
Rumah >Peranti teknologi >AI >Bagaimana untuk menulis kod LoRA dari awal, berikut adalah tutorial
Bagaimana untuk menulis kod LoRA dari awal, berikut adalah tutorial

- 王林ke hadapan
- 2024-03-20 15:06:45709semak imbas
LoRA (Penyesuaian Kedudukan Rendah) ialah teknik popular yang direka untuk memperhalusi model bahasa besar (LLM). Teknologi ini pada asalnya dicadangkan oleh penyelidik Microsoft dan dimasukkan ke dalam kertas kerja "LORA: ADAPTASI RENDAH MODEL BAHASA BESAR". LoRA berbeza daripada teknik lain kerana bukannya melaraskan semua parameter rangkaian saraf, ia memfokuskan pada mengemas kini sebilangan kecil matriks peringkat rendah, dengan ketara mengurangkan jumlah pengiraan yang diperlukan untuk melatih model.
Memandangkan kualiti penalaan halus LoRA adalah setanding dengan penalaan halus model penuh, ramai orang memanggil kaedah ini sebagai artifak penalaan halus. Sejak dikeluarkan, ramai yang ingin tahu tentang teknologi dan ingin menulis kod untuk lebih memahami penyelidikan. Pada masa lalu, kekurangan dokumentasi yang betul telah menjadi isu, tetapi kini, kami mempunyai tutorial untuk membantu.
Pengarang tutorial ini ialah Sebastian Raschka, seorang penyelidik pembelajaran mesin dan AI yang terkenal Dia berkata bahawa antara pelbagai kaedah penalaan halus LLM yang berkesan, LoRA masih menjadi pilihan pertamanya. Untuk tujuan ini, Sebastian menulis blog "Code LoRA From Scratch" untuk membina LoRA dari awal Pada pendapatnya, ini adalah kaedah pembelajaran yang baik.
