
Rumah >Peranti teknologi >AI >Ketua Pegawai Eksekutif DeepMind: LLM+tree search ialah rangkaian teknologi AGI yang bergantung pada keupayaan kejuruteraan Model sumber tertutup adalah lebih selamat daripada model sumber terbuka.
Ketua Pegawai Eksekutif DeepMind: LLM+tree search ialah rangkaian teknologi AGI yang bergantung pada keupayaan kejuruteraan Model sumber tertutup adalah lebih selamat daripada model sumber terbuka.

- PHPzke hadapan
- 2024-03-05 12:04:18458semak imbas
Google tiba-tiba bertukar kepada mod 996 selepas Februari, melancarkan 5 model dalam masa kurang daripada sebulan.
Dan CEO DeepMind Hassabis sendiri juga telah mempromosikan platform produknya sendiri, mendedahkan banyak maklumat dalaman pembangunan di sebalik tabir.
Pada pandangannya, walaupun penemuan teknologi masih diperlukan, jalan menuju AGI untuk manusia kini telah muncul.
Penggabungan DeepMind dan Google Brain menandakan bahawa pembangunan teknologi AI telah memasuki era baharu.
S: DeepMind sentiasa berada di barisan hadapan dalam teknologi. Sebagai contoh, dalam sistem seperti AlphaZero, ejen pintar dalaman boleh mencapai matlamat akhir melalui satu siri pemikiran. Adakah ini bermakna model bahasa besar (LLM) juga boleh menyertai peringkat penyelidikan jenis ini?
Hassabis percaya bahawa model berskala besar mempunyai potensi besar dan perlu dioptimumkan lagi untuk meningkatkan ketepatan ramalan mereka dan seterusnya membina model dunia yang lebih dipercayai. Walaupun langkah ini penting, ia mungkin tidak mencukupi untuk membina sistem kecerdasan am buatan (AGI) yang lengkap.
Atas dasar ini, kami sedang membangunkan mekanisme perancangan yang serupa dengan AlphaZero untuk merangka rancangan untuk mencapai matlamat dunia tertentu melalui model dunia.
Ini termasuk menyusun rangkaian pemikiran atau penaakulan yang berbeza, atau menggunakan carian pokok untuk meneroka ruang kemungkinan yang luas.
Ini adalah pautan yang hilang dalam model besar semasa kami.
S: Bermula daripada kaedah pembelajaran tetulang tulen (RL), adakah mungkin untuk beralih terus ke AGI?
Nampaknya model bahasa yang besar akan membentuk pengetahuan sedia ada asas, dan kemudian kajian lanjut boleh dijalankan atas dasar ini.
Secara teorinya, adalah mungkin untuk menggunakan sepenuhnya kaedah membangunkan AlphaZero.
Sesetengah orang dalam DeepMind dan komuniti RL berusaha ke arah ini Mereka bermula dari awal dan tidak bergantung pada sebarang pengetahuan atau data terdahulu untuk membina sistem pengetahuan baharu sepenuhnya.
Saya percaya bahawa memanfaatkan pengetahuan dunia sedia ada - seperti maklumat di web dan data yang telah kami kumpulkan - akan menjadi cara terpantas untuk mencapai AGI.
Kami kini mempunyai algoritma berskala - Transformer - yang boleh menyerap maklumat ini Kami boleh menggunakan sepenuhnya model sedia ada ini sebagai pengetahuan sedia ada untuk ramalan dan pembelajaran.
Oleh itu, saya percaya bahawa sistem AGI akhir pasti akan memasukkan model besar hari ini sebagai sebahagian daripada penyelesaian.
Tetapi model besar sahaja tidak mencukupi, kita juga perlu menambah lebih banyak perancangan dan keupayaan carian kepadanya.
S: Menghadapi sumber pengkomputeran yang besar yang diperlukan oleh kaedah ini, bagaimanakah kita boleh membuat satu kejayaan?
Malah sistem seperti AlphaGo agak mahal kerana keperluan untuk melakukan pengiraan pada setiap nod pepohon keputusan.
Kami komited untuk membangunkan kaedah dan strategi cekap sampel untuk menggunakan semula data sedia ada, seperti main semula pengalaman, serta meneroka kaedah yang lebih cekap.
Malah, jika model dunia cukup bagus, pencarian anda boleh menjadi lebih cekap.
Ambil Alpha Zero sebagai contoh prestasinya dalam permainan seperti Go dan catur melebihi tahap kejohanan dunia, tetapi julat cariannya jauh lebih kecil daripada kaedah carian brute force tradisional.
Ini menunjukkan bahawa penambahbaikan model boleh menjadikan carian lebih cekap dan seterusnya mencapai sasaran selanjutnya.
Tetapi apabila menentukan fungsi dan matlamat ganjaran, bagaimana untuk memastikan sistem berkembang ke arah yang betul akan menjadi salah satu cabaran yang kita hadapi.
Kenapa Google boleh menghasilkan 5 model dalam masa setengah bulan?
S: Bolehkah anda bercakap tentang sebab Google dan DeepMind mengusahakan begitu banyak model yang berbeza pada masa yang sama?
Oleh kerana kami telah menjalankan penyelidikan asas, kami mempunyai sejumlah besar kerja penyelidikan asas yang meliputi pelbagai inovasi dan hala tuju yang berbeza.
Ini bermakna semasa kami membina trek model utama - model teras Gemini, terdapat juga banyak lagi projek penerokaan sedang dijalankan.
Apabila projek penerokaan ini mempunyai beberapa hasil, kami akan menggabungkannya ke dalam cawangan utama ke dalam versi Gemini yang seterusnya, itulah sebabnya anda akan melihat 1.5 dikeluarkan serta-merta selepas 1.0, kerana kami sedang mengusahakan versi seterusnya Ya, kerana kami mempunyai beberapa pasukan yang bekerja pada skala masa yang berbeza, berbