
Rumah >Peranti teknologi >AI >WorldGPT ada di sini: Buat ejen AI video seperti Sora, grafik dan teks 'hidupkan semula'.
WorldGPT ada di sini: Buat ejen AI video seperti Sora, grafik dan teks 'hidupkan semula'.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-03-22 08:30:441442semak imbas
Sora OpenAI membuat penampilan sulung yang menakjubkan pada Februari tahun ini, membawa satu kejayaan baharu kepada video yang dijana teks. Ia boleh mencipta video yang realistik dan imaginasi yang menakjubkan berdasarkan input teks yang kelihatan seperti ia datang dari Hollywood. Ramai orang kagum dengan inovasi ini dan percaya bahawa prestasi OpenAI telah mencapai kemuncak.
Kegilaan yang disebabkan oleh Sora terus berlanjutan Pada masa yang sama, penyelidik telah mula menyedari potensi besar teknologi penjanaan video AI, dan bidang ini semakin menarik perhatian.
Walau bagaimanapun, dalam bidang semasa penjanaan video AI, kebanyakan penyelidikan algoritma memfokuskan pada penjanaan video melalui input teks berbilang modal, terutamanya senario di mana gambar dan teks digabungkan, belum dibincangkan secara mendalam atau digunakan secara meluas. Bias ini mengurangkan kepelbagaian dan kebolehkawalan video yang dihasilkan dan mengehadkan keupayaan untuk menukar imej statik kepada video dinamik.
Sebaliknya, kebanyakan model penjanaan video sedia ada kekurangan sokongan keboleheditan untuk kandungan video yang dijana dan tidak dapat memenuhi keperluan pengguna untuk pelarasan diperibadikan pada video yang dijana.


Petua: Tukar panda menjadi beruang dan buat ia menari. (Tukar panda kepada beruang dan jadikan ia menari.)
Dalam artikel ini, penyelidik dari SEEKING AI, Universiti Harvard, Universiti Stanford dan Universiti Peking bersama-sama mencadangkan rangka kerja bersepadu yang inovatif untuk penjanaan dan penyuntingan video berasaskan teks imej. bernama WorldGPT. Rangka kerja ini dibina di atas rangka kerja VisionGPT yang dibangunkan bersama oleh SEEKING AI dan universiti terkemuka yang disebutkan di atas Ia bukan sahaja dapat merealisasikan fungsi menjana video secara langsung daripada gambar dan teks, tetapi juga menyokong pemindahan gaya dan penggantian latar belakang video yang dihasilkan melalui. gesaan teks ringkas (prompt) dan satu siri operasi penyuntingan penampilan video.
Satu lagi kelebihan penting rangka kerja ini ialah ia tidak memerlukan latihan, yang sangat merendahkan ambang teknikal dan juga menjadikan penggunaan dan penggunaan sangat mudah. Pengguna boleh terus menggunakan model untuk mencipta tanpa memberi perhatian kepada proses latihan yang membosankan di belakangnya.

- Alamat kertas: https://arxiv.org/pdf/2403.07944.pdf
- Tajuk kertas: WorldGPT: Ejen AI Video Inspirasi Sora sebagai Model Dunia Kaya daripada Input Teks dan Imej
Penggantian Latar Belakang + Penggayaan + Jana Video
Prompt: "Seekor naga comel di jalan bandar Bernafas api. (Naga comel sedang meludah api jalanan.) "
Penggantian objek + Penggantian latar belakang + Jana video
Prompt: "Robot gaya cyberpunk yang diterangi oleh lampu neon Sebuah automaton gaya cyberpunk bercahaya berlumba melalui neon dispian hologram yang menjulang tinggi dan pereputan digital ditayangkan pada badan logamnya yang licin bermain di seluruh badan logamnya yang ramping.)》
Seperti yang dapat dilihat dari contoh di atas, WorldGPT mempunyai kelebihan berikut apabila berhadapan dengan video yang kompleks. arahan penjanaan:
 1) Ia lebih baik mengekalkan Input asal, struktur dan persekitaran imej; video yang dihasilkan boleh disesuaikan dan diedit melalui gesaan.
1) Ia lebih baik mengekalkan Input asal, struktur dan persekitaran imej; video yang dihasilkan boleh disesuaikan dan diedit melalui gesaan.