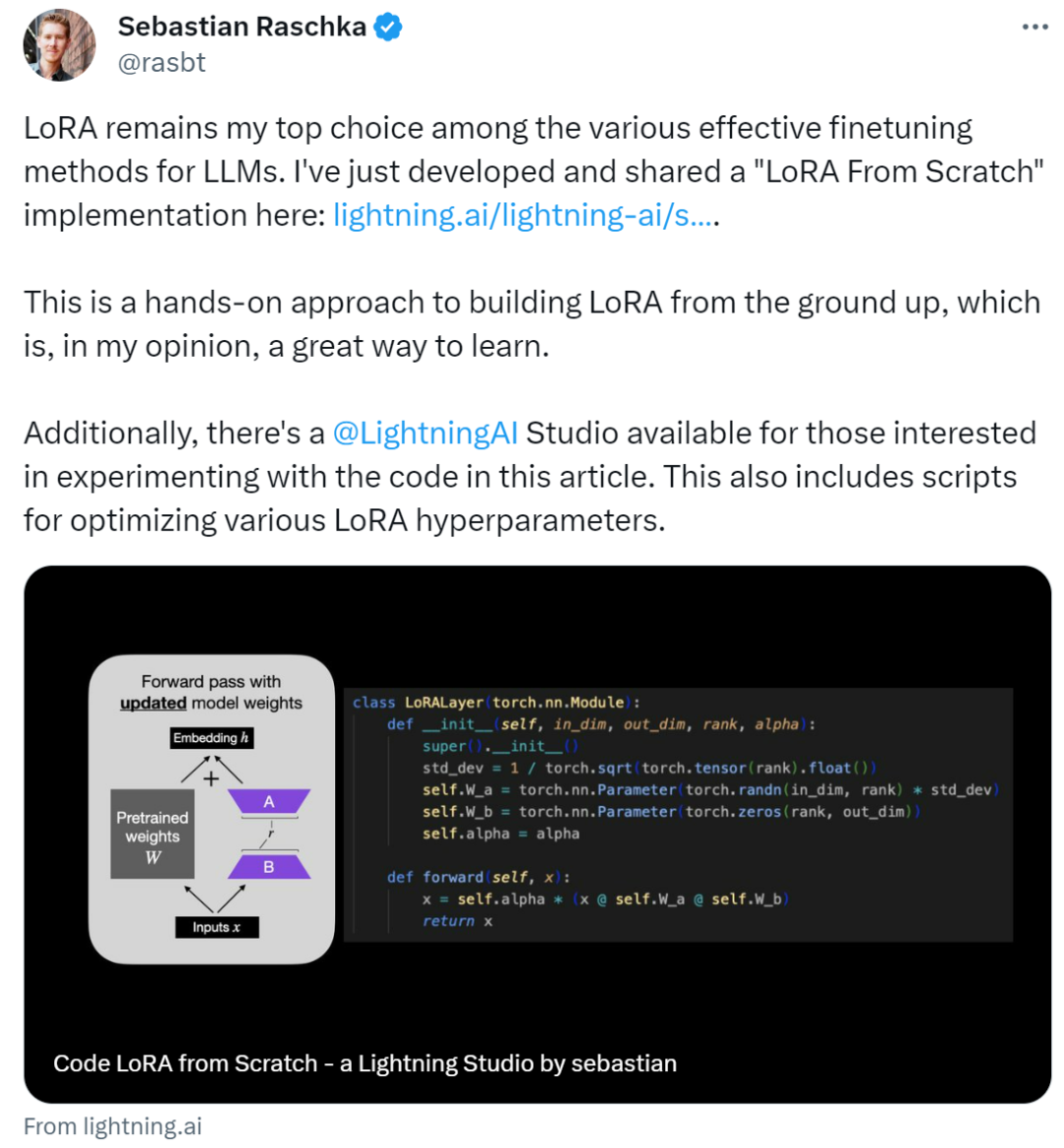
Artikel ini memperkenalkan penyesuaian peringkat rendah (LoRA) dengan menulis kod dari awal Sebastian memperhalusi model DistilBERT dalam percubaan dan menggunakannya pada tugas pengelasan.
Hasil perbandingan antara kaedah LoRA dan kaedah penalaan halus tradisional menunjukkan bahawa kaedah LoRA mencapai 92.39% dalam ketepatan ujian, yang lebih baik daripada penalaan halus hanya beberapa lapisan terakhir model (86.22% ketepatan ujian ) prestasi. Ini menunjukkan bahawa kaedah LoRA mempunyai kelebihan yang jelas dalam mengoptimumkan prestasi model dan boleh meningkatkan keupayaan generalisasi model dan ketepatan ramalan dengan lebih baik. Keputusan ini menyerlahkan kepentingan mengguna pakai teknik dan kaedah lanjutan semasa latihan dan penalaan model untuk mendapatkan prestasi dan hasil yang lebih baik. Dengan membandingkan bagaimana
Sebastian mencapainya, mari lihat di bawah.
Tulis LoRA dari awal
Menerangkan lapisan LoRA dalam kod adalah seperti ini:
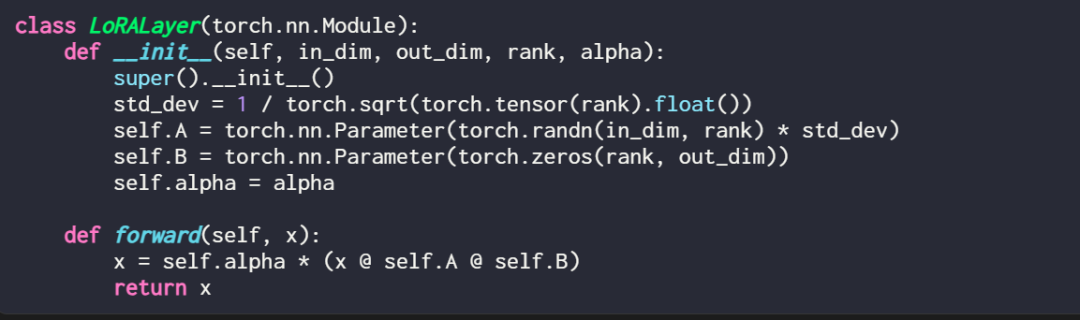
di mana in_dim ialah dimensi input ubah suai menggunakan lapisan yang anda ingin ubah LoRA ini. dimensi keluaran lapisan. Hiperparameter, alfa faktor penskalaan, juga ditambahkan pada kod nilai alfa yang lebih tinggi bermakna pelarasan yang lebih besar kepada tingkah laku model, dan nilai yang lebih rendah bermakna sebaliknya. Selain itu, artikel ini memulakan matriks A dengan nilai yang lebih kecil daripada taburan rawak dan memulakan matriks B dengan sifar.
