
Rumah >Peranti teknologi >AI >Kertas Stable Diffusion 3 akhirnya telah dikeluarkan, dan butiran seni bina didedahkan Adakah ia akan membantu untuk menghasilkan semula Sora?
Kertas Stable Diffusion 3 akhirnya telah dikeluarkan, dan butiran seni bina didedahkan Adakah ia akan membantu untuk menghasilkan semula Sora?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-03-06 17:34:14778semak imbas
Kertas untuk Stable Diffusion 3 akhirnya tiba!
Model ini dikeluarkan dua minggu lalu dan menggunakan seni bina DiT (Diffusion Transformer) yang sama seperti Sora. Ia menimbulkan kekecohan semasa dikeluarkan.
Berbanding dengan versi sebelumnya, kualiti imej yang dijana oleh Stable Diffusion 3 telah dipertingkatkan dengan ketara Ia kini menyokong gesaan berbilang tema, dan kesan penulisan teks juga telah dipertingkatkan, bukan lagi aksara yang bercelaru.
Stability AI menunjukkan bahawa Stable Diffusion 3 ialah satu siri model dengan saiz parameter antara 800M hingga 8B. Julat parameter ini bermakna model boleh dijalankan terus pada banyak peranti mudah alih, dengan ketara menurunkan ambang untuk menggunakan model AI yang besar.
Dalam kertas yang baru dikeluarkan, Stability AI menyatakan bahawa dalam penilaian berasaskan keutamaan manusia, Stable Diffusion 3 mengatasi sistem penjanaan teks-ke-imej terkini seperti DALL・E 3, Midjourney v6, dan Ideogram v1. Tidak lama lagi, mereka akan menjadikan data eksperimen, kod dan berat model kajian tersedia secara terbuka.
Dalam kertas itu, Stability AI mendedahkan lebih banyak butiran tentang Stable Diffusion 3. . .com/Stable+Diffusion+3+Paper.pdf

