
Rumah >Peranti teknologi >AI >Kerja baharu pada ramalan siri masa + model besar NLP: secara automatik menjana gesaan tersirat untuk ramalan siri masa
Kerja baharu pada ramalan siri masa + model besar NLP: secara automatik menjana gesaan tersirat untuk ramalan siri masa

- 王林ke hadapan
- 2024-03-18 09:20:101233semak imbas
Hari ini saya ingin berkongsi kerja penyelidikan baru-baru ini dari Universiti Connecticut yang mencadangkan kaedah untuk menjajarkan data siri masa dengan model pemprosesan bahasa semula jadi (NLP) yang besar pada ruang terpendam untuk meningkatkan Kesan siri masa. Kunci kepada kaedah ini ialah menggunakan petunjuk spatial terpendam (prompt) untuk meningkatkan ketepatan ramalan siri masa. . 1. Latar belakang masalah
Model besar semakin digunakan dalam siri masa, terutamanya dibahagikan kepada dua kategori: kategori pertama menggunakan pelbagai data siri masa untuk melatih model besarnya sendiri dalam medan siri masa, kategori kedua secara langsung menggunakan teks yang dilatih dalam medan NLP Besar model digunakan pada siri masa. Oleh kerana siri masa adalah berbeza daripada imej dan teks, set data yang berbeza mempunyai format input dan pengedaran yang berbeza, dan terdapat masalah seperti anjakan pengedaran, menjadikannya sukar untuk melatih model bersatu menggunakan semua data siri masa. Oleh itu, semakin banyak kerja telah mula cuba menggunakan model besar NLP secara langsung untuk menyelesaikan masalah berkaitan siri masa. 
2. Kaedah pelaksanaan
Berikut memperkenalkan kaedah pelaksanaan kerja ini dari tiga aspek: pemprosesan data, penjajaran ruang terpendam dan butiran model.
Pemprosesan data: Disebabkan masalah seperti anjakan pengedaran siri masa, artikel ini melakukan penguraian satu langkah item trend dan item bermusim pada siri input. Setiap siri masa terurai diseragamkan secara berasingan dan kemudian dibahagikan kepada tompok bertindih. Setiap set patch sepadan dengan patch istilah trend, patch jangka bermusim, dan patch baki ketiga-tiga set patch ini disambungkan bersama-sama dan dimasukkan ke dalam MLP untuk mendapatkan perwakilan benam asas bagi setiap set patch.
