
Rumah >Peranti teknologi >AI >Adakah era GPT-4 sudah berakhir? Netizen di seluruh dunia menguji Claude 3 dan terkejut
Adakah era GPT-4 sudah berakhir? Netizen di seluruh dunia menguji Claude 3 dan terkejut

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-03-06 13:00:18580semak imbas
Arah teks biasa model besar telah digulung ke penghujung?
Malam tadi, pesaing terbesar OpenAI, Anthropic mengeluarkan generasi baharu siri model besar AI - Claude 3.
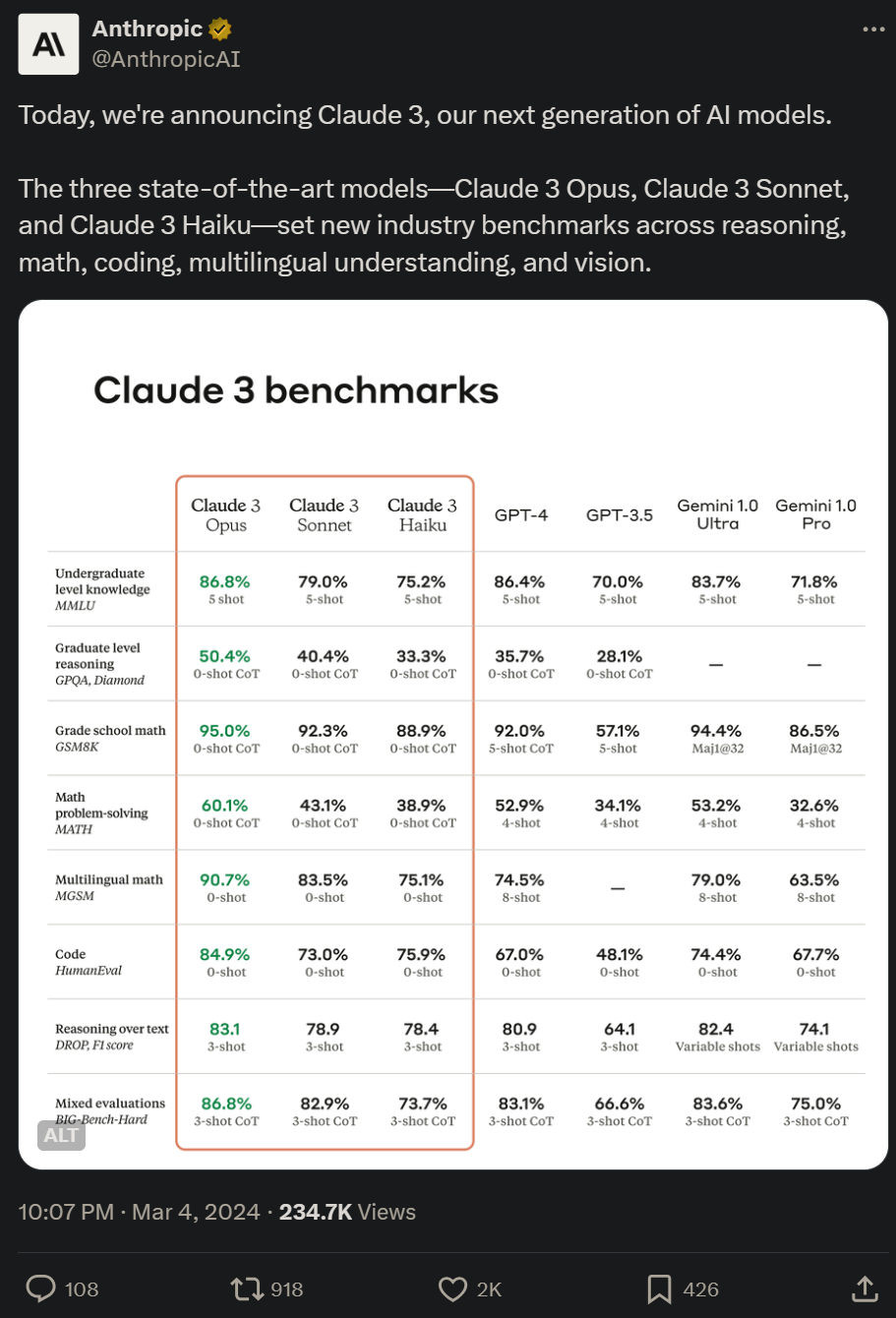
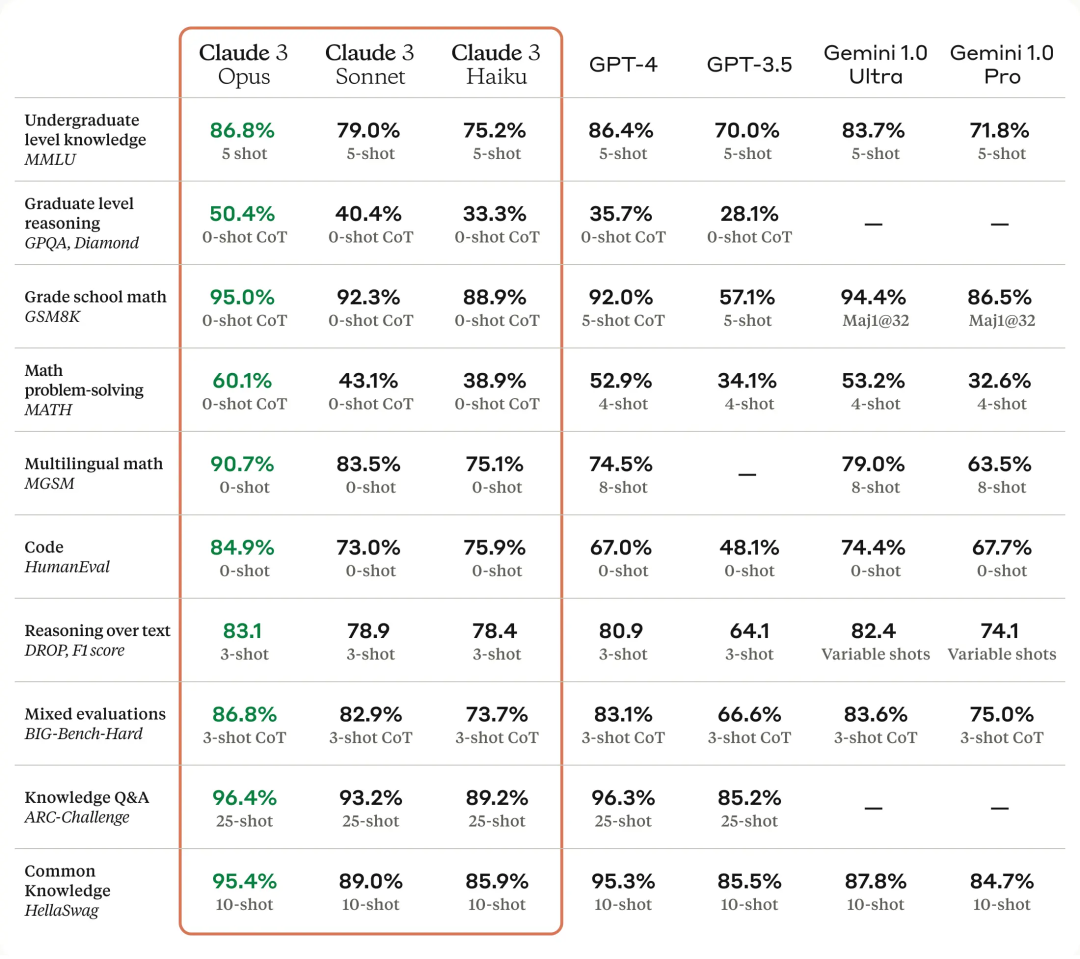
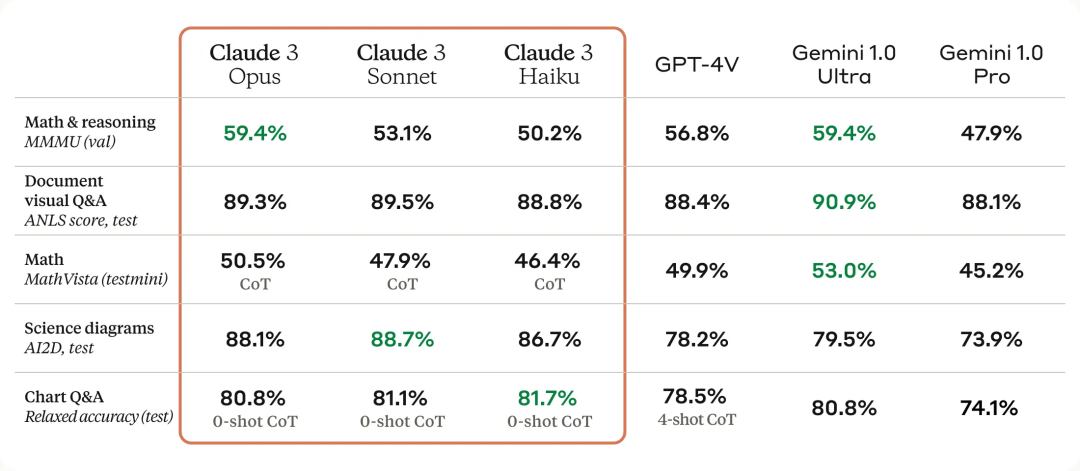
Siri ini mengandungi tiga model, disenaraikan dari yang paling lemah kepada yang paling kuat, iaitu Claude 3 Haiku, Claude 3 Sonnet dan Claude 3 Opus. Antaranya, Opus, yang paling berkebolehan, telah mendapat markah lebih tinggi daripada GPT-4 dan Gemini 1.0 Ultra dalam pelbagai ujian penanda aras, menetapkan penanda aras industri baharu dalam pelbagai dimensi seperti matematik, pengaturcaraan, pemahaman berbilang bahasa dan penglihatan.
Anthropic menyatakan bahawa Claude 3 Opus memiliki pengetahuan peringkat sarjana muda manusia.
