
Rumah >Peranti teknologi >AI >OpenAI secara rasmi mengumumkan Transformer Debugger sumber terbuka! Tidak perlu menulis kod, semua orang boleh memecahkan kotak hitam LLM
OpenAI secara rasmi mengumumkan Transformer Debugger sumber terbuka! Tidak perlu menulis kod, semua orang boleh memecahkan kotak hitam LLM

- PHPzke hadapan
- 2024-03-12 15:16:191251semak imbas
AGI memang semakin hampir!
Untuk memastikan manusia tidak dibunuh oleh AI, OpenAI tidak pernah berhenti dalam menyahsulit rangkaian neural/kotak hitam Transfomer.
Pada Mei tahun lalu, pasukan OpenAI mengeluarkan penemuan yang mengejutkan: GPT-4 sebenarnya boleh menerangkan 300,000 neuron GPT-2!
Seru netizen bahawa hikmahnya menjadi seperti ini.
 Pictures
Pictures
Sebentar tadi, ketua pasukan penjajaran super OpenAI secara rasmi mengumumkan bahawa mereka akan membuka sumber Transformer Debugger, alat pembunuh yang telah digunakan secara dalaman.
Ringkasnya, penyelidik boleh menggunakan alat TDB untuk menganalisis struktur dalaman Transformer untuk menyiasat tingkah laku khusus model kecil.
 Gambar
Gambar
Dalam erti kata lain, dengan alat TDB ini, ia boleh membantu kami menganalisis dan menganalisis AGI pada masa hadapan!
 Pictures
Pictures
Penyahpepijat Transformer menggabungkan pengekod automatik yang jarang dengan "kebolehtafsiran automatik" yang dibangunkan oleh OpenAI - iaitu, menggunakan model besar untuk menerangkan model kecil, teknologi secara automatik.
Pautan: OpenAI meletupkan kerja baharu: GPT-4 memecahkan otak GPT-2! Kesemua 300,000 neuron telah dilihat
 Gambar
Gambar
Alamat kertas: https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html#sec
Perlu dinyatakan bahawa penyelidik boleh meneroka struktur dalaman LLM dengan cepat tanpa menulis kod.
Sebagai contoh, ia boleh menjawab soalan seperti "Mengapa model mengeluarkan token A dan bukannya token B", "Mengapa ketua perhatian H memberi tumpuan kepada token T".
 Gambar
Gambar
Oleh kerana TDB boleh menyokong neuron dan kepala perhatian, ia membolehkan penyelidik campur tangan dalam penghantaran ke hadapan dengan mengecilkan neuron individu dan memerhati perubahan khusus yang berlaku.
Namun, menurut Jan Leike, alat ini masih merupakan versi awal OpenAI mengeluarkannya dengan harapan lebih ramai penyelidik dapat menggunakannya dan menambah baik lagi atas dasar sedia ada. . 2023 Kajian berkaitan penjajaran telah dikeluarkan pada bulan Mei.
 Alat TDB adalah berdasarkan dua kajian yang diterbitkan sebelum ini dan tidak akan menerbitkan kertas
Alat TDB adalah berdasarkan dua kajian yang diterbitkan sebelum ini dan tidak akan menerbitkan kertas
Ringkasnya, OpenAI berharap untuk menggunakan model (GPT-4) dengan parameter yang lebih besar dan keupayaan kecil yang lebih kukuh untuk menganalisis secara automatik Kelakuan model (GPT-2), menerangkan cara ia beroperasi.
Gambar
Hasil awal penyelidikan OpenAI pada masa itu ialah model dengan parameter yang agak sedikit mudah difahami, tetapi apabila parameter model menjadi lebih besar dan bilangan lapisan meningkat, kesan penjelasan akan menjunam.

 Pictures
Pictures
Pada masa itu, OpenAI menyatakan dalam penyelidikannya bahawa GPT-4 sendiri tidak direka untuk menerangkan tingkah laku model kecil, jadi penjelasan keseluruhan GPT-2 masih sangat lemah.
 Gambar
Gambar
Algoritma dan alatan yang boleh menerangkan tingkah laku model dengan lebih baik perlu dibangunkan pada masa hadapan.
Transformer Debugger sumber terbuka kini ialah pencapaian berperingkat OpenAI pada tahun berikutnya.
Dan "alat yang lebih baik" ini - Penyahpepijat Transformer, menggabungkan "pengekod auto jarang" ke dalam barisan teknikal "menggunakan model besar untuk menerangkan model kecil".
Kemudian proses OpenAI sebelumnya menggunakan GPT-4 untuk menerangkan model kecil dalam penyelidikan kebolehtafsiran adalah berkod sifar, sekali gus mengurangkan ambang untuk penyelidik bermula.
GPT-2 Small telah dilihat melalui
Di halaman utama projek GitHub, ahli pasukan OpenAI memperkenalkan alat penyahpepijat Transformer terkini melalui video.
Sama seperti penyahpepijat Python, TDB membolehkan anda melangkah melalui output model bahasa, menjejaki pengaktifan penting dan menganalisis pengaktifan huluan.