Perlu dinyatakan bahawa tempat LoRA berperanan biasanya adalah lapisan linear (suapan) rangkaian saraf. Contohnya, untuk model atau modul PyTorch mudah dengan dua lapisan linear (contohnya, ini mungkin modul suapan hadapan blok Transformer), kaedah hadapan boleh dinyatakan sebagai:

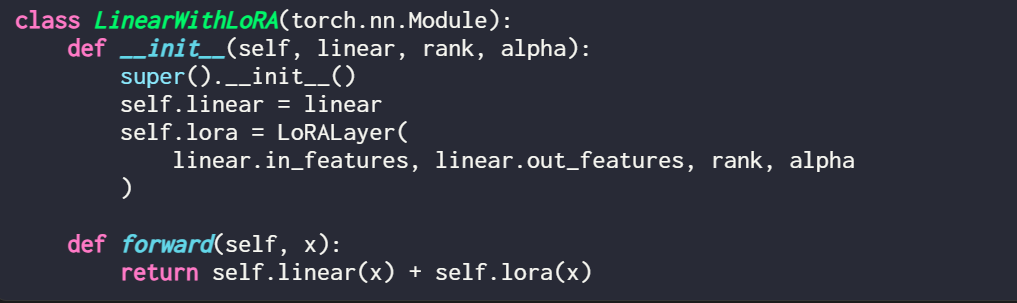
Apabila menggunakan LoRA, ia adalah perkara biasa untuk menambah kemas kini LoRA pada output lapisan linear ini, dan kod yang terhasil adalah seperti berikut:

Jika anda ingin melaksanakan LoRA dengan mengubah suai model PyTorch sedia ada, cara mudah ialah dengan Setiap lapisan linear digantikan dengan lapisan LinearWithLoRA:
Konsep di atas diringkaskan dalam rajah di bawah:
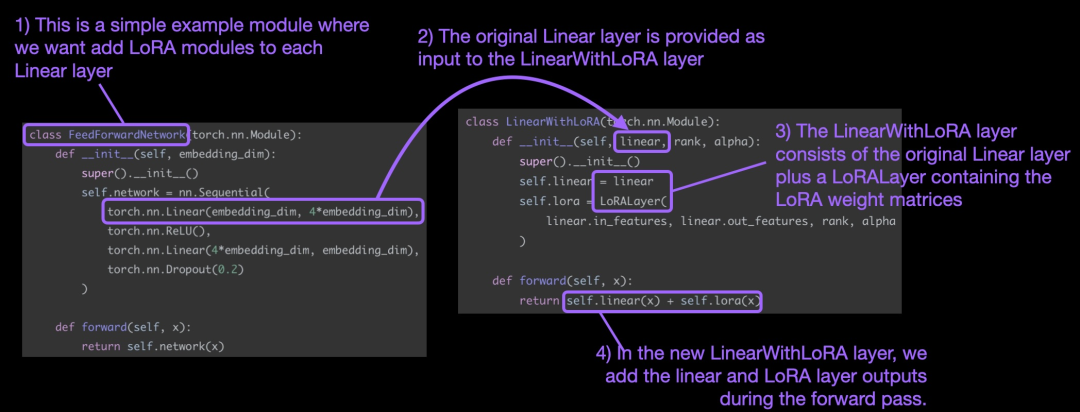
Untuk menggunakan LoRA, artikel ini menggantikan dalam rangkaian linear yang sedia ada. digabungkan Lapisan linear asal dan lapisan LinearWithLoRA LoRALayer.
Cara mula menggunakan LoRA untuk penalaan halus
LoRA boleh digunakan untuk model seperti GPT atau penjanaan imej. Untuk penjelasan ringkas, artikel ini menggunakan model BERT (DistilBERT) kecil untuk pengelasan teks.