Penjajaran ruang terpendam: Ini ialah langkah teras dalam artikel ini. Reka bentuk gesaan mempunyai impak yang besar pada prestasi model besar, dan gesaan siri masa sukar untuk direka bentuk. Oleh itu, artikel ini bercadang untuk menjajarkan perwakilan tampung siri masa dengan pembenaman perkataan model besar dalam ruang terpendam, dan kemudian mendapatkan semula pembenaman perkataan topK sebagai gesaan tersirat. Kaedah khusus ialah menggunakan pembenaman tampalan yang dijana dalam langkah sebelumnya untuk mengira persamaan kosinus dengan pembenaman perkataan dalam model bahasa, pilih pembenaman perkataan topK dan kemudian gunakan pembenaman perkataan ini sebagai gesaan untuk menyambungkannya ke hadapan benam tampalan siri masa. Memandangkan terdapat banyak benam perkataan dalam model besar, untuk mengurangkan jumlah pengiraan, kami mula-mula memetakan perkataan benam ke sebilangan kecil pusat kelompok. 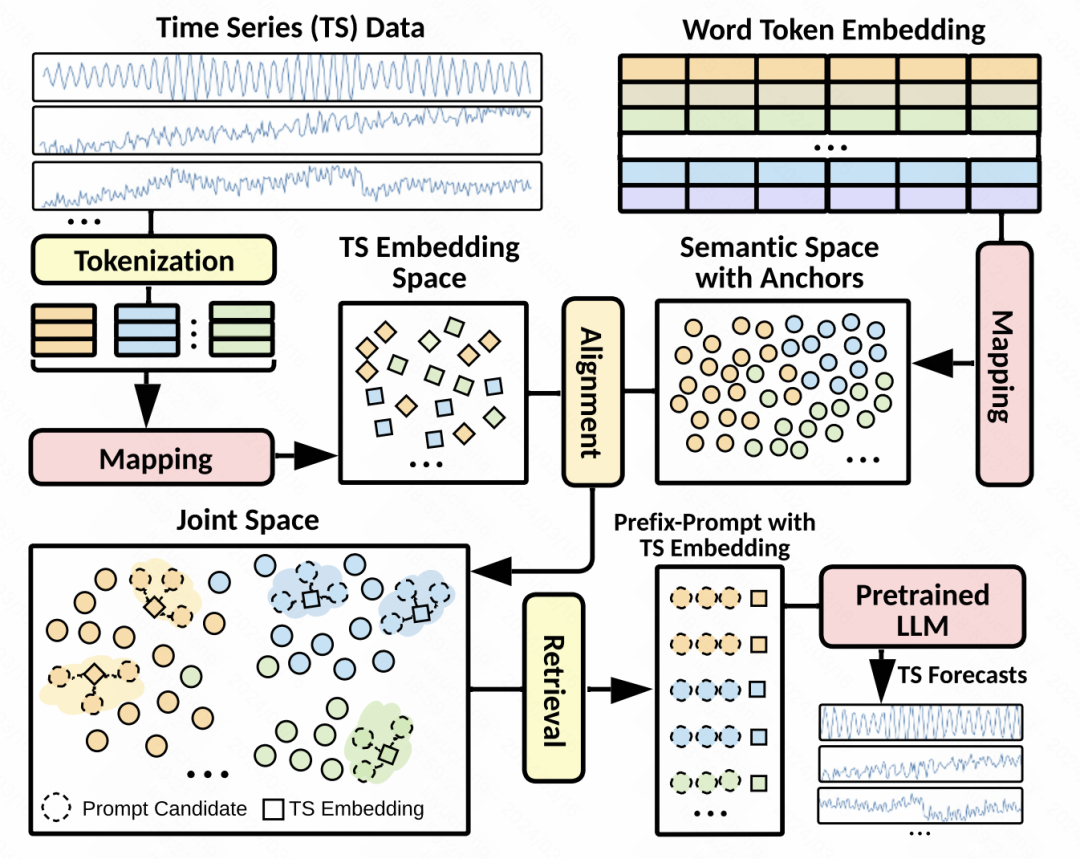 Butiran model: Dari segi butiran model, GPT2 digunakan sebagai bahagian model bahasa Kecuali untuk parameter bahagian pembenaman kedudukan dan penormalan lapisan, selebihnya dibekukan. Selain MSE, matlamat pengoptimuman juga memperkenalkan persamaan antara pembenaman tampalan dan pembenaman gugusan topK yang diambil sebagai kekangan, yang memerlukan jarak antara keduanya sekecil mungkin. Keputusan ramalan akhir juga ialah
Butiran model: Dari segi butiran model, GPT2 digunakan sebagai bahagian model bahasa Kecuali untuk parameter bahagian pembenaman kedudukan dan penormalan lapisan, selebihnya dibekukan. Selain MSE, matlamat pengoptimuman juga memperkenalkan persamaan antara pembenaman tampalan dan pembenaman gugusan topK yang diambil sebagai kekangan, yang memerlukan jarak antara keduanya sekecil mungkin. Keputusan ramalan akhir juga ialah
3 Keputusan percubaan
Artikel membandingkan kesan beberapa model siri masa yang besar, iTransformer, PatchTST dan model SOTA lain dan ramalan dalam tetingkap masa yang berbeza bagi kebanyakan data set Kedua-duanya telah mencapai keputusan yang agak baik.