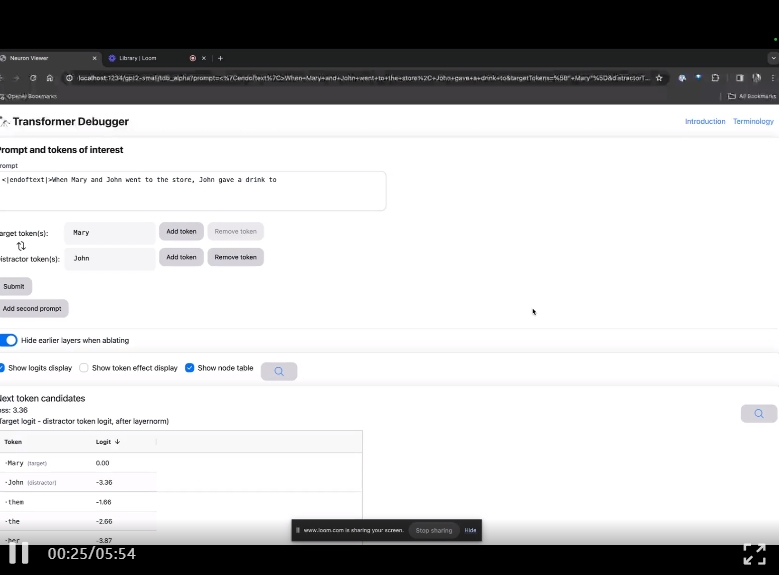
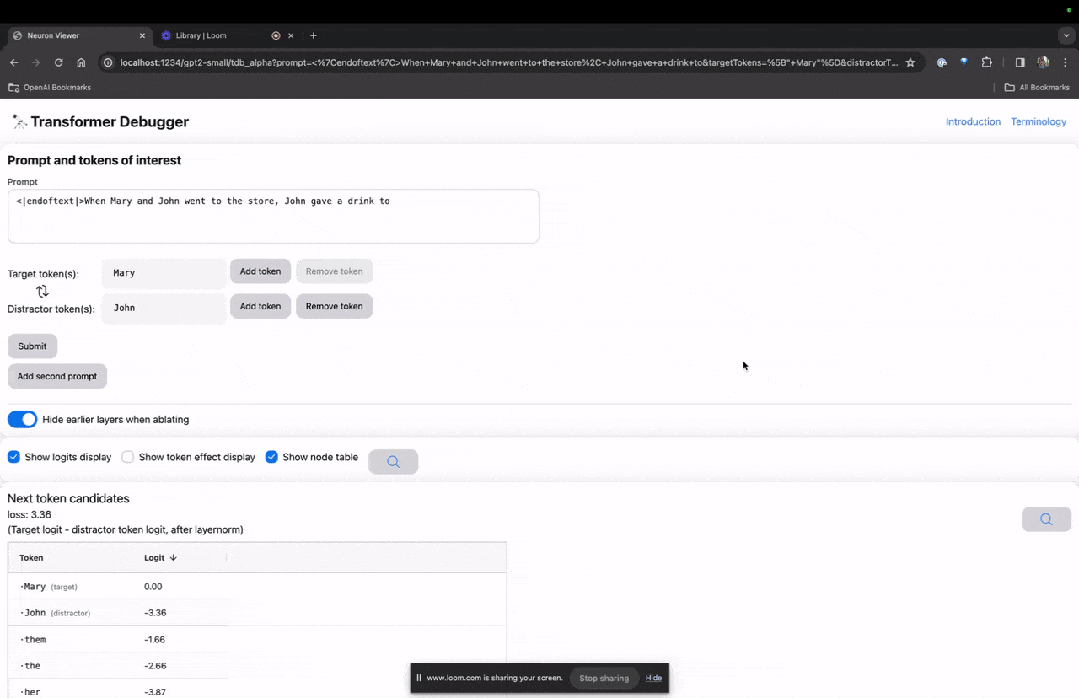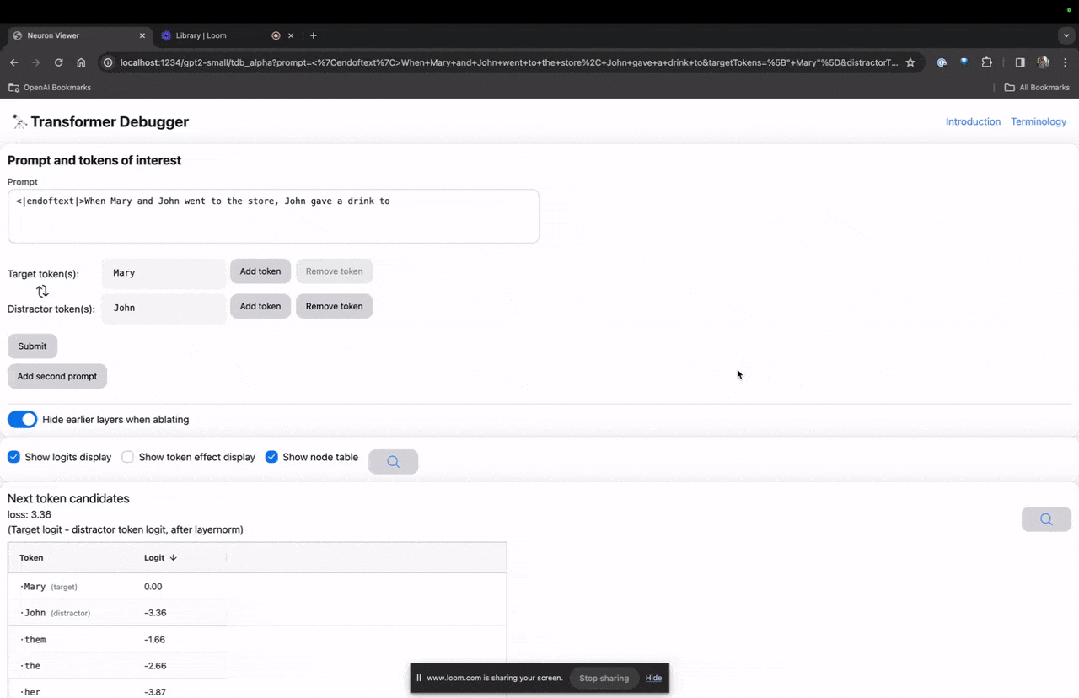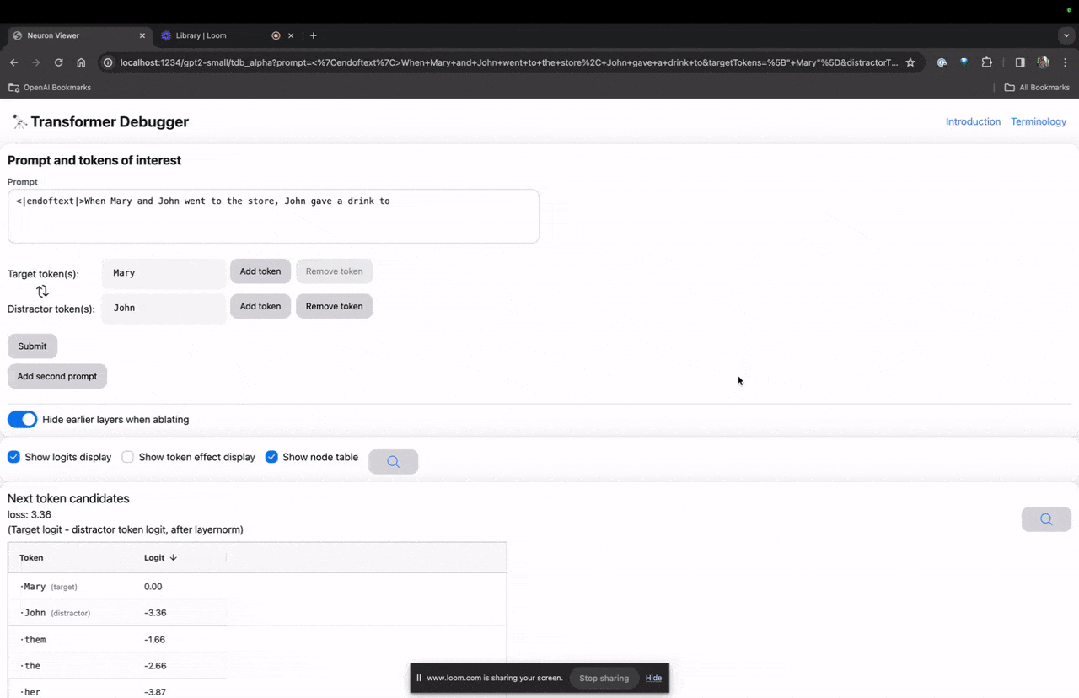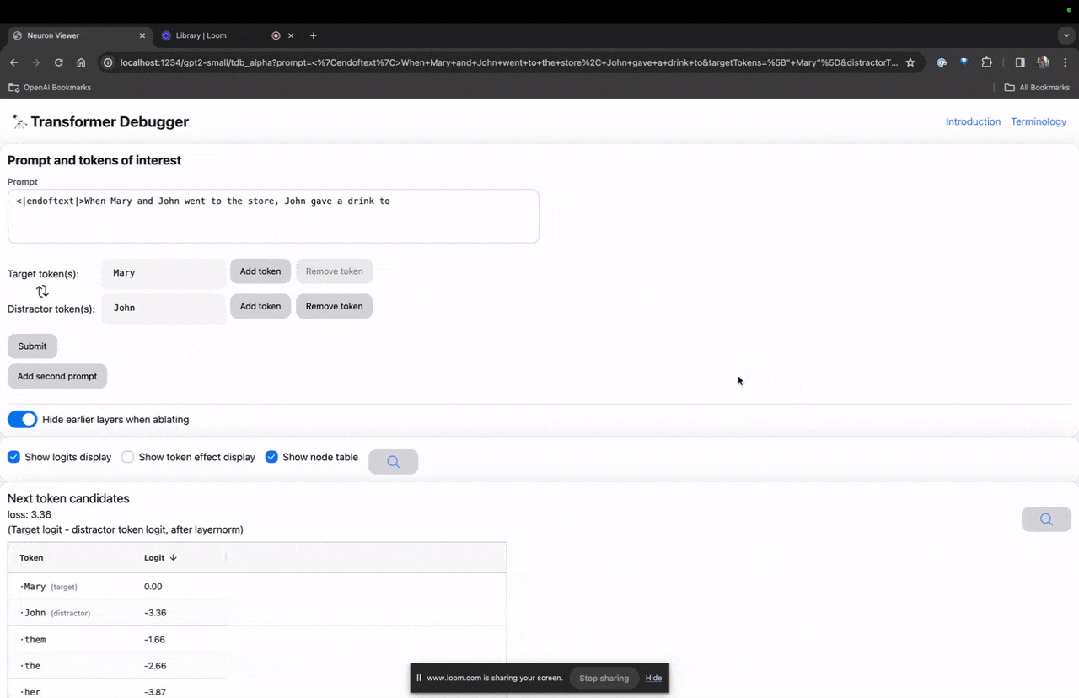
Masuk laman utama TDB, mula-mula masukkan ruangan "Prompt" - gesaan dan tanda minat:
