab. Tugas sintesis termasuk kedua-dua set data dalam domain dan set data luar domain.
Keputusan ujian menunjukkan bahawa kaedah penyelidik mengurangkan kehilangan prestasi minimum sambil mengekalkan prestasi tinggi, dan berprestasi cemerlang dalam kalangan kaedah pemampatan teks tidak khusus tugasan.
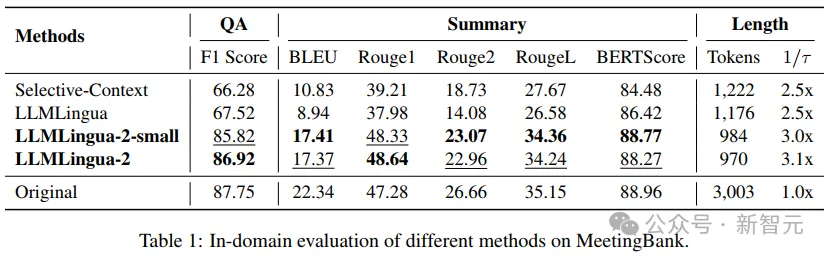
- Ujian dalam domain (MeetingBank)
Para penyelidik membandingkan prestasi LLMLingua-2 pada ujian MeetingBank yang ditetapkan dengan kaedah asas lain yang berkuasa.
Walaupun saiz model mereka jauh lebih kecil daripada LLaMa-2-7B yang digunakan dalam garis dasar, pada tugas menjawab soalan dan ringkasan teks, kaedah penyelidik bukan sahaja meningkatkan prestasi dengan ketara, tetapi juga dilakukan hampir seperti serta gesaan teks asal.
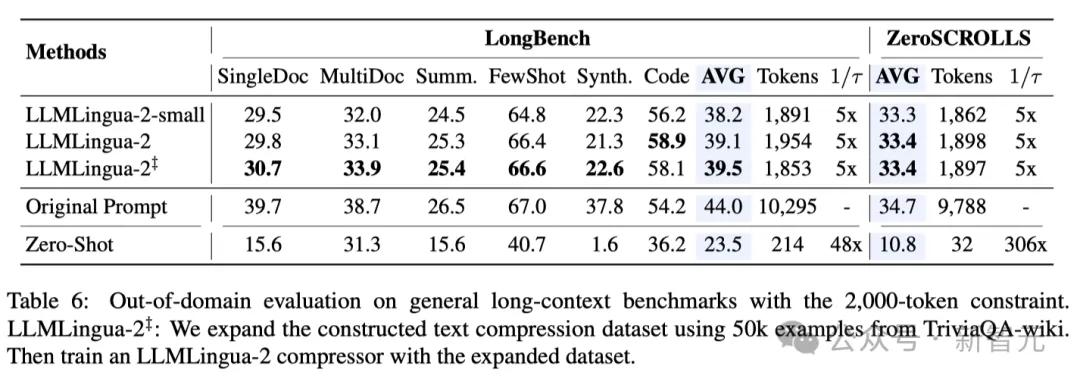
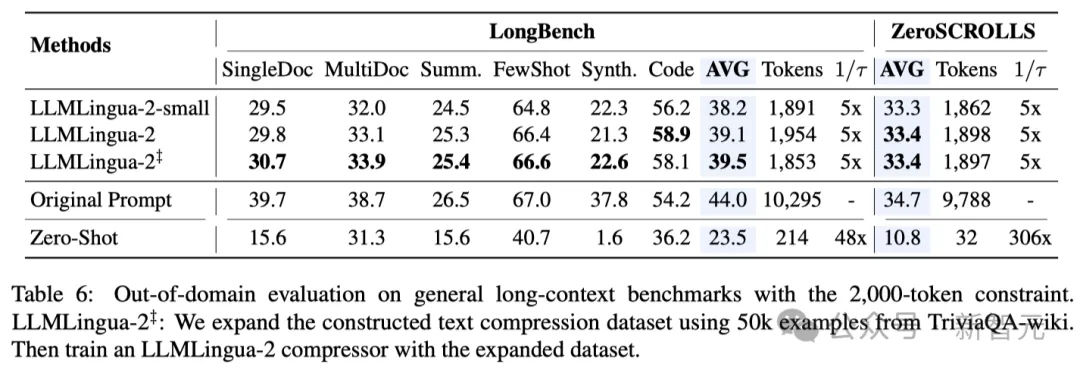
- Ujian di luar domain (LongBench, GSM8K dan BBH)
Memandangkan para penyelidik menggunakan data yang direkodkan hanya dilatih dalam mesyuarat Mesej. dalam keupayaan Generalisasi dalam senario yang berbeza seperti teks panjang, penaakulan logik dan pembelajaran kontekstual.
