
Rumah >Peranti teknologi >AI >Apakah teknologi yang ada pada ByteDance di sebalik 'Sora versi Cina' yang salah faham?
Apakah teknologi yang ada pada ByteDance di sebalik 'Sora versi Cina' yang salah faham?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-03-12 22:55:021210semak imbas
Pada awal tahun 2024, OpenAI telah menurunkan blockbuster dalam bidang AI generatif: Sora.
Dalam beberapa tahun kebelakangan ini, lelaran teknologi dalam bidang penjanaan video terus meningkat, dan banyak syarikat teknologi juga telah mengumumkan kemajuan teknologi dan hasil pelaksanaan yang berkaitan. Sebelum ini, Pika dan Runway telah melancarkan produk yang sama, tetapi demo yang dikeluarkan oleh Sora jelas secara bersendirian meningkatkan standard dalam bidang penjanaan video.
Pada persaingan akan datang, masih tidak diketahui syarikat mana yang akan menjadi yang pertama mencipta produk yang mengatasi Sora.
Di China, perhatian tertumpu pada beberapa pengeluar teknologi utama.
Sebelum ini, dilaporkan bahawa Bytedance telah membangunkan model penjanaan video yang dipanggil Boximator sebelum keluaran Sora.
Boximator menyediakan cara untuk mengawal penjanaan objek dalam video dengan tepat. Daripada menulis arahan teks yang kompleks, pengguna hanya boleh melukis kotak dalam imej rujukan untuk memilih sasaran, dan kemudian menambah kotak dan garisan tambahan untuk menentukan kedudukan akhir sasaran atau keseluruhan laluan gerakan silang bingkai, seperti yang ditunjukkan di bawah:
. Ia masih belum siap sepenuhnya, dan masih terdapat jurang yang besar antaranya dengan model penjanaan video asing terkemuka dari segi kualiti gambar, kesetiaan dan tempoh video. 
Adalah disebutkan dalam kertas teknikal yang berkaitan (https://arxiv.org/abs/2402.01566) bahawa Boximator dijalankan sebagai pemalam dan boleh disepadukan dengan mudah dengan model penjanaan video sedia ada. Dengan menambahkan keupayaan kawalan gerakan, ia bukan sahaja mengekalkan kualiti video tetapi juga meningkatkan fleksibiliti dan kebolehgunaan.
Penjanaan video melibatkan teknologi dalam berbilang subbahagian dan berkait rapat dengan pemahaman imej/video, penjanaan imej, resolusi super dan teknologi lain. Selepas penyelidikan yang mendalam, didapati bahawa ByteDance telah menerbitkan beberapa hasil penyelidikan secara terbuka di beberapa cawangan.
Artikel ini akan memperkenalkan 9 kajian daripada pasukan penciptaan pintar ByteDance, yang melibatkan banyak pencapaian terkini seperti Vincent Picture, Vincent Video, Tush Video dan Video Understanding. Daripada kajian ini, kita mungkin juga menjejaki kemajuan teknologi dalam meneroka model generatif visual.
Mengenai penjanaan video, apakah pencapaian yang dimiliki Byte?
Pada awal Januari tahun ini, ByteDance mengeluarkan model penjanaan video MagicVideo-V2, yang pernah mencetuskan perbincangan hangat dalam komuniti.

- Alamat projek: https://magicvideov2.github.io/
- Inovasi MagicVideo-V2 adalah untuk menyepadukan teks kepada model imej, penjana gerakan video, modul pembenaman imej rujukan dan modul interpolasi bingkai ke dalam akhir Dalam saluran penjanaan video hujung ke hujung. Terima kasih kepada reka bentuk seni bina ini, MagicVideo-V2 boleh mengekalkan prestasi tahap tinggi yang stabil dari segi "estetika", bukan sahaja menghasilkan video resolusi tinggi yang cantik, tetapi juga mempunyai kesetiaan dan kelancaran yang agak baik.
- Secara khusus, para penyelidik mula-mula menggunakan modul T2I untuk mencipta imej 1024×1024 yang merangkumi pemandangan yang diterangkan. Modul I2V kemudian menghidupkan imej statik ini untuk menjana jujukan bingkai 600×600×32, dengan bunyi asas memastikan kesinambungan daripada bingkai awal. Modul V2V mempertingkatkan bingkai ini kepada resolusi 1048×1048 sambil memperhalusi kandungan video. Akhir sekali, modul interpolasi memanjangkan jujukan kepada 94 bingkai, menghasilkan video resolusi 1048×1048, dan video yang dihasilkan mempunyai kualiti estetik yang tinggi dan kelancaran temporal.
Penilaian pengguna berskala besar yang dijalankan oleh penyelidik membuktikan bahawa MagicVideo-V2 lebih popular daripada beberapa kaedah T2V yang terkenal (bar hijau, kelabu dan merah jambu mewakili MagicVideo-V2 masing-masing dinilai sebagai lebih baik, setara atau lebih baik. ) Beza).

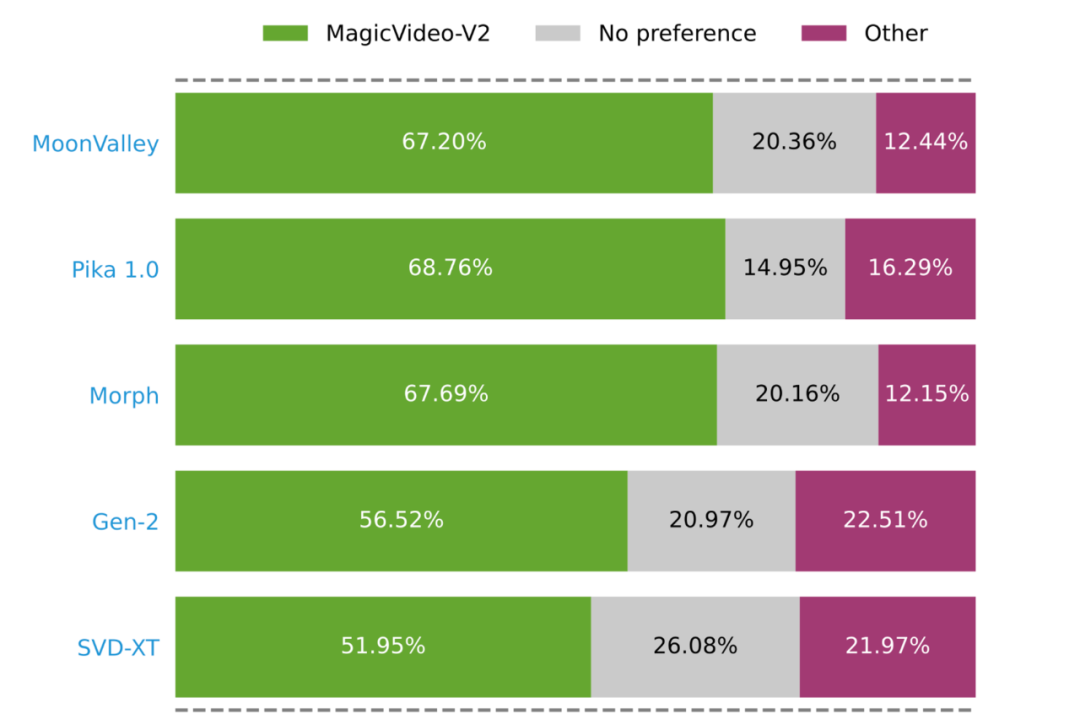
Di sebalik penjanaan video berkualiti tinggi
Paradigma penyelidikan yang menyatukan visi dan pembelajaran bahasa
Daripada teknologi penjanaan video-V2 kita, kita boleh melihat kemajuan teknologi video-V2. . Membuka jalan untuk teknologi AIGC seperti Wenshengtu dan Tushengvideo. Asas untuk menjana kandungan estetik tinggi terletak pada pemahaman, terutamanya peningkatan keupayaan model untuk belajar dan mengintegrasikan modaliti visual dan bahasa.
Dalam beberapa tahun kebelakangan ini, skalabiliti dan keupayaan umum model bahasa yang besar telah menimbulkan paradigma penyelidikan yang menyatukan visi dan pembelajaran bahasa. Untuk merapatkan jurang semula jadi antara dua modaliti "visual" dan "bahasa", penyelidik menyambung perwakilan model bahasa besar yang telah terlatih dan model visual, mengekstrak ciri rentas modal dan menyelesaikan tugas seperti menjawab soalan visual, Tugas seperti kapsyen imej, penaakulan pengetahuan visual dan dialog.
