
Rumah >Peranti teknologi >AI >Mengesan imej yang dijana AI menggunakan pengesanan kontras tekstur
Mengesan imej yang dijana AI menggunakan pengesanan kontras tekstur

- 王林ke hadapan
- 2024-03-06 21:28:091087semak imbas
Dalam artikel ini kami akan memperkenalkan cara membangunkan model pembelajaran mendalam untuk mengesan imej yang dihasilkan oleh kecerdasan buatan.

Banyak kaedah pembelajaran mendalam untuk mengesan imej yang dijana AI adalah berdasarkan cara imej dijana atau ciri/semantik imej Lazimnya model ini hanya boleh mengecam objek tertentu yang dihasilkan oleh AI, seperti orang , Muka, kereta, dsb.
Walau bagaimanapun, kaedah yang dicadangkan dalam kajian ini bertajuk "Kontras Tekstur Kaya dan Miskin: Pendekatan yang Mudah namun Berkesan untuk Pengesanan Imej janaan AI" mengatasi cabaran ini dan mempunyai kebolehgunaan yang lebih luas. Kami akan menyelami kertas penyelidikan ini untuk menggambarkan cara ia berkesan menyelesaikan masalah yang dihadapi oleh kaedah lain untuk mengesan imej yang dijana AI.
Masalah generalisasi
Apabila kita menggunakan model (seperti ResNet-50) untuk mengenali imej yang dihasilkan oleh kecerdasan buatan, model belajar berdasarkan semantik imej. Jika kami melatih model untuk mengenali imej kereta yang dijana AI, menggunakan imej sebenar dan imej kereta yang dijana AI yang berbeza untuk latihan, maka model itu hanya akan dapat mendapatkan maklumat tentang kereta daripada data ini, tetapi bukan untuk objek lain untuk tepat pengenalan.
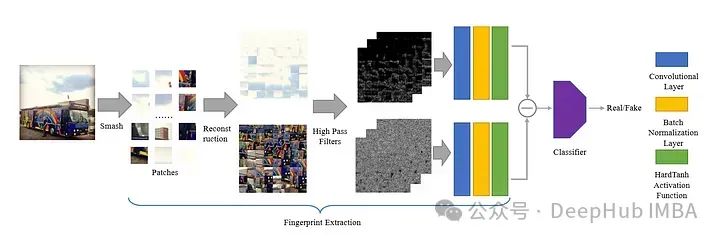
Walaupun latihan boleh dilakukan pada data pelbagai objek, kaedah ini mengambil masa yang lama dan hanya boleh mencapai ketepatan kira-kira 72% pada data yang tidak diketahui. Walaupun ketepatan boleh dipertingkatkan dengan menambah bilangan masa latihan dan jumlah data, kami tidak boleh mendapatkan data latihan tanpa had. Kertas kerja ini memperkenalkan kaedah unik , digunakan untuk menghalang model daripada mempelajari ciri yang dijana AI daripada bentuk imej semasa latihan. Penulis mencadangkan kaedah yang dipanggil Smash&Reconstruction untuk mencapai matlamat ini.
Dalam kaedah ini, imej dibahagikan kepada blok kecil saiz yang telah ditetapkan dan kemudian disusun semula untuk menghasilkan imej baharu. Ini hanyalah gambaran ringkas kerana langkah tambahan diperlukan sebelum membentuk imej input akhir untuk model generatif.
