
Rumah >Peranti teknologi >AI >Selain CNN, Transformer dan Uniformer, kami akhirnya mempunyai teknologi pemahaman video yang lebih cekap
Selain CNN, Transformer dan Uniformer, kami akhirnya mempunyai teknologi pemahaman video yang lebih cekap

- PHPzke hadapan
- 2024-03-25 09:16:53739semak imbas
Matlamat teras pemahaman video adalah untuk memahami perwakilan spatiotemporal dengan tepat, tetapi ia menghadapi dua cabaran utama: terdapat banyak redundansi spatiotemporal dalam klip video pendek dan kebergantungan spatiotemporal yang kompleks. Rangkaian saraf konvolusi tiga dimensi (CNN) dan Transformer video telah menunjukkan prestasi yang baik dalam menyelesaikan salah satu cabaran ini, tetapi mereka mempunyai kelemahan tertentu dalam menangani kedua-dua cabaran secara serentak. UniFormer cuba untuk menggabungkan kelebihan kedua-dua pendekatan, tetapi menghadapi kesukaran dalam memodelkan video panjang.
Kemunculan penyelesaian kos rendah seperti S4, RWKV dan RetNet dalam bidang pemprosesan bahasa semula jadi telah membuka jalan baharu untuk model visual. Mamba menonjol dengan Model Ruang Negeri Terpilih (SSM), yang mencapai keseimbangan mengekalkan kerumitan linear sambil memudahkan pemodelan dinamik jangka panjang. Inovasi ini memacu aplikasinya dalam tugas penglihatan, seperti yang ditunjukkan oleh Vision Mamba dan VMamba, yang mengeksploitasi SSM berbilang arah untuk meningkatkan pemprosesan imej 2D. Model-model ini adalah setanding dalam prestasi dengan seni bina berasaskan perhatian sambil mengurangkan penggunaan memori dengan ketara.
Memandangkan jujukan yang dihasilkan oleh video itu sendiri lebih panjang, persoalan biasa ialah: adakah Mamba berfungsi dengan baik untuk pemahaman video?
Diinspirasikan oleh Mamba, artikel ini memperkenalkan VideoMamba, SSM (Selective State Space Model) yang disesuaikan khas untuk pemahaman video. VideoMamba menggunakan falsafah reka bentuk Vanilla ViT dan menggabungkan mekanisme lilitan dan perhatian. Ia menyediakan kaedah kerumitan linear untuk pemodelan latar belakang spatiotemporal dinamik, terutamanya sesuai untuk memproses video panjang resolusi tinggi. Penilaian ini tertumpu terutamanya pada empat keupayaan utama VideoMamba:
Skalabilitas dalam bidang visual: Artikel ini mengkaji kebolehskalaan VideoMamba dan mendapati bahawa model Mamba tulen cenderung untuk mudah dikembangkan apabila ia terus berkembang. . Sesuai, kertas kerja ini memperkenalkan strategi penyulingan kendiri yang mudah tetapi berkesan, yang membolehkan VideoMamba mencapai peningkatan prestasi yang ketara apabila model dan saiz input meningkat tanpa memerlukan latihan pra-latihan set data berskala besar.
Sensitiviti kepada pengecaman tindakan jangka pendek: Analisis dalam kertas kerja ini meliputi penilaian keupayaan VideoMamba untuk membezakan dengan tepat tindakan jangka pendek, terutamanya yang mempunyai perbezaan gerakan halus, seperti pembukaan dan penutupan. Hasil penyelidikan menunjukkan bahawa VideoMamba mempamerkan prestasi cemerlang berbanding model berasaskan perhatian sedia ada. Lebih penting lagi, ia juga sesuai untuk pemodelan topeng, meningkatkan lagi sensitiviti temporalnya.