Dalam arah ini, ByteDance juga mempunyai penerokaan yang berkaitan.
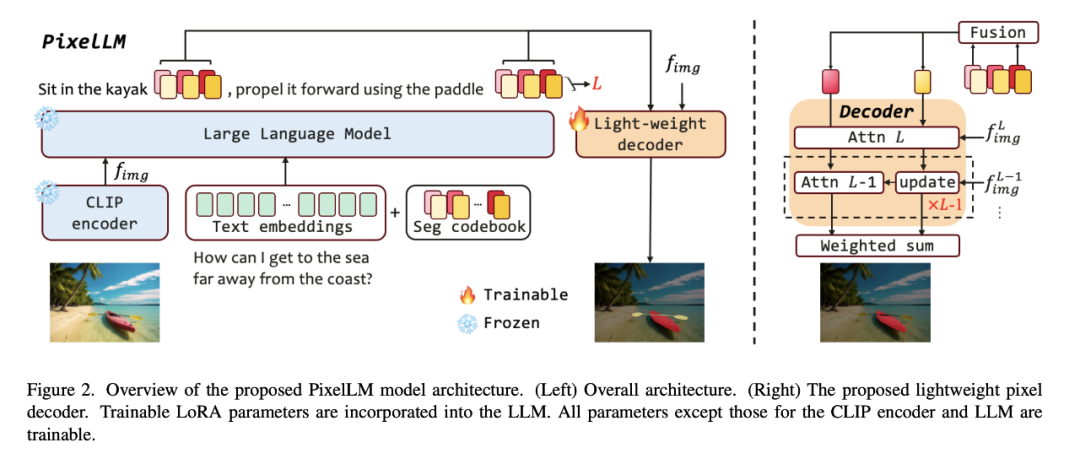
Sebagai contoh, untuk menangani cabaran penaakulan dan segmentasi pelbagai objektif dalam tugas penglihatan dunia terbuka, ByteDance bekerjasama dengan penyelidik dari Universiti Jiaotong Beijing dan Universiti Sains dan Teknologi Beijing untuk mencadangkan piksel berskala besar yang cekap- model penaakulan tahap, PixelLM, dan menjadikannya sumber terbuka. .

- PixelLM boleh mengendalikan tugas dengan mahir dengan sebarang bilangan objektif yang ditetapkan terbuka dan kerumitan penaakulan yang berbeza Rajah di bawah menunjukkan PixelLM dalam pelbagai tugasan segmentasi Keupayaan untuk menjana topeng sasaran berkualiti tinggi.
- Inti PixelLM ialah penyahkod piksel baru dan buku kod segmentasi: buku kod mengandungi token yang boleh dipelajari yang mengekod konteks dan pengetahuan yang berkaitan dengan rujukan sasaran pada skala visual yang berbeza, dan penyahkod piksel adalah berdasarkan pembenaman Tersembunyi token buku kod dan ciri imej menjana topeng sasaran. Sambil mengekalkan struktur asas LMM, PixelLM boleh menjana topeng berkualiti tinggi tanpa model pembahagian visual tambahan yang mahal, sekali gus meningkatkan kecekapan dan kebolehpindahan kepada aplikasi yang berbeza.
- Perlu diambil perhatian bahawa penyelidik membina set data segmentasi inferens pelbagai objektif yang komprehensif MUSE. Mereka memilih sejumlah 910k topeng segmentasi contoh berkualiti tinggi dan huraian teks terperinci berdasarkan kandungan imej daripada set data LVIS, dan menggunakan ini untuk membina 246k pasangan jawapan soalan.
Berbanding imej, jika kandungan video terlibat, cabaran yang dihadapi oleh model semakin meningkat. Kerana video bukan sahaja mengandungi maklumat visual yang kaya dan pelbagai, tetapi juga melibatkan perubahan dinamik dalam siri masa.
Apabila model berbilang modal besar sedia ada memproses kandungan video, mereka biasanya menukar bingkai video kepada satu siri token visual dan menggabungkannya dengan token bahasa untuk menghasilkan teks. Walau bagaimanapun, apabila panjang teks yang dijana meningkat, pengaruh kandungan video akan beransur-ansur lemah, menyebabkan teks yang dijana semakin jauh menyimpang daripada kandungan video asal, menghasilkan apa yang dipanggil "ilusi." 