Selepas keluaran model baharu, Claude membawakan sokongan untuk keupayaan pelbagai mod buat kali pertama (skor MMMU versi Opus ialah 59.4%, melebihi GPT-4V dan setanding dengan Gemini 1.0 Ultra). Pengguna kini boleh memuat naik foto, carta, dokumen dan jenis data tidak berstruktur lain untuk dianalisis dan dijawab oleh AI.
Selain itu, ketiga-tiga model ini juga mengekalkan kelebihan konsisten model siri Claude iaitu tetingkap konteks panjang. Tetingkap konteks 200K token akan disokong pada mulanya, tetapi Anthropic berkata ketiga-tiga model akan menyokong input kontekstual sebanyak 1 juta token (untuk pelanggan tertentu), bersamaan dengan versi Inggeris Moby Dick atau Harry Potter and the Deathly Hallows 》panjang.
Walau bagaimanapun, dari segi harga, Claude 3 yang paling berkuasa juga jauh lebih mahal daripada GPT-4 Turbo: GPT-4 Turbo mengecaj 10/30 USD setiap juta input/output token manakala Claude 3 Opus ialah $15/; 75.
Model Opus dan Sonnet kini tersedia dalam claude.ai dan Claude API, dengan model Haiku akan datang tidak lama lagi. Amazon Cloud Technologies telah mengumumkan bahawa model baharu mereka kini tersedia di Amazon Bedrock. Anthropic mengumumkan demo rasmi, butirannya adalah seperti berikut:
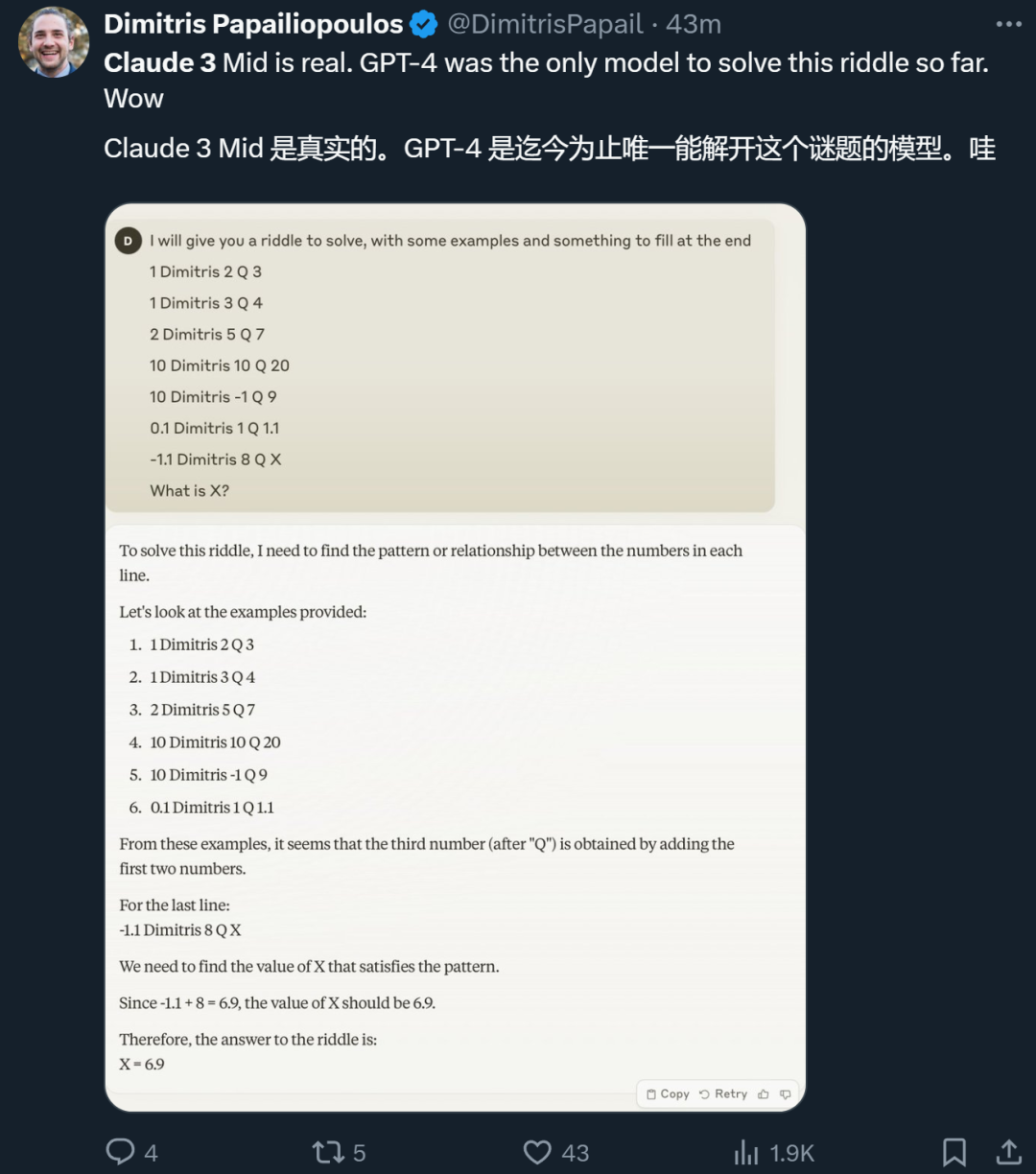
Selepas pengumuman rasmi Anthropic, ramai penyelidik yang mendapat peluang mencubanya turut berkongsi pengalaman mereka. Ada yang mengatakan bahawa Claude 3 Sonnet telah menyelesaikan teka-teki yang hanya GPT-4 boleh selesaikan sebelum ini.
Namun, ada yang mengatakan bahawa dari segi pengalaman sebenar, Claude 3 tidak mengalahkan GPT-4 sepenuhnya.
Ujian sebenar Claude 3
Alamat: https://claude.ai/
benar-benar lulus Claude 4 ? Pada masa ini, kebanyakan orang berfikir bahawa ia mempunyai beberapa makna.
Berikut adalah beberapa keputusan ujian sebenar:
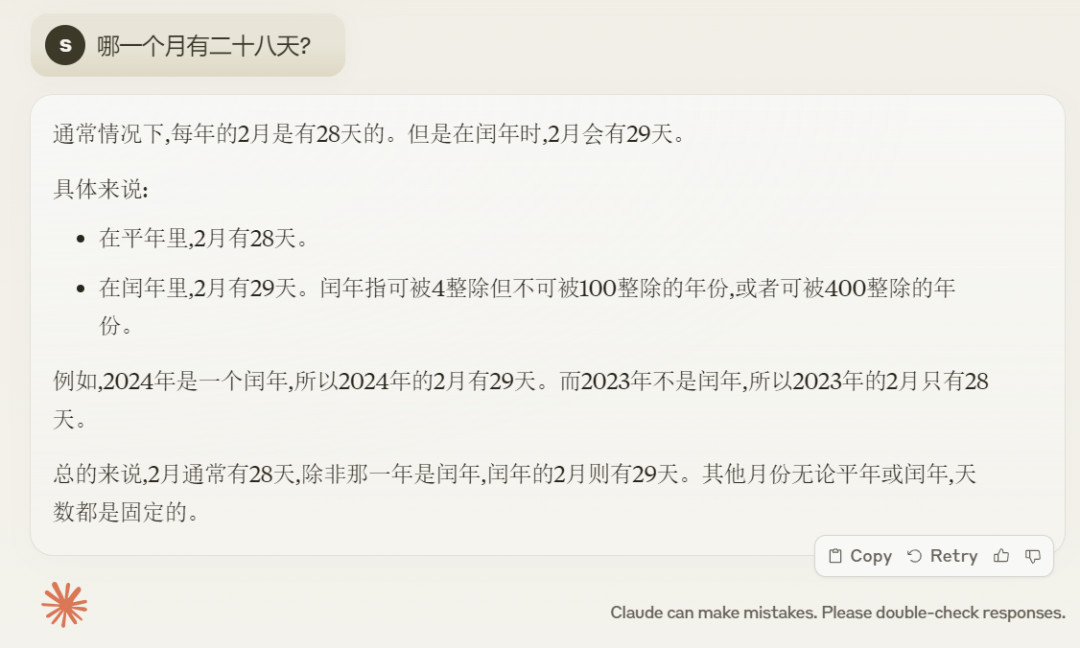
Pertama sekali, mari kita buat asah otak Bulan manakah yang mempunyai dua puluh lapan hari? Jawapan yang betul adalah setiap bulan. Nampaknya Claude 3 belum pandai buat soalan macam ni.
Kemudian kami menguji bidang yang Claude 3 mahir Dari pengenalan rasmi, kami dapat melihat bahawa Claude pandai "memahami dan memproses imej", termasuk mengekstrak teks daripada imej, menukar UI ke hadapan-. kod akhir, dan memahami persamaan Kompleks, menyalin nota tulisan tangan, dan banyak lagi.