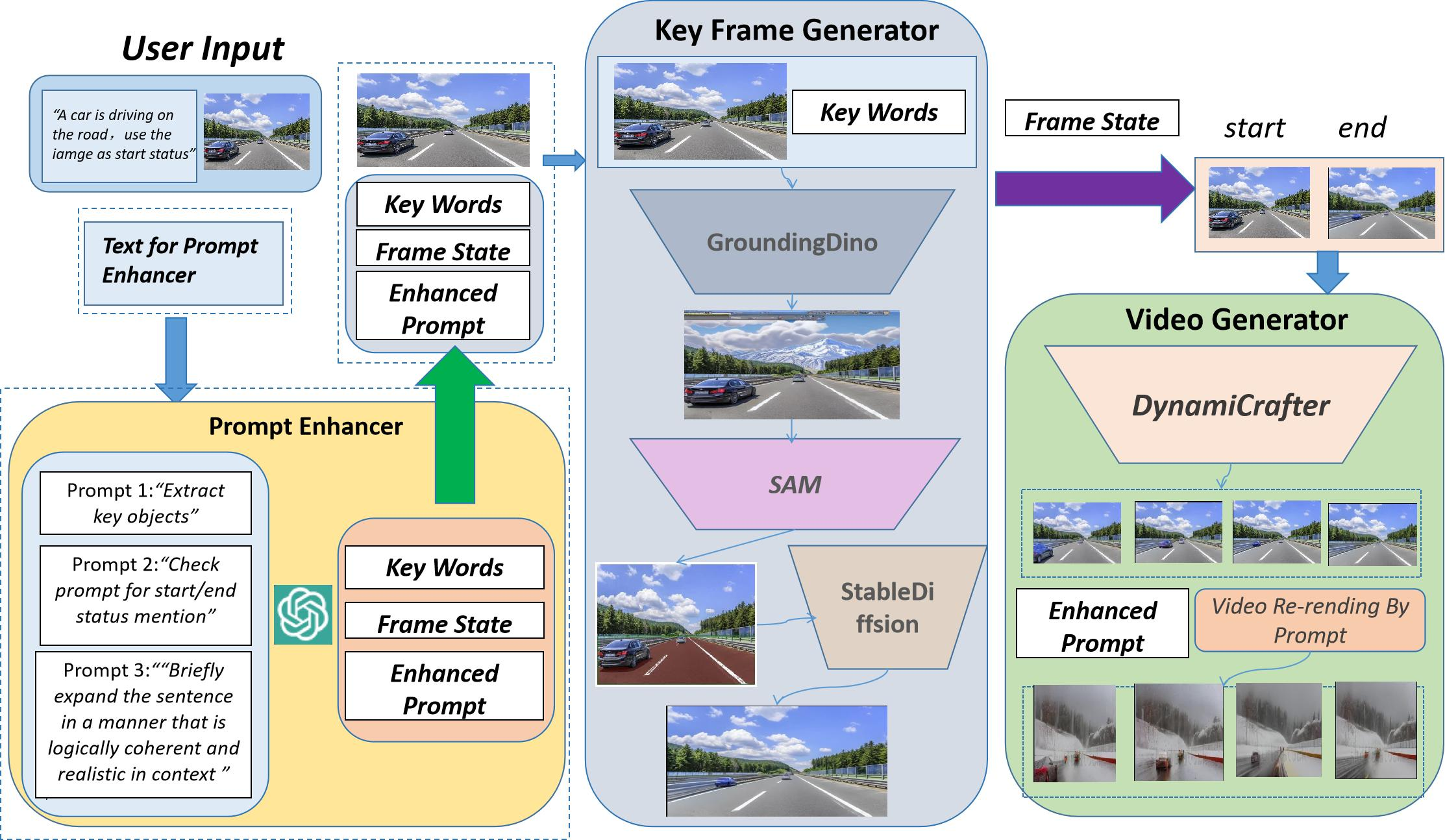
Untuk mengetahui lebih lanjut tentang prinsip, eksperimen dan kes penggunaan WorldGPT, sila lihat kertas asal.
VisonGPT
Seperti yang dinyatakan sebelum ini, rangka kerja WorldGPT dibina di atas rangka kerja VisionGPT. Seterusnya kami memperkenalkan secara ringkas maklumat tentang VisionGPT.
VisionGPT dibangunkan bersama oleh SeekingAI, Universiti Stanford, Universiti Harvard, Universiti Peking dan institusi terkemuka dunia yang lain Ia merupakan rangka kerja model besar persepsi visual dunia terbuka. Rangka kerja ini menyediakan keupayaan pemprosesan imej berbilang mod AI yang berkuasa melalui penyepaduan pintar dan pemilihan model besar SOTA yang canggih dan membuat keputusan.
Inovasi VisionGPT dicerminkan terutamanya dalam tiga aspek:
- Pertama, ia memerlukan model bahasa yang besar (seperti LLaMA-2) sebagai teras, menguraikan permintaan segera pengguna kepada keperluan langkah terperinci, dan secara automatik memanggil paling banyak model Besar yang sesuai diproses;
- Kedua, VisionGPT secara automatik menerima dan menggabungkan output berbilang modal yang dijana daripada berbilang model besar SOTA untuk menjana hasil pemprosesan imej yang disesuaikan dengan keperluan pengguna
- Akhirnya, VisionGPT mempunyai fleksibiliti dan Serbaguna yang sangat tinggi, tanpa memerlukan; untuk pengguna memperhalusi model, boleh menyokong pelbagai senario aplikasi termasuk pemahaman imej dipacu teks, penjanaan dan penyuntingan.

- Alamat kertas: https://arxiv.org/pdf/2403.09027.pdf
- Tajuk kertas: VisionGPT: Vision-Language Understanding Agent using Generalized Multimodal Framework
Seperti yang dapat dilihat daripada di atas, VisionGPT boleh mencapai 1) pembahagian contoh dalam dunia terbuka tanpa penalaan halus; 2) penjanaan imej berasaskan segera dan fungsi penyuntingan, dsb. Aliran kerja VisionGPT ditunjukkan dalam rajah di bawah.