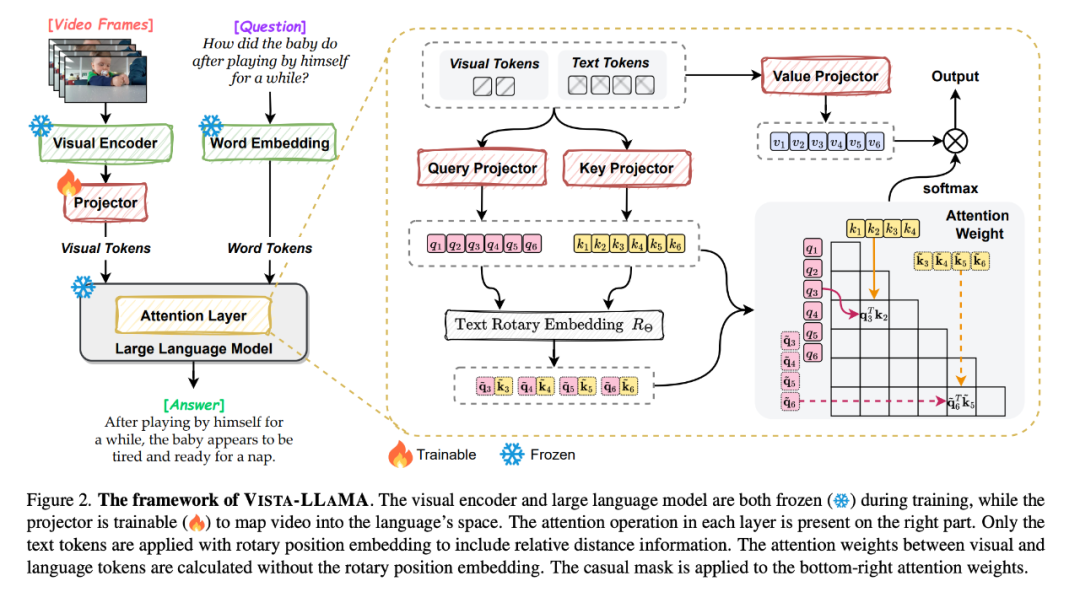
Menghadapi masalah ini, ByteDance dan Universiti Zhejiang mencadangkan Vista-LLaMA, model besar berbilang modal yang direka khusus untuk kerumitan kandungan video.
- Tajuk kertas: Vista-LLaMA: Narator Video Boleh Dipercayai melalui Jarak Yang Sama dengan Token Visual
- Alamat kertas: https://arxiv.org/pdf/2312.08870.pdf
- :https://jinxxian.github.io/Vista-LLaMA/
Vista-LLaMA mengguna pakai mekanisme perhatian yang lebih baik - Visual Equidistant Token Attention (EDVT) untuk memproses penglihatan dan teks Token membuang pengekodan kedudukan relatif tradisional sementara mengekalkan pengekodan kedudukan relatif antara teks. Kaedah ini meningkatkan kedalaman dan ketepatan pemahaman model bahasa tentang kandungan video.
Khususnya, projektor visual bersiri yang diperkenalkan oleh Vista-LLaMA menyediakan perspektif baharu untuk masalah analisis siri masa dalam video Ia mengekod konteks temporal token visual melalui lapisan unjuran linear, meningkatkan tindak balas model terhadap perubahan dinamik dalam. kebolehan memahami video tersebut.
Dalam kajian yang diterima baru-baru ini oleh ICLR 2024, penyelidik ByteDance turut meneroka kaedah pra-latihan untuk meningkatkan keupayaan model untuk mempelajari kandungan video.
Disebabkan skala dan kualiti korpus latihan teks video yang terhad, kebanyakan model asas bahasa visual menggunakan set data teks imej untuk pra-latihan dan terutamanya menumpukan pada pemodelan perwakilan semantik visual, sambil mengabaikan perwakilan semantik temporal dan jantina korelasi.