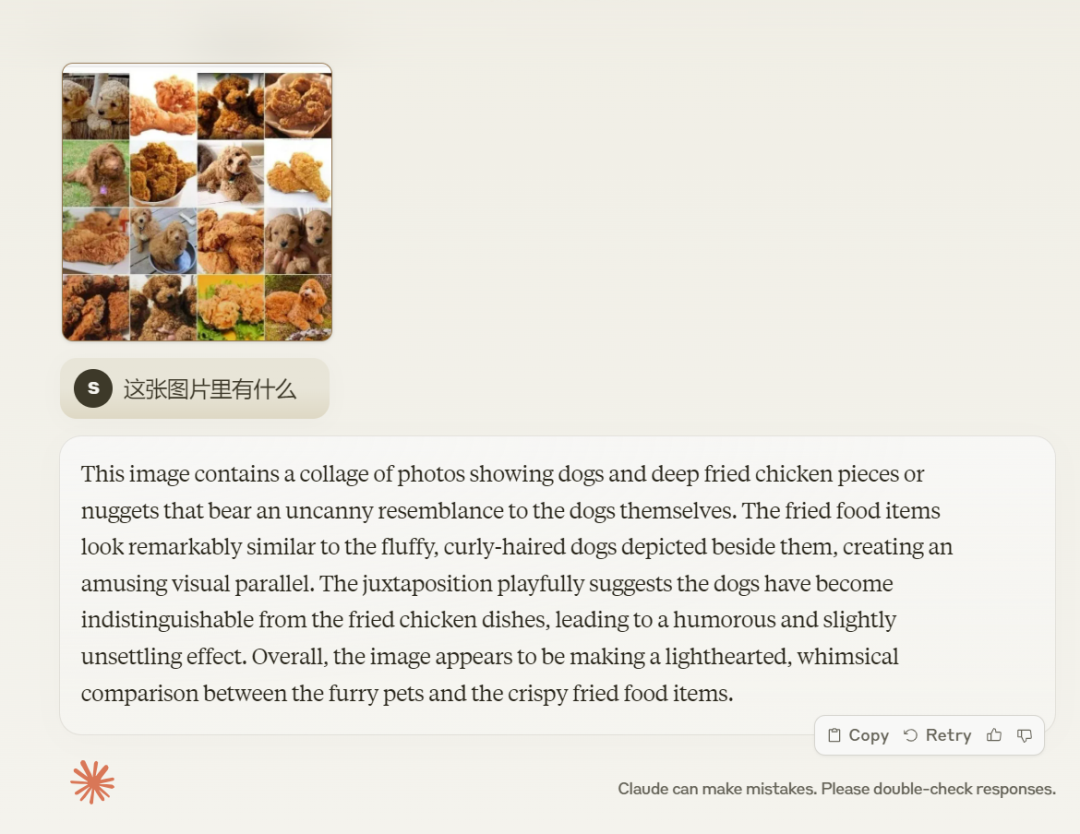
Bagi model besar, selalunya sukar untuk membezakan antara ayam goreng dan teddy Apabila kita memasukkan gambar yang mengandungi teddy dan ayam goreng, Claude 3 memberikan jawapan "Gambar ini adalah satu set kolaj A yang mengandungi seekor anjing dan ayam. nugget atau nugget yang mempunyai persamaan yang ketara dengan anjing itu sendiri...” Soalan ini berlalu.
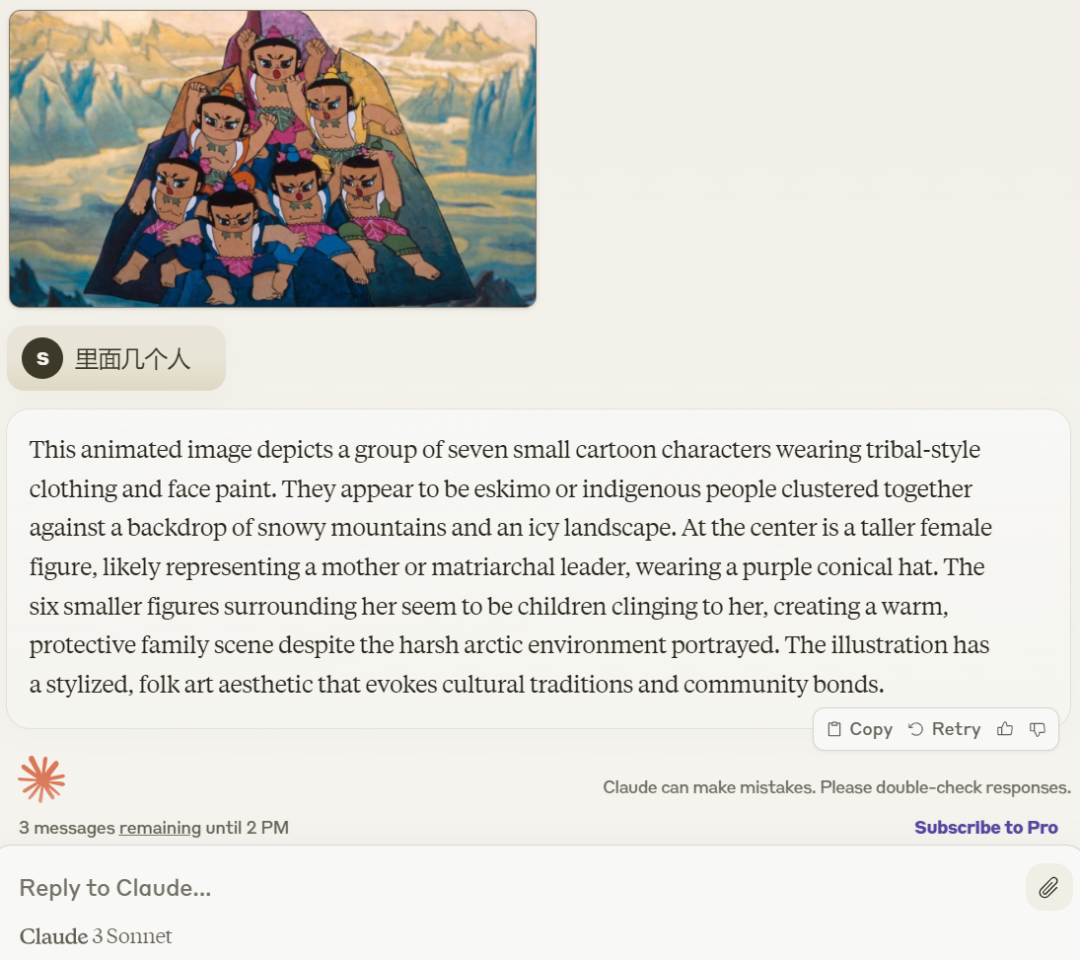
Kemudian ditanya berapa orang di dalamnya, Claude 3 pun menjawab betul, "Animasi ini menggambarkan tujuh watak kartun kecil."
Claude 3 boleh mengekstrak teks daripada foto, malah susunan menegak Cina dan Jepun boleh dikenali dengan betul:

Jika saya menggunakan meme di Internet, bagaimanakah ia akan menanganinya? Mengenai gambar ralat visual, GPT-4 dan Claude3 memberikan tekaan yang bertentangan:
Yang manakah betul?
Selain memahami imej, Claude juga mampu memproses teks panjang Siri penuh model besar yang dikeluarkan kali ini boleh menyediakan 200k tetingkap konteks dan menerima lebih daripada 1 juta input token.
Bagaimana kesannya? Kami memberikan kertas kerja baru-baru ini "The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits" yang diterbitkan oleh Microsoft dan National University of Science and Technology, dan memintanya untuk meringkaskan perkara utama artikel dalam bentuk daripada 1, 2, dan 3. Kami merekodkannya Masa, masa untuk mengeluarkan jawapan keseluruhan adalah kira-kira 15 saat.
Tetapi ini hanya kesan keluaran Claude 3 Sonnet Jika anda menggunakan versi Claude Pro, ia akan menjadi lebih pantas, tetapi ia akan menelan kos $20 sebulan. . mencadangkan bahawa keupayaan pengekodan model baharu dipertingkatkan dengan ketara, seseorang terus melemparkan kod ASCII asas kepada Claude dan mendapati ia tidak mempunyai tekanan:
Kita sepatutnya dapat mengesahkan bahawa Claude 3 mempunyai keupayaan pengekodan yang lebih kuat daripada GPT-4.
 Beberapa masa lalu, Karpathy, yang baru sahaja meletak jawatan daripada OpenAI, mencadangkan cabaran "pembahagian perkataan". Secara khusus, dia meletakkan video tutorial 2 jam 13 minit ke dalam LLM dan telah diterjemahkan ke dalam format bab buku atau catatan blog tentang tokenizer.
Beberapa masa lalu, Karpathy, yang baru sahaja meletak jawatan daripada OpenAI, mencadangkan cabaran "pembahagian perkataan". Secara khusus, dia meletakkan video tutorial 2 jam 13 minit ke dalam LLM dan telah diterjemahkan ke dalam format bab buku atau catatan blog tentang tokenizer.
Faced dengan tugas ini, Claude 3 mengambilnya. Karpathy memberikan penilaian yang agak lengkap dan objektif:
Sekiranya ada apa-apa yang berkaitan saya ingin katakan, orang ramai harus berhati-hati apabila membuat perbandingan penilaian, bukan sahaja kerana keputusan penilaian itu sendiri lebih buruk daripada yang anda fikirkan, tetapi juga kerana banyak keputusan penilaian berakhir dengan Ia terlalu lengkap dalam cara yang tidak ditentukan, juga kerana perbandingan yang dibuat mungkin mengelirukan. Kadar pengekodan (HumanEval) GPT-4 bukan 67%. Setiap kali saya melihat perbandingan ini digunakan sebagai ganti prestasi pengekodan, tubir mata saya mula berkedut.
Berdasarkan pelbagai keputusan ujian rumit di atas, ada yang sudah menjerit "Anthropic is so back".
Akhirnya, antropopik juga melancarkan perpustakaan segera yang mengandungi kandungan segera dalam pelbagai arah. Jika anda ingin mengetahui lebih lanjut tentang ciri baharu Claude 3, cubalah.
Pautan: https://docs.anthropic.com/claude/prompt-library
Claude 3 Series Models
Tiga versi model Claude 3 Series ialah Claude 3 Opus, Claude 3 dan Claude 3 Haiku.