Keunggulan dalam Pemahaman Video Panjang: Kertas kerja ini menilai keupayaan VideoMamba untuk mentafsir video panjang. Dengan latihan hujung ke hujung, ia menunjukkan kelebihan ketara berbanding kaedah berasaskan ciri tradisional. Terutama, VideoMamba berjalan 6x lebih pantas daripada TimeSformer pada video 64 bingkai dan memerlukan 40x kurang memori GPU (ditunjukkan dalam Rajah 1).

Kesesuaian dengan modaliti lain: Akhir sekali, artikel ini menilai kebolehsuaian VideoMamba dengan modaliti lain. Keputusan dalam pengambilan teks video menunjukkan prestasi yang lebih baik berbanding ViT, terutamanya dalam video panjang dengan senario yang kompleks. Ini menyerlahkan kekukuhan dan keupayaan penyepaduan pelbagai mod.
Eksperimen mendalam kajian ini mendedahkan potensi besar VideoMamba untuk pemahaman kandungan video jangka pendek (K400 dan SthSthV2) dan jangka panjang (Sarapan, COIN dan LVU). VideoMamba menunjukkan kecekapan dan ketepatan yang tinggi, menunjukkan bahawa ia akan menjadi komponen utama dalam bidang pemahaman video yang panjang. Untuk memudahkan penyelidikan masa depan, semua kod dan model telah dijadikan sumber terbuka.

- Alamat kertas: https://arxiv.org/pdf/2403.06977.pdf
- Alamat projek: https://Ogithub Kertas Tajuk: VideoMamba: State Space Model for Efficient Video Understanding
Rajah 2a di bawah menunjukkan butiran modul Mamba.

Rajah 3 menggambarkan rangka kerja keseluruhan VideoMamba. Kertas kerja ini mula-mula menggunakan lilitan 3D (iaitu 1×16×16) untuk menayangkan video input Xv ∈ R 3×T ×H×W ke L tompok spatio-temporal tidak bertindih Xp ∈ R L×C, dengan L=t×h ×w (t=T, h= H 16, dan w= W 16). Input jujukan token kepada pengekod VideoMamba seterusnya ialah 

Imbasan ruang: Untuk menggunakan lapisan B-Mamba pada input spatiotemporal, imbasan 2D asal dikembangkan ke dalam imbasan Rajah 4D dwiarah yang berbeza artikel ini :
(a) Ruang dahulu, susun token spatial mengikut kedudukan, dan kemudian susunkannya bingkai demi bingkai
(b) Masa dahulu, susun token masa mengikut bingkai, kemudian susun mengikut dimensi ruang;
( c) Hibrid ruang-masa, dengan keutamaan ruang dan keutamaan masa, dengan v1 melaksanakan separuh daripadanya dan v2 melaksanakan semua (2 kali ganda jumlah pengiraan).
Eksperimen dalam Rajah 7a menunjukkan bahawa pengimbasan dwiarah pertama angkasa adalah yang paling cekap tetapi paling mudah. Disebabkan oleh kerumitan linear Mamba, VideoMamba dalam artikel ini boleh memproses video panjang resolusi tinggi dengan cekap.

Untuk SSM dalam lapisan B-Mamba, artikel ini menggunakan tetapan hiperparameter lalai yang sama seperti Mamba, menetapkan dimensi keadaan dan nisbah pengembangan kepada 16 dan 2 masing-masing. Mengikut pendekatan ViT, kertas kerja ini melaraskan dimensi kedalaman dan benam untuk mencipta model saiz yang setanding dengan yang terdapat dalam Jadual 1, termasuk VideoMamba-Ti, VideoMamba-S dan VideoMamba-M. Walau bagaimanapun, telah diperhatikan dalam eksperimen bahawa VideoMamba yang lebih besar sering terdedah kepada overfitting dalam eksperimen, mengakibatkan prestasi suboptimum seperti yang ditunjukkan dalam Rajah 6a. Masalah overfitting ini wujud bukan sahaja dalam model yang dicadangkan dalam kertas ini, tetapi juga dalam VMamba, di mana prestasi terbaik VMamba-B dicapai pada tiga perempat daripada jumlah tempoh latihan. Untuk memerangi masalah overfitting model Mamba yang lebih besar, kertas kerja ini memperkenalkan strategi penyulingan kendiri yang berkesan yang menggunakan model yang lebih kecil dan terlatih sebagai "guru" untuk membimbing latihan model "pelajar" yang lebih besar. Keputusan yang ditunjukkan dalam Rajah 6a menunjukkan bahawa strategi ini membawa kepada penumpuan yang lebih baik yang dijangkakan.