Selepas membahagikan imej kepada tompok kecil, kita bahagikan tompok kepada dua kumpulan, satu tompok dengan tekstur kaya dan satu lagi tompok dengan tekstur yang lemah.
Kawasan terperinci dalam imej, seperti objek atau sempadan antara dua kawasan warna kontras, menjadi blok tekstur yang kaya. Kawasan bertekstur kaya mempunyai variasi piksel yang besar berbanding dengan kawasan bertekstur yang terutamanya latar belakang, seperti langit atau air pegun.
Mengira metrik kekayaan tekstur 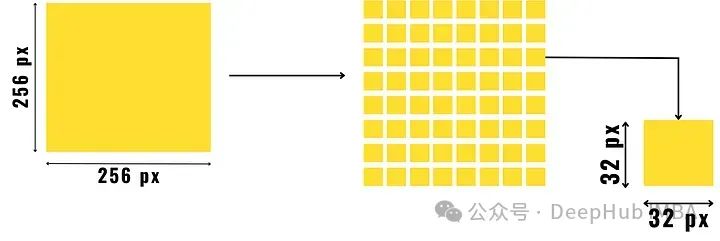
Mulakan dengan membahagikan imej kepada ketulan kecil saiz yang telah ditetapkan, seperti yang ditunjukkan dalam imej di atas. Kemudian cari kecerunan piksel tampalan imej ini (iaitu cari perbezaan nilai piksel dalam arah mendatar, pepenjuru dan anti pepenjuru dan tambahkannya) dan pisahkan kepada tampalan tekstur kaya dan tampalan bertekstur buruk . . Dua imej komposit diperolehi. Proses ini merupakan proses lengkap yang disebut oleh artikel ini sebagai "Smash&Reconstruction".
Ini membolehkan model mempelajari butiran tekstur dan bukannya perwakilan kandungan objek
cap jari
Kebanyakan teknologi berasaskan cap jari ini dihadkan oleh penjanaan/penjanaan imej model Algoritma hanya boleh mengesan imej yang dijana oleh kaedah khusus/serupa seperti resapan, GAN atau kaedah penjanaan imej berasaskan CNN yang lain.
Untuk menyelesaikan masalah ini dengan tepat, kertas telah membahagikan tampalan imej ini kepada tekstur kaya atau miskin. Penulis kemudiannya mencadangkan kaedah baru mengenal pasti cap jari dalam imej yang dihasilkan oleh kecerdasan buatan, yang merupakan tajuk kertas. Mereka mencadangkan untuk mencari kontras antara tompok kaya dan tidak bertekstur dalam imej selepas menggunakan 30 penapis laluan tinggi. 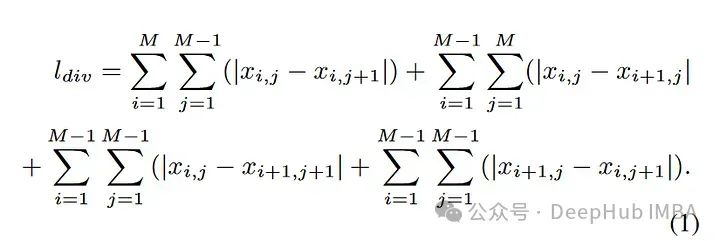
Bagaimanakah perbezaan antara blok tekstur kaya dan miskin membantu?
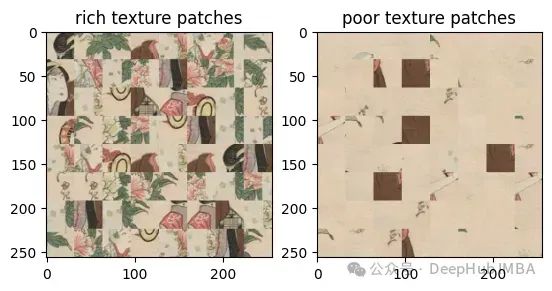 Untuk pemahaman yang lebih baik, kami membandingkan imej sebelah menyebelah, imej sebenar dan imej yang dijana AI.
Untuk pemahaman yang lebih baik, kami membandingkan imej sebelah menyebelah, imej sebenar dan imej yang dijana AI.

