

 Peranti teknologiAIKarya baharu oleh Yan Shuicheng/Cheng Mingming! Latihan DiT, komponen teras Sora, dipercepatkan sebanyak 10 kali, dan Masked Diffusion Transformer V2 ialah sumber terbuka
Peranti teknologiAIKarya baharu oleh Yan Shuicheng/Cheng Mingming! Latihan DiT, komponen teras Sora, dipercepatkan sebanyak 10 kali, dan Masked Diffusion Transformer V2 ialah sumber terbukaKarya baharu oleh Yan Shuicheng/Cheng Mingming! Latihan DiT, komponen teras Sora, dipercepatkan sebanyak 10 kali, dan Masked Diffusion Transformer V2 ialah sumber terbuka

Sebagai salah satu teknologi teras Sora yang menarik, DiT menggunakan Diffusion Transformer untuk menskalakan model generatif kepada skala yang lebih besar untuk mencapai kesan penjanaan imej yang cemerlang.
Namun, saiz model yang lebih besar menyebabkan kos latihan melambung tinggi.
Pasukan penyelidik Yan Shuicheng dan Cheng Mingming dari Sea AI Lab, Nankai University, dan Institut Penyelidikan Kunlun Wanwei 2050 mencadangkan model baharu yang dipanggil Masked Diffusion Transformer pada persidangan ICCV 2023. Model ini menggunakan teknologi pemodelan topeng untuk mempercepatkan latihan Diffusion Transformer dengan mempelajari maklumat perwakilan semantik, dan mencapai keputusan SoTA dalam bidang penjanaan imej. Inovasi ini membawa penemuan baharu kepada pembangunan model penjanaan imej dan menyediakan penyelidik kaedah latihan yang lebih cekap. Dengan menggabungkan kepakaran dan teknologi dari pelbagai bidang, pasukan penyelidik berjaya mencadangkan penyelesaian yang meningkatkan kelajuan latihan dan meningkatkan hasil penjanaan. Kerja mereka telah menyumbang idea inovatif yang penting kepada pembangunan bidang kecerdasan buatan dan memberikan inspirasi berguna untuk penyelidikan dan amalan masa depan 2303.14389
Alamat GitHub: https://github.com/sail-sg/MDT
 Baru-baru ini. , Masked Diffusion Transformer V2 telah menyegarkan semula SoTA Berbanding dengan DiT, kelajuan latihan meningkat lebih daripada 10 kali ganda, dan ia telah mencapai penanda aras ImageNet 1.58.
Baru-baru ini. , Masked Diffusion Transformer V2 telah menyegarkan semula SoTA Berbanding dengan DiT, kelajuan latihan meningkat lebih daripada 10 kali ganda, dan ia telah mencapai penanda aras ImageNet 1.58.
Sebagai contoh, seperti yang ditunjukkan dalam gambar di atas, DiT telah belajar untuk menjana tekstur rambut anjing pada langkah latihan ke-50, dan kemudian belajar untuk menjana salah satu daripada mata anjing pada ke-200. langkah latihan dan mulut, tetapi mata lain hilang.
 Walaupun pada langkah latihan 300k, kedudukan relatif dua telinga anjing yang dijana oleh DiT tidak begitu tepat.
Walaupun pada langkah latihan 300k, kedudukan relatif dua telinga anjing yang dijana oleh DiT tidak begitu tepat.
Seperti yang ditunjukkan dalam rajah di atas, MDT memperkenalkan strategi pembelajaran model topeng sambil mengekalkan proses latihan penyebaran. Dengan menutup token imej bising, MDT menggunakan seni bina Pengubah Resapan asimetri (Pengubah Resapan Asymmetric) untuk meramalkan token imej bertopeng daripada token imej bising yang belum bertopeng, sekali gus mencapai proses latihan pemodelan topeng dan resapan.