Mary dan Johon ke kedai, Johon memberi minuman kepada....
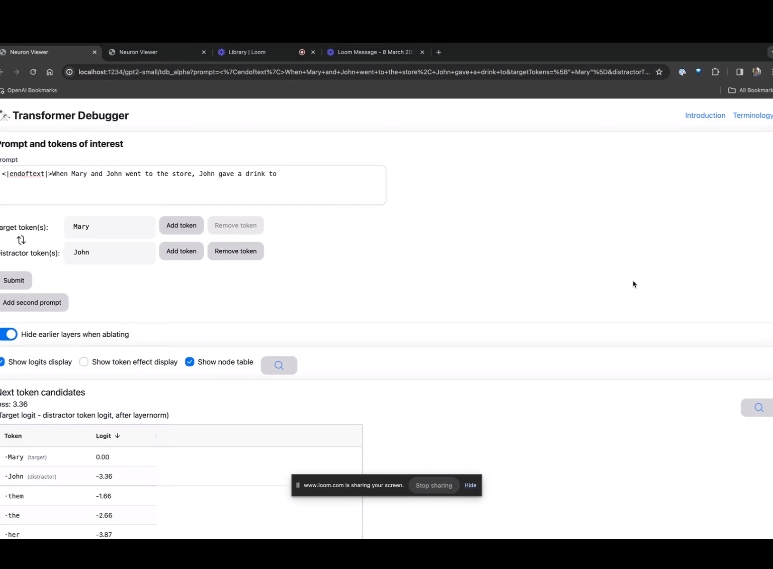
Langkah seterusnya ialah membuat ramalan "perkataan seterusnya", yang memerlukan memasukkan token sasaran dan token yang mengganggu.