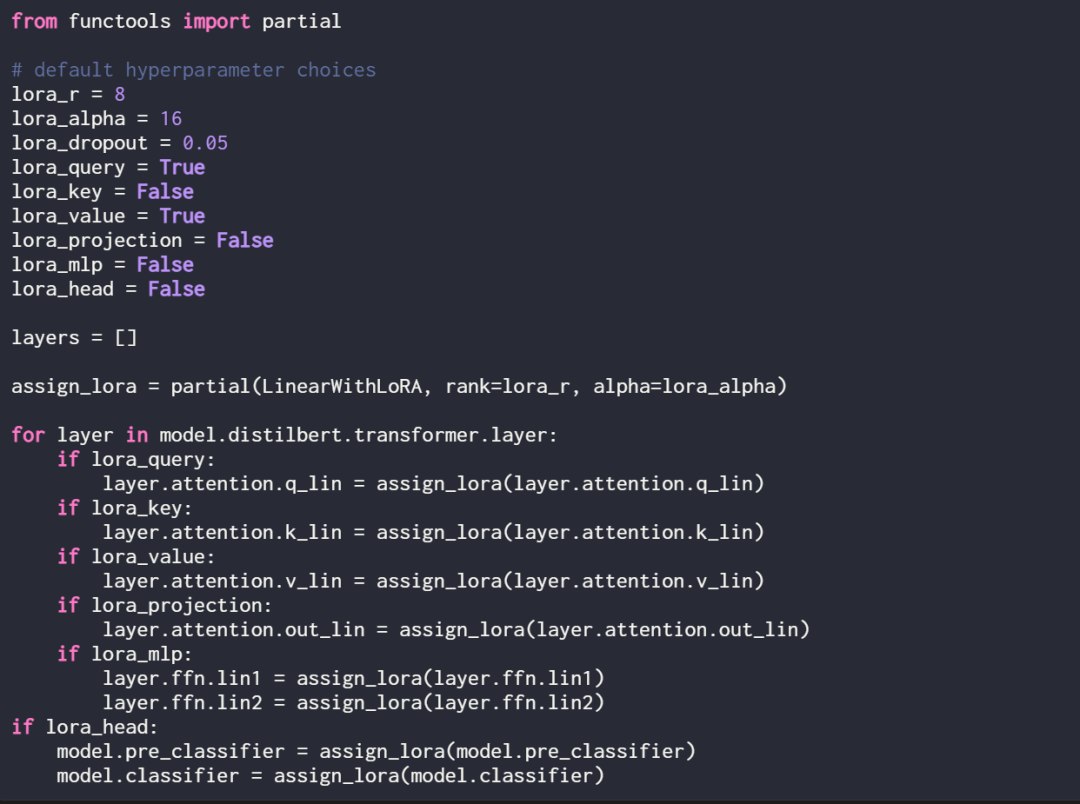
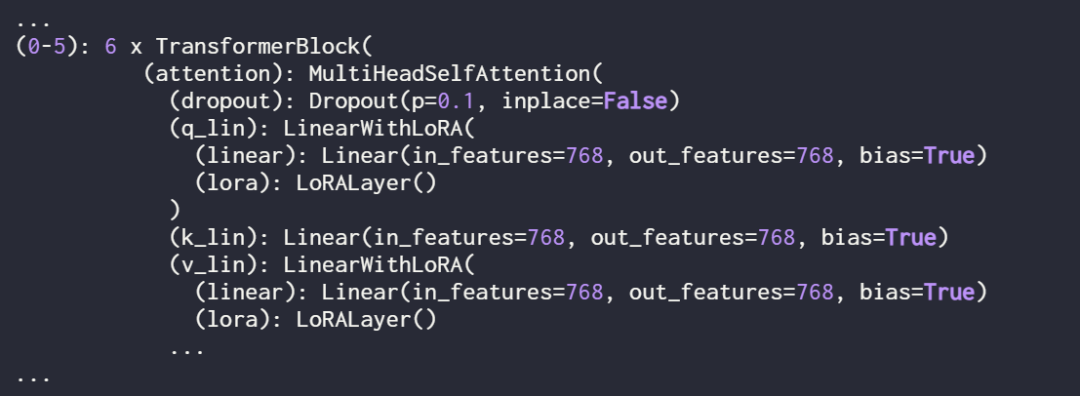
Memandangkan artikel ini hanya melatih pemberat LoRA baharu, anda perlu menetapkan require_grad semua parameter boleh dilatih kepada False untuk membekukan semua parameter model:

Seterusnya, gunakan cetakan (model) Struktur

 Semak model sekali lagi menggunakan cetakan (model) untuk menyemak strukturnya yang dikemas kini:
Semak model sekali lagi menggunakan cetakan (model) untuk menyemak strukturnya yang dikemas kini:
Seperti yang anda lihat di atas, lapisan Linear telah berjaya digantikan oleh lapisan LinearWithLoRA.