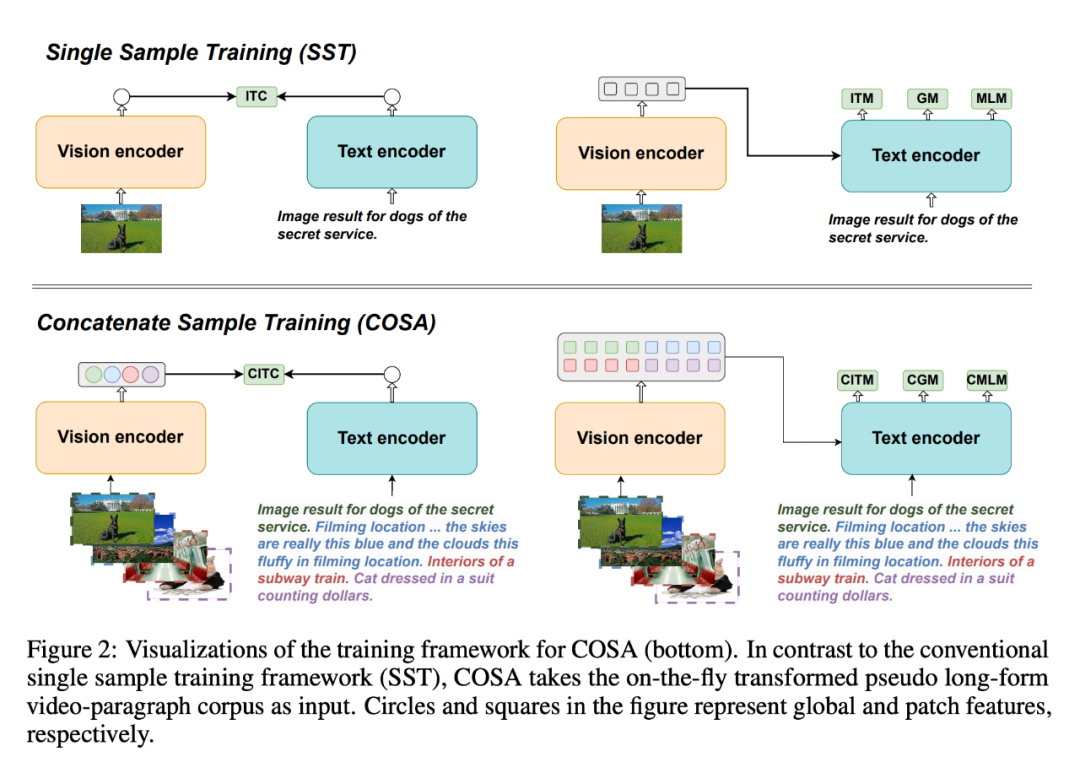
Untuk menyelesaikan masalah ini, mereka mencadangkan COSA, sampel model asas bahasa visual pra-latihan yang digabungkan.

- paper Tajuk: COSA: Model Model Yayasan Vision-Language Sample Pretrained Pautan: https://arxiv.org/pdf/2306.09085.pdf
- Laman utama projek: https://github.com/TXH-mercury/COSA
- COSA bersama-sama memodelkan kandungan visual dan isyarat temporal peringkat acara menggunakan hanya korpora teks imej. Para penyelidik menggabungkan beberapa pasangan teks imej dalam urutan sebagai input untuk pra-latihan. Transformasi ini secara berkesan menukarkan korpus teks imej sedia ada kepada korpus perenggan video berbentuk pseudo-panjang, membolehkan peralihan pemandangan yang lebih kaya dan surat-menyurat perihalan peristiwa yang jelas. Percubaan menunjukkan bahawa COSA boleh meningkatkan prestasi secara konsisten pada pelbagai tugasan hiliran, termasuk tugasan teks video panjang/pendek dan tugasan teks imej (seperti mendapatkan semula, sari kata dan menjawab soalan).
 Dari imej ke video
Dari imej ke video
Selain itu, model difusi visual juga digunakan oleh kebanyakan model video. model generasi.
Melalui latihan ketat mengenai set data berpasangan imej-teks yang besar, model resapan dapat menjana imej terperinci berdasarkan sepenuhnya maklumat teks. Selain penjanaan imej, model resapan juga boleh digunakan untuk penjanaan audio, penjanaan siri masa, penjanaan awan titik 3D dan banyak lagi.
