
Rumah >Peranti teknologi >AI >Jangan tunggu OpenAI, tunggu Open-Sora menjadi sumber terbuka sepenuhnya
Jangan tunggu OpenAI, tunggu Open-Sora menjadi sumber terbuka sepenuhnya

- PHPzke hadapan
- 2024-03-18 20:40:11868semak imbas
Tidak lama dahulu, OpenAI Sora dengan cepat menjadi popular dengan kesan penjanaan videonya yang menakjubkan. Ia menonjol di kalangan ramai model video Wensheng dan menjadi tumpuan perhatian global. Berikutan pelancaran proses pembiakan inferens latihan Sora dengan pengurangan kos sebanyak 46% 2 minggu yang lalu, pasukan Colossal-AI sumber terbuka sepenuhnya menggunakan model penjanaan video seni bina seperti Sora pertama di dunia "Open-Sora 1.0", meliputi keseluruhan proses latihan , termasuk pemprosesan data, semua butiran latihan dan berat model, serta berganding bahu dengan peminat AI global untuk mempromosikan era baharu penciptaan video.
Untuk melihat sekilas, mari kita tonton video bandar yang sibuk yang dihasilkan oleh model "Open-Sora 1.0" yang dikeluarkan oleh pasukan Colossal-AI. Snapshot kota yang sibuk yang dihasilkan oleh Open-Sora 1.0 ini hanyalah hujung gunung es dari teknologi pembiakan Sora. semua butiran latihan pembiakan, Pasukan Colossal-AI telah membuat proses prapemprosesan data, paparan demo dan tutorial permulaan terperinci secara percuma dan sumber terbuka pada GitHub Pada masa yang sama, pengarang menghubungi pasukan itu dengan segera dan mengetahui bahawa mereka akan melakukannya teruskan mengemaskini penyelesaian berkaitan Open-Sora dan perkembangan terkini , rakan-rakan yang berminat boleh terus memberi perhatian kepada komuniti sumber terbuka Open-Sora
.
Alamat sumber terbuka Open-Sora: https://github.com/hpcaitech/Open-Sora
Tafsiran komprehensif penyelesaian replikasi Sora
Seterusnya, kami akan menyelidiki beberapa aspek Sora penyelesaian replikasi Aspek utama termasuk reka bentuk seni bina model, kaedah latihan, prapemprosesan data, paparan kesan model dan strategi latihan pengoptimuman.
Reka bentuk seni bina model
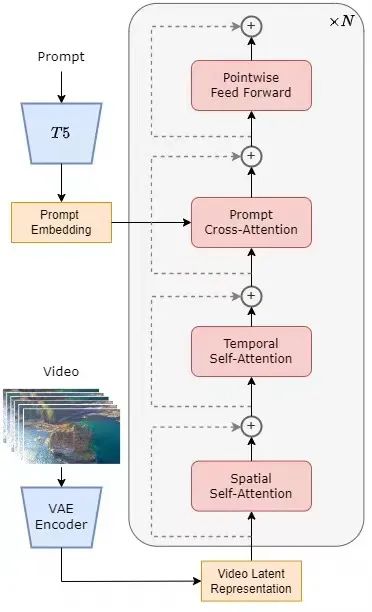
Model ini menggunakan seni bina Diffusion Transformer (DiT) [1] yang popular pada masa ini. Pasukan pengarang menggunakan model graf Vincent sumber terbuka berkualiti tinggi PixArt-α [2] yang turut menggunakan seni bina DiT sebagai asas, memperkenalkan lapisan perhatian sementara atas dasar ini, dan memanjangkannya kepada data video. Secara khususnya, keseluruhan seni bina termasuk VAE yang telah dilatih, pengekod teks dan model STDiT (Spatial Temporal Diffusion Transformer) yang menggunakan mekanisme perhatian spatial-temporal. Antaranya, struktur setiap lapisan STDiT ditunjukkan dalam rajah di bawah. Ia menggunakan kaedah bersiri untuk menindih modul perhatian temporal satu dimensi pada modul perhatian spatial dua dimensi untuk memodelkan hubungan temporal. Selepas modul perhatian temporal, modul perhatian silang digunakan untuk menyelaraskan semantik teks. Berbanding dengan mekanisme perhatian penuh, struktur sedemikian sangat mengurangkan overhed latihan dan inferens. Berbanding dengan model Latte [3], yang turut menggunakan mekanisme perhatian spatial-temporal, STDiT boleh menggunakan pemberat imej pra-latihan DiT dengan lebih baik untuk meneruskan latihan mengenai data video.