Selepas penyerahan akhir, anda boleh melihat logaritma ramalan calon perkataan seterusnya yang diberikan oleh sistem.
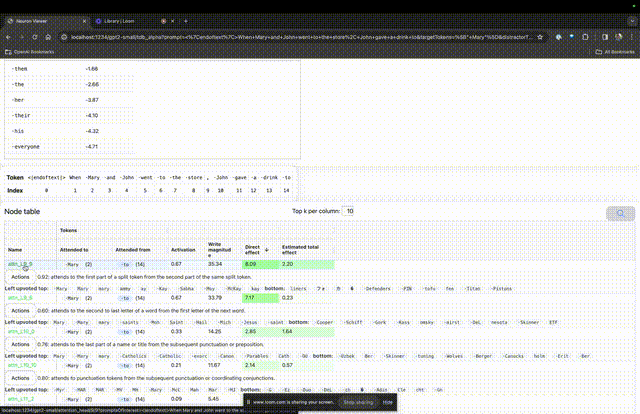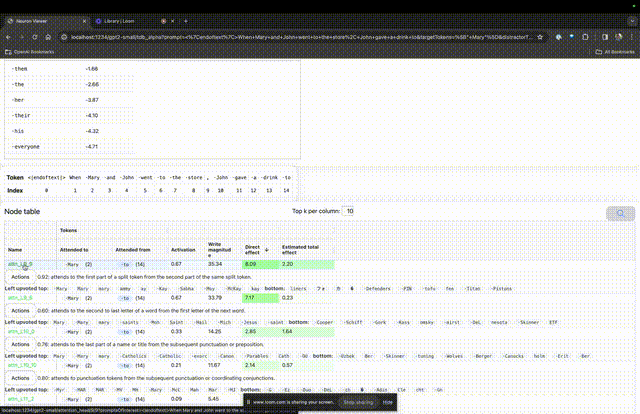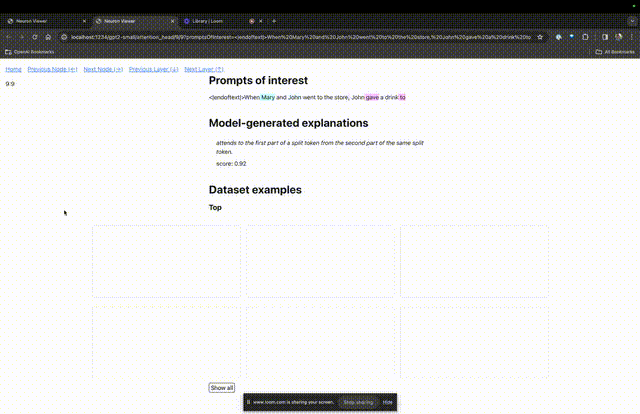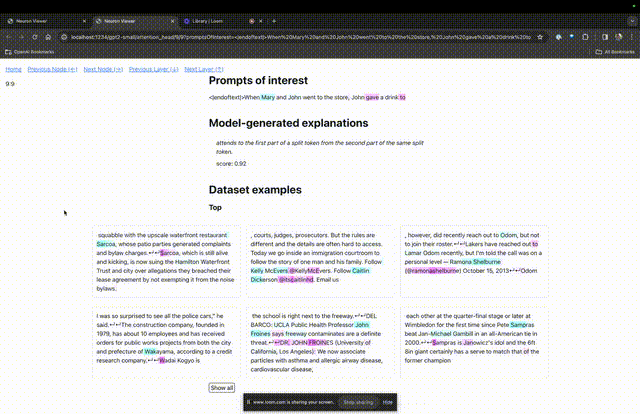
 "Jadual nod" di bawah adalah bahagian teras TDB. Setiap baris di sini sepadan dengan nod, yang mengaktifkan komponen model.
"Jadual nod" di bawah adalah bahagian teras TDB. Setiap baris di sini sepadan dengan nod, yang mengaktifkan komponen model.
Gambar
Jika anda ingin mengetahui fungsi kepala perhatian yang sangat penting untuk gesaan tertentu, klik sahaja pada nama komponen.
 Kemudian TDB akan membuka halaman "Pelayar Neuron", dan perkataan gesaan sebelumnya akan dipaparkan di bahagian atas.
Kemudian TDB akan membuka halaman "Pelayar Neuron", dan perkataan gesaan sebelumnya akan dipaparkan di bahagian atas.
