
Rumah >Peranti teknologi >AI >'AI Perspective Eye', pemenang Marr Prize tiga kali Andrew mengetuai pasukan untuk menyelesaikan masalah oklusi dan penyiapan sebarang objek
'AI Perspective Eye', pemenang Marr Prize tiga kali Andrew mengetuai pasukan untuk menyelesaikan masalah oklusi dan penyiapan sebarang objek

- WBOYke hadapan
- 2024-03-08 15:46:02807semak imbas
Oklusi adalah salah satu masalah paling asas tetapi masih tidak dapat diselesaikan dalam penglihatan komputer, kerana oklusi bermaksud kekurangan maklumat visual, manakala sistem penglihatan mesin bergantung pada maklumat visual untuk persepsi dan pemahaman, dan dalam dunia nyata, antara objek Mutual occlusion ada di mana-mana. Kerja terbaru pasukan Andrew Zisserman di Makmal VGG di Universiti Oxford secara sistematik menyelesaikan masalah penyiapan oklusi objek sewenang-wenangnya dan mencadangkan set data penilaian baharu dan lebih tepat untuk masalah ini. Kerja ini dipuji oleh bos MPI Michael Black, akaun rasmi CVPR, akaun rasmi Jabatan Sains Komputer Universiti Southern California, dsb. pada platform X. Berikut ialah kandungan utama kertas kerja "Amodal Ground Truth and Completion in the Wild".

- Pautan kertas: https://arxiv.org/pdf/2312.17247.pdf
- Laman utama projek: https://www.acrobots.uk. /research/amodal/
- Alamat kod: https://github.com/Championchess/Amodal-Completion-in-the-Wild
Amodal Segmentation direka untuk melengkapkan objek yang Bahagian tersumbat, bahawa ialah, topeng bentuk yang memberikan bahagian objek yang boleh dilihat dan tidak kelihatan. Tugas ini boleh memberi manfaat kepada banyak tugas hiliran: pengecaman objek, pengesanan sasaran, pembahagian contoh, penyuntingan imej, pembinaan semula 3D, pembahagian objek video, penaakulan perhubungan sokongan antara objek, manipulasi robot dan navigasi, kerana dalam tugasan ini diketahui bahawa objek tersumbat adalah utuh Bentuk akan membantu.

Walau bagaimanapun, cara menilai prestasi model untuk segmentasi bukan mod dalam dunia nyata adalah masalah yang sukar: walaupun terdapat sejumlah besar objek tersumbat dalam banyak gambar, bagaimana untuk mendapatkan rujukan untuk bentuk lengkap objek ini Bagaimana pula dengan topeng standard atau bukan modal? Kerja sebelumnya telah melibatkan anotasi manual topeng bukan modal, tetapi piawaian rujukan untuk anotasi sedemikian sukar untuk dielakkan daripada memperkenalkan ralat manusia, terdapat juga kerja dengan mencipta set data sintetik, seperti melampirkan objek lain secara langsung pada objek lengkap bentuk objek tersumbat diperoleh, tetapi gambar yang diperoleh dengan cara ini bukanlah pemandangan gambar sebenar. Oleh itu, kerja ini mencadangkan kaedah melalui unjuran model 3D untuk membina dataset imej sebenar berskala besar (MP3D-Amodal) yang meliputi pelbagai kategori objek dan menyediakan topeng amodal untuk menilai dengan tepat prestasi pembahagian amodal. Perbandingan set data yang berbeza adalah seperti berikut:
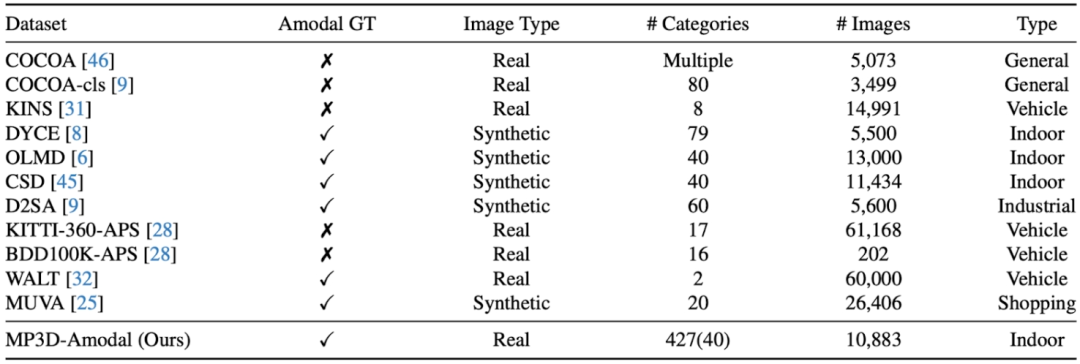
Secara khusus, mengambil set data MatterPort3D sebagai contoh, untuk mana-mana set data dengan foto sebenar dan struktur tiga dimensi tempat kejadian, kami boleh menggabungkan data daripada semua objek dalam tempat kejadian Bentuk tiga dimensi ditayangkan secara serentak ke kamera untuk mendapatkan topeng modal setiap objek (bentuk yang boleh dilihat, kerana objek itu menutup satu sama lain), dan kemudian bentuk tiga dimensi setiap objek. dalam adegan ditayangkan ke kamera secara berasingan untuk mendapatkan topeng bukan modal objek, iaitu bentuk lengkap. Dengan membandingkan topeng modal dan topeng bukan modal, objek tersumbat boleh dipilih.

