Model ini menggunakan rangka kerja DiT seperti Sora.
Seperti yang kita semua tahu, membangunkan model T2I peringkat atas memerlukan banyak sumber, jadi pada asasnya mustahil untuk penyelidik individu yang mempunyai sumber terhad untuk membelinya. Ini juga telah menjadi AIGC (Kandungan Kecerdasan Buatan Generasi) komuniti Penghalang utama kepada inovasi. Pada masa yang sama, seiring dengan berlalunya masa, komuniti AIGC akan dapat memperoleh set data yang sentiasa dikemas kini, berkualiti tinggi dan algoritma yang lebih maju. Jadi inilah persoalan utama: Bagaimanakah kita boleh menyepadukan elemen baharu ini dengan cekap ke dalam model sedia ada dan menjadikan model itu lebih berkuasa dengan sumber yang terhad? Untuk meneroka masalah ini, pasukan penyelidik dari institusi penyelidikan seperti Makmal Bahtera Nuh Huawei mencadangkan kaedah latihan baharu: latihan lemah kepada kuat. 
Tajuk kertas: PixArt-Σ: Latihan Transformer Resapan Lemah-ke-Kuat untuk Penjanaan Teks-ke-Imej 4KAlamat kertas: https://arxiv.org/pdf/2403.04692.pdfProjek
Halaman: https://pixart-alpha.github.io/PixArt-sigma-project/ Penyelidikan mereka adalah berdasarkan PixArt-α, kaedah latihan leksikografi cekap yang mereka cadangkan pada Oktober lalu, sila rujuk laman web ini Laporan "PixArt, model graf berasaskan teks kos latihan yang sangat rendah, ada di sini, dengan hasil yang setanding dengan MJ dan hanya memerlukan masa latihan SD 10%". PixArt-α ialah percubaan awal pada rangka kerja DiT (Diffusion Transformer). Kini, dengan Sora pada carian hangat dan Stable Diffusion muncul dalam aplikasi yang tidak berkesudahan, keberkesanan seni bina DiT telah disahkan oleh semakin banyak kerja dalam komuniti penyelidikan, seperti PixArt, Dit-3D, GenTron, dll. [1] . Pasukan menggunakan model asas terlatih PixArt-α dan elemen lanjutan bersepadu untuk mempromosikan peningkatan berterusannya, akhirnya menghasilkan model PixArt-Σ yang lebih berkuasa. Rajah 1 menunjukkan beberapa contoh hasil yang dijana.
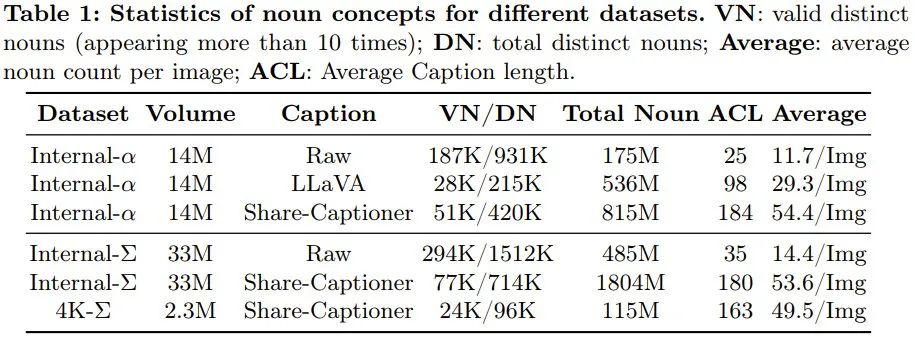
PixArt-Σ Bagaimana cara membuatnya? Khususnya, untuk mencapai latihan yang lemah kepada yang kuat dan mencipta PixArt-Σ, pasukan ini telah menggunakan langkah penambahbaikan berikut. . mengandungi 33 juta imej resolusi tinggi daripada Internet, semuanya melebihi resolusi 1K, termasuk 2.3 juta imej pada resolusi lebih kurang 4K. Ciri utama imej ini ialah estetikanya yang tinggi dan meliputi pelbagai gaya artistik. (2) Penerangan padat dan tepat: Untuk memberikan penerangan yang lebih tepat dan terperinci untuk imej di atas, pasukan menggantikan LLaVA yang digunakan dalam PixArt-α dengan deskriptor imej yang lebih berkuasa, Share-Captioner .
Bukan itu sahaja, untuk meningkatkan keupayaan model untuk menyelaraskan konsep teks dan konsep visual, pasukan memanjangkan panjang token pengekod teks (iaitu Flan-T5) kepada kira-kira 300 perkataan. Mereka mendapati bahawa penambahbaikan ini berkesan menghapuskan kecenderungan model untuk berhalusinasi, membolehkan penjajaran imej teks yang berkualiti tinggi.