Semasa proses inferens, MDT masih mengekalkan proses penjanaan resapan piawai. Reka bentuk MDT membantu Diffusion Transformer mempunyai kedua-dua keupayaan ekspresi maklumat semantik yang dibawa oleh pembelajaran perwakilan model topeng dan keupayaan model resapan untuk menjana butiran imej.
Secara khusus, MDT memetakan imej ke ruang terpendam melalui pengekod VAE dan memprosesnya dalam ruang terpendam untuk menjimatkan kos pengkomputeran.
Semasa proses latihan, MDT mula-mula menutup sebahagian daripada token imej selepas menambah hingar, dan menghantar token yang tinggal ke Transformer Resapan Asymmetric untuk meramalkan semua token imej selepas menafikan.
Seni bina Asymmetric Diffusion Transformer
 Picture
Picture
Seperti yang ditunjukkan dalam rajah di atas, Asymmetric Diffusion epolcoder Transformer (polycoder.auxili) termasuk Asymmetric Diffusion Intercoder Transformer
 Gambar
Gambar
Semasa proses latihan, Pengekod hanya memproses token yang tidak bertopeng semasa proses inferens, kerana tiada langkah topeng, ia memproses semua token.
Oleh itu, untuk memastikan penyahkod sentiasa boleh memproses semua token semasa fasa latihan atau inferens, penyelidik mencadangkan penyelesaian: semasa proses latihan, melalui interpolator tambahan yang terdiri daripada blok DiT (seperti yang ditunjukkan dalam rajah di atas ), interpolasi dan ramalkan token bertopeng daripada output pengekod, dan alih keluarnya semasa peringkat inferens tanpa menambah sebarang overhed inferens.
Pengekod dan penyahkod MDT memasukkan maklumat pengekodan kedudukan global dan tempatan ke dalam blok DiT standard untuk membantu meramalkan token di bahagian topeng.
Asymmetric Diffusion Transformer V2
 Pictures
Pictures
Seperti yang ditunjukkan dalam gambar di atas, MDTv2 terus mengoptimumkan proses difducing dan diffusion yang lebih cekap proses pemodelan.
Ini termasuk menyepadukan pintasan panjang gaya U-Net dalam pengekod dan pintasan input padat dalam penyahkod.
Antaranya, pintasan input padat menghantar token bertopeng selepas menambah bunyi pada penyahkod, mengekalkan maklumat hingar yang sepadan dengan token bertopeng, sekali gus memudahkan latihan proses penyebaran.
Selain itu, MDT juga telah memperkenalkan strategi latihan yang lebih baik termasuk penggunaan pengoptimum Adan yang lebih pantas, berat kehilangan berkaitan langkah masa, dan nisbah topeng yang diperluas untuk mempercepatkan lagi proses latihan model Resapan Bertopeng. .
Jelas sekali bahawa MDT mencapai markah FID yang lebih tinggi dengan kos latihan yang lebih rendah pada semua saiz model.
Parameter dan kos inferens MDT pada asasnya adalah sama dengan DiT, kerana seperti yang dinyatakan di atas, proses resapan piawai yang konsisten dengan DiT masih dikekalkan dalam proses inferens MDT. 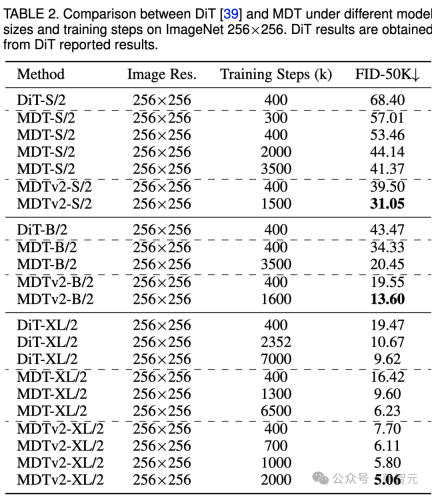
Untuk model kecil, MDTv2-S/2 masih mencapai prestasi yang jauh lebih baik daripada DiT-S/2 dengan langkah latihan yang jauh lebih sedikit. Sebagai contoh, dengan latihan yang sama sebanyak 400k langkah, MDTv2 mempunyai indeks FID 39.50, yang jauh mendahului indeks FID DiT sebanyak 68.40.
Lebih penting lagi, keputusan ini juga melebihi prestasi model DiT-B/2 yang lebih besar pada 400k langkah latihan (39.50 vs 43.47).
ImageNet 256 penanda aras perbandingan kualiti penjanaan CFG
 imej
imej
Kami juga membandingkan prestasi penjanaan imej MDT dengan kaedah sedia ada di bawah bimbingan tanpa pengelas dalam jadual di atas.
MDT mengatasi SOTA DiT sebelumnya dan kaedah lain dengan skor FID 1.79. MDTv2 meningkatkan lagi prestasi, melonjakkan skor SOTA FID untuk penjanaan imej ke paras terendah baharu 1.58 dengan langkah latihan yang lebih sedikit.