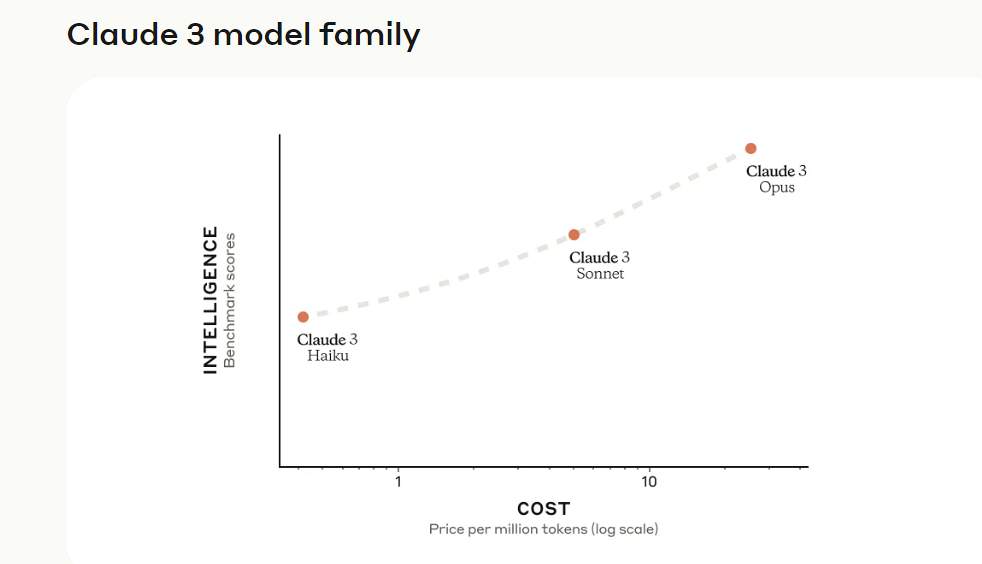
Antaranya, Claude 3 Opus ialah model paling pintar, menyokong tetingkap konteks token 200k dan mencapai prestasi SOTA semasa pada tugas yang sangat kompleks. Model ini mengendalikan gesaan terbuka dan adegan ghaib dengan kefasihan yang sangat baik dan pemahaman peringkat manusia. Claude 3 Opus menunjukkan kepada kita had apa yang mungkin dengan AI generatif.

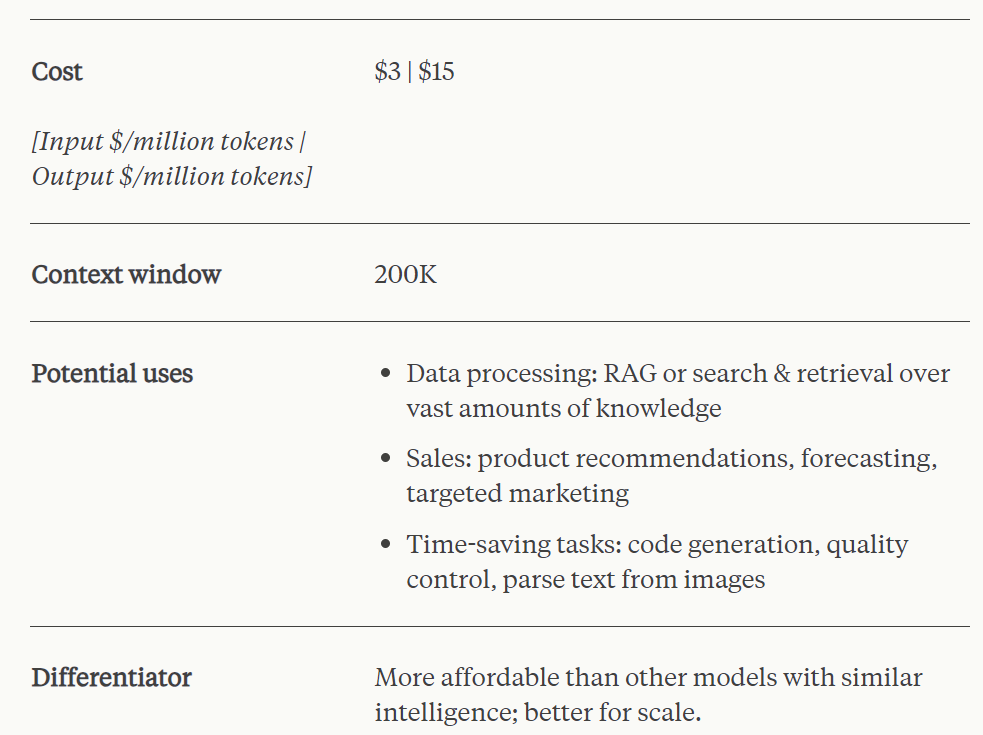
Claude 3 Sonnet menawarkan keseimbangan ideal antara kecerdasan dan kelajuan, terutamanya untuk beban kerja perusahaan. Ia memberikan prestasi berkuasa pada kos yang lebih rendah daripada model yang serupa dan direka bentuk untuk ketahanan tinggi dalam penggunaan AI berskala besar. Claude 3 Sonnet menyokong tetingkap konteks sebanyak 200k token.
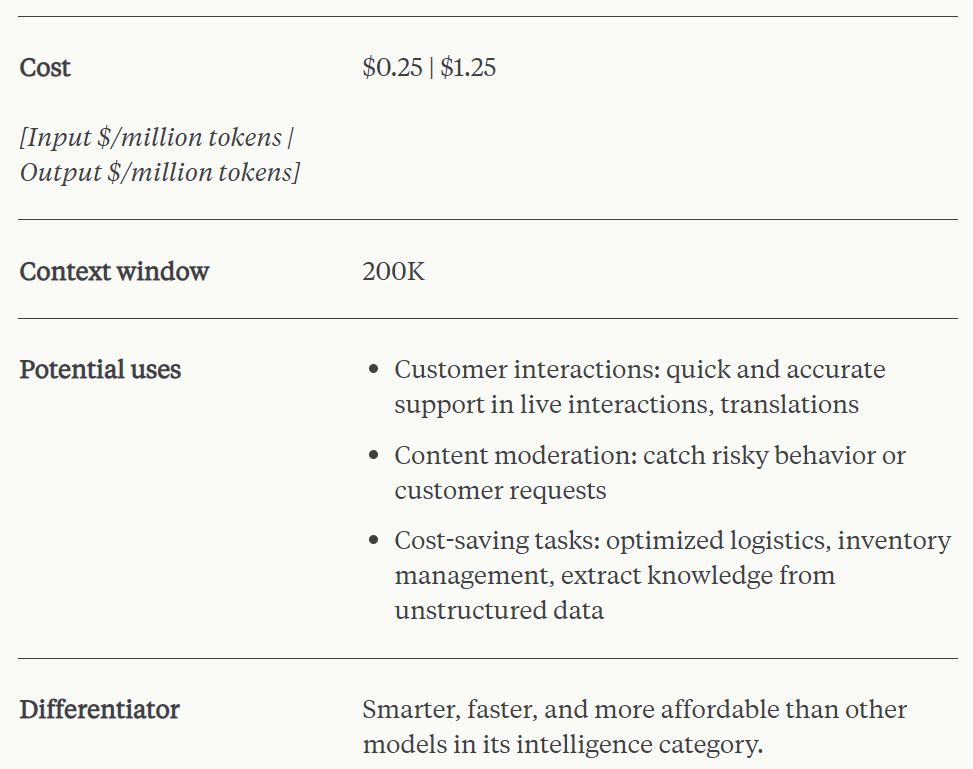
Claude 3 Haiku ialah model terpantas dan paling padat dengan responsif hampir masa nyata. Menariknya, tetingkap konteks yang disokongnya juga 200k. Model ini mampu menjawab pertanyaan dan permintaan mudah pada kelajuan yang tiada tandingan, membolehkan pengguna membina pengalaman AI yang lancar yang meniru interaksi manusia.
Seterusnya, mari kita lihat secara terperinci ciri dan prestasi model siri Claude 3.
Melebihi GPT-4 secara menyeluruh dan mencapai tahap kecerdasan SOTA baharu
Sebagai model paling pintar dalam siri Claude 3, Opus mengatasi produk pesaing pada kebanyakan penanda aras penilaian sistem pakar peringkat ijazah pertama AI, termasuk (MMLU), Penaakulan Pakar Peringkat Siswazah (GPQA), Matematik Asas (GSM8K) dan penanda aras lain. Lebih-lebih lagi, Opus menunjukkan pemahaman dan kelancaran hampir peringkat manusia dalam tugas yang kompleks, memimpin sempadan kecerdasan am.
Selain itu, semua model Claude 3 Series, termasuk Opus, menampilkan keupayaan yang dipertingkatkan dalam analitis dan ramalan, penciptaan kandungan berbutir, penjanaan kod dan perbualan dalam bahasa bukan Inggeris seperti Sepanyol, Jepun dan Perancis.
Gambar di bawah menunjukkan perbandingan antara model Claude 3 dan model bersaing pada pelbagai penanda aras prestasi Ia boleh dilihat bahawa Opus terkuat adalah lebih baik daripada GPT-4 OpenAI.
Hampir respons masa nyata
Model Claude 3 boleh menyokong tugas seperti sembang pelanggan secara langsung, pengisian semula automatik dan pengekstrakan data di mana respons mestilah segera dan masa nyata
Haiku adalah model terpantas dan paling kos efektif di pasaran dalam kategori pintar. Ia boleh membaca kertas platform arXiv (~10k token) yang mengandungi carta padat dan maklumat grafik dalam masa kurang daripada tiga saat.
Untuk sebahagian besar pekerjaan, Sonnet adalah 2x lebih pantas dan lebih pintar daripada Claude 2 dan Claude 2.1. Ia cemerlang dalam tugas yang memerlukan respons pantas, seperti mendapatkan semula pengetahuan atau automasi jualan. Opus adalah serupa dalam kelajuan dengan Claude 2 dan 2.1, tetapi dengan tahap kecerdasan yang lebih tinggi.
Keupayaan visual yang berkuasa
Claude 3 mempunyai keupayaan visual yang canggih setanding dengan model kepala yang lain. Mereka boleh memproses data dalam pelbagai format visual, termasuk foto, carta, graf dan gambar rajah teknikal.
Anthropic mengatakan bahawa sesetengah pelanggan mereka mempunyai lebih daripada 50% pangkalan pengetahuan mereka yang diprogramkan dalam pelbagai format data, seperti PDF, carta alir atau slaid pembentangan. Oleh itu, keupayaan visual berkuasa model baharu ini sangat membantu.