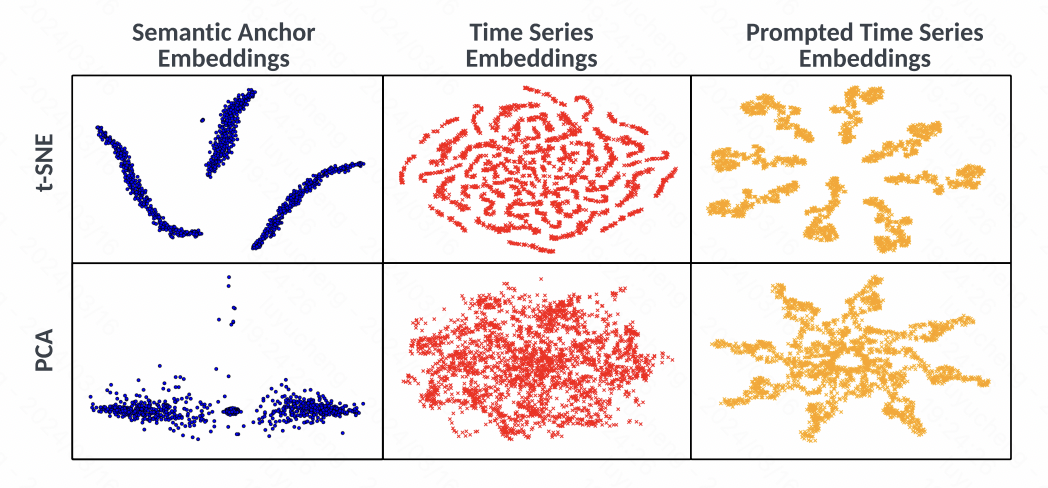
Gambar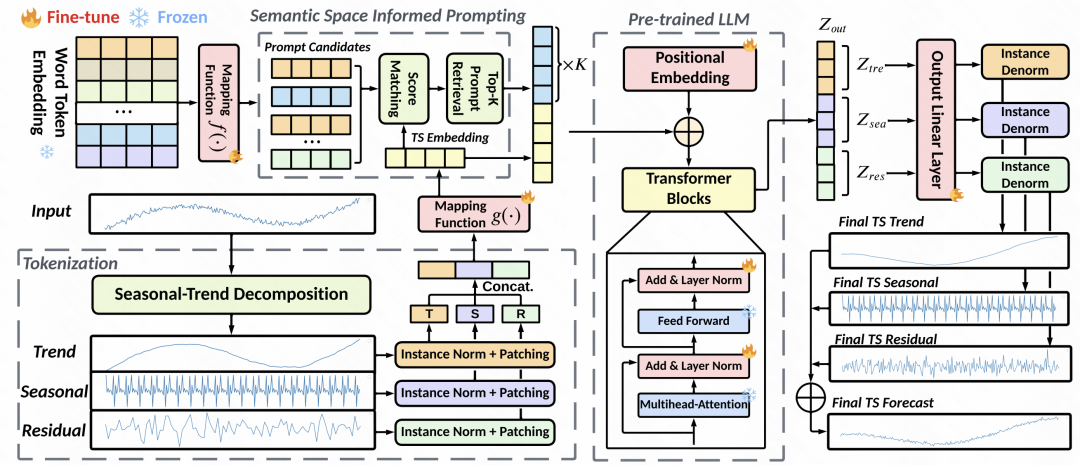 Pada masa yang sama, artikel itu juga menganalisis secara visual pembenaman melalui t-SNE Seperti yang dapat dilihat daripada rajah, pembenaman siri masa tidak mempunyai fenomena pengelompokan yang jelas sebelum penjajaran, manakala pembenaman. dijana melalui gesaan mempunyai Perubahan jelas dalam kelompok menunjukkan bahawa kaedah yang dicadangkan dalam artikel ini menggunakan penjajaran spatial teks dan siri masa, serta gesaan yang sepadan, untuk meningkatkan kualiti perwakilan siri masa.
Pada masa yang sama, artikel itu juga menganalisis secara visual pembenaman melalui t-SNE Seperti yang dapat dilihat daripada rajah, pembenaman siri masa tidak mempunyai fenomena pengelompokan yang jelas sebelum penjajaran, manakala pembenaman. dijana melalui gesaan mempunyai Perubahan jelas dalam kelompok menunjukkan bahawa kaedah yang dicadangkan dalam artikel ini menggunakan penjajaran spatial teks dan siri masa, serta gesaan yang sepadan, untuk meningkatkan kualiti perwakilan siri masa.
 Gambar
Gambar
Atas ialah kandungan terperinci Kerja baharu pada ramalan siri masa + model besar NLP: secara automatik menjana gesaan tersirat untuk ramalan siri masa. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!