Sama seperti DiT, kami tidak melihat ketepuan skor FID model semasa latihan semasa kami meneruskan latihan. . 256 penanda aras DiT-S/ pada GPU 2 FID prestasi garis dasar, MDT-S/2 dan MDTv2-S/2 di bawah langkah latihan/masa latihan yang berbeza.
Terima kasih kepada keupayaan pembelajaran kontekstual yang lebih baik, MDT mengatasi DiT dalam kedua-dua prestasi dan kelajuan penjanaan. Kelajuan penumpuan latihan MDTv2 adalah lebih daripada 10 kali lebih tinggi daripada DiT. 
 Ringkasan & Perbincangan
Ringkasan & Perbincangan
MDT memperkenalkan skema pembelajaran perwakilan model topeng yang serupa dengan MAE dalam proses latihan resapan, yang boleh menggunakan maklumat kontekstual objek imej untuk membina semula maklumat lengkap imej input yang tidak lengkap, dengan itu belajar semantik dalam imej Kolerasi antara bahagian, dengan itu meningkatkan kualiti penjanaan imej dan kelajuan pembelajaran.
Penyelidik percaya bahawa meningkatkan pemahaman semantik dunia fizikal melalui pembelajaran perwakilan visual boleh meningkatkan kesan simulasi model generatif pada dunia fizikal. Ini bertepatan dengan visi Sora untuk membina simulator dunia fizikal melalui model generatif. Semoga karya ini akan memberi inspirasi kepada lebih banyak kerja untuk menyatukan pembelajaran perwakilan dan pembelajaran generatif.
Rujukan:
https://arxiv.org/abs/2303.14389
Atas ialah kandungan terperinci Karya baharu oleh Yan Shuicheng/Cheng Mingming! Latihan DiT, komponen teras Sora, dipercepatkan sebanyak 10 kali, dan Masked Diffusion Transformer V2 ialah sumber terbuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Jurang kemahiran AI memperlahankan rantaian bekalanApr 26, 2025 am 11:13 AM
Jurang kemahiran AI memperlahankan rantaian bekalanApr 26, 2025 am 11:13 AMIstilah "tenaga kerja siap sedia" sering digunakan, tetapi apakah maksudnya dalam industri rantaian bekalan? Menurut Abe Eshkenazi, Ketua Pegawai Eksekutif Persatuan Pengurusan Rantaian Bekalan (ASCM), ia menandakan profesional yang mampu mengkritik
 Bagaimana satu syarikat secara senyap -senyap bekerja untuk mengubah AI selama -lamanyaApr 26, 2025 am 11:12 AM
Bagaimana satu syarikat secara senyap -senyap bekerja untuk mengubah AI selama -lamanyaApr 26, 2025 am 11:12 AMRevolusi AI yang terdesentralisasi secara senyap -senyap mendapat momentum. Jumaat ini di Austin, Texas, Sidang Kemuncak Endgame Bittensor menandakan momen penting, beralih ke desentralisasi AI (DEAI) dari teori kepada aplikasi praktikal. Tidak seperti iklan mewah
 NVIDIA Melepaskan Microservices Nemo Untuk Menyebarkan Pembangunan Agen AIApr 26, 2025 am 11:11 AM
NVIDIA Melepaskan Microservices Nemo Untuk Menyebarkan Pembangunan Agen AIApr 26, 2025 am 11:11 AMPerusahaan AI menghadapi cabaran integrasi data Penggunaan perusahaan AI menghadapi cabaran utama: sistem bangunan yang dapat mengekalkan ketepatan dan kepraktisan dengan terus belajar data perniagaan. Microservices NEMO menyelesaikan masalah ini dengan mewujudkan apa yang NVIDIA menggambarkan sebagai "Flywheel Data", yang membolehkan sistem AI tetap relevan melalui pendedahan berterusan kepada maklumat perusahaan dan interaksi pengguna. Toolkit yang baru dilancarkan ini mengandungi lima microservices utama: Nemo Customizer mengendalikan penalaan model bahasa yang besar dengan latihan yang lebih tinggi. NEMO Evaluator menyediakan penilaian ringkas model AI untuk tanda aras tersuai. Nemo Guardrails Melaksanakan Kawalan Keselamatan untuk mengekalkan pematuhan dan kesesuaian
 AI melukis gambar baru untuk masa depan seni dan reka bentukApr 26, 2025 am 11:10 AM