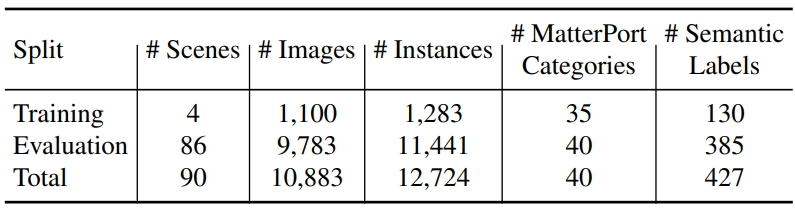
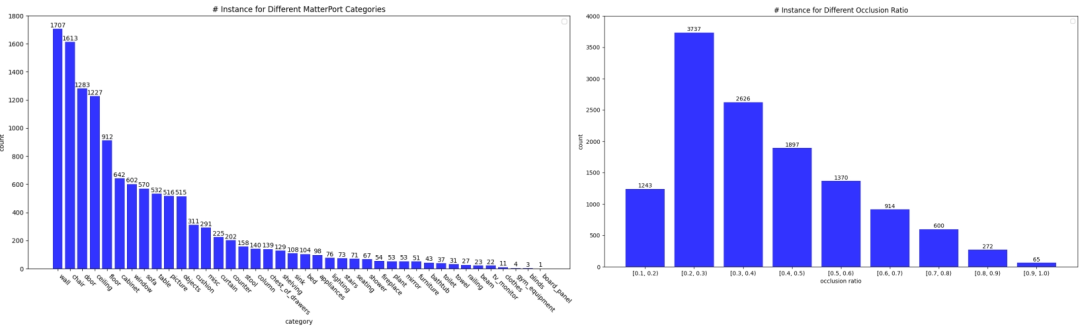
Statistik set data adalah seperti berikut:
Sampel set data adalah seperti berikut:
Selain itu, untuk menyelesaikan bentuk lengkap tugas pembinaan semula mana-mana objek, Penulis mengekstrak pengetahuan terdahulu tentang bentuk lengkap objek daripada ciri-ciri model Resapan Stabil untuk melaksanakan pembahagian bukan mod bagi mana-mana objek tersumbat. Seni bina khusus adalah seperti berikut (SDAmodal):
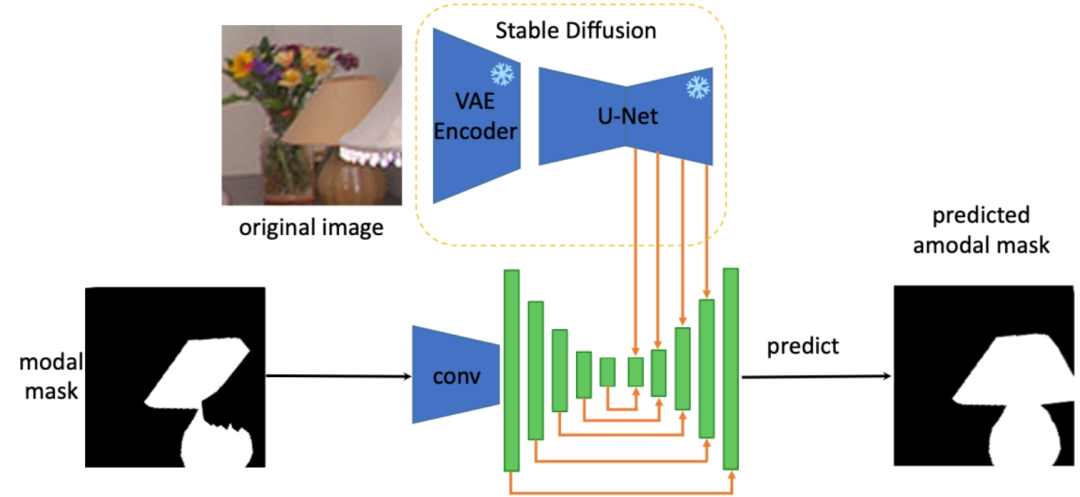
Motivasi untuk menggunakan Ciri Stable Diffusion ialah Stable Diffusion mempunyai keupayaan untuk melengkapkan gambar, jadi ia mungkin mengandungi semua maklumat tentang objek pada tahap tertentu dan kerana Stable Diffusion telah dilatih dengan sejumlah besar gambar, anda boleh mengharapkannya Ciri mempunyai keupayaan untuk memproses sebarang objek dalam mana-mana persekitaran. Berbeza daripada rangka kerja dua peringkat sebelumnya, SDAmodal tidak memerlukan topeng oklusi beranotasi kerana input SDAmodal mempunyai struktur mudah, tetapi menunjukkan keupayaan generalisasi sampel sifar yang kuat (bandingkan Tetapan