Sebagai contoh, dalam beberapa aplikasi video pendek, pengguna hanya perlu menyediakan gambar untuk menghasilkan video aksi palsu.
Mona Lisa, yang telah mengekalkan senyuman misteri selama ratusan tahun, boleh mula berlari serta-merta:
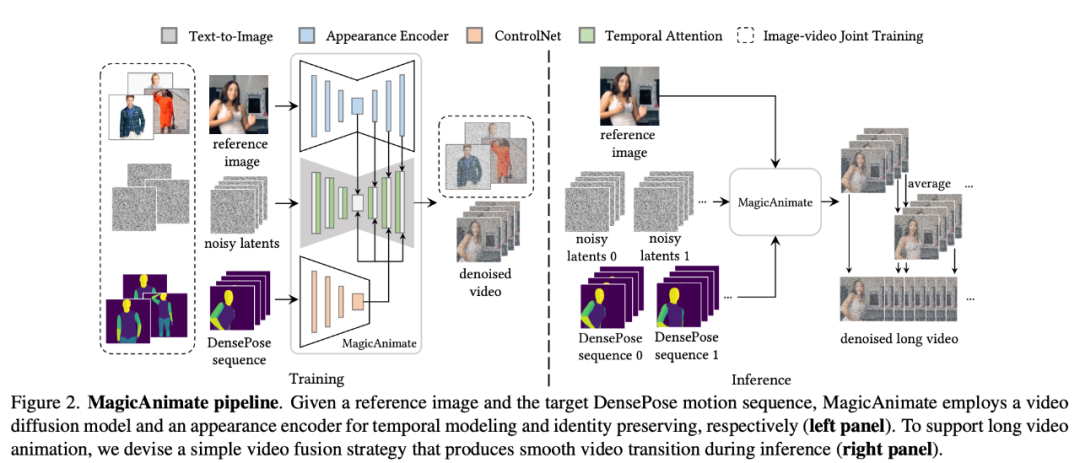
Teknologi di sebalik aplikasi menarik ini adalah usaha bersama antara penyelidik dari Universiti Nasional Singapura dan ByteDance "MagicAnimate" dilancarkan.
MagicAnimate ialah rangka kerja animasi imej manusia berasaskan resapan yang boleh memastikan ketekalan temporal keseluruhan animasi dan meningkatkan kesetiaan animasi dalam tugas menjana video berdasarkan urutan gerakan tertentu. Selain itu, projek MagicAnimate adalah sumber terbuka.

- Tajuk kertas: MagicAnimate: Animasi Imej Manusia Konsisten Sementara menggunakan Model Difusi
- Pautan kertas: https://arxiv.org.pdf
- Alamat projek: https://showlab.github.io/magicanimate/
MagicAnimate menguraikan keseluruhan video ke dalam segmen bertindih dan hanya purata ramalan bingkai bertindih. Akhir sekali, penyelidik juga memperkenalkan strategi latihan bersama imej-video untuk meningkatkan lagi keupayaan pengekalan imej rujukan dan kesetiaan bingkai tunggal. Walaupun dilatih hanya pada data manusia sebenar, MagicAnimate telah menunjukkan keupayaan untuk membuat generalisasi kepada pelbagai senario aplikasi, termasuk animasi data domain yang tidak kelihatan, penyepaduan dengan model penyebaran imej teks dan animasi berbilang orang.
 Alamat projek: https://dreamtalkemo.github.io/
Alamat projek: https://dreamtalkemo.github.io/
- Kita tahu bahawa dalam tugas ini, sukar untuk mencapai dialog emosi yang ekspresif secara serentak penyegerakan, biasanya untuk memastikan ketepatan penyegerakan bibir, ekspresi sering dikurangkan. "DREAM-Talk" ialah rangka kerja dipacu audio berasaskan resapan, dibahagikan kepada dua peringkat: Pertama, penyelidik mencadangkan modul penyebaran novel EmoDiff, yang boleh menjana pelbagai corak yang sangat dinamik berdasarkan audio dan rujukan emosi gaya ekspresi emosi dan postur kepala. Memandangkan korelasi yang kukuh antara pergerakan bibir dan audio, para penyelidik kemudiannya menambah baik dinamik menggunakan ciri audio dan gaya emosi untuk meningkatkan ketepatan penyegerakan bibir, dan juga menggunakan modul pemaparan video-ke-video untuk mencapai Pindahkan ekspresi dan pergerakan bibir ke mana-mana potret.