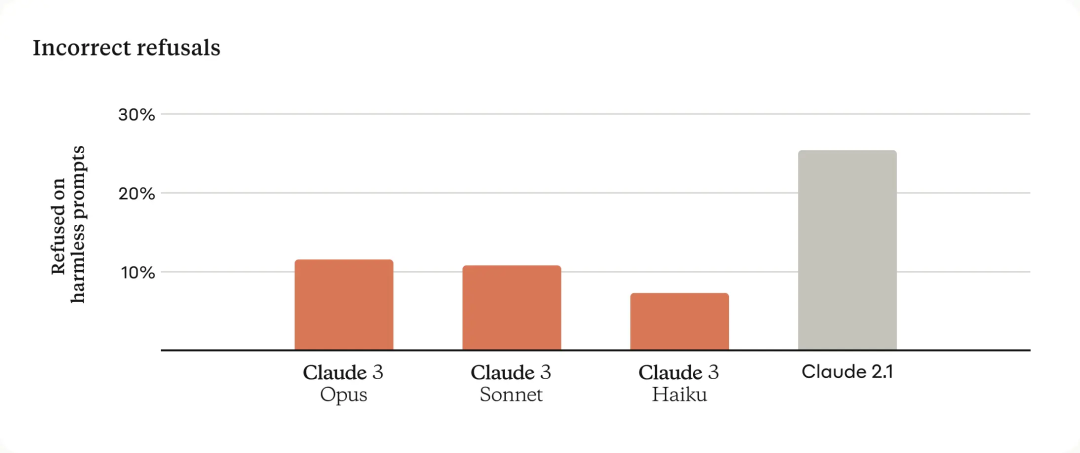
Sedikit balasan penolakan
Model Claude sebelumnya sering membuat penolakan yang tidak perlu, menunjukkan kekurangan pemahaman kontekstual oleh model tersebut. Anthropic telah mencapai kemajuan yang bermakna dalam bidang ini: Opus, Sonnet dan Haiku secara ketara kurang berkemungkinan menolak jawapan berbanding model generasi sebelumnya, walaupun apabila gesaan pengguna hampir dengan garis bawah sistem. Seperti yang ditunjukkan di bawah, model Claude 3 mempamerkan pemahaman yang lebih bernuansa tentang permintaan, dapat mengenal pasti gesaan yang benar-benar berbahaya dan enggan menjawab gesaan yang tidak berbahaya dengan lebih jarang.
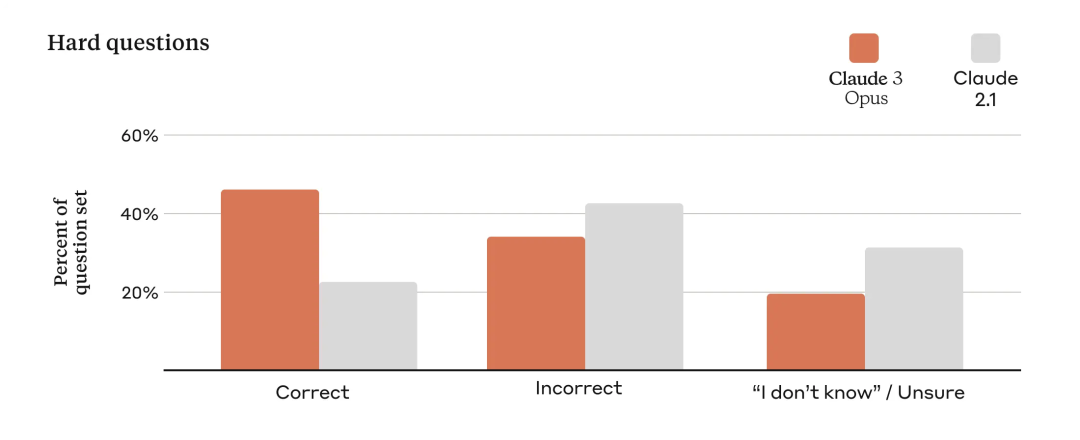
Meningkatkan Ketepatan
Untuk menilai ketepatan model, Anthropic menggunakan beberapa soalan berasaskan fakta yang kompleks untuk menangani kelemahan yang diketahui dalam model semasa. Anthropic mengelaskan jawapan kepada jawapan yang betul, jawapan yang salah (atau halusinasi), dan jawapan yang tidak pasti, di mana model tidak mengetahui jawapannya, dan bukannya memberikan maklumat yang salah. Berbanding dengan Claude 2.1, Opus menggandakan ketepatan (atau jawapan yang betul) pada soalan terbuka yang mencabar ini sambil mengurangkan jawapan yang salah.
Selain menghasilkan respons yang lebih boleh dipercayai, Anthropic akan mendayakan petikan dalam model Claude 3 supaya model itu boleh menunjuk kepada ayat yang tepat dalam bahan rujukan untuk mengesahkan respons.
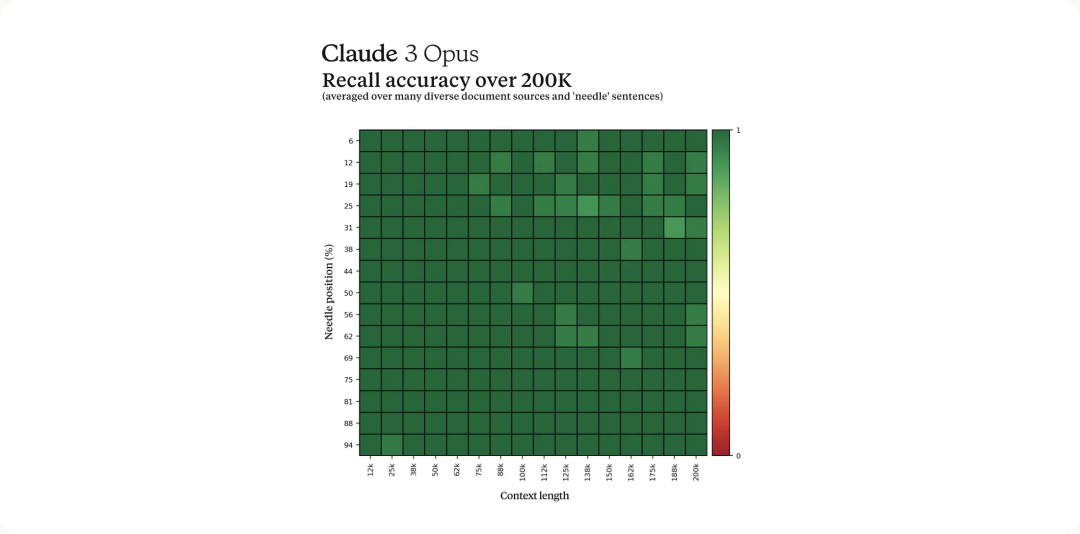
Konteks panjang dan ingatan hampir sempurna
Model siri Claude 3 pada mulanya akan menawarkan tetingkap konteks 200K semasa pelancaran. Walau bagaimanapun, pegawai menyatakan bahawa ketiga-tiga model mampu menerima input lebih daripada 1 juta token, dan keupayaan ini akan diberikan kepada pengguna tertentu yang memerlukan keupayaan pemprosesan yang dipertingkatkan.
Untuk mengendalikan isyarat kontekstual yang panjang dengan berkesan, model memerlukan keupayaan mengingat yang kuat. Penilaian Needle In A Haystack (NIAH) mengukur keupayaan model untuk mengingati maklumat dengan tepat daripada sejumlah besar data. Anthropic meningkatkan keteguhan penanda aras ini dengan mengujinya pada asas dokumen sumber ramai yang berbeza menggunakan 30 pasangan Jarum/soalan rawak dalam setiap gesaan. Claude 3 Opus bukan sahaja mencapai ingatan hampir sempurna tetapi juga melebihi ketepatan 99%. Dan dalam beberapa kes, ia juga mengenal pasti batasan dalam penilaian itu sendiri, menyedari bahawa ayat "jarum" nampaknya telah dimasukkan secara buatan ke dalam teks asal.
Selamat dan mudah digunakan
Anthropic berkata ia telah menubuhkan pasukan khusus untuk menjejak dan mengurangkan risiko keselamatan. Syarikat itu juga sedang membangunkan kaedah seperti AI Perlembagaan untuk meningkatkan keselamatan dan ketelusan model serta mengurangkan kebimbangan privasi yang mungkin ditimbulkan oleh model baharu.
Walaupun siri model Claude 3 telah membuat penambahbaikan dalam penunjuk utama pengetahuan biologi, pengetahuan berkaitan rangkaian dan autonomi berbanding model sebelumnya, menurut penyelidikan, model baharu itu berada di Tahap Keselamatan AI 2 (ASL-2) Dalam .
Dari segi pengalaman pengguna, Claude 3 lebih baik mengikut arahan berbilang langkah yang kompleks berbanding model sebelumnya, dan lebih mampu mematuhi garis panduan jenama dan tindak balas, supaya ia boleh membangunkan aplikasi yang boleh dipercayai dengan lebih baik. Selain itu, Anthropic berkata model Claude 3 kini lebih baik dalam menghasilkan output berstruktur popular dalam format seperti JSON, menjadikannya lebih mudah untuk membimbing Claude untuk kes penggunaan seperti klasifikasi bahasa semula jadi dan analisis sentimen.
Apa yang tertulis dalam laporan teknikal
Pada masa ini, Anthropic telah mengeluarkan laporan teknikal 42 muka surat "The Claude 3 Model Family: Opus, Sonnet, Haiku".

Alamat laporan: https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf siri
siri Claude_3.pdfkriteria penilaian, dan keputusan eksperimen yang lebih terperinci .
Dari segi data latihan, model siri Claude 3 dilatih pada gabungan proprietari data yang tersedia secara umum di Internet setakat Ogos 2023, serta data bukan awam daripada pihak ketiga, data yang disediakan oleh penyedia perkhidmatan pelabelan data dan kontraktor berbayar , data dalaman Claude.
Model Claude 3 Series telah dinilai secara meluas pada pelbagai metrik termasuk: 语Keupayaan penaakulan 言 Kebolehan berbilang bahasa
- konteks panjang
- kebolehpercayaan/ fakta
- Keupayaan pelbagai mod
- Pertama sekali, dalam A dan Aturcara hasil penilaian, model siri Claude 3 dibandingkan dengan model bersaing pada satu siri penanda aras standard industri untuk penaakulan, pemahaman bacaan, matematik, sains dan pengaturcaraan Hasilnya menunjukkan bahawa mereka bukan sahaja mengatasi model sebelumnya, tetapi juga mencapainya dalam kebanyakan kes SOTA Baharu.