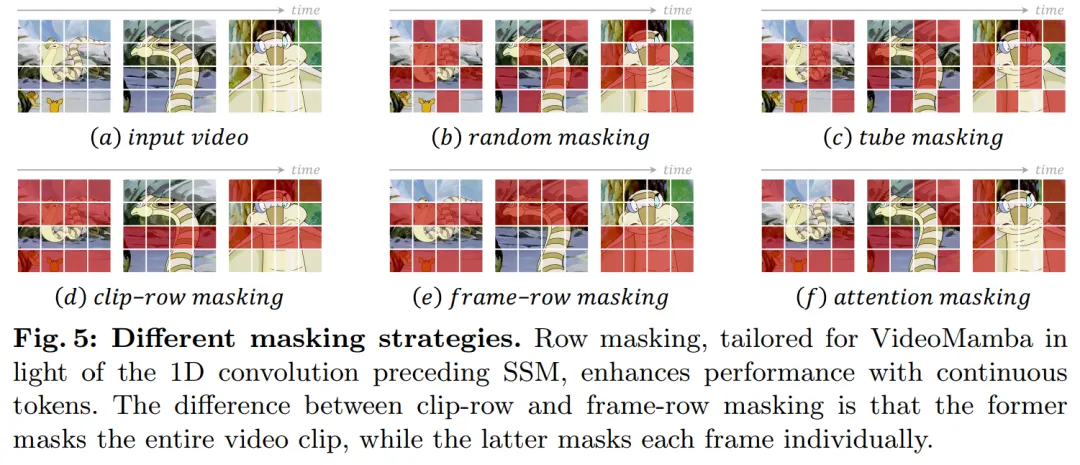
Mengenai strategi penyamaran, kertas kerja ini mencadangkan teknik penyamaran baris yang berbeza, seperti yang ditunjukkan dalam Rajah 5, secara khusus menyasarkan keutamaan blok B-Mamba untuk token berturut-turut.
Eksperimen
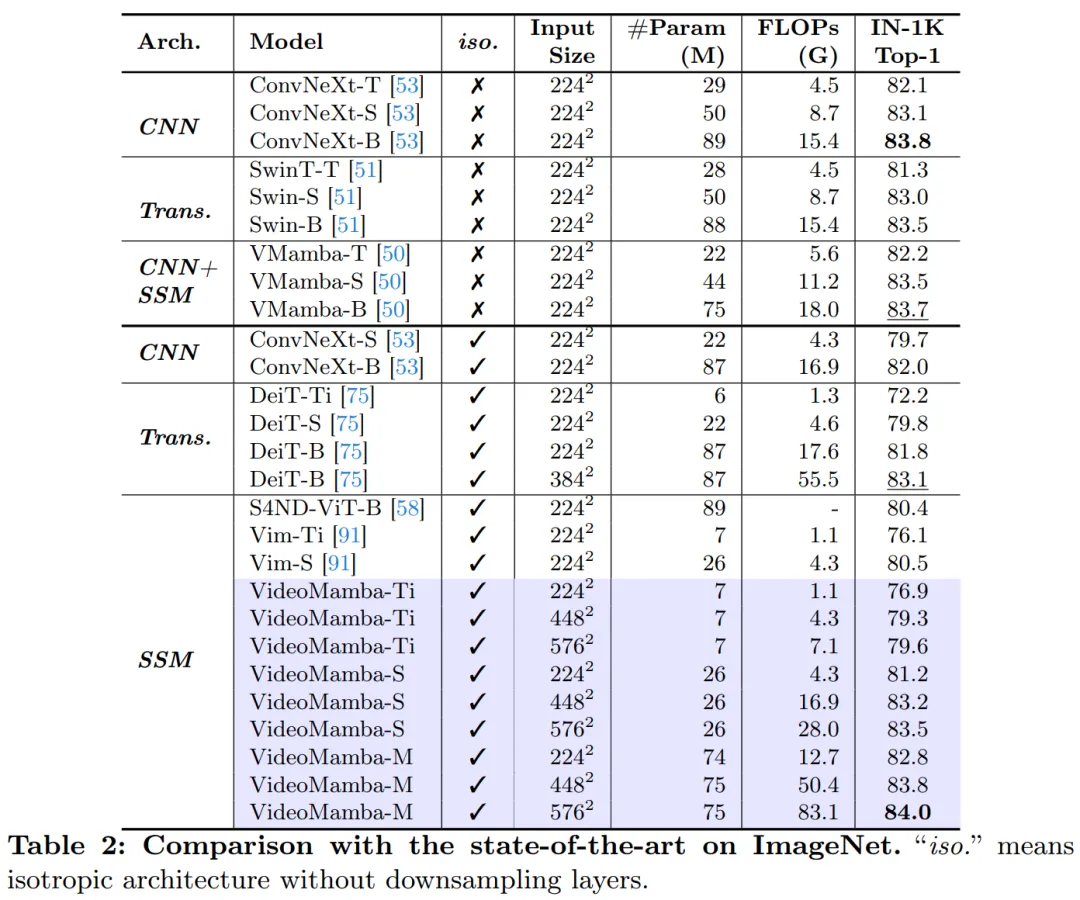
Jadual 2 menunjukkan keputusan pada set data ImageNet-1K. Terutama sekali, VideoMamba-M mengatasi prestasi seni bina isotropik lain dengan ketara, meningkat sebanyak +0.8% berbanding ConvNeXt-B dan +2.0% berbanding DeiT-B, sambil menggunakan lebih sedikit parameter . VideoMamba-M juga berprestasi baik dalam struktur tulang belakang bukan isotropik yang menggunakan ciri berlapis untuk prestasi yang dipertingkatkan. Memandangkan kecekapan Mamba dalam memproses jujukan panjang, kertas kerja ini meningkatkan lagi prestasi dengan meningkatkan resolusi, mencapai 84.0% ketepatan top-1 hanya menggunakan parameter 74M.
Jadual 3 dan Jadual 4 menyenaraikan keputusan pada set data video jangka pendek. (a) Pembelajaran diselia: Berbanding dengan kaedah perhatian tulen, VideoMamba-M berdasarkan SSM memperoleh kelebihan yang jelas, mengatasi prestasi ViViT-L pada set data K400 yang berkaitan dengan tempat kejadian dan masing-masing +2.0% dan +3.0%. . Peningkatan ini datang dengan keperluan pengiraan yang dikurangkan dengan ketara dan kurang data pra-latihan. Keputusan VideoMamba-M adalah setanding dengan SOTA UniFormer, yang dengan bijak menyepadukan lilitan dan perhatian dalam seni bina bukan isotropik. (b) Pembelajaran diselia sendiri: Dengan pralatihan topeng, VideoMamba mengatasi VideoMAE, yang terkenal dengan kemahiran motor halusnya. Pencapaian ini menyerlahkan potensi model berasaskan SSM tulen kami untuk memahami video jangka pendek dengan cekap dan berkesan, menekankan kesesuaiannya untuk kedua-dua paradigma pembelajaran yang diselia dan diselia sendiri.