Jadual 1 di bawah menunjukkan statistik set data yang berbeza. Mampatan token yang cekap
Untuk meningkatkan PixArt-α, pasukan itu meningkatkan resolusi penjanaannya daripada 1K kepada 4K. Untuk menjana imej resolusi ultra tinggi (seperti 2K/4K), bilangan token akan meningkat dengan ketara, yang akan membawa kepada peningkatan ketara dalam keperluan pengkomputeran. Untuk menyelesaikan masalah ini, mereka memperkenalkan modul perhatian kendiri yang ditala khas untuk rangka kerja DiT, yang menggunakan pemampatan token kunci dan nilai. Khususnya, mereka menggunakan konvolusi berkumpulan dengan langkah 2 untuk melaksanakan pengagregatan tempatan kunci dan nilai, seperti yang ditunjukkan dalam Rajah 7 di bawah.
Selain itu, pasukan ini menggunakan skim permulaan berat yang direka khas yang membolehkan penyesuaian lancar daripada model pra-latihan tanpa menggunakan mampatan KV (nilai-kunci). Reka bentuk ini berkesan mengurangkan masa latihan dan inferens untuk penjanaan imej resolusi tinggi sebanyak kira-kira 34%. . Ini termasuk: (1) Penggantian menggunakan pengekod auto variasi yang lebih berkuasa (VAE): menggantikan VAE PixArt-α dengan VAE SDXL.
(2) Untuk mengembangkan daripada resolusi rendah kepada resolusi tinggi, bagi menangani masalah kemerosotan prestasi, mereka menggunakan kaedah interpolasi Position Embedding (PE). (3) Berevolusi daripada model yang tidak menggunakan pemampatan KV kepada model yang menggunakan pemampatan KV.
Hasil eksperimen mengesahkan kebolehlaksanaan dan keberkesanan kaedah latihan yang lemah-ke-kuat.
Melalui penambahbaikan di atas, PixArt-Σ boleh menjana imej resolusi 4K berkualiti tinggi dengan kos latihan serendah mungkin dan parameter model sesedikit mungkin.
Secara khusus, dengan memulakan model yang sudah terlatih dan memperhalusinya, pasukan itu dapat menghasilkan model yang mampu menjana imej resolusi tinggi 1K menggunakan hanya tambahan 9% masa GPU yang diperlukan oleh PixArt-α. Prestasi ini luar biasa kerana ia turut menggunakan data latihan baharu dan VAE yang lebih berkuasa.
Selain itu, jumlah parameter PixArt-Σ hanyalah 0.6B Sebagai perbandingan, jumlah parameter SDXL dan SD Cascade masing-masing ialah 2.6B dan 5.1B.
Kecantikan imej yang dijana oleh PixArt-Σ adalah setanding dengan produk seni piksel teratas semasa, seperti DALL・E 3 dan MJV6. Selain itu, PixArt-Σ juga menunjukkan keupayaan yang sangat baik untuk penjajaran halus dengan gesaan teks. Rajah 2 menunjukkan hasil PixArt-Σ menjana imej resolusi tinggi 4K Dapat dilihat bahawa hasil yang dijana mengikut arahan teks yang kompleks dan padat maklumat dengan baik.
implementation Butiran Butiran: Untuk pengekod teks yang melakukan pengekstrakan ciri bersyarat, pasukan menggunakan pengekodan T5 berikutan amalan peranti Imagen dan Pixart-α (iaitu Flan-T5-XXL). Model resapan asas ialah PixArt-α. Berbeza daripada amalan mengekstrak 77 token teks tetap dalam kebanyakan kajian, panjang token teks ditingkatkan daripada 120 dalam PixArt-α kepada 300 kerana maklumat perihalan yang dianjurkan dalam Internal-Σ lebih padat dan boleh memberikan butiran yang sangat halus. . Selain itu, VAE menggunakan versi beku terlatih bagi VAE daripada SDXL. Butiran pelaksanaan lain adalah sama seperti PixArt-α.
Model diperkemaskan bermula dari pusat pemeriksaan pra-latihan 256px PixArt-α dan menggunakan teknologi interpolasi benam kedudukan. Model terakhir (termasuk resolusi 1K) telah dilatih pada 32 GPU V100. Mereka juga menggunakan 16 GPU A100 tambahan untuk melatih model penjanaan imej 2K dan 4K.
Metrik penilaian: Untuk menunjukkan estetika dan keupayaan semantik dengan lebih baik, pasukan itu mengumpulkan 30,000 pasangan imej teks berkualiti tinggi untuk menanda aras model graf Vincent yang paling berkuasa. PixArt-Σ dinilai terutamanya di sini oleh keutamaan manusia dan AI, kerana metrik FID mungkin tidak mencerminkan kualiti penjanaan dengan sewajarnya.
Penilaian kualiti imej: Pasukan secara kualitatif membandingkan kualiti penjanaan PixArt-Σ dengan produk teks-ke-imej (T2I) sumber tertutup dan model sumber terbuka. Seperti yang ditunjukkan dalam Rajah 3, berbanding model sumber terbuka SDXL dan PixArt-α pasukan sebelumnya, potret yang dijana oleh PixArt-Σ adalah lebih realistik dan mempunyai keupayaan analisis semantik yang lebih baik. PixArt-Σ mengikut arahan pengguna lebih baik daripada SDXL.