Untuk butiran lanjut, sila rujuk kertas.
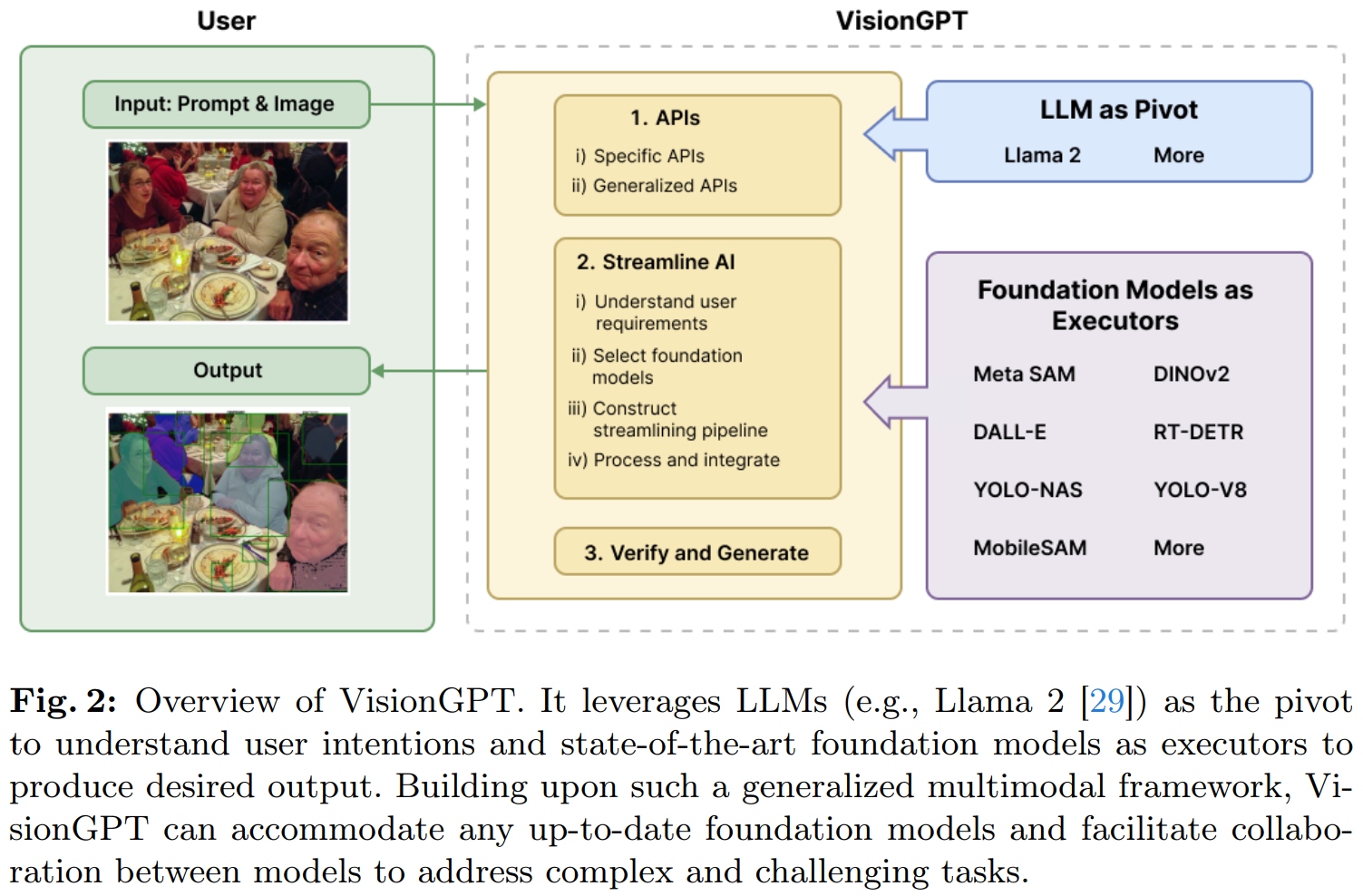 VisionGPT-3D
VisionGPT-3D
Alamat kertas: https://arxiv.org/pdf/2403.09530v1.pdf
 Tajuk kertas: VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
Tajuk kertas: VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
- kepada kertas asal.
Atas ialah kandungan terperinci WorldGPT ada di sini: Buat ejen AI video seperti Sora, grafik dan teks 'hidupkan semula'.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- h5自学教程:6个适合初学者的零基础html5入门自学教程推荐
- linux系统使用入门教程
- phpstudy v8 使用快速入门教程
- Bermula: Lihat cara menambah kesan kecerunan pada gambar dalam PS (perkongsian pengetahuan)
- Kestabilan AI telah bertambah baik dengan pesat sekali lagi: demonstrasi penjanaan video baharu yang menakjubkan, diiktiraf sebulat suara oleh netizen