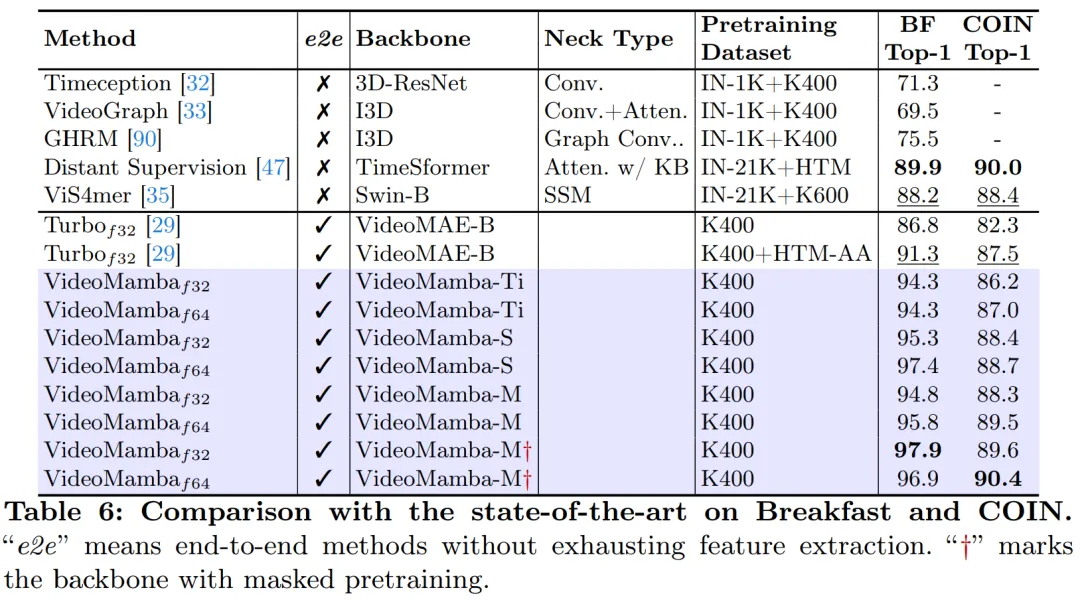
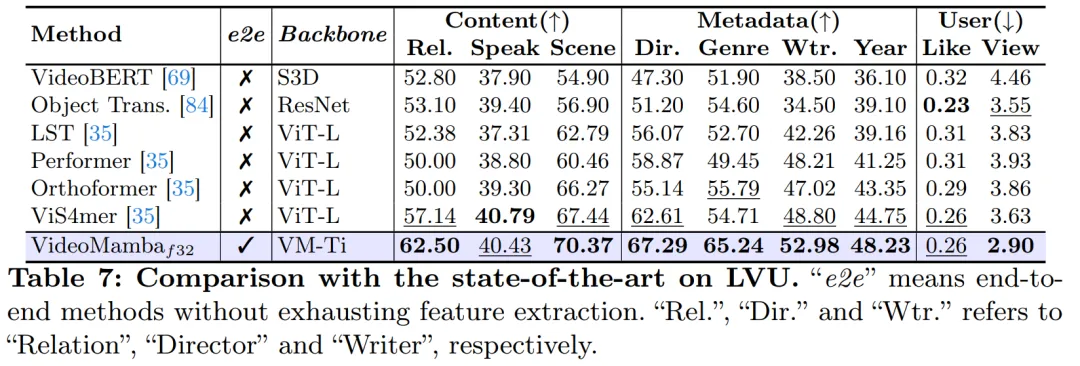
Seperti yang ditunjukkan dalam Rajah 1, kerumitan linear VideoMamba menjadikannya sangat sesuai untuk latihan hujung ke hujung dengan video panjang. Perbandingan dalam Jadual 6 dan 7 menyerlahkan kesederhanaan dan keberkesanan VideoMamba berbanding kaedah berasaskan ciri tradisional dalam tugasan ini. Ia membawa peningkatan prestasi yang ketara, membolehkan keputusan SOTA walaupun pada saiz model yang lebih kecil. VideoMamba-Ti menunjukkan peningkatan ketara +6.1% berbanding ViS4mer menggunakan ciri Swin-B, dan juga peningkatan +3.0% berbanding kaedah penjajaran multimodal Turbo. Terutamanya, hasilnya menyerlahkan kesan positif model penskalaan dan kadar bingkai untuk tugas jangka panjang. Mengenai sembilan tugasan yang pelbagai dan mencabar yang dicadangkan oleh LVU, kertas kerja ini menggunakan pendekatan hujung ke hujung untuk memperhalusi VideoMamba-Ti dan mencapai keputusan yang setanding atau lebih baik daripada kaedah SOTA semasa. Keputusan ini bukan sahaja menyerlahkan keberkesanan VideoMamba, tetapi juga menunjukkan potensi besarnya untuk pemahaman video panjang masa hadapan.
