
Rumah >Peranti teknologi >AI >Direka bentuk untuk latihan Llama 3, butiran kluster Meta 49,000 H100 diumumkan
Direka bentuk untuk latihan Llama 3, butiran kluster Meta 49,000 H100 diumumkan

- PHPzke hadapan
- 2024-03-15 11:30:111313semak imbas
Model besar generatif telah menyebabkan perubahan besar dalam bidang kecerdasan buatan Walaupun harapan orang ramai untuk mencapai kecerdasan buatan am (AGI) semakin meningkat, kuasa pengkomputeran yang diperlukan untuk melatih dan menggunakan model besar juga semakin besar.
Sebentar tadi, Meta mengumumkan pelancaran dua kluster GPU 24k (sejumlah 49152 H100s), menandakan pelaburan utama Meta dalam masa depan kecerdasan buatan.
Ini adalah sebahagian daripada pelan infrastruktur Meta yang bercita-cita tinggi. Menjelang akhir tahun 2024, Meta merancang untuk mengembangkan infrastrukturnya untuk memasukkan 350,000 GPU NVIDIA H100, yang akan memberikan kuasa pengkomputeran yang setara dengan hampir 600,000 H100. Meta komited untuk terus mengembangkan infrastrukturnya untuk memenuhi keperluan masa hadapan.
Meta menekankan: "Kami tegas menyokong pengkomputeran terbuka dan teknologi sumber terbuka. Kami telah membina kelompok pengkomputeran ini berdasarkan Grand Teton, OpenRack dan PyTorch, dan akan terus mempromosikan inovasi terbuka di seluruh industri. Kami akan memanfaatkan ini Mengkomputerkan kelompok sumber untuk melatih Llama 3. "
Pemenang Anugerah Turing dan ketua saintis Meta Yann LeCun turut menulis tweet untuk menekankan perkara ini.
Meta berkongsi butiran tentang perkakasan, rangkaian, storan, reka bentuk, prestasi dan perisian kluster baharu, yang direka untuk memberikan daya pemprosesan yang tinggi dan kebolehpercayaan yang tinggi untuk pelbagai beban kerja kecerdasan buatan.
Tinjauan Kluster
Visi jangka panjang Meta adalah untuk membina kecerdasan buatan am yang terbuka dan bertanggungjawab supaya semua orang boleh menggunakannya secara meluas dan mendapat manfaat daripadanya.
Pada tahun 2022, Meta berkongsi buat kali pertama butiran Kluster Super Penyelidikan AI (RSC) yang dilengkapi dengan 16,000 GPU NVIDIA A100. RSC memainkan peranan penting dalam pembangunan Llama dan Llama 2, serta dalam pembangunan model kecerdasan buatan lanjutan dalam penglihatan komputer, NLP, pengecaman pertuturan, penjanaan imej, pengekodan dan banyak lagi.
Kluster AI terbaharu Meta dibina berdasarkan kejayaan dan pengajaran yang dipelajari daripada fasa sebelumnya. Meta menekankan komitmennya untuk membina sistem kecerdasan buatan yang komprehensif dan menumpukan pada meningkatkan pengalaman dan kecekapan kerja penyelidik dan pembangun.
Fabrik rangkaian berprestasi tinggi yang digunakan dalam dua kluster baharu, digabungkan dengan keputusan storan utama dan 24,576 GPU NVIDIA Tensor Core H100 dalam setiap kluster, membolehkan kedua-dua kluster ini menyokong kluster yang lebih besar dan lebih kompleks daripada model kluster RSC.
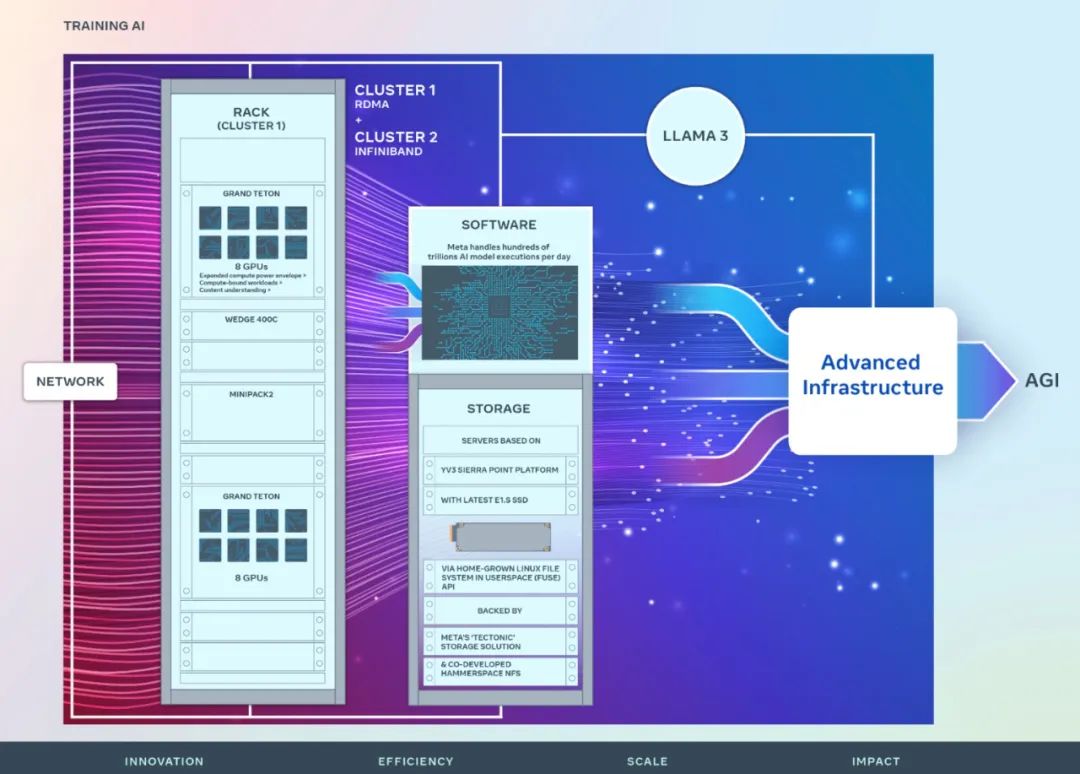
Rangkaian
Meta memproses ratusan bilion model AI dijalankan setiap hari. Menyediakan model AI pada skala besar memerlukan infrastruktur yang sangat maju dan fleksibel.
Untuk mengoptimumkan pengalaman hujung ke hujung untuk penyelidik kecerdasan buatan sambil memastikan pusat data Meta beroperasi dengan cekap, Meta membina protokol komunikasi rangkaian kluster berdasarkan Arista 7800 dan Wedge400 dan suis rak Minipack2, sebuah rangkaian kelompok struktur yang melaksanakan Akses Memori Langsung Jauh (RDMA) melalui Ethernet. Kelompok lain menggunakan fabrik NVIDIA Quantum2 InfiniBand. Kedua-dua penyelesaian saling menyambung titik akhir 400 Gbps.
Dua kluster baharu ini boleh digunakan untuk menilai kesesuaian dan kebolehskalaan pelbagai jenis interkoneksi untuk latihan berskala besar, membantu Meta memahami cara mereka bentuk dan membina kluster berskala lebih besar pada masa hadapan. Melalui reka bentuk bersama rangkaian, perisian dan seni bina model yang teliti, Meta berjaya memanfaatkan kluster RoCE dan InfiniBand untuk beban kerja GenAI yang besar tanpa sebarang kesesakan rangkaian.
Compute
Kedua-dua kelompok dibina menggunakan Grand Teton, platform perkakasan GPU terbuka yang direka secara dalaman di Meta.