Model Claude 3 Series yang dinilai antropik pada Ujian Kemasukan Sekolah Undang-Undang (LSAT), Peperiksaan Bar Berbilang Negeri (MBE), Pertandingan Matematik Amerika Syarikat 2023, dan Peperiksaan Rekod Siswazah (GRE), khususnya Peperiksaan Am keputusan ditunjukkan dalam Jadual 2 di bawah.
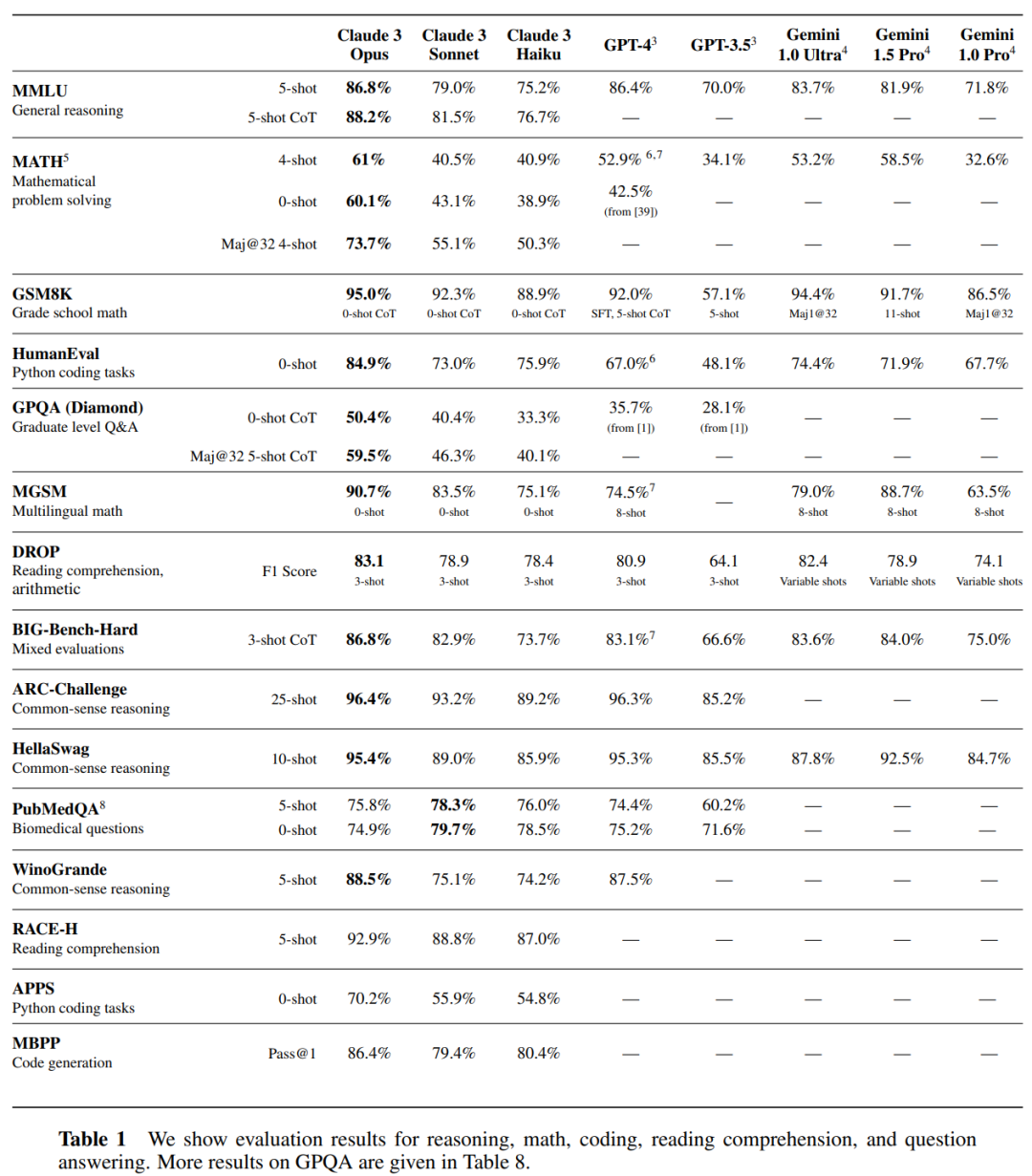
Model siri Claude 3 berkeupayaan berbilang modal (input bingkai imej dan video) dan telah mencapai kemajuan yang ketara dalam menyelesaikan cabaran penaakulan pelbagai mod yang kompleks melangkaui pemahaman teks mudah.
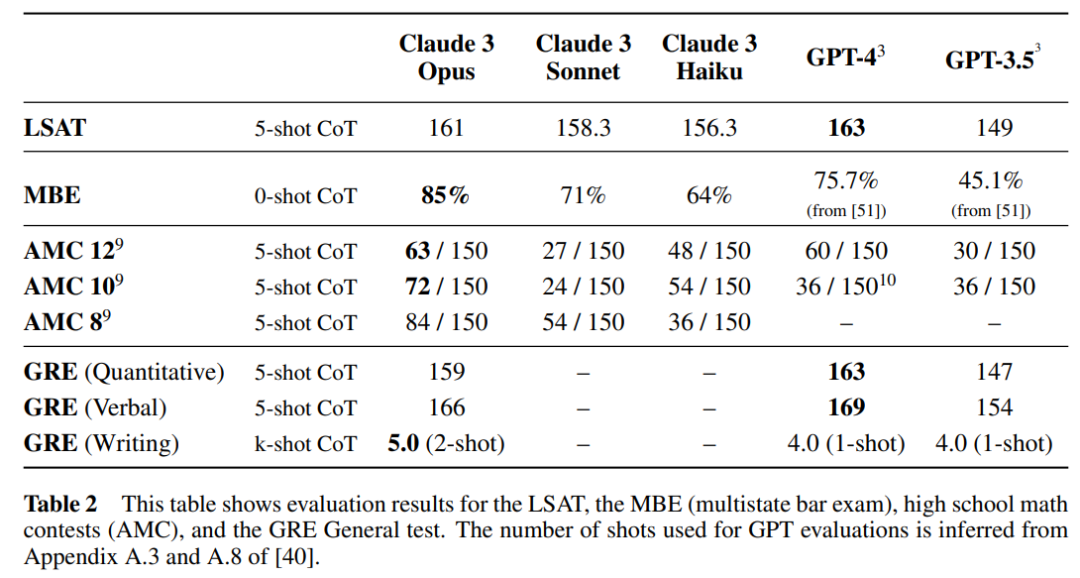
Claude 3 Sonnet mencapai tahap SOTA dalam tetapan 0-shot - 89.2%, diikuti oleh Claude 3 Opus (88.3%) dan Claude 3 Haiku (80.6%) Keputusan khusus ditunjukkan dalam Jadual 3 di bawah.
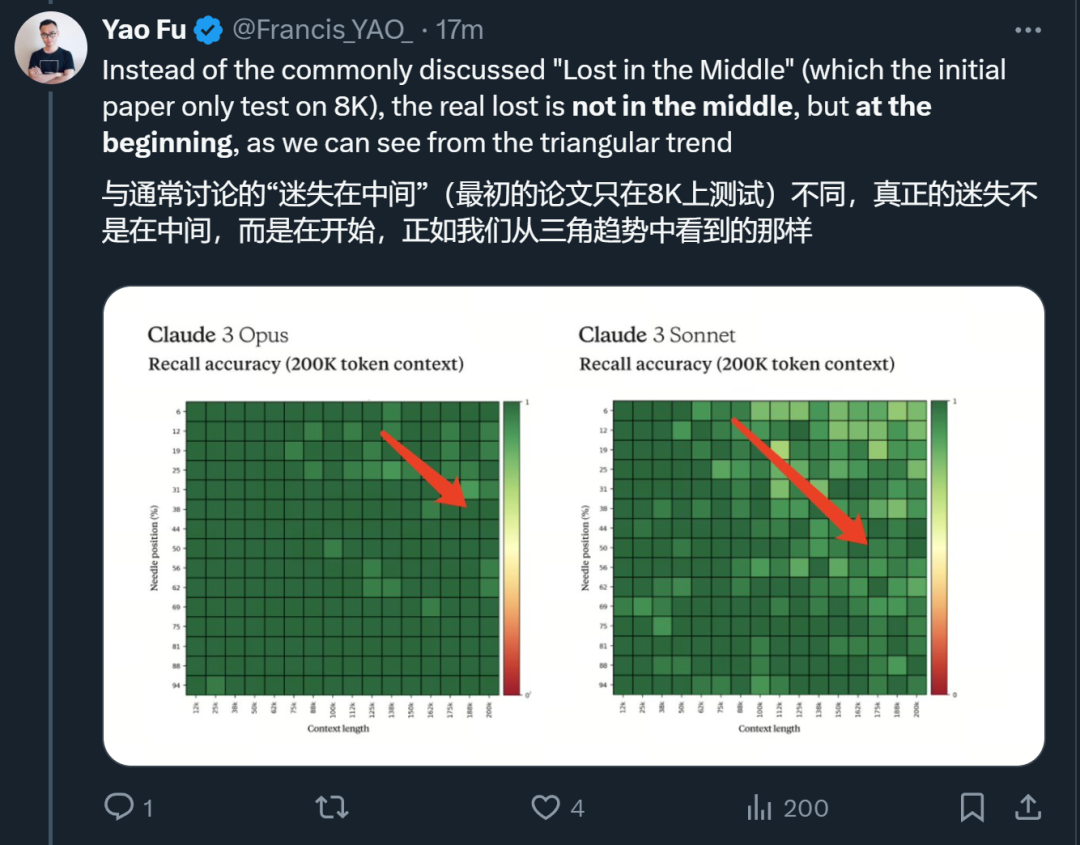
Berkenaan laporan teknikal ini, Fu Yao, pelajar kedoktoran di Universiti Edinburgh, memberikan analisisnya sendiri serta-merta. 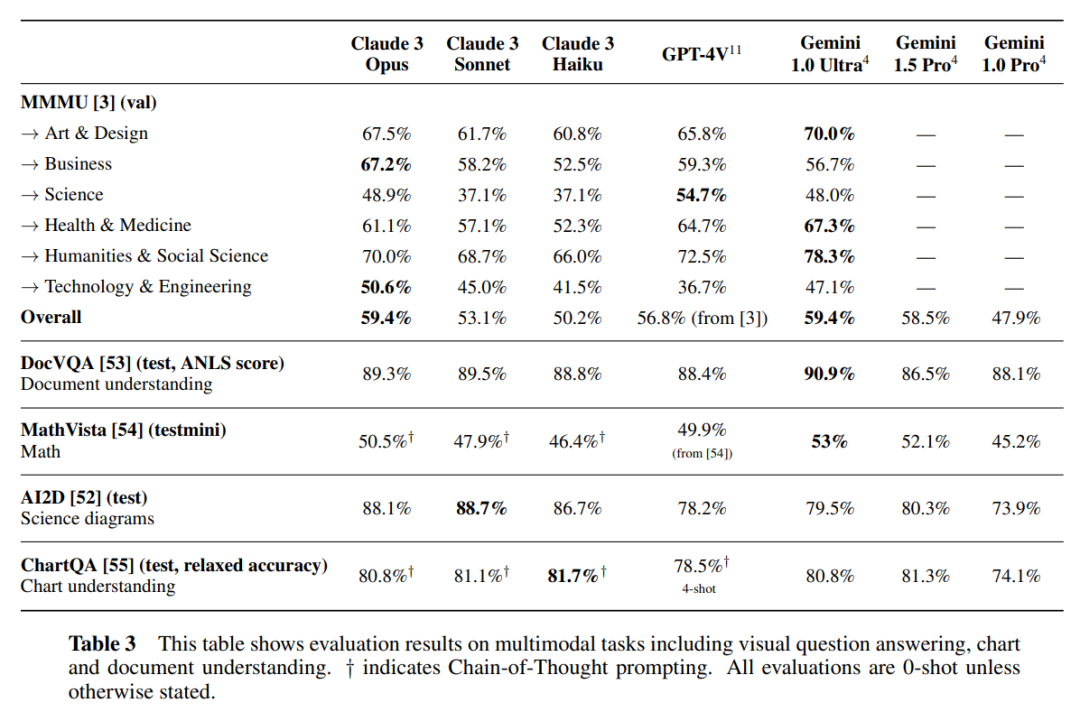
Dia percaya bahawa apa yang benar-benar boleh membezakan model itu ialah MATH dan GPQA Masalah yang sangat berduri ini adalah matlamat yang harus disasarkan oleh model AI.