STDiT rajah struktur
Proses latihan dan inferens keseluruhan model adalah seperti berikut. Difahamkan bahawa dalam fasa latihan, pengekod Variational Autoencoder (VAE) yang telah dilatih terlebih dahulu digunakan untuk memampatkan data video, dan kemudian model resapan STDiT dilatih bersama-sama dengan pembenaman teks dalam ruang pendam termampat. Dalam peringkat inferens, hingar Gaussian diambil secara rawak daripada ruang terpendam VAE dan dimasukkan ke dalam STDiT bersama-sama dengan pembenaman segera untuk mendapatkan ciri-ciri yang dihilangkan Akhirnya, ia adalah input kepada penyahkod VAE dan dinyahkod untuk mendapatkan video. Proses Latihan Model Rancangan Replikasi yang dipelajari dari pasukan bahawa skim replikasi Open-Sora merujuk kepada kerja penyebaran video yang stabil (SVD) [3]. peringkat, iaitu:
Latihan pra-latihan imej berskala besar.
Pra-latihan video berskala besar.
 Penalaan halus data video berkualiti tinggi.
Penalaan halus data video berkualiti tinggi.
Setiap peringkat akan meneruskan latihan berdasarkan berat peringkat sebelumnya. Berbanding dengan latihan satu peringkat dari awal, latihan berbilang peringkat mencapai matlamat penjanaan video berkualiti tinggi dengan lebih cekap dengan mengembangkan data secara beransur-ansur.
Tiga peringkat pelan latihan
Peringkat pertama: pra-latihan imej berskala besar
Peringkat pertama menggunakan pralatihan imej berskala besar dan menggunakan model graf Vincentian matang untuk mengurangkan kos pralatihan video secara berkesan.
Pasukan pengarang mendedahkan kepada kami bahawa melalui data imej berskala besar yang kaya di Internet dan teknologi graf Vincent yang canggih, kami boleh melatih model graf Vincent berkualiti tinggi, yang akan berfungsi sebagai pemberat permulaan untuk peringkat seterusnya video pra-latihan . Pada masa yang sama, memandangkan pada masa ini tiada VAE spatiotemporal berkualiti tinggi, mereka menggunakan imej VAE yang dipralatih oleh model Stable Diffusion [5]. Strategi ini bukan sahaja memastikan prestasi unggul model awal, tetapi juga mengurangkan kos keseluruhan pra-latihan video dengan ketara.
Peringkat kedua: pra-latihan video berskala besar
Peringkat kedua melaksanakan pralatihan video berskala besar untuk meningkatkan keupayaan generalisasi model dan memahami korelasi siri masa video dengan berkesan.
Kami faham bahawa peringkat ini memerlukan penggunaan sejumlah besar data video untuk latihan bagi memastikan kepelbagaian tema video, dengan itu meningkatkan keupayaan generalisasi model. Model peringkat kedua menambah modul perhatian temporal pada model graf Vincentian peringkat pertama untuk mempelajari hubungan temporal dalam video. Modul yang selebihnya kekal konsisten dengan peringkat pertama dan memuatkan pemberat peringkat pertama sebagai permulaan Pada masa yang sama, output modul perhatian temporal dimulakan kepada sifar untuk mencapai penumpuan yang lebih cekap dan lebih cepat. Pasukan Colossal-AI menggunakan pemberat sumber terbuka daripada PixArt-alpha [2] sebagai permulaan untuk model STDiT peringkat kedua, dan model T5 [6] sebagai pengekod teks. Pada masa yang sama, mereka menggunakan resolusi kecil 256x256 untuk pra-latihan, yang meningkatkan lagi kelajuan penumpuan dan mengurangkan kos latihan.
Peringkat ketiga: memperhalusi data video berkualiti tinggi
Peringkat ketiga memperhalusi data video berkualiti tinggi untuk meningkatkan kualiti penjanaan video dengan ketara.