Kedua-dua imej ini juga sangat sukar untuk dilihat dengan mata kasar, bukan? penapis laluan tinggi, kontras antara mereka:

Daripada keputusan ini kita dapat melihat bahawa imej yang dijana AI mempunyai tompok tekstur yang kaya dan kontras yang lemah berbanding dengan imej sebenar Kontrasnya jauh lebih tinggi. 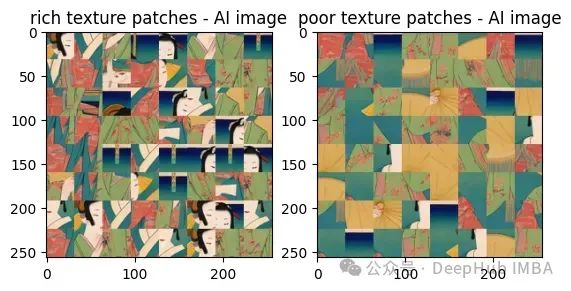
Dengan cara ini, kita dapat melihat perbezaan dengan mata kasar, jadi kita boleh meletakkan hasil kontras ke dalam model yang boleh dilatih dan memasukkan data hasil ke dalam pengelas Ini adalah seni bina model kertas kami:

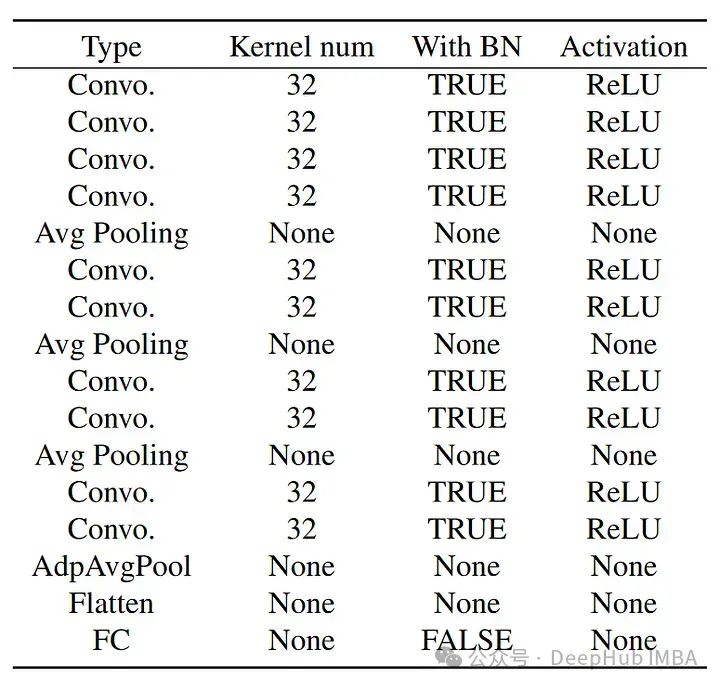
 Struktur pengelas adalah seperti berikut:
Struktur pengelas adalah seperti berikut:
Kertas tersebut menyebut 30 penapis laluan tinggi, yang pada asalnya diperkenalkan untuk steganalisis.
 Nota: Terdapat banyak cara steganografi imej. Secara umum, selagi maklumat disembunyikan dalam gambar dalam beberapa cara dan sukar ditemui melalui cara biasa, ia boleh dipanggil steganografi gambar Terdapat banyak kajian berkaitan mengenai steganalysis, dan mereka yang berminat boleh menyemak maklumat yang berkaitan.
Nota: Terdapat banyak cara steganografi imej. Secara umum, selagi maklumat disembunyikan dalam gambar dalam beberapa cara dan sukar ditemui melalui cara biasa, ia boleh dipanggil steganografi gambar Terdapat banyak kajian berkaitan mengenai steganalysis, dan mereka yang berminat boleh menyemak maklumat yang berkaitan.
Penapis di sini ialah nilai matriks yang digunakan pada imej menggunakan kaedah konvolusi Penapis yang digunakan ialah penapis laluan tinggi, yang hanya membenarkan ciri frekuensi tinggi imej melaluinya. Ciri frekuensi tinggi biasanya termasuk tepi, butiran halus dan perubahan pantas dalam keamatan atau warna.
Kecuali (f) dan (g), semua penapis diputar pada satu sudut sebelum digunakan semula pada imej, sekali gus membentuk sejumlah 30 penapis. Putaran matriks ini dilakukan menggunakan transformasi affine, yang dilakukan menggunakan SciPy.
Summary
Hasil kertas telah mencapai ketepatan pengesahan sebanyak 92%, dan dikatakan bahawa jika lebih banyak latihan dilakukan, akan ada hasil yang lebih baik. jumpa Kod latihan, mereka yang berminat boleh belajar secara mendalam:
 Kertas: https://arxiv.org/abs/2311.12397
Kertas: https://arxiv.org/abs/2311.12397
Kod: https://github.com/hridayK/Detection-of-AI- terhasil-imej
Atas ialah kandungan terperinci Mengesan imej yang dijana AI menggunakan pengesanan kontras tekstur. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!