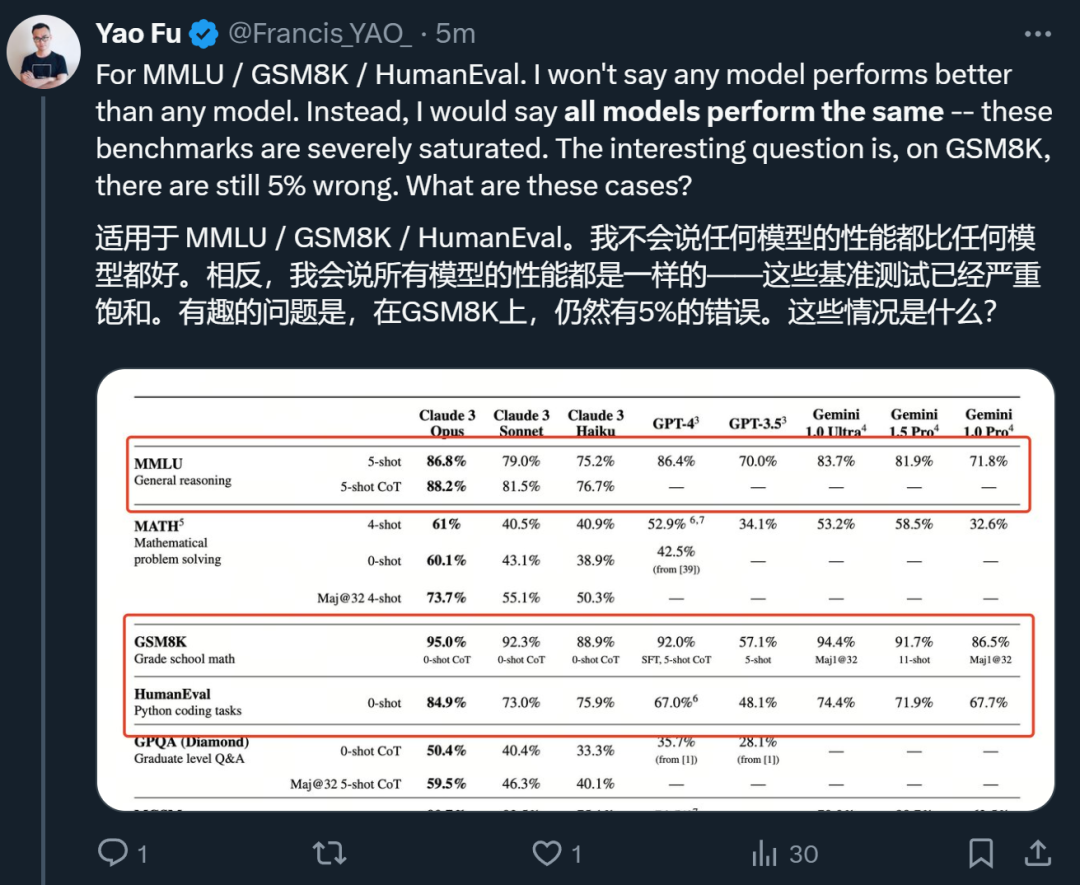
Berbanding dengan model Claude sebelum ini, bidang yang lebih baik adalah kewangan dan perubatan.
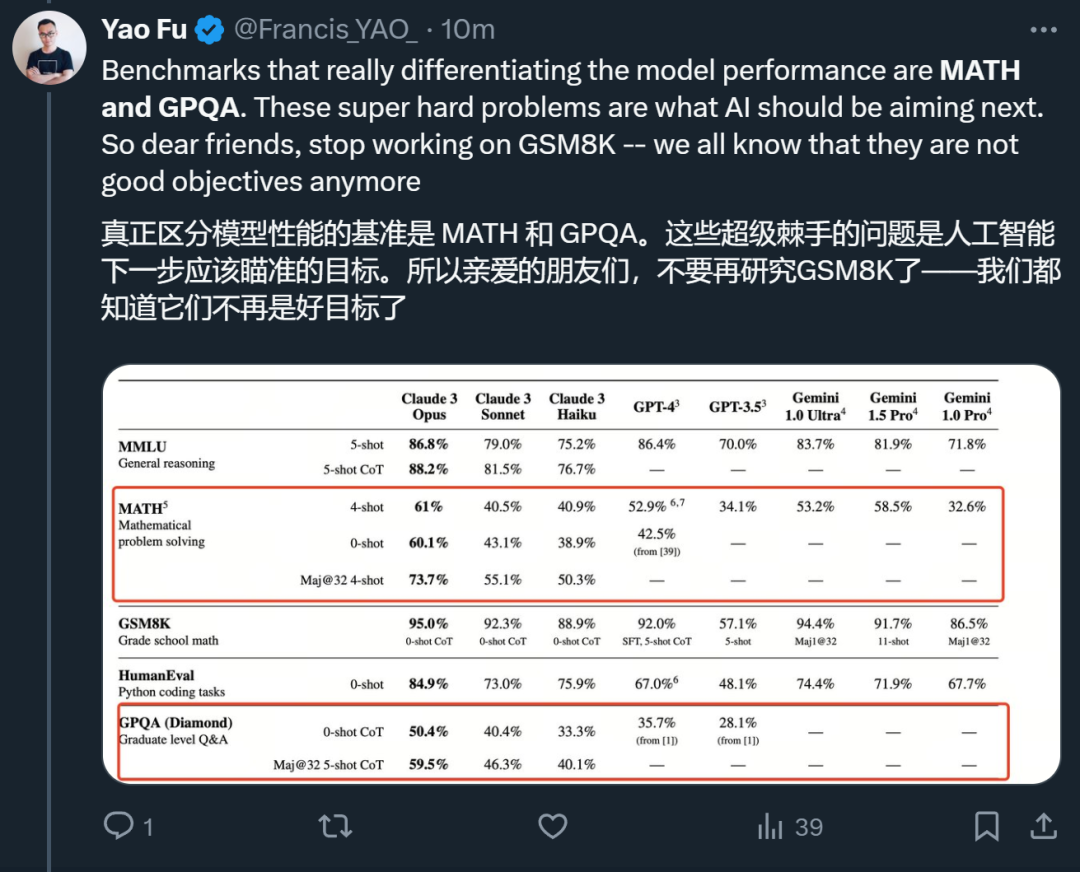
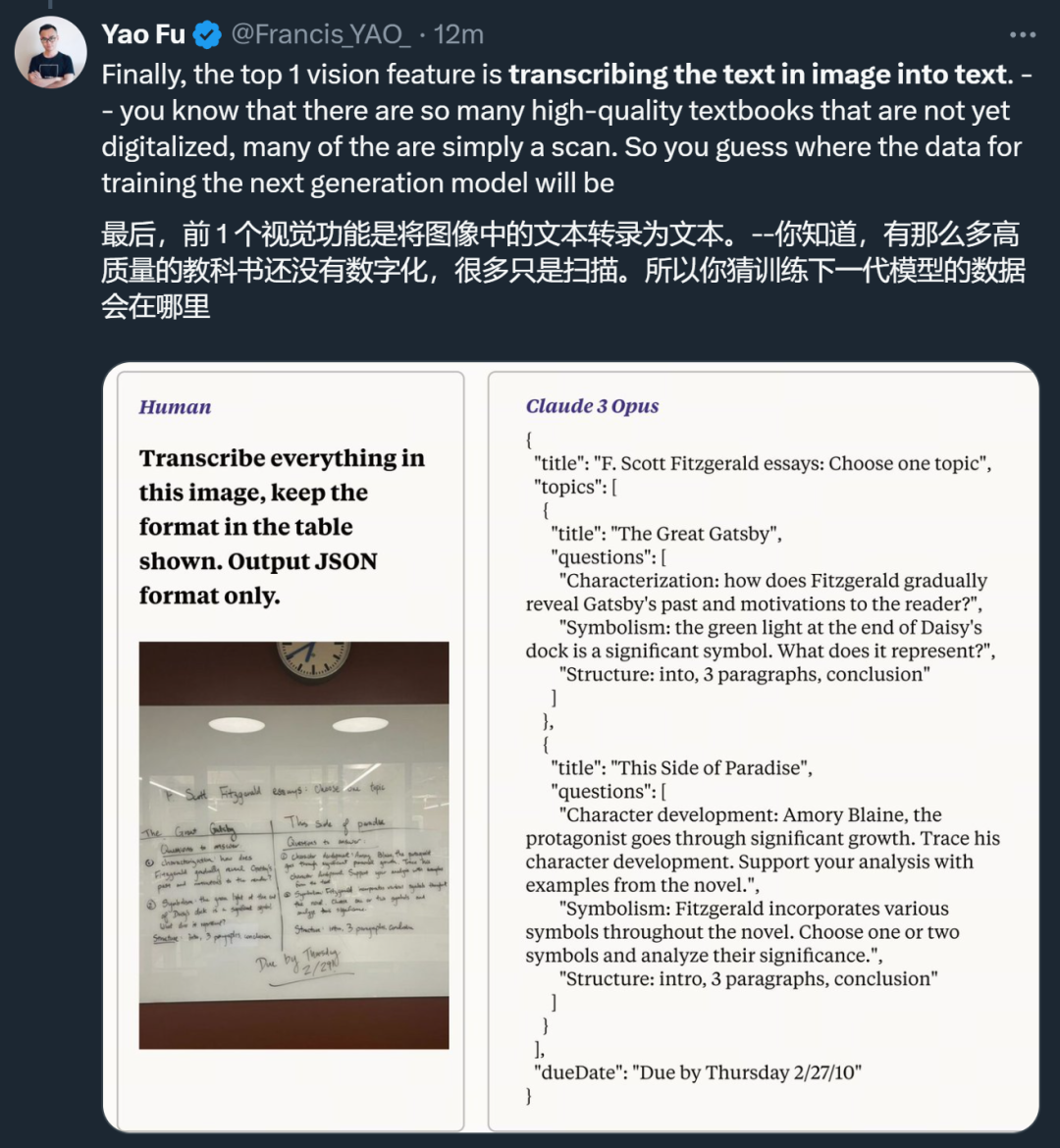
Dari segi penglihatan, keupayaan OCR visual Claude 3 membuatkan orang ramai melihat potensi besarnya dalam pengumpulan data. 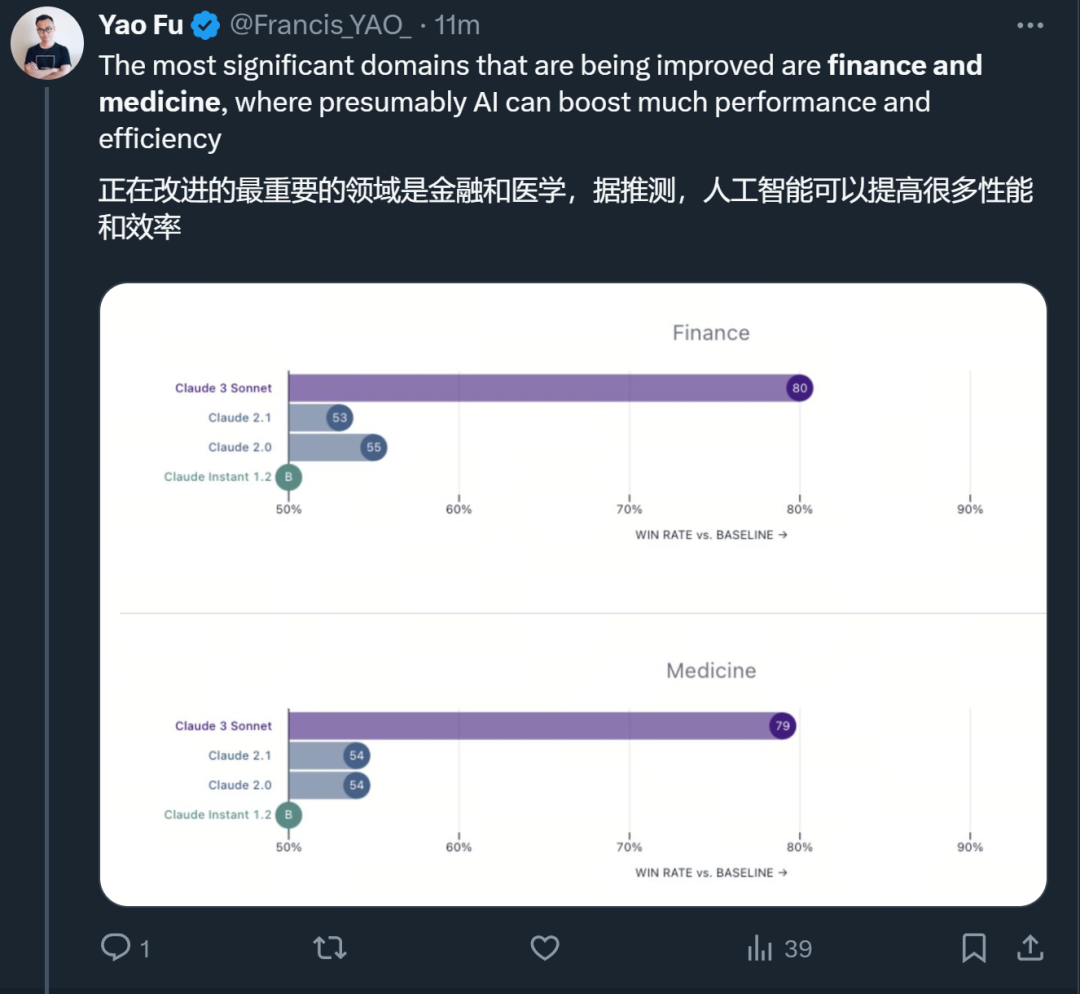