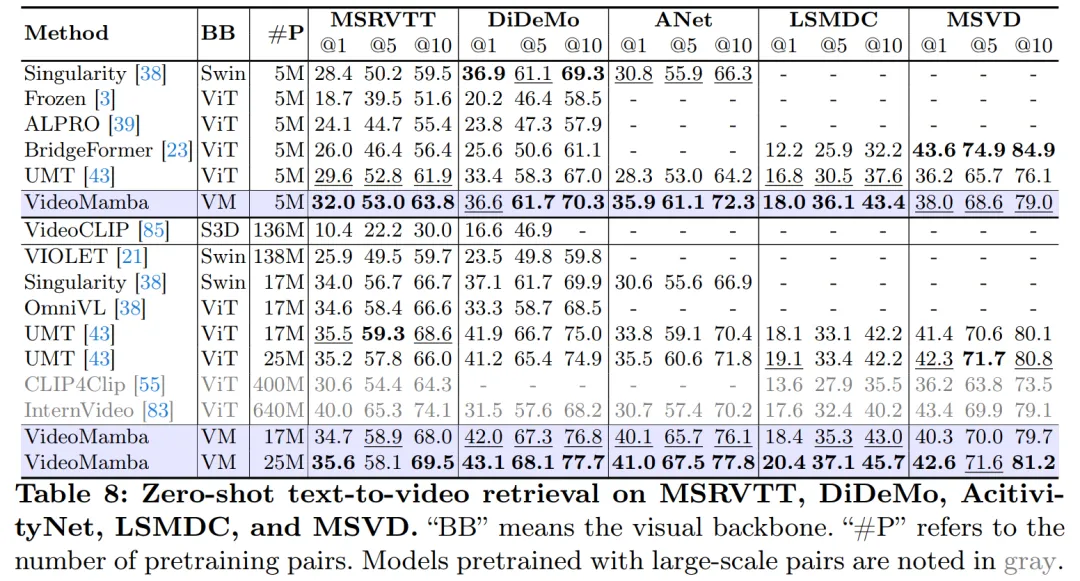
Seperti yang ditunjukkan dalam Jadual 8, di bawah korpus pra-latihan yang sama dan strategi latihan yang serupa, VideoMamba mengatasi UMT berasaskan ViT dalam prestasi pengambilan video sifar tangkapan. Ini menyerlahkan kecekapan dan skalabiliti setanding Mamba berbanding ViT dalam memproses tugasan video berbilang modal. Terutama, VideoMamba menunjukkan peningkatan ketara pada set data dengan panjang video yang lebih panjang (cth., ANet dan DiDeMo) dan adegan yang lebih kompleks (cth., LSMDC). Ini menunjukkan keupayaan Mamba dalam persekitaran multimodal yang mencabar, walaupun di mana penjajaran rentas mod diperlukan.
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Selain CNN, Transformer dan Uniformer, kami akhirnya mempunyai teknologi pemahaman video yang lebih cekap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!