- Butiran seni bina Untuk penjanaan teks ke imej, model Stable Diffusion 3 mesti mempertimbangkan kedua-dua mod teks dan imej. Oleh itu, pengarang kertas itu memanggil seni bina baharu ini MMDiT, merujuk kepada keupayaannya untuk mengendalikan pelbagai modaliti. Seperti versi Stable Diffusion sebelumnya, penulis menggunakan model pra-latihan untuk memperoleh teks dan perwakilan imej yang sesuai. Khususnya, mereka menggunakan tiga model pembenaman teks yang berbeza—dua model CLIP dan T5—untuk mengekod perwakilan teks dan model pengekodan automatik yang dipertingkatkan untuk mengekod token imej.
- Seni bina model Resapan Stabil 3.
Pengubah resapan berbilang modal yang dipertingkatkan: blok MMDiT.
Seni bina SD3 adalah berdasarkan DiT yang dicadangkan oleh ahli R&D teras Sora William Peebles dan Xie Saining, penolong profesor sains komputer di Universiti New York. Memandangkan pembenaman teks dan pembenaman imej secara konsepnya sangat berbeza, pengarang SD3 menggunakan dua set pemberat yang berbeza untuk kedua-dua modaliti. Seperti yang ditunjukkan dalam rajah di atas, ini bersamaan dengan menyediakan dua transformer bebas untuk setiap modaliti, tetapi menggabungkan jujukan dua modaliti untuk operasi perhatian, supaya kedua-dua perwakilan boleh berfungsi dalam ruang mereka sendiri, Perwakilan lain juga diambil kira. . 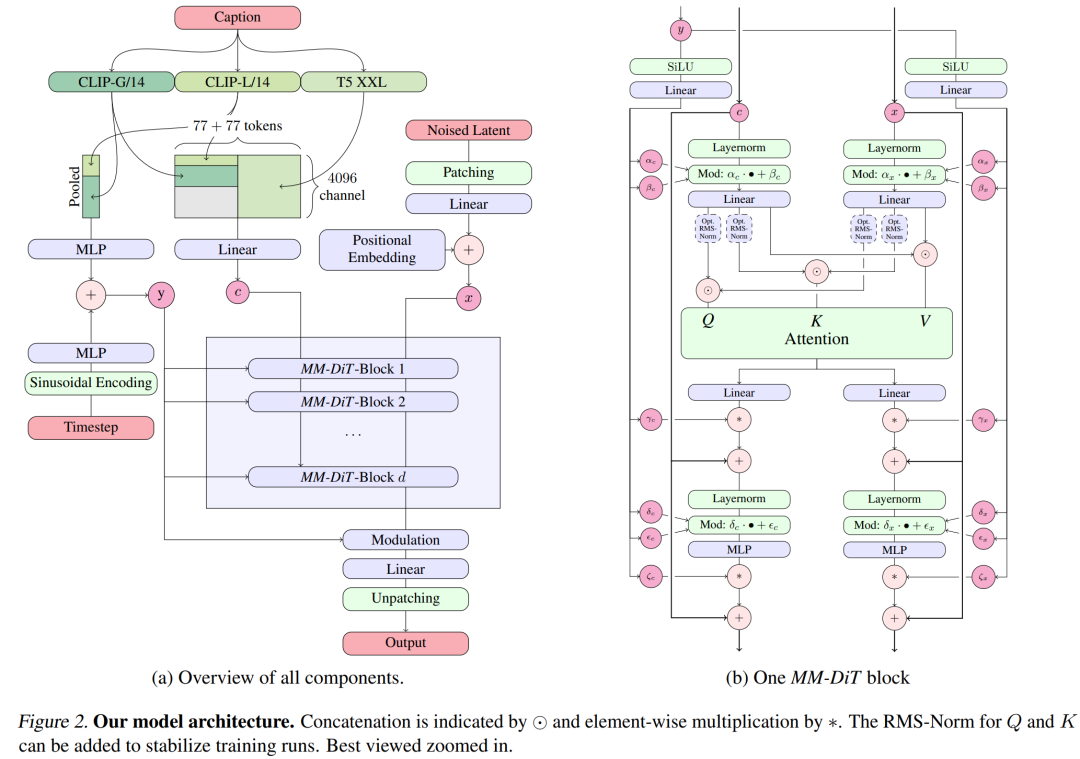
Seni bina MMDiT yang dicadangkan oleh pengarang mengatasi prestasi tulang belakang teks-ke-imej seperti UViT dan DiT apabila mengukur kesetiaan visual dan penjajaran teks semasa latihan. 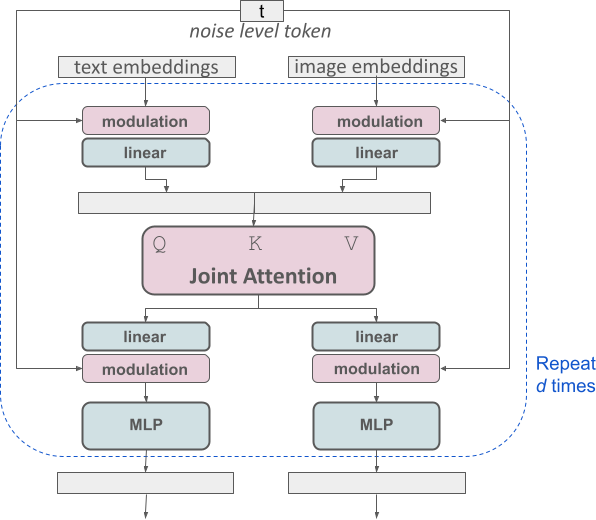
Dengan pendekatan ini, maklumat boleh mengalir antara imej dan token teks, dengan itu meningkatkan pemahaman keseluruhan model dan menambah baik pemformatan teks output yang dijana. Seperti yang dibincangkan dalam kertas kerja, seni bina ini juga mudah diperluaskan kepada pelbagai modaliti seperti video.