Pasukan pengarang menyebut bahawa saiz data video yang digunakan pada peringkat ketiga adalah satu urutan magnitud kurang daripada itu pada peringkat kedua, tetapi tempoh, resolusi dan kualiti video lebih tinggi. Dengan penalaan halus dengan cara ini, mereka mencapai penskalaan penjanaan video yang cekap daripada pendek ke panjang, daripada peleraian rendah ke tinggi dan dari kesetiaan rendah ke tinggi.
Pasukan pengarang menyatakan bahawa dalam proses pembiakan Open-Sora, mereka menggunakan 64 blok H800 untuk latihan. Jumlah volum latihan peringkat kedua ialah 2808 jam GPU, iaitu kira-kira $7000, dan volum latihan peringkat ketiga ialah 1920 jam GPU, iaitu kira-kira $4500. Selepas anggaran awal, keseluruhan program latihan berjaya mengawal proses pembiakan Open-Sora kepada kira-kira AS$10,000. . -latihan termasuk memuat turun set data video awam, membahagikan video panjang kepada klip video pendek berdasarkan kesinambungan tangkapan, dan menggunakan model bahasa besar sumber terbuka LLaVA [7] untuk menjana perkataan segera yang tepat. Pasukan pengarang menyebut bahawa kod penjanaan tajuk video kelompok yang mereka berikan boleh menganotasi video dengan dua kad dan 3 saat, dan kualitinya hampir dengan GPT-4V. Pasangan video/teks yang terhasil boleh digunakan terus untuk latihan. Dengan kod sumber terbuka yang mereka sediakan di GitHub, kami boleh dengan mudah dan cepat menjana pasangan video/teks yang diperlukan untuk latihan pada set data kami sendiri, dengan ketara mengurangkan ambang teknikal dan persediaan awal untuk memulakan projek replikasi Sora.
Gandingan video/teks dijana secara automatik berdasarkan skrip prapemprosesan data
Paparan kesan penjanaan model
Mari kita lihat kesan penjanaan video Open-Sora sebenar. Sebagai contoh, biarkan Open-Sora menjana rakaman udara air laut yang menghantam batu di pantai tebing.
Biarkan Open-Sora menangkap pemandangan gunung dan air terjun yang megah turun dari tebing dan akhirnya mengalir ke dalam tasik.

Selain pergi ke langit, anda juga boleh memasuki laut dengan mudah dan biarkan Open-Sora menjana gambar dunia bawah air terumbu karang.

Open-Sora juga boleh menunjukkan kepada kita Bima Sakti dengan bintang berkelipan melalui fotografi selang masa.

Jika anda mempunyai idea yang lebih menarik untuk penjanaan video, anda boleh melawati komuniti sumber terbuka Open-Sora untuk mendapatkan berat model untuk pengalaman percuma. Pautan: https://github.com/hpcaitech/Open-Sora
Perlu diperhatikan bahawa pasukan pengarang menyebut di Github bahawa versi semasa hanya menggunakan 400K data latihan, kualiti penjanaan model dan keupayaan untuk mengikuti teks Semua perlu diperbaiki. Sebagai contoh, dalam video penyu di atas, penyu yang terhasil mempunyai kaki tambahan. Open-Sora 1.0 juga tidak pandai menghasilkan potret dan imej yang kompleks. Pasukan pengarang menyenaraikan satu siri rancangan yang perlu dilakukan pada Github, bertujuan untuk terus menyelesaikan kecacatan sedia ada dan meningkatkan kualiti pengeluaran.
Sokongan latihan yang cekap
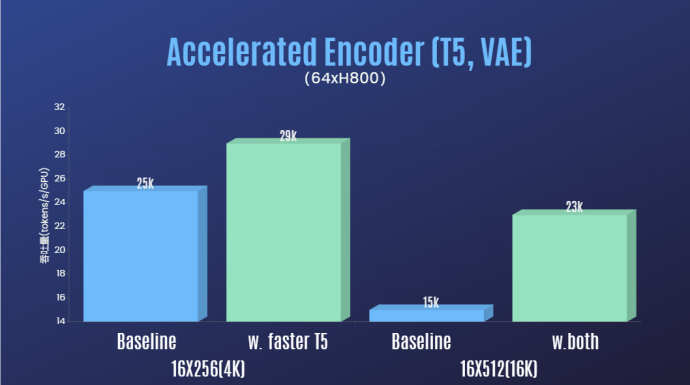
Selain mengurangkan dengan ketara ambang teknikal untuk pembiakan Sora dan meningkatkan kualiti penjanaan video dalam pelbagai dimensi seperti tempoh, resolusi dan kandungan, pasukan pengarang juga menyediakan pecutan Colossal-AI sistem untuk pembiakan Sora Sokongan latihan yang cekap sekarang. Melalui strategi latihan yang cekap seperti pengoptimuman operator dan paralelisme hibrid, kesan pecutan sebanyak 1.55 kali dicapai dalam latihan pemprosesan video 64-bingkai, 512x512. Pada masa yang sama, terima kasih kepada sistem pengurusan memori heterogen Colossal-AI, tugas latihan video definisi tinggi 1080p 1 minit boleh dilakukan tanpa halangan pada pelayan tunggal (8*H800).