Jika anda melatih model menggunakan hiperparameter lalai yang ditunjukkan di atas, ia menghasilkan prestasi berikut pada set data klasifikasi semakan filem IMDb:
 Ketepatan latihan: 92.15%
Ketepatan latihan: 92.15%
9 % ketepatan klasifikasi
 8
8
Ketepatan ujian: 89.44%
Dalam bahagian seterusnya, kertas kerja ini membandingkan keputusan penalaan halus LoRA ini dengan hasil penalaan halus tradisional.
- Perbandingan dengan kaedah penalaan halus tradisional
- Dalam bahagian sebelumnya, LoRA mencapai ketepatan ujian 89.44% di bawah tetapan lalai. Bagaimanakah ini dibandingkan dengan kaedah penalaan halus tradisional?
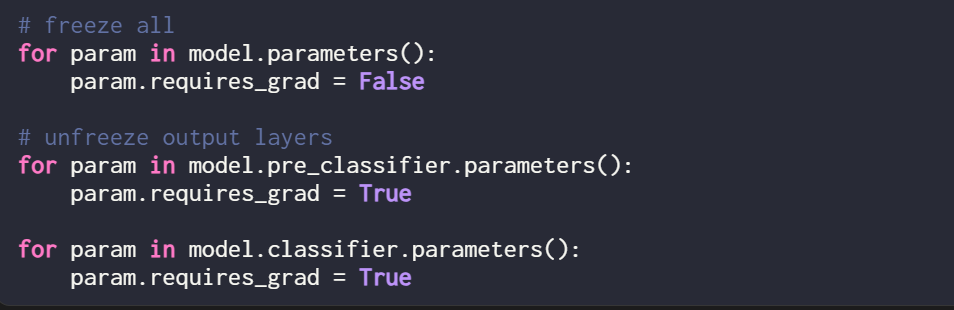
- Sebagai perbandingan, artikel ini menjalankan satu lagi eksperimen, mengambil latihan model DistilBERT sebagai contoh, tetapi hanya mengemas kini 2 lapisan terakhir semasa latihan. Penyelidik mencapai ini dengan membekukan semua berat model dan kemudian menyahbekukan dua lapisan keluaran linear:
Prestasi klasifikasi yang diperolehi dengan melatih hanya dua lapisan terakhir adalah seperti berikut:
:Pengumpulan 8% Latihan. . . Penalaan halus semua lapisan memerlukan pengemaskinian 450 kali lebih banyak parameter daripada persediaan LoRA, tetapi hanya meningkatkan ketepatan ujian sebanyak 2%. . gunakan Perintah berikut:
Walau bagaimanapun, konfigurasi hiperparameter optimum adalah seperti berikut:
Di bawah konfigurasi ini, hasilnya ialah:
-
- Ketepatan pengesahan: 92.96%
- Ketepatan ujian: 92.39%
Perlu diperhatikan bahawa walaupun hanya terdapat sekumpulan kecil parameter ketepatan Lo (ra 600) dalam tetapan boleh dilatih Lo (ra 600) masih lebih tinggi sedikit daripada ketepatan yang diperoleh dengan penalaan halus sepenuhnya.
Pautan asal: https://lightning.ai/lightning-ai/studios/code-lora-from-scratch?cnotallow=f5fc72b1f6eeeaf74b648b2aa8aaf8b6
Atas ialah kandungan terperinci Bagaimana untuk menulis kod LoRA dari awal, berikut adalah tutorial. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!