Grand Teton dibina pada berbilang generasi sistem AI, menyepadukan antara muka kuasa, kawalan, pengiraan dan fabrik ke dalam satu casis untuk prestasi keseluruhan yang lebih baik, integriti isyarat dan prestasi terma. Ia memberikan kebolehskalaan dan fleksibiliti pantas dalam reka bentuk yang dipermudahkan, membolehkan ia digunakan dengan cepat ke dalam kumpulan pusat data dan diselenggara dan dikembangkan dengan mudah.
Storage
Storage memainkan peranan penting dalam latihan AI, tetapi merupakan salah satu aspek yang paling kurang diperkatakan.
Seiring berjalannya waktu, usaha latihan GenAI telah menjadi lebih multimodal, menggunakan sejumlah besar data imej, video dan teks, dan permintaan untuk penyimpanan data telah berkembang dengan pesat.
Penempatan storan Meta untuk kluster baharu memenuhi keperluan data dan titik semakan bagi kluster AI melalui API Sistem Fail Linux Asli (FUSE) dalam ruang pengguna, yang dikuasakan oleh penyelesaian storan teragih "Tektonik" Meta. Penyelesaian ini membolehkan beribu-ribu GPU menyimpan dan memuatkan pusat pemeriksaan secara segerak, di samping menyediakan storan berskala exabait yang fleksibel dan tinggi yang diperlukan untuk pemuatan data.
Meta juga bekerjasama dengan Hammerspace untuk bersama-sama membangunkan dan melaksanakan penempatan Sistem Fail Rangkaian (NFS) selari. Hammerspace membolehkan jurutera melakukan penyahpepijatan interaktif kerja menggunakan beribu-ribu GPU.
Prestasi
Meta Salah satu prinsip untuk membina kelompok kecerdasan buatan berskala besar adalah untuk memaksimumkan prestasi dan kemudahan penggunaan secara serentak. Ini adalah prinsip penting untuk mencipta model AI terbaik dalam kelasnya.
Meta Apabila menolak had sistem kecerdasan buatan, cara terbaik untuk menguji keupayaan reka bentuk berskala adalah dengan membina sistem, kemudian mengoptimumkan dan benar-benar mengujinya (sementara simulator membantu, mereka hanya boleh pergi sejauh ini ).
Dalam reka bentuk ini, Meta membandingkan prestasi kelompok kecil dan kelompok besar untuk memahami di mana kesesakan itu. Berikut menunjukkan prestasi AllGather kolektif (dinyatakan sebagai lebar jalur normal pada skala 0-100) apabila sebilangan besar GPU berkomunikasi antara satu sama lain pada saiz komunikasi dengan prestasi yang dijangkakan tertinggi.
Prestasi kluster besar di luar kotak pada mulanya adalah lemah dan tidak konsisten berbanding prestasi kluster kecil yang dioptimumkan. Untuk menangani isu ini, Meta membuat beberapa perubahan pada cara penjadual kerja dalaman ditala dengan kesedaran topologi rangkaian, yang membawa faedah kependaman dan meminimumkan trafik ke lapisan atas rangkaian.
Meta juga mengoptimumkan dasar penghalaan rangkaian bersama-sama dengan perubahan Perpustakaan Komunikasi Kolektif NVIDIA (NCCL) untuk penggunaan rangkaian yang optimum. Ini membantu memacu kluster besar untuk mencapai prestasi jangkaan yang sama seperti kluster yang lebih kecil.
