
Rumah >Peranti teknologi >AI >Anggaran kedalaman SOTA! Gabungan penyesuaian kedalaman monokular dan sekeliling untuk pemanduan autonomi
Anggaran kedalaman SOTA! Gabungan penyesuaian kedalaman monokular dan sekeliling untuk pemanduan autonomi

- PHPzke hadapan
- 2024-03-23 13:06:021408semak imbas
Ditulis sebelum & pemahaman peribadi
Anggaran kedalaman berbilang paparan telah mencapai prestasi tinggi dalam pelbagai ujian penanda aras. Walau bagaimanapun, hampir semua sistem berbilang paparan semasa bergantung pada pose kamera ideal yang diberikan, yang tidak tersedia dalam banyak senario dunia sebenar, seperti pemanduan autonomi. Kerja ini mencadangkan penanda aras kekukuhan baharu untuk menilai sistem anggaran kedalaman di bawah pelbagai tetapan pose bising. Yang menghairankan, didapati kaedah anggaran kedalaman berbilang paparan semasa atau kaedah gabungan pandangan tunggal dan berbilang pandangan gagal apabila diberikan tetapan pose bising. Untuk menangani cabaran ini, di sini kami mencadangkan AFNet, sistem anggaran kedalaman bercantum satu pandangan dan berbilang paparan yang menyepadukan secara adaptif hasil berbilang pandangan dan pandangan tunggal berkeyakinan tinggi untuk mencapai anggaran kedalaman yang mantap dan tepat. Modul gabungan adaptif melakukan gabungan dengan memilih kawasan berkeyakinan tinggi secara dinamik antara kedua-dua cawangan berdasarkan peta keyakinan bungkusan. Oleh itu, apabila berhadapan dengan pemandangan tanpa tekstur, penentukuran yang tidak tepat, objek dinamik dan keadaan lain yang terdegradasi atau mencabar, sistem cenderung untuk memilih cawangan yang lebih dipercayai. Di bawah ujian kekukuhan, kaedah ini mengatasi kaedah berbilang pandangan dan gabungan terkini. Selain itu, prestasi tercanggih dicapai pada penanda aras yang mencabar (KITTI dan DDAD).
Pautan kertas: https://arxiv.org/pdf/2403.07535.pdf
Nama kertas: Gabungan Suaian Kedalaman Pandangan Tunggal dan Pelbagai Pandangan untuk Pemanduan Autonomi
Latar belakang medan
sentiasa ada estimasi imej telah Satu cabaran dalam bidang penglihatan komputer dengan pelbagai aplikasi. Untuk sistem pemanduan autonomi berasaskan penglihatan, persepsi kedalaman adalah kunci, membantu memahami objek di jalan raya dan membina peta 3D persekitaran. Dengan aplikasi rangkaian neural dalam dalam pelbagai masalah visual, kaedah berdasarkan rangkaian neural konvolusi (CNN) telah menjadi arus utama tugas anggaran kedalaman. Mengikut format input, ia terbahagi terutamanya kepada anggaran kedalaman berbilang pandangan dan anggaran kedalaman pandangan tunggal. Andaian di sebalik kaedah berbilang paparan untuk menganggarkan kedalaman ialah, memandangkan kedalaman yang betul, penentukuran kamera dan pose kamera, piksel merentas paparan sepatutnya serupa. Mereka bergantung pada geometri epipolar untuk menyegitiga ukuran kedalaman berkualiti tinggi. Walau bagaimanapun, ketepatan dan keteguhan kaedah berbilang paparan sangat bergantung pada konfigurasi geometri kamera dan padanan yang sepadan antara pandangan. Pertama, kamera perlu menterjemah cukup untuk membenarkan triangulasi. Dalam senario pandu sendiri, kenderaan sendiri mungkin berhenti di lampu isyarat atau membelok tanpa bergerak ke hadapan, yang boleh menyebabkan triangulasi gagal. Selain itu, kaedah berbilang paparan mengalami masalah sasaran dinamik dan kawasan tanpa tekstur, yang lazim dalam senario pemanduan autonomi. Masalah lain ialah pengoptimuman sikap SLAM pada kenderaan bergerak. Dalam kaedah SLAM sedia ada, bunyi bising tidak dapat dielakkan, apatah lagi situasi yang mencabar dan tidak dapat dielakkan. Sebagai contoh, robot atau kereta pandu sendiri boleh digunakan selama bertahun-tahun tanpa penentukuran semula, menghasilkan pose yang bising. Sebaliknya, memandangkan kaedah pandangan tunggal bergantung pada pemahaman semantik adegan dan isyarat unjuran perspektif, kaedah tersebut lebih teguh kepada kawasan tanpa tekstur, objek dinamik dan tidak bergantung pada pose kamera. Walau bagaimanapun, disebabkan oleh kekaburan skala, prestasinya masih jauh di belakang kaedah berbilang paparan. Di sini, kami cenderung untuk mempertimbangkan sama ada kelebihan kedua-dua kaedah ini boleh digabungkan dengan baik untuk anggaran kedalaman video monokular yang mantap dan tepat dalam senario pemanduan autonomi.Struktur rangkaian AFNet
Struktur AFNet ditunjukkan di bawah Ia terdiri daripada tiga bahagian: cawangan satu pandangan, cawangan berbilang pandangan dan modul gabungan adaptif (AF). Kedua-dua cawangan berkongsi rangkaian pengekstrakan ciri dan mempunyai ramalan dan peta keyakinan mereka sendiri, iaitu, , , dan , dan kemudian digabungkan oleh modul AF untuk mendapatkan ramalan akhir yang tepat dan mantap Latar belakang hijau dalam modul AF mewakili tunggal -lihat cawangan dan Keluaran cawangan berbilang paparan.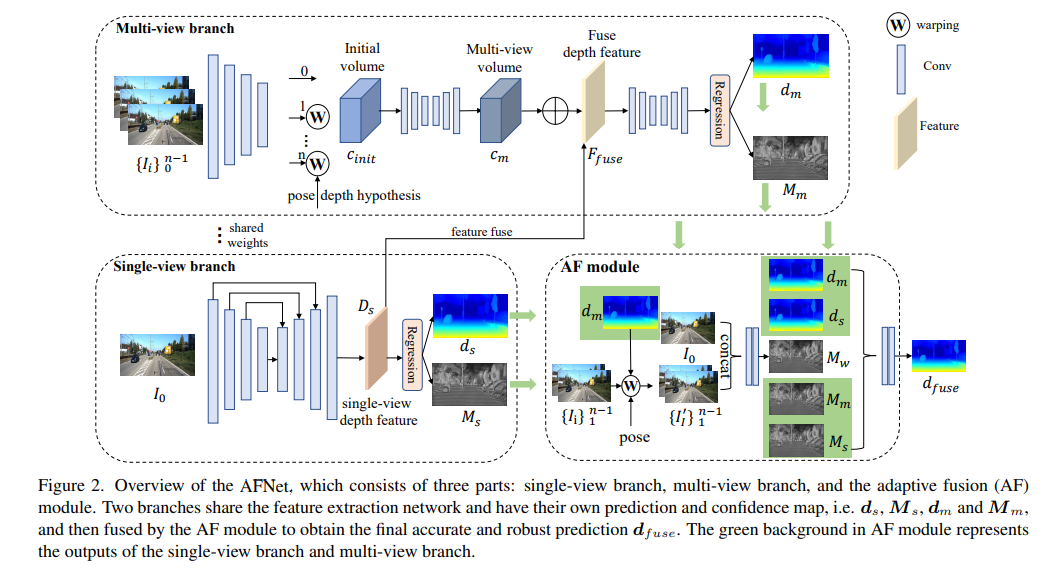

Modul kedalaman paparan tunggal dan berbilang pandangan
Untuk menggabungkan ciri-ciri tulang belakang dan mendapatkan ciri binaan dalam Ds.-AFNet Dalam proses ini, operasi softmax dilakukan pada 256 saluran pertama Ds untuk mendapatkan isipadu kebarangkalian kedalaman Ps. Saluran terakhir dalam ciri kedalaman digunakan sebagai peta keyakinan kedalaman pandangan tunggal Ms. Akhir sekali, kedalaman satu pandangan dikira melalui pemberat lembut.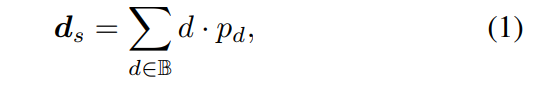
Cawangan berbilang paparan
Cawangan berbilang paparan berkongsi tulang belakang dengan cawangan pandangan tunggal untuk mengekstrak ciri rujukan dan imej sumber. Kami mengguna pakai penyahkonvolusi untuk mengasingkan ciri resolusi rendah kepada resolusi suku dan menggabungkannya dengan ciri suku awal yang digunakan untuk membina volum kos. Isipadu ciri dibentuk dengan membungkus ciri sumber ke dalam satah hipotesis diikuti oleh kamera rujukan. Untuk padanan mantap yang tidak memerlukan terlalu banyak maklumat, dimensi saluran ciri dikekalkan dalam pengiraan dan volum kos 4D dibina, dan kemudian bilangan saluran dikurangkan kepada 1 melalui dua lapisan konvolusi 3D.
Kaedah pensampelan hipotesis kedalaman adalah konsisten dengan cawangan pandangan tunggal, tetapi bilangan sampel hanya 128, dan kemudian diselaraskan menggunakan rangkaian jam pasir 2D bertindan untuk mendapatkan volum kos berbilang paparan akhir. Untuk menambah maklumat semantik yang kaya bagi ciri paparan tunggal dan butiran yang hilang akibat penyelarasan kos, struktur sisa digunakan untuk menggabungkan ciri kedalaman satu paparan Ds dan volum kos untuk mendapatkan ciri kedalaman bersatu seperti berikut:
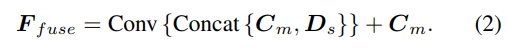
Modul Gabungan Adaptif
Untuk mendapatkan ramalan akhir yang tepat dan mantap, modul AF direka bentuk untuk menyesuaikan secara adaptif kedalaman paling tepat antara kedua-dua cawangan sebagai output akhir, seperti yang ditunjukkan dalam Rajah 2. Pemetaan gabungan dilakukan melalui tiga keyakinan, dua daripadanya ialah peta keyakinan Ms dan Mm masing-masing yang dijana oleh kedua-dua cabang Yang paling kritikal ialah peta keyakinan Mw yang dijana oleh pembalut hadapan untuk menentukan sama ada ramalan cawangan berbilang pandangan itu. boleh dipercayai.
Hasil Eksperimen
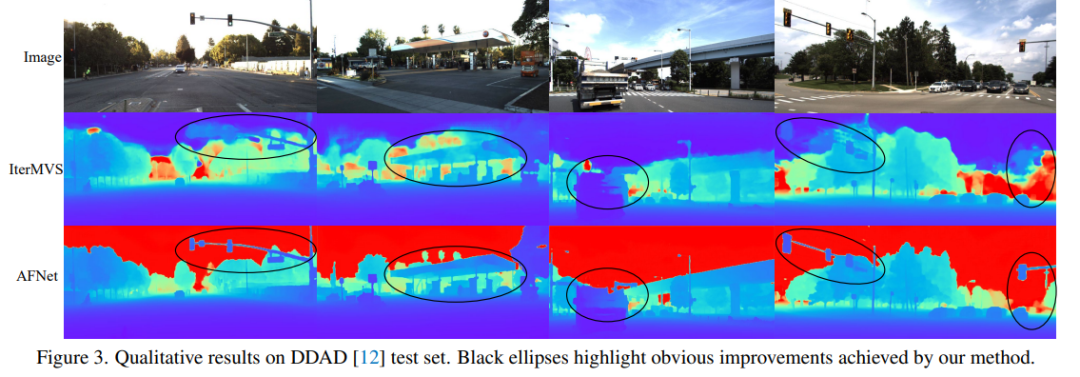
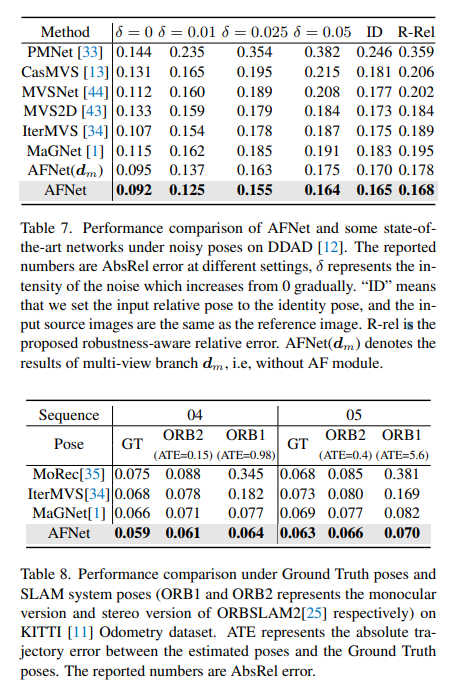
DDAD (Dense Depth for Autonomous Driving) ialah penanda aras pemanduan autonomi baharu untuk anggaran kedalaman padat dalam keadaan bandar yang mencabar dan pelbagai. Ia ditangkap oleh 6 kamera yang disegerakkan dan mengandungi kedalaman tanah yang tepat (keseluruhan medan pandangan 360 darjah) yang dijana oleh lidar berketumpatan tinggi. Ia mempunyai 12650 sampel latihan dan 3950 sampel pengesahan dalam paparan kamera tunggal dengan resolusi 1936×1216. Semua data daripada 6 kamera digunakan untuk latihan dan ujian. Set data KITTI menyediakan imej stereoskopik pemandangan luar yang dirakam pada kenderaan bergerak dan imbasan laser 3D yang sepadan, dengan resolusi lebih kurang 1241×376.
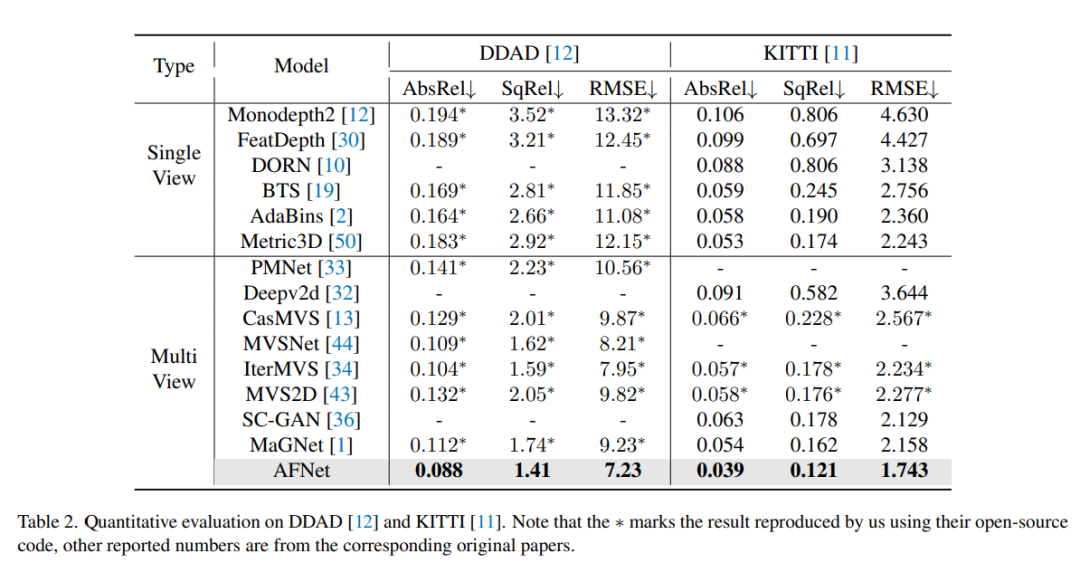
Perbandingan keputusan penilaian pada DDAD dan KITTI. Ambil perhatian bahawa * menandakan keputusan direplikasi menggunakan kod sumber terbuka mereka, nombor lain yang dilaporkan adalah daripada kertas asal yang sepadan.
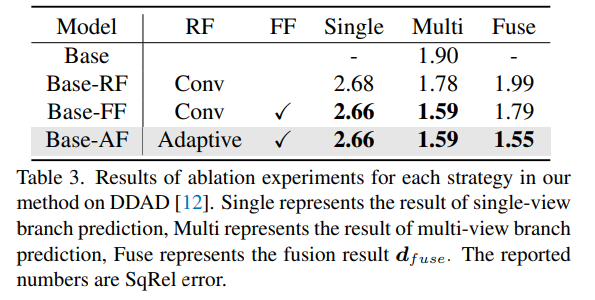
Keputusan percubaan ablasi untuk setiap strategi dalam kaedah pada DDAD. Tunggal mewakili hasil ramalan cawangan pandangan tunggal, Berbilang mewakili hasil ramalan cawangan berbilang paparan, dan Fius mewakili hasil gabungan dfuse.
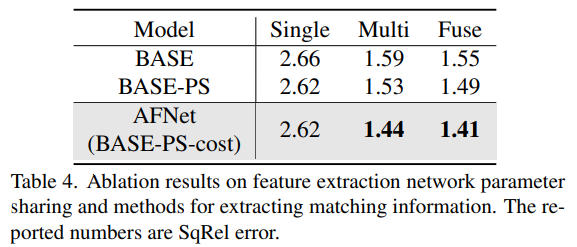
Satu kaedah untuk berkongsi parameter rangkaian dan mengekstrak maklumat padanan untuk pengekstrakan ciri hasil ablasi.

Atas ialah kandungan terperinci Anggaran kedalaman SOTA! Gabungan penyesuaian kedalaman monokular dan sekeliling untuk pemanduan autonomi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!