Perlu dinyatakan bahawa walaupun LLMLlingua-2 hanya dilatih pada satu set data, dalam ujian di luar domain, prestasinya bukan sahaja setanding dengan kaedah pemampatan tidak spesifik tugas terkini, malah dalam beberapa kes Lebih teruk lagi.
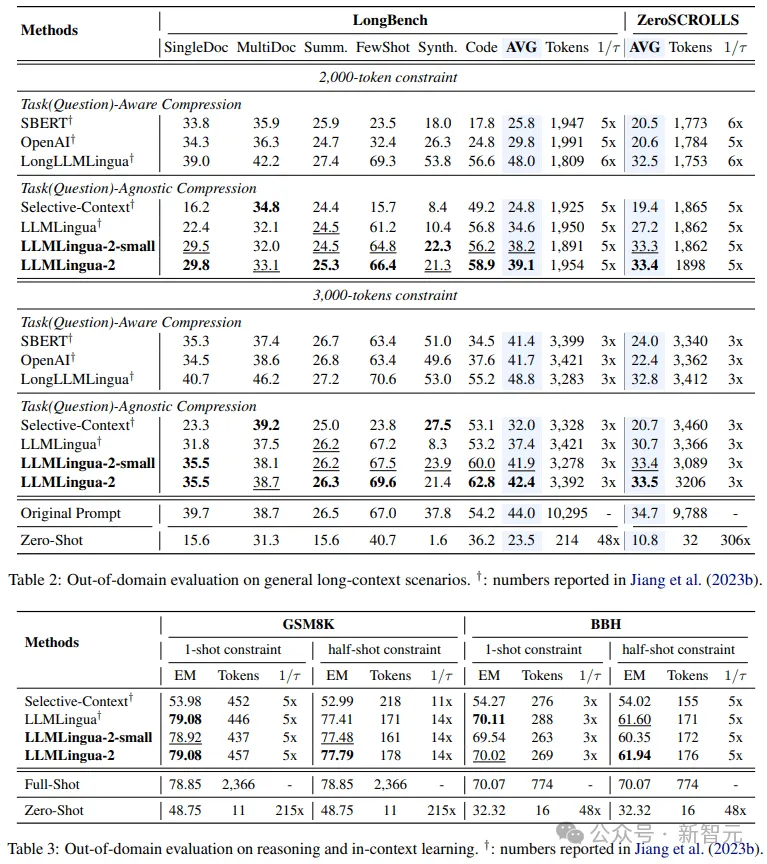
Malah model penyelidik yang lebih kecil (saiz asas BERT) mampu mencapai prestasi yang setanding dengan, dan dalam beberapa kes malah lebih baik sedikit daripada petunjuk asal.
Walaupun pendekatan penyelidik mencapai hasil yang memberangsangkan, ia masih mempunyai kelemahan jika dibandingkan dengan kaedah pemampatan sedar tugas lain seperti LongLLMlingua di Longbench.
Para penyelidik mengaitkan jurang prestasi ini kepada maklumat tambahan yang mereka peroleh daripada masalah tersebut. Walau bagaimanapun, model penyelidik adalah agnostik tugas, menjadikannya pilihan yang cekap dengan kebolehgeneralisasian yang baik apabila digunakan dalam senario yang berbeza.