Terima kasih kepada keupayaan berikutan pantas Stable Diffusion 3 yang dipertingkatkan, model baharu ini mempunyai keupayaan untuk menghasilkan imej yang memfokus pada pelbagai tema dan kualiti yang berbeza, di samping sangat fleksibel dalam gaya imej itu sendiri. 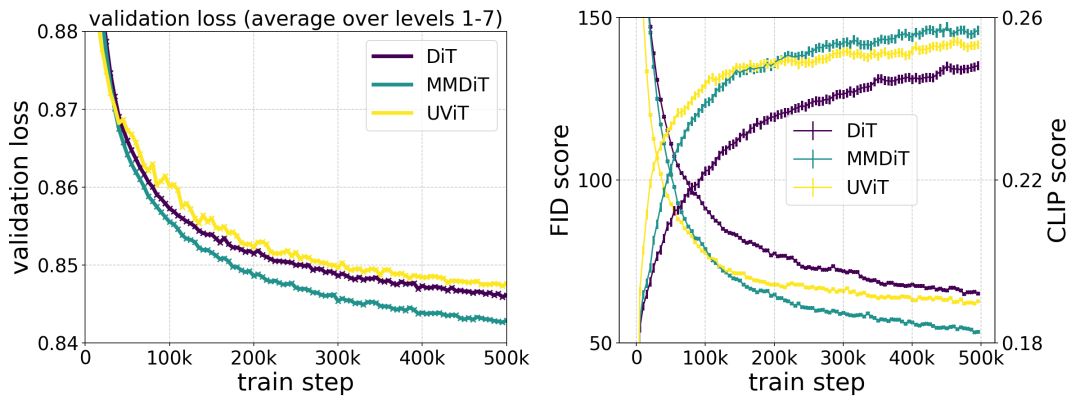

Peningkatan Aliran Diperbetulkan melalui pemberat semula
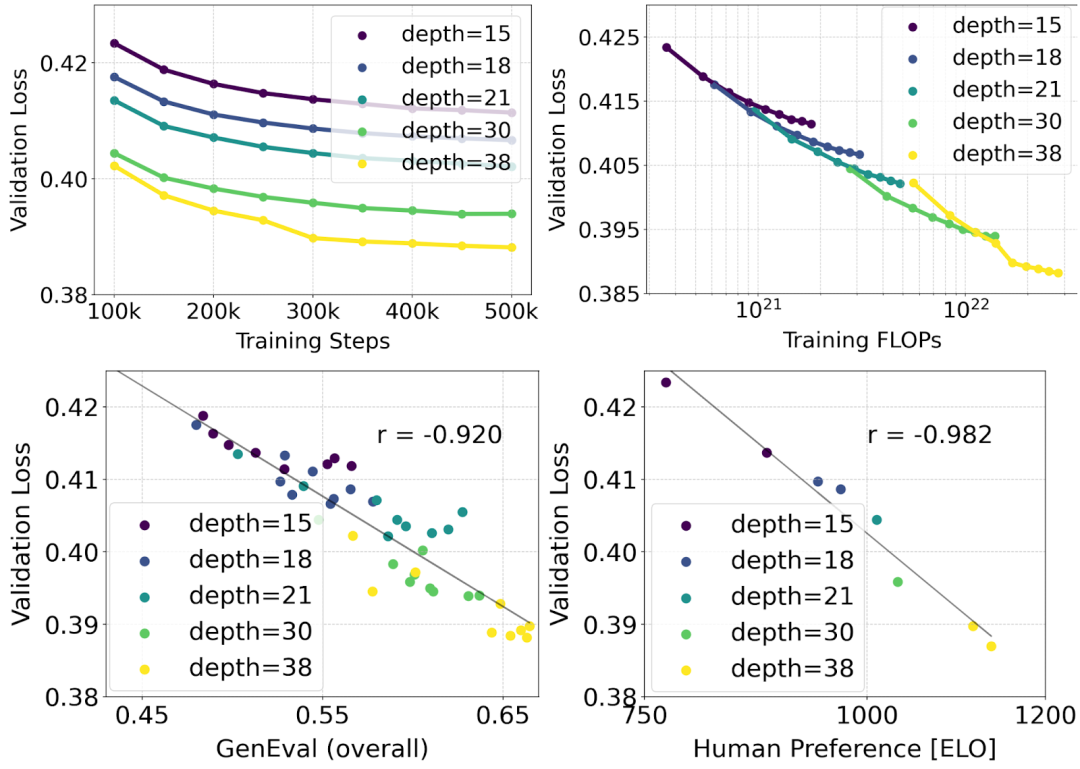
Stable Diffusion 3 menggunakan formula Rectified Flow (RF) Semasa proses latihan, data dan hingar disambungkan dalam trajektori linear. Ini menjadikan laluan inferens lebih lurus, sekali gus mengurangkan langkah pensampelan. Selain itu, penulis juga memperkenalkan skim pensampelan trajektori baharu semasa proses latihan. Mereka membuat hipotesis bahawa bahagian tengah trajektori akan menimbulkan tugas ramalan yang lebih mencabar, jadi skema itu memberi lebih berat kepada bahagian tengah trajektori. Mereka membandingkan menggunakan berbilang set data, metrik dan tetapan pensampel dan menguji kaedah cadangan mereka terhadap 60 trajektori resapan lain seperti LDM, EDM dan ADM. Keputusan menunjukkan bahawa walaupun prestasi formulasi RF sebelumnya bertambah baik dengan beberapa langkah pensampelan, prestasi relatifnya berkurangan apabila bilangan langkah meningkat. Sebaliknya, varian RF wajaran semula yang dicadangkan oleh pengarang secara konsisten meningkatkan prestasi. . Mereka melatih model antara 15 blok dengan parameter 450M hingga 38 blok dengan parameter 8B dan memerhatikan bahawa kehilangan pengesahan menurun dengan lancar dengan peningkatan saiz model dan langkah latihan (bahagian pertama