PixArt-Σ bukan sahaja mengatasi model sumber terbuka, tetapi juga bersaing dengan produk sumber tertutup semasa, seperti ditunjukkan dalam Rajah 4.
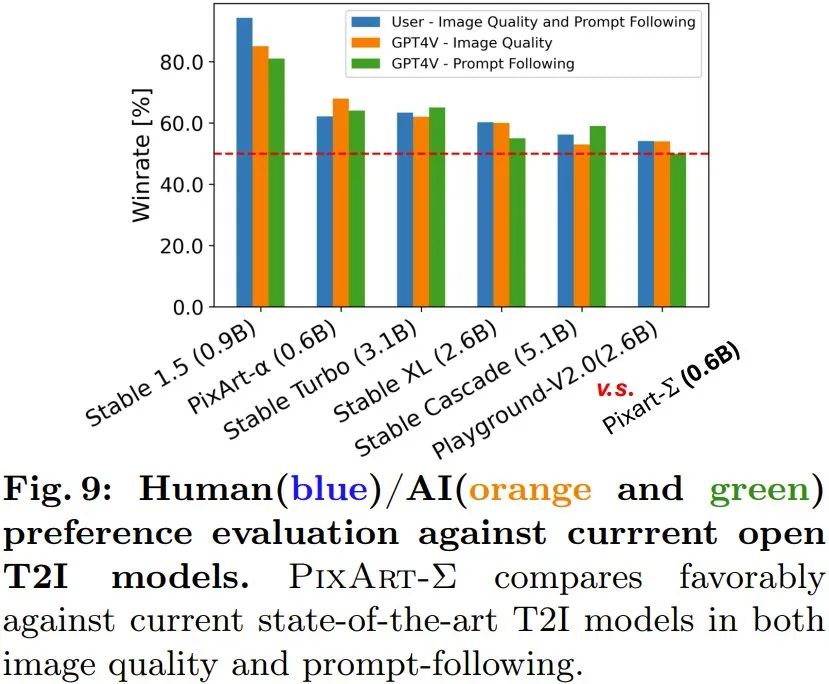
Jana imej beresolusi tinggi: Kaedah baharu boleh terus menjana imej resolusi 4K tanpa sebarang pasca pemprosesan. Di samping itu, PixArt-Σ juga boleh mematuhi dengan tepat teks panjang yang rumit dan terperinci yang disediakan oleh pengguna. Oleh itu, pengguna tidak perlu bersusah payah mereka bentuk gesaan untuk mendapatkan hasil yang memuaskan. Kajian keutamaan Manusia/AI (GPT-4V): Pasukan ini juga mengkaji keutamaan manusia dan AI untuk hasil yang dijana. Mereka mengumpul hasil penjanaan 6 model sumber terbuka, termasuk PixArt-α, PixArt-Σ, SD1.5, Stable Turbo, Stable XL, Stable Cascade dan Playground-V2.0. Mereka membangunkan tapak web yang mengumpulkan maklum balas keutamaan manusia dengan memaparkan gesaan dan imej yang sepadan. Penilai manusia boleh menilai imej berdasarkan kualiti penjanaan dan sejauh mana ia sepadan dengan gesaan. Keputusan ditunjukkan dalam graf bar biru Rajah 9. Dapat dilihat bahawa penilai manusia lebih suka PixArt-Σ berbanding 6 penjana yang lain. Berbanding dengan model penyebaran graf Vincentian sebelumnya, seperti SDXL (parameter 2.6B) dan SD Cascade (parameter 5.1B), PixArt-Σ boleh menjana kualiti yang lebih tinggi dan lebih konsisten dengan gesaan pengguna dengan imej parameter yang jauh lebih sedikit (0.6B).
Selain itu, pasukan menggunakan model berbilang mod termaju GPT-4 Vision untuk melaksanakan kajian keutamaan AI. Apa yang mereka lakukan ialah suapan GPT-4 Vision dua imej dan biarkan ia mengundi berdasarkan kualiti imej dan penjajaran teks imej. Hasilnya ditunjukkan dalam bar oren dan hijau dalam Rajah 9, dan dapat dilihat bahawa keadaan itu pada dasarnya konsisten dengan penilaian manusia. Pasukan juga menjalankan kajian ablasi untuk mengesahkan keberkesanan pelbagai langkah penambahbaikan. Untuk butiran lanjut, sila lawati kertas asal. Artikel rujukan: 1. https://www.shoufachen.com/Awesome-Diffusion-Transformers/Atas ialah kandungan terperinci Berdasarkan DiT dan penjanaan imej 4K yang menyokong, model graf Huawei Noah 0.6B Vincent PixArt-Σ ada di sini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!