- Dari sudut kesan, DREAM-Talk memang bagus dari segi ekspresif, ketepatan penyegerakan bibir dan kualiti yang dilihat:
- Tetapi sama ada penjanaan imej atau penjanaan video semasa laluan berdasarkan Penyelidikan masih mempunyai beberapa cabaran asas yang perlu ditangani.
Sebagai contoh, ramai orang mengambil berat tentang kualiti kandungan yang dihasilkan (sepadan dengan SAG, DREAM-Talk Ini mungkin berkaitan dengan beberapa langkah dalam proses penjanaan model resapan, seperti pensampelan berpandu).
Pensampelan berpandu dalam model resapan boleh dibahagikan secara kasar kepada dua kategori: yang memerlukan latihan dan yang tidak memerlukan latihan. Persampelan berpandu tanpa latihan menggunakan rangkaian pra-latihan sedia dibuat (seperti model penilaian estetik) untuk membimbing proses penjanaan, bertujuan untuk mendapatkan pengetahuan daripada model pra-latihan dengan langkah yang lebih sedikit dan ketepatan yang lebih tinggi. Algoritma persampelan tanpa panduan latihan semasa adalah berdasarkan anggaran satu langkah imej bersih untuk mendapatkan fungsi tenaga bimbingan. Walau bagaimanapun, memandangkan rangkaian pra-latihan dilatih pada imej bersih, proses anggaran satu langkah untuk imej bersih mungkin tidak tepat, terutamanya pada peringkat awal model resapan, mengakibatkan panduan tidak tepat pada langkah masa awal.
Sebagai tindak balas kepada masalah ini, penyelidik dari ByteDance dan Universiti Nasional Singapura bersama-sama mencadangkan Symplectic Adjoint Guidance (SAG). .
 SAG Panduan kecerunan dikira melalui dua peringkat dalaman: Pertama, SAG menganggarkan imej bersih melalui n panggilan fungsi, di mana n berfungsi sebagai parameter fleksibel yang boleh dilaraskan mengikut keperluan kualiti imej tertentu. Kedua, SAG menggunakan kaedah dwi simetri untuk mendapatkan kecerunan berkenaan dengan keperluan memori dengan tepat dan cekap. Pendekatan ini boleh menyokong pelbagai tugas penjanaan imej dan video, termasuk penjanaan imej berpandukan gaya, peningkatan estetik dan penggayaan video serta meningkatkan kualiti kandungan yang dijana dengan berkesan.
SAG Panduan kecerunan dikira melalui dua peringkat dalaman: Pertama, SAG menganggarkan imej bersih melalui n panggilan fungsi, di mana n berfungsi sebagai parameter fleksibel yang boleh dilaraskan mengikut keperluan kualiti imej tertentu. Kedua, SAG menggunakan kaedah dwi simetri untuk mendapatkan kecerunan berkenaan dengan keperluan memori dengan tepat dan cekap. Pendekatan ini boleh menyokong pelbagai tugas penjanaan imej dan video, termasuk penjanaan imej berpandukan gaya, peningkatan estetik dan penggayaan video serta meningkatkan kualiti kandungan yang dijana dengan berkesan.
- Sebuah kertas yang dipilih baru-baru ini untuk ICLR 2024 memfokuskan pada "kaedah sensitiviti kritikal perambatan belakang kecerunan model kebarangkalian resapan".
Tajuk kertas: Kaedah Sensitiviti Bersebelahan untuk Rambatan Balik Kecerunan Model Probabilistik Difusi
07 11.pdf
- Memandangkan proses pensampelan model kebarangkalian resapan melibatkan panggilan rekursif ke U-Net yang merendahkan, perambatan balik kecerunan naif perlu menyimpan keadaan perantaraan semua lelaran, menghasilkan penggunaan memori yang sangat tinggi.
- Dalam kertas ini, AdjointDPM yang dicadangkan oleh penyelidik mula-mula menjana sampel baharu daripada model resapan dengan menyelesaikan ODE aliran kebarangkalian yang sepadan. Kemudian, kecerunan kehilangan dalam parameter model (termasuk isyarat penyaman udara, berat rangkaian dan hingar awal) dirambat balik menggunakan kaedah kepekaan bersebelahan dengan menyelesaikan ODE tambahan yang lain. Untuk mengurangkan ralat berangka semasa penjanaan ke hadapan dan perambatan belakang kecerunan, para penyelidik menyelaraskan semula aliran kebarangkalian ODE dan mempertingkatkan ODE kepada ODE tidak tegar mudah menggunakan penyepaduan eksponen.
- Para penyelidik menegaskan bahawa AdjointDPM sangat berharga dalam tiga tugas: menukar kesan visual kepada pembenaman teks yang diiktiraf, model probabilistik resapan penalaan halus untuk jenis penggayaan tertentu dan mengoptimumkan hingar awal untuk menjana bagi audit keselamatan contoh musuh untuk mengurangkan kos kerja pengoptimuman. Untuk tugasan persepsi visual, kaedah menggunakan model resapan teks ke imej sebagai pengekstrak ciri juga semakin mendapat perhatian. Ke arah ini, penyelidik ByteDance mencadangkan penyelesaian yang mudah dan berkesan dalam kertas kerja mereka.
Tajuk kertas; Memanfaatkan Model Penyebaran untuk Persepsi Visual dengan Meta Prompt
Pautan kertas: https://arxiv.org.pdf
Ini Inovasi teras kertas ini ialah pengenalan pembenaman boleh dipelajari (meta-kiu) dalam model resapan terlatih untuk mengekstrak ciri persepsi, tanpa bergantung pada model berbilang modal tambahan untuk menjana kapsyen imej, mahupun menggunakan label kategori dalam set data. 
- Meta-cues mempunyai dua tujuan: pertama, sebagai pengganti langsung untuk pembenaman teks dalam model T2I, ia boleh mengaktifkan ciri berkaitan tugas semasa pengekstrakan ciri kedua, ia akan digunakan untuk menyusun semula ciri yang diekstrak, untuk memastikan bahawa model memfokuskan pada ciri yang paling relevan dengan tugasan yang sedang dijalankan. Selain itu, penyelidik juga mereka bentuk strategi latihan penghalusan kitaran untuk menggunakan sepenuhnya ciri-ciri model resapan untuk mendapatkan ciri visual yang lebih kukuh. Berapa jauh lagi sebelum "Sora versi Cina" dilahirkan
- ?
Tetapi jika dibandingkan dengan Sora, sama ada ByteDance atau beberapa syarikat bintang dalam bidang penjanaan video AI, terdapat jurang yang boleh dilihat dengan mata kasar. Kelebihan Sora adalah berdasarkan kepercayaannya terhadap Undang-undang Skala dan inovasi teknologi terobosan: menyatukan data video melalui tampalan, bergantung pada seni bina teknikal seperti Diffusion Transformer dan keupayaan pemahaman semantik DALL・E 3, ia telah benar-benar mencapai "jauh ke hadapan". Dari letupan Wenshengtu pada tahun 2022 hingga kemunculan Sora pada tahun 2024, kelajuan lelaran teknologi dalam bidang kecerdasan buatan telah melebihi imaginasi semua orang. Pada tahun 2024, saya percaya akan ada lebih banyak "produk hangat" dalam bidang ini. Byte jelas juga meningkatkan pelaburan dalam penyelidikan dan pembangunan teknologi. Baru-baru ini, ketua projek Google VideoPoet Jiang Lu, dan Chunyuan Li, ahli pasukan LLaVA model besar berbilang mod sumber terbuka dan bekas ketua penyelidik Microsoft Research, semuanya telah didedahkan telah menyertai pasukan penciptaan pintar ByteDance. Pasukan ini juga sedang giat merekrut, dan beberapa jawatan yang berkaitan dengan algoritma model besar telah disiarkan di laman web rasmi. Bukan sahaja Byte, syarikat gergasi lama seperti BAT juga telah mengeluarkan banyak hasil penyelidikan penjanaan video yang menarik perhatian, dan beberapa syarikat permulaan model besar lebih agresif. Apakah penemuan baharu yang akan dibuat dalam Teknologi Video Vincent? Kita akan lihat.
Atas ialah kandungan terperinci Apakah teknologi yang ada pada ByteDance di sebalik 'Sora versi Cina' yang salah faham?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!