rajah di atas OK). Untuk mengkaji sama ada ini diterjemahkan kepada peningkatan yang bermakna dalam output model, penulis juga menilai metrik penjajaran imej automatik (GenEval) dan skor keutamaan manusia (ELO) (baris kedua di atas). Keputusan menunjukkan korelasi yang kuat antara metrik ini dan kehilangan pengesahan, menunjukkan bahawa yang terakhir adalah peramal yang baik bagi prestasi keseluruhan model. Tambahan pula, trend penskalaan tidak menunjukkan tanda-tanda tepu, menjadikan pengarang optimis untuk terus meningkatkan prestasi model pada masa hadapan.
 Pengekod teks fleksibel
Pengekod teks fleksibel
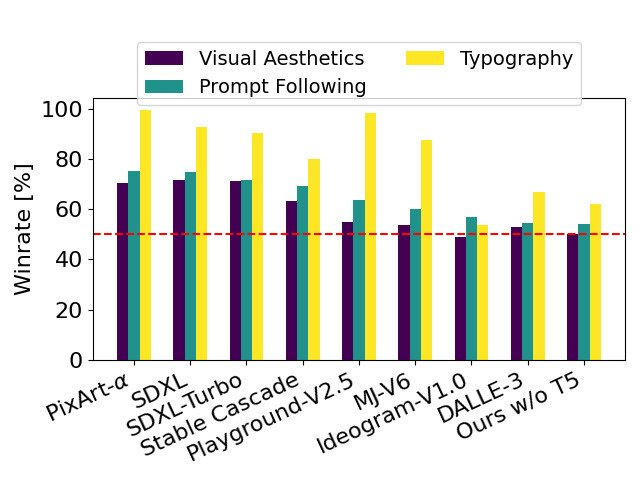
Dengan mengalih keluar pengekod teks T5 parameter 4.7B intensif memori yang digunakan untuk inferens, keperluan memori SD3 boleh dikurangkan dengan ketara dengan kehilangan prestasi yang minimum. Seperti yang ditunjukkan, mengalih keluar pengekod teks ini tidak memberi kesan pada estetika visual (kadar kemenangan 50% tanpa T5) dan hanya mengurangkan sedikit konsistensi teks (kadar kemenangan 46%). Walau bagaimanapun, penulis mengesyorkan menambah T5 apabila menjana teks bertulis untuk menggunakan sepenuhnya prestasi SD3, kerana mereka mendapati bahawa tanpa menambah T5, prestasi penjanaan taip menurun lebih banyak lagi (kadar kemenangan 38%), seperti yang ditunjukkan dalam rajah di bawah:
Hanya apabila mengemukakan gesaan yang sangat kompleks yang melibatkan banyak butiran atau sejumlah besar teks bertulis akan pengalihan keluar T5 untuk inferens mengakibatkan penurunan prestasi yang ketara. Imej di atas menunjukkan tiga sampel rawak bagi setiap contoh.