AI melukis gambar baru untuk masa depan seni dan reka bentukApr 26, 2025 am 11:10 AMAI: Masa Depan Seni dan Reka Bentuk Kecerdasan Buatan (AI) mengubah bidang seni dan reka bentuk dengan cara yang belum pernah terjadi sebelumnya, dan impaknya tidak lagi terhad kepada amatur, tetapi lebih mempengaruhi profesional. Skim karya seni dan reka bentuk yang dihasilkan oleh AI dengan cepat menggantikan imej dan pereka bahan tradisional dalam banyak aktiviti reka bentuk transaksional seperti pengiklanan, generasi imej media sosial dan reka bentuk web. Walau bagaimanapun, artis dan pereka profesional juga mendapati nilai praktikal AI. Mereka menggunakan AI sebagai alat tambahan untuk meneroka kemungkinan estetik baru, menggabungkan gaya yang berbeza, dan membuat kesan visual baru. AI membantu artis dan pereka mengautomasikan tugas berulang, mencadangkan elemen reka bentuk yang berbeza dan memberikan input kreatif. AI menyokong pemindahan gaya, iaitu menggunakan gaya gambar
 Bagaimana Zoom merevolusikan kerja dengan Agentic AI: Dari mesyuarat ke tonggakApr 26, 2025 am 11:09 AM
Bagaimana Zoom merevolusikan kerja dengan Agentic AI: Dari mesyuarat ke tonggakApr 26, 2025 am 11:09 AMZoom, yang pada mulanya dikenali untuk platform persidangan video, memimpin revolusi tempat kerja dengan penggunaan inovatif AIS AI. Perbualan baru -baru ini dengan CTO Zoom, XD Huang, mendedahkan penglihatan yang bercita -cita tinggi syarikat itu. Menentukan Agentic AI Huang d
 Ancaman eksistensi ke universitiApr 26, 2025 am 11:08 AM
Ancaman eksistensi ke universitiApr 26, 2025 am 11:08 AMAdakah AI akan merevolusikan pendidikan? Soalan ini mendorong refleksi serius di kalangan pendidik dan pihak berkepentingan. Penyepaduan AI ke dalam pendidikan memberikan peluang dan cabaran. Sebagai Matthew Lynch dari Nota Edvocate Tech, Universit
 Prototaip: saintis Amerika mencari pekerjaan di luar negaraApr 26, 2025 am 11:07 AM
Prototaip: saintis Amerika mencari pekerjaan di luar negaraApr 26, 2025 am 11:07 AMPembangunan penyelidikan dan teknologi saintifik di Amerika Syarikat mungkin menghadapi cabaran, mungkin disebabkan oleh pemotongan anggaran. Menurut Alam, bilangan saintis Amerika yang memohon pekerjaan di luar negara meningkat sebanyak 32% dari Januari hingga Mac 2025 berbanding dengan tempoh yang sama pada tahun 2024. Pungutan sebelumnya menunjukkan bahawa 75% penyelidik yang ditinjau sedang mempertimbangkan untuk mencari pekerjaan di Eropah dan Kanada. Beratus-ratus geran NIH dan NSF telah ditamatkan dalam beberapa bulan yang lalu, dengan geran baru NIH turun kira-kira $ 2.3 bilion tahun ini, setitik hampir satu pertiga. Cadangan belanjawan yang bocor menunjukkan bahawa pentadbiran Trump sedang mempertimbangkan untuk memotong belanjawan secara mendadak untuk institusi saintifik, dengan kemungkinan pengurangan sehingga 50%. Kegawatan dalam bidang penyelidikan asas juga telah menjejaskan salah satu kelebihan utama Amerika Syarikat: menarik bakat luar negara. 35
 Semua Mengenai Keluarga GPT 4.1 Terbuka AI - Analytics VidhyaApr 26, 2025 am 10:19 AM
Semua Mengenai Keluarga GPT 4.1 Terbuka AI - Analytics VidhyaApr 26, 2025 am 10:19 AMOpenAI melancarkan siri GPT-4.1 yang kuat: keluarga tiga model bahasa lanjutan yang direka untuk aplikasi dunia nyata. Lompat penting ini menawarkan masa tindak balas yang lebih cepat, pemahaman yang lebih baik, dan kos yang dikurangkan secara drastik berbanding t


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

Pelayar Peperiksaan Selamat
Pelayar Peperiksaan Selamat ialah persekitaran pelayar selamat untuk mengambil peperiksaan dalam talian dengan selamat. Perisian ini menukar mana-mana komputer menjadi stesen kerja yang selamat. Ia mengawal akses kepada mana-mana utiliti dan menghalang pelajar daripada menggunakan sumber yang tidak dibenarkan.

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

Dreamweaver CS6
Alat pembangunan web visual