Selain itu, dia juga menemui beberapa trend lain:
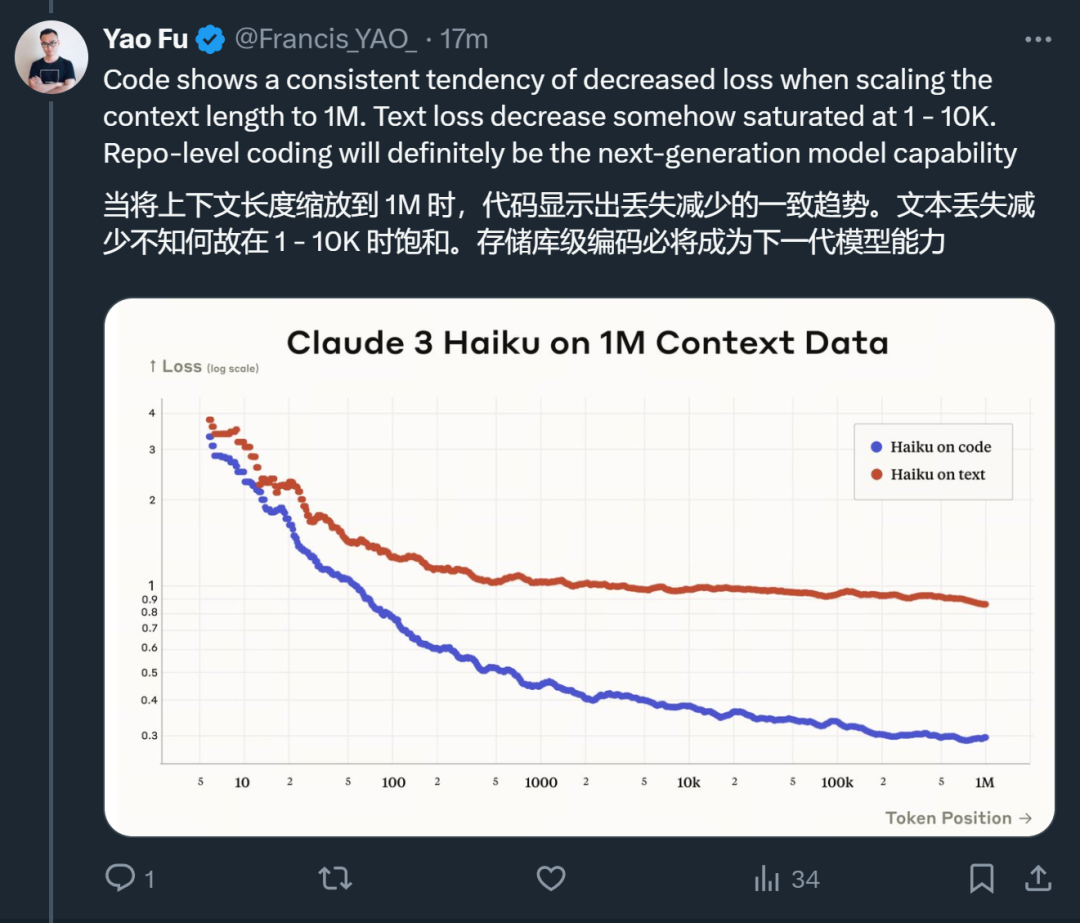
 Alamat blog: https://www.anthropic.com/news/claude-3-family
Alamat blog: https://www.anthropic.com/news/claude-3-family
Atas ialah kandungan terperinci Adakah era GPT-4 sudah berakhir? Netizen di seluruh dunia menguji Claude 3 dan terkejut. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!