Prestasi Model
 Pengarang membandingkan imej keluaran Stable Diffusion 3 dengan pelbagai model sumber terbuka lain (termasuk SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 dan Pixart-α) serta sumber tertutup model seperti DALL -E 3, Midjourney v6 dan Ideogram v1) dibandingkan untuk menilai prestasi berdasarkan maklum balas manusia. Dalam ujian ini, penilai manusia diberikan contoh output daripada setiap model dan dinilai berdasarkan sejauh mana output model mengikut konteks gesaan yang diberikan (prompt following), seberapa baik teks dipaparkan mengikut prompt (tipografi), dan yang mana. imej Imej dengan estetika visual yang lebih tinggi dipilih untuk hasil terbaik.
Pengarang membandingkan imej keluaran Stable Diffusion 3 dengan pelbagai model sumber terbuka lain (termasuk SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 dan Pixart-α) serta sumber tertutup model seperti DALL -E 3, Midjourney v6 dan Ideogram v1) dibandingkan untuk menilai prestasi berdasarkan maklum balas manusia. Dalam ujian ini, penilai manusia diberikan contoh output daripada setiap model dan dinilai berdasarkan sejauh mana output model mengikut konteks gesaan yang diberikan (prompt following), seberapa baik teks dipaparkan mengikut prompt (tipografi), dan yang mana. imej Imej dengan estetika visual yang lebih tinggi dipilih untuk hasil terbaik.
Ditanda aras dengan SD3, carta ini menggariskan kadar kemenangannya berdasarkan penilaian manusia terhadap estetika visual, mengikuti segera dan reka letak teks.
Daripada keputusan ujian, penulis mendapati bahawa Stable Diffusion 3 adalah bersamaan atau lebih baik daripada sistem penjanaan teks-ke-imej terkini dalam semua aspek di atas.
 Dalam ujian inferens awal yang tidak dioptimumkan pada perkakasan pengguna, model SD3 parameter 8B terbesar sesuai dengan 24GB VRAM RTX 4090, mengambil masa 34 saat untuk menjana imej pada resolusi 1024x1024 menggunakan 50 langkah pensampelan.
Dalam ujian inferens awal yang tidak dioptimumkan pada perkakasan pengguna, model SD3 parameter 8B terbesar sesuai dengan 24GB VRAM RTX 4090, mengambil masa 34 saat untuk menjana imej pada resolusi 1024x1024 menggunakan 50 langkah pensampelan.
Selain itu, pada keluaran awal, Stable Diffusion 3 akan tersedia dalam pelbagai varian, antara model parametrik 800m hingga 8B untuk menghapuskan lagi halangan perkakasan.


Sila rujuk kertas asal untuk butiran lanjut.
Pautan rujukan: https://stability.ai/news/stable-diffusion-3-research-paper
Atas ialah kandungan terperinci Kertas Stable Diffusion 3 akhirnya telah dikeluarkan, dan butiran seni bina didedahkan Adakah ia akan membantu untuk menghasilkan semula Sora?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- nb-lot技术的特点是什么?
- 电脑main什么意思
- 区块链有哪四大核心技术
- Adakah boleh dipercayai untuk menggunakan ChatGPT untuk menulis kertas kerja? Sesetengah sarjana mencubanya: penuh dengan kelemahan, tetapi alat yang 'baik' untuk suntikan air
- 'Kertas 100 AI Teratas' pada 2022 dikeluarkan: Tsinghua menduduki tempat kedua selepas Google, dan Institut Teknologi Ningbo menjadi kuda hitam terbesar