F dan H dalam jadual berikut, hanya dalam latihan tentang COCOA boleh bertambah baik; pada set data lain dalam domain berbeza dan kategori berbeza); walaupun tiada anotasi objek tersumbat, SDAmodal boleh menambah baik set data sedia ada COCOA yang meliputi pelbagai jenis objek tersumbat dan yang baru dicadangkan Pada set data MP3D-Amodal, Prestasi SOTA (Tetapan H) telah dicapai.
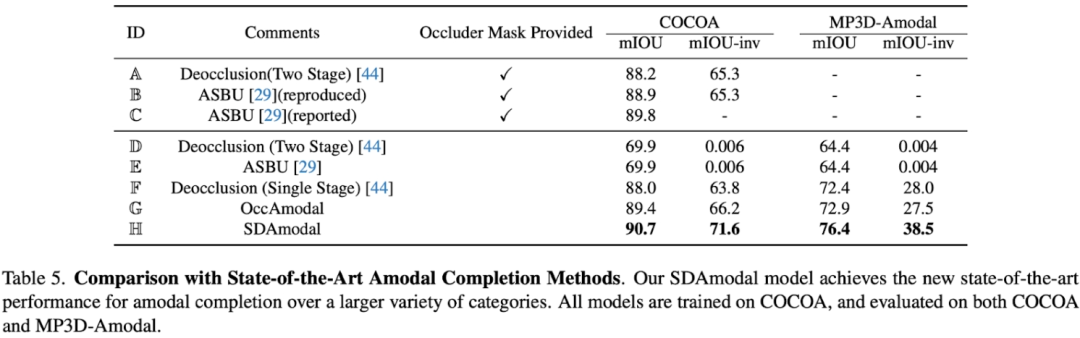
Selain eksperimen kuantitatif, perbandingan kualitatif juga mencerminkan kelebihan model SDAmodal: Ia boleh diperhatikan daripada rajah di bawah (semua model hanya dilatih menggunakan COCOA), untuk jenis objek tersumbat yang berbeza, sama ada Sama ada ia datang daripada COCOA atau MP3D-Amodal yang lain, SDAmodal boleh meningkatkan kesan pembahagian bukan modal dengan banyak, dan topeng bukan modal yang diramalkan lebih hampir kepada yang sebenar.

Untuk butiran lanjut, sila baca kertas asal.
Atas ialah kandungan terperinci 'AI Perspective Eye', pemenang Marr Prize tiga kali Andrew mengetuai pasukan untuk menyelesaikan masalah oklusi dan penyiapan sebarang objek. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!