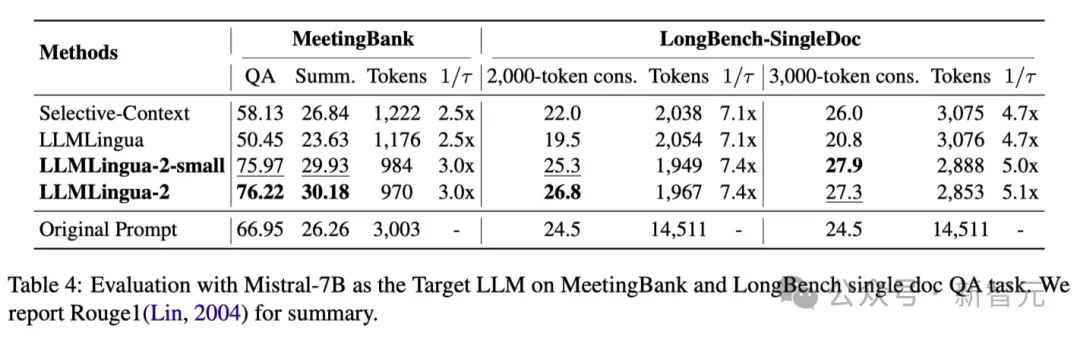
Jadual 4 di atas menyenaraikan keputusan kaedah berbeza menggunakan Mistral-7Bv0.1 4 sebagai LLM sasaran.
Berbanding dengan kaedah asas yang lain, kaedah penyelidik mempunyai peningkatan yang ketara dalam prestasi, menunjukkan keupayaan generalisasi yang baik pada LLM sasaran.
Perlu diperhatikan bahawa LLMLingua-2 berprestasi lebih baik daripada gesaan asal.
Penyelidik membuat spekulasi bahawa Mistral-7B mungkin tidak pandai mengurus konteks panjang seperti GPT-3.5-Turbo.
Pendekatan penyelidik secara berkesan meningkatkan prestasi inferens akhir Mistral7B dengan memberikan petunjuk ringkas dengan kepadatan maklumat yang lebih tinggi.
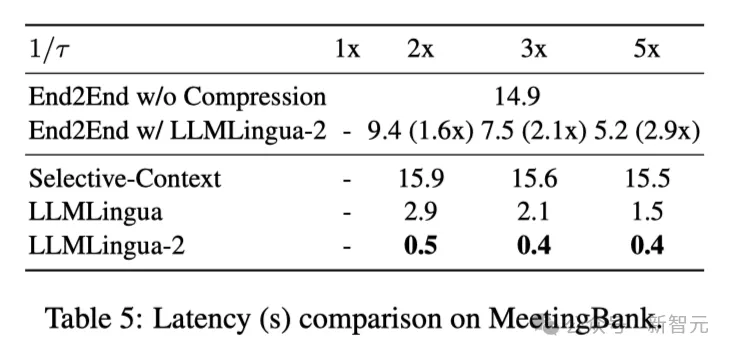
Jadual 5 di atas menunjukkan kependaman sistem berbeza pada GPU V100-32G dengan nisbah mampatan berbeza.
Hasilnya menunjukkan bahawa berbanding dengan kaedah pemampatan lain, LLMLingua2 mempunyai lebih sedikit overhed pengiraan dan boleh mencapai peningkatan kelajuan hujung ke hujung sebanyak 1.6x hingga 2.9x.
Di samping itu, kaedah penyelidik boleh mengurangkan kos memori GPU sebanyak 8 kali ganda, sekali gus mengurangkan permintaan untuk sumber perkakasan.
Pemerhatian Sedar Konteks Para penyelidik memerhatikan bahawa apabila nisbah mampatan meningkat, LLMLingua-2 boleh mengekalkan perkataan yang paling bermaklumat dengan konteks yang lengkap dengan berkesan.
Ini adalah terima kasih kepada penggunaan pengekstrak ciri peka konteks dua arah dan strategi yang mengoptimumkan secara eksplisit ke arah matlamat pemampatan tepat pada masanya.
Para penyelidik memerhatikan bahawa apabila nisbah mampatan meningkat, LLMLingua-2 boleh mengekalkan perkataan paling bermaklumat yang berkaitan dengan konteks lengkap dengan berkesan.
Ini adalah terima kasih kepada penggunaan pengekstrak ciri peka konteks dua hala dan strategi yang secara eksplisit mengoptimumkan ke arah matlamat pemampatan tepat pada masanya.
Akhirnya, penyelidik meminta GPT-4 untuk membina semula nada asal daripada pembayang mampatan LLMLlingua-2.
Hasilnya menunjukkan bahawa GPT-4 boleh membina semula petua asal dengan berkesan, menunjukkan bahawa tiada maklumat penting hilang semasa proses pemampatan LLMLingua-2.
Atas ialah kandungan terperinci Tsinghua Microsoft sumber terbuka alat pemampatan perkataan segera baharu, panjangnya menurun sebanyak 80%! GitHub mendapat 3.1K bintang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!