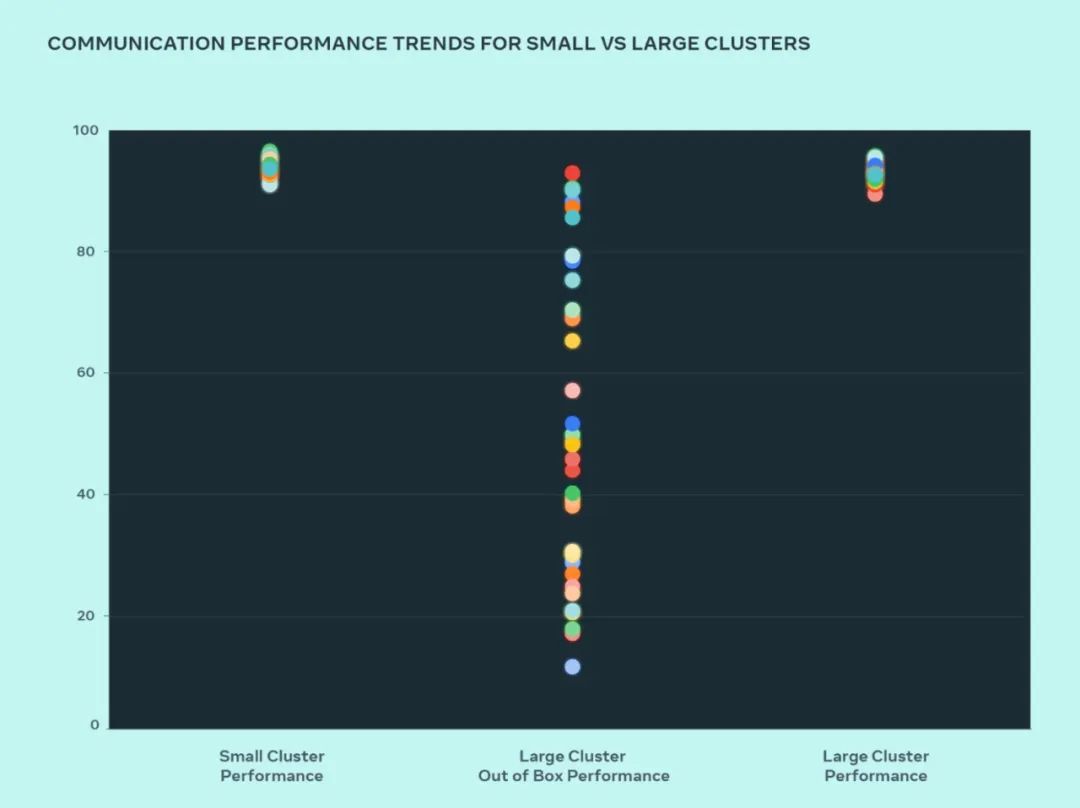
Kita dapat lihat daripada rajah bahawa prestasi kluster kecil (lebar lebar komunikasi keseluruhan dan penggunaan) mencapai 90%+ di luar kotak, tetapi penggunaan prestasi kluster besar yang tidak dioptimumkan adalah sangat rendah, daripada 10% Ia berbeza-beza daripada 90% hingga 90%. Selepas mengoptimumkan keseluruhan sistem (perisian, rangkaian, dll.) kami melihat prestasi kelompok besar kembali kepada julat 90%+ yang ideal.
Selain perubahan perisian kepada infrastruktur dalaman, Meta bekerjasama rapat dengan pasukan yang menulis rangka kerja dan model latihan untuk menyesuaikan diri dengan infrastruktur yang berkembang. Sebagai contoh, GPU NVIDIA H100 membuka kemungkinan latihan dengan jenis data baharu seperti titik terapung 8-bit (FP8). Mengambil kesempatan sepenuhnya daripada kluster yang lebih besar memerlukan pelaburan dalam teknik penyejajaran tambahan dan penyelesaian storan baharu, yang memberikan peluang untuk mengoptimumkan pusat pemeriksaan pada beribu-ribu tahap untuk berjalan dalam ratusan milisaat.
Meta juga mengiktiraf bahawa kebolehnyahpenyahpecatan adalah salah satu cabaran utama latihan pada skala. Mengenal pasti GPU sesat yang menghalang keseluruhan latihan adalah sukar pada skala. Meta sedang membina alatan seperti penyahpepijatan tak segerak atau perakam penerbangan kolektif yang diedarkan untuk mendedahkan butiran latihan yang diedarkan dan membantu mengenal pasti masalah apabila ia timbul dengan cara yang lebih cepat dan mudah.
Atas ialah kandungan terperinci Direka bentuk untuk latihan Llama 3, butiran kluster Meta 49,000 H100 diumumkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!