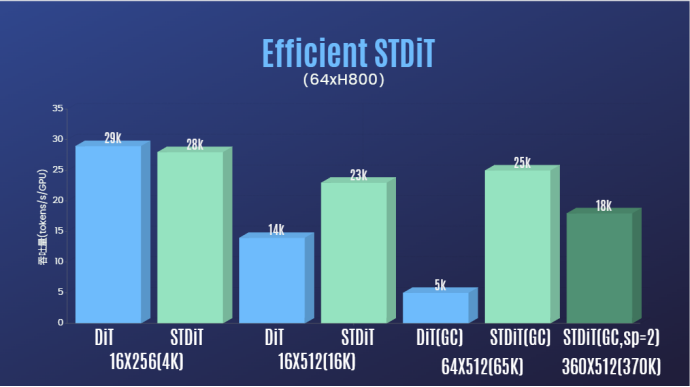
Selain itu, dalam laporan pasukan pengarang, kami juga mendapati bahawa seni bina model STDiT juga menunjukkan kecekapan yang sangat baik semasa latihan. Berbanding dengan DiT, yang menggunakan mekanisme perhatian penuh, STDiT mencapai pecutan sehingga 5 kali ganda apabila bilangan bingkai bertambah, yang amat kritikal dalam tugas dunia sebenar seperti memproses jujukan video yang panjang.
Alu-alukan untuk terus memberi perhatian kepada projek sumber terbuka Open-Sora: https://github.com/hpcaitech/Open-Sora
Pasukan penulis menyatakan bahawa mereka akan terus mengekalkan dan mengoptimumkan projek Open-Sora dan dijangka akan Menggunakan lebih banyak data latihan video untuk menjana kualiti yang lebih tinggi, kandungan video yang lebih panjang, dan menyokong ciri berbilang resolusi untuk mempromosikan pelaksanaan teknologi AI secara berkesan dalam filem, permainan, pengiklanan dan bidang lain.
Pautan rujukan:
[1] https://arxiv.org/abs/2212.09748 Model Resapan Boleh Skala dengan Transformer.
[2] https://arxiv.org/abs/2310.00426 PixArt-α: Latihan Pantas Transformer Resapan untuk Sintesis Teks-ke-Imej Fotorealistik.
[3] https://arxiv.org/abs/2311.15127 Resapan Video Stabil: Menskalakan Model Resapan Video Terpendam kepada Set Data Besar.
[4] https://arxiv.org/abs/2401.03048 Latte: Pengubah Resapan Terpendam untuk Penjanaan Video.
[5] https://huggingface.co/stabilityai/sd-vae-ft-mse-original.
[6] https://github.com/google-research/text-to-text-transfer-transformer.
[7] https://github.com/haotian-liu/LLaVA.
[8] https://hpc-ai.com/blog/open-sora-v1.0.
Atas ialah kandungan terperinci Jangan tunggu OpenAI, tunggu Open-Sora menjadi sumber terbuka sepenuhnya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 人工智能的本质是对人类智能的模拟甚至超越,对吗?
- 自然语言理解是人工智能重要应用领域,它要实现的目标是什么
- 人工智能、机器学习、深度学习的关系是什么
- Kedudukan 'kadar penukaran petikan tinggi' kertas AI dikeluarkan: OpenAI di tempat pertama, Megvii di tempat kedua dan Google di tempat kesembilan
- Tontonan topik ChatGPT Zhihu melebihi 200 juta, pekerja OpenAI menyertai perbincangan