Gambar
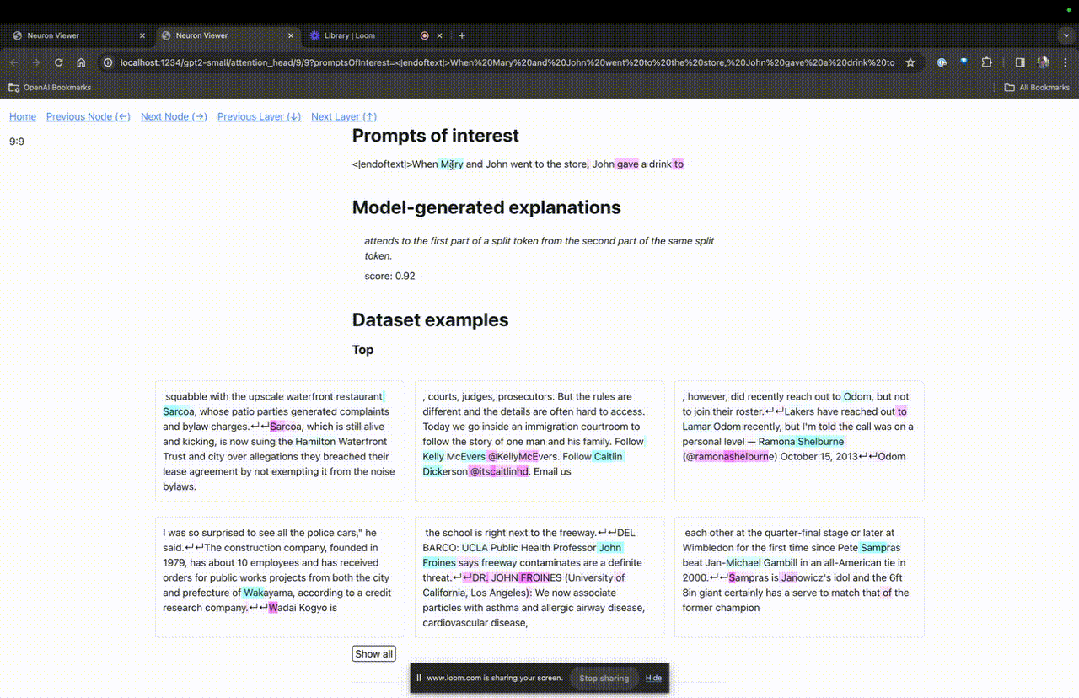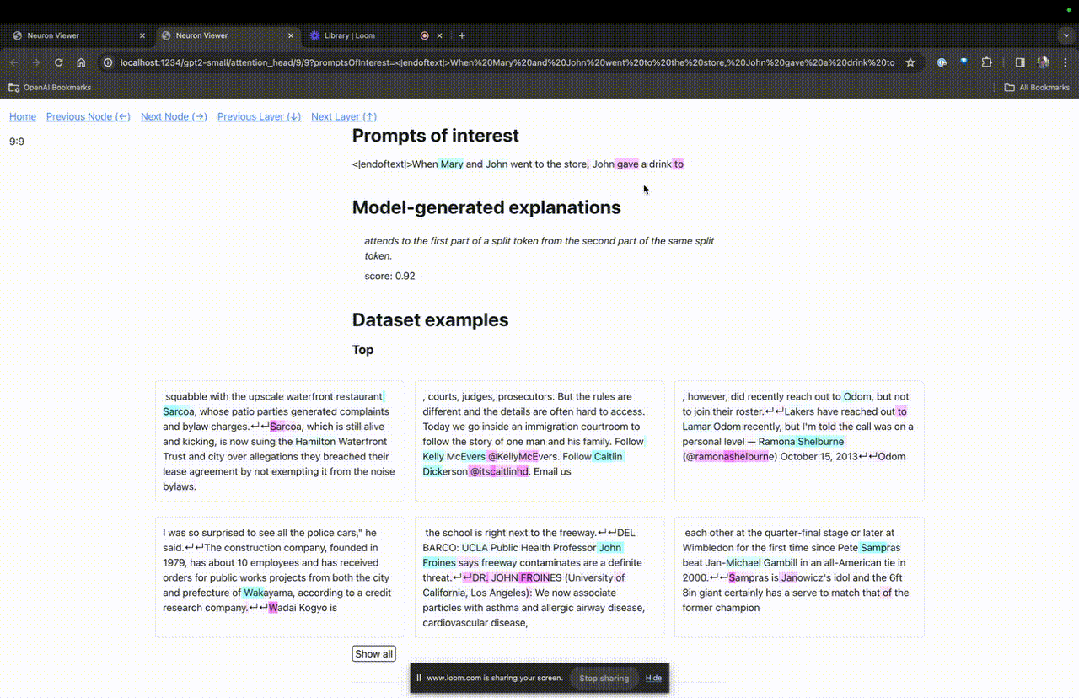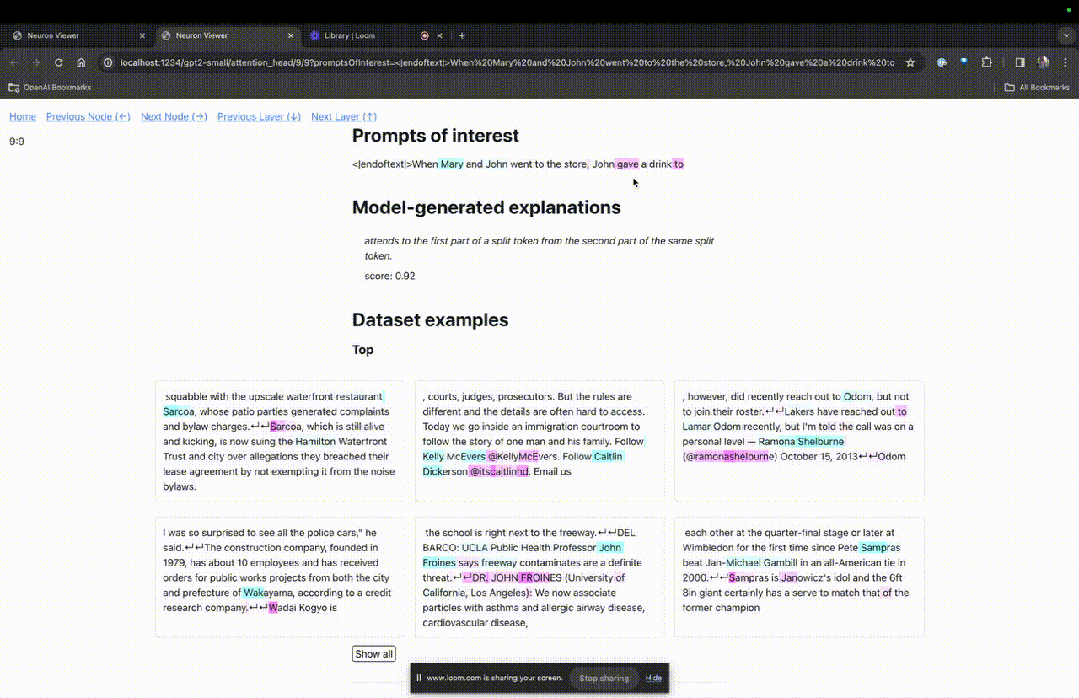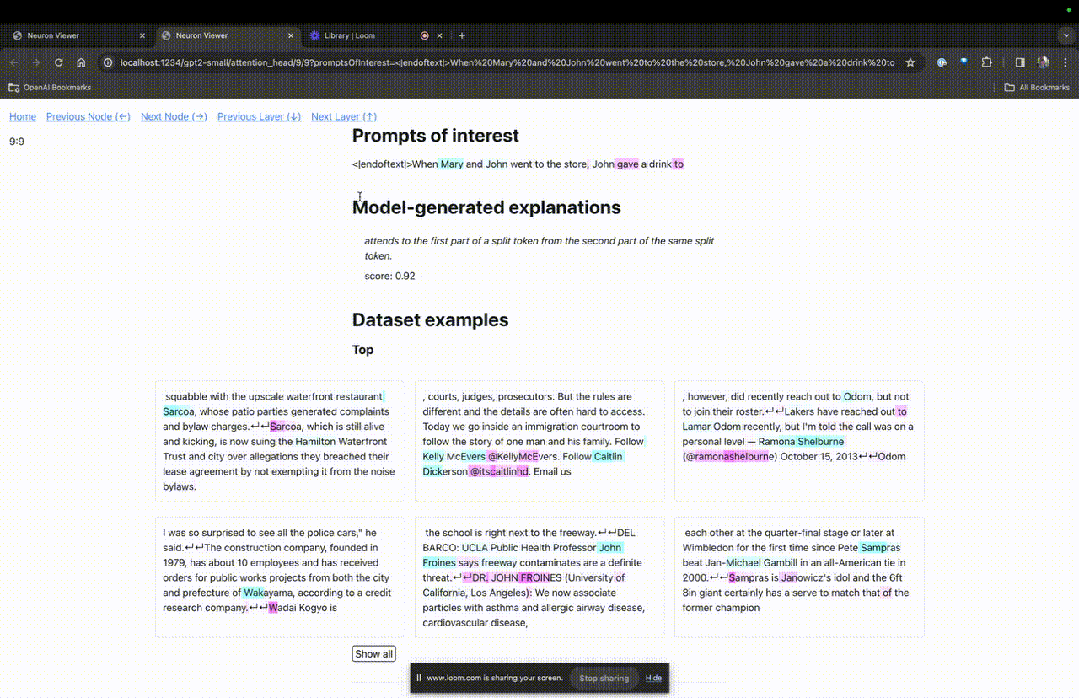 Anda boleh melihat token biru muda dan merah jambu di sini. Di bawah setiap token warna yang sepadan, perhatian daripada teg seterusnya kepada token ini akan menyebabkan vektor norma besar ditulis pada token berikutnya.
Anda boleh melihat token biru muda dan merah jambu di sini. Di bawah setiap token warna yang sepadan, perhatian daripada teg seterusnya kepada token ini akan menyebabkan vektor norma besar ditulis pada token berikutnya.
Gambar
 Dalam dua video lain, penyelidik memperkenalkan konsep TDB, dan aplikasinya dalam memahami gelung. Pada masa yang sama, beliau juga menunjukkan bagaimana TDB boleh menghasilkan semula secara kualitatif salah satu penemuan dalam kertas itu.
Dalam dua video lain, penyelidik memperkenalkan konsep TDB, dan aplikasinya dalam memahami gelung. Pada masa yang sama, beliau juga menunjukkan bagaimana TDB boleh menghasilkan semula secara kualitatif salah satu penemuan dalam kertas itu.
Penyelidikan Kebolehtafsiran Automatik OpenAI
Ringkasnya, idea Penyelidikan Kebolehtafsiran Automatik OpenAI adalah untuk membenarkan GPT-4 mentafsirkan tingkah laku GPT dan kemudiannya menggunakan bahasa semula jadi ini. -2.
🎜🎜Bagaimana ini boleh berlaku? Pertama, kita perlu "membedah" LLM. 🎜🎜Seperti otak, ia terdiri daripada "neuron" yang memerhati corak tertentu dalam teks, yang menentukan apa yang keseluruhan model akan katakan seterusnya.
Sebagai contoh, jika diberi gesaan seperti, "Wira-wira Marvel yang manakah mempunyai kuasa besar yang paling berguna" boleh meningkatkan kebarangkalian model itu menamakan wira-wira tertentu dalam filem Marvel .
Alat OpenAI menggunakan tetapan ini untuk menguraikan model kepada bahagian yang berasingan.
Langkah 1: Gunakan GPT-4 untuk menjana penjelasan
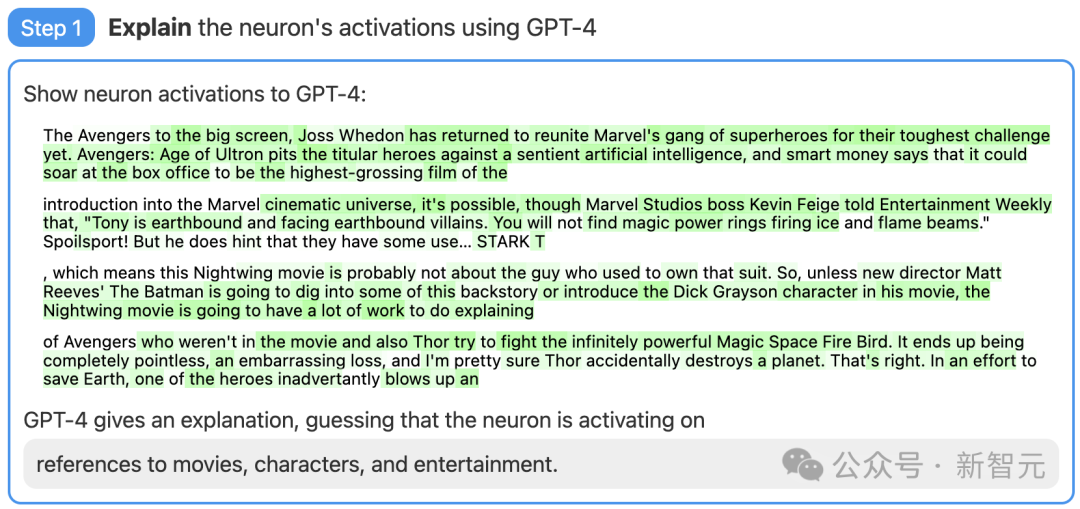
Mula-mula, cari neuron GPT-2 dan tunjukkan urutan teks yang berkaitan dan pengaktifan kepada GPT-4.
Kemudian, biarkan GPT-4 menjana penjelasan yang mungkin berdasarkan tingkah laku ini.
Sebagai contoh, dalam contoh di bawah, GPT-4 percaya bahawa neuron ini berkaitan dengan filem, watak dan hiburan.
 Gambar
Gambar
Langkah 2: Gunakan GPT-4 untuk mensimulasikan
Seterusnya, biarkan GPT-4 mensimulasikan apa yang akan dijana oleh neuron ini. . lihat betapa tepatnya tekaan GPT-4.
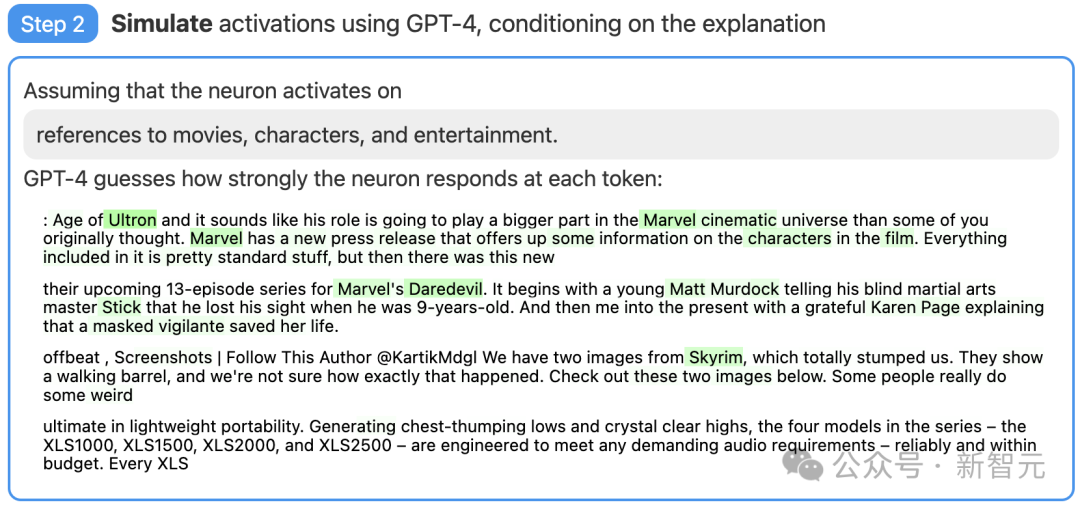 Gambar
Gambar
Juga Had
Dengan pemarkahan, penyelidik OpenAI mengukur cara teknologi berfungsi pada bahagian berlainan rangkaian saraf. Teknik ini tidak menerangkan juga untuk model yang lebih besar, mungkin kerana lapisan kemudiannya lebih sukar untuk dijelaskan.
Gambar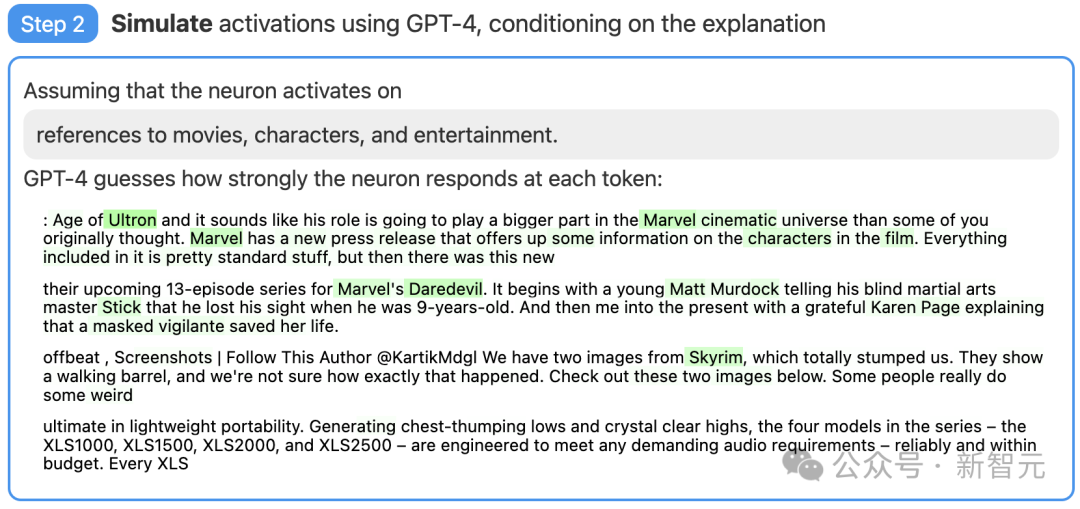
Kini, OpenAI membuka sumber set data dan alat visualisasi untuk hasil "Menggunakan GPT-4 untuk menerangkan kesemua 307,200 neuron dalam GPT-2", dan juga membuat tafsiran dan pemarkahan model sedia ada di pasaran awam melalui kod OpenAI API, dan menyeru komuniti akademik untuk membangunkan teknik yang lebih baik yang menghasilkan penjelasan skor yang lebih tinggi.
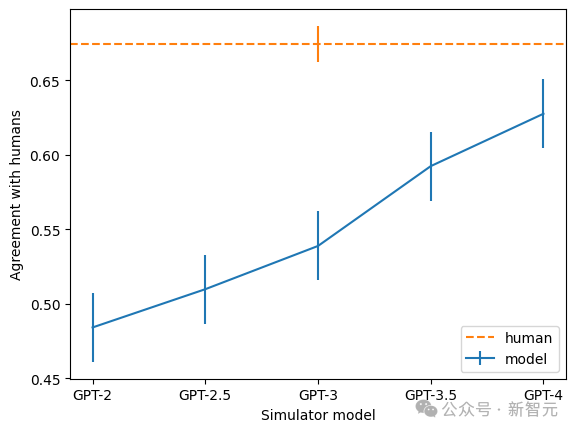
Selain itu, pasukan juga mendapati bahawa lebih besar model, lebih tinggi kadar ketekalan penjelasan. Antaranya, GPT-4 paling hampir dengan manusia, tetapi masih terdapat jurang yang besar. .

gambar
gambar
 gambar
gambar
Sparse Autoencoder Setup
Sparse Autoencoder yang digunakan oleh OpenAI ialah model dengan pincang pada input dan juga termasuk lapisan linear dengan pincang dan ReLU untuk pengekod, dan satu lagi lapisan Linear dan pincang untuk penyahkod.
Para penyelidik mendapati bahawa istilah bias adalah sangat penting kepada prestasi pengekod auto. Mereka mengaitkan bias yang digunakan dalam input dan output, dan hasilnya adalah bersamaan dengan menolak bias tetap daripada semua pengaktifan.
Para penyelidik menggunakan pengoptimum Adam untuk melatih pengekod automatik untuk membina semula pengaktifan MLP Transformer menggunakan MSE. Menggunakan kehilangan MSE boleh mengelakkan cabaran polisemantik, dan menggunakan kerugian ditambah penalti L1 untuk menggalakkan jarang.
Beberapa prinsip adalah sangat penting semasa melatih pengekod auto.
Perkara pertama adalah skala. Melatih pengekod auto pada lebih banyak data menjadikan ciri secara subjektif "lebih tajam" dan lebih boleh ditafsir. Jadi OpenAI menggunakan 8 bilion mata latihan untuk pengekod auto.
Kedua, semasa latihan, sesetengah neuron akan berhenti menembak, walaupun pada sejumlah besar titik data.
Penyelidik kemudiannya "mengambil sampel semula" neuron mati ini semasa latihan, membolehkan model itu mewakili lebih banyak ciri untuk dimensi lapisan tersembunyi pengekod auto tertentu, sekali gus menghasilkan hasil yang lebih baik.
Penunjuk Penghakiman
Bagaimana untuk menilai sama ada kaedah anda berkesan? Dalam pembelajaran mesin, anda hanya boleh menggunakan kerugian sebagai standard, tetapi bukan mudah untuk mencari rujukan yang serupa di sini.
Sebagai contoh, mencari metrik berasaskan maklumat supaya dalam erti kata tertentu, penguraian terbaik ialah yang meminimumkan jumlah maklumat pengekod automatik dan data.
- Tetapi sebenarnya, jumlah maklumat selalunya tiada kaitan dengan kebolehtafsiran ciri subjektif atau jarang pengaktifan.
Akhirnya, penyelidik menggunakan gabungan beberapa metrik tambahan:
- Pemeriksaan manual: Adakah ciri-ciri kelihatan boleh dijelaskan?
- Ketumpatan Ciri: Bilangan masa nyata ciri dan peratusan token yang mencetuskannya ialah panduan yang sangat berguna.
- Kehilangan pembinaan semula: mengukur seberapa baik pengekod auto membina semula pengaktifan MLP. Matlamat utama adalah untuk mengambil kira kefungsian lapisan MLP, jadi kehilangan MSE sepatutnya rendah.
- Model Mainan: Menggunakan model yang telah difahami dengan baik membolehkan penilaian yang jelas terhadap prestasi pengekod automatik.
Walau bagaimanapun, para penyelidik juga menyatakan harapan mereka untuk menentukan penunjuk yang lebih baik untuk penyelesaian pembelajaran kamus daripada pengekod automatik yang jarang dilatih pada Transformer.
Rujukan:
Atas ialah kandungan terperinci OpenAI secara rasmi mengumumkan Transformer Debugger sumber terbuka! Tidak perlu menulis kod, semua orang boleh memecahkan kotak hitam LLM. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- OpenAI mengeluarkan model konsisten baharu, kelajuan GAN mencapai 18FPS, dan boleh menjana imej berkualiti tinggi dalam masa nyata.
- Memfokuskan pada persaingan chatbot antara Google, Meta dan OpenAI, ChatGPT menjadikan ketidakpuasan hati LeCun sebagai tumpuan topik
- Copilot muncul di tempat kejadian, ChatGPT menggunakan carian Bing secara lalai, dan alam semesta besar Microsoft dan OpenAI ada di sini
- Bagaimana untuk memodelkan pokok keputusan dan rangkaian neuron dalam PHP?
- 'Lalat buah elektronik' penggera Musk! Di belakangnya terdapat peta seluruh otak yang mengandungi 130,000 neuron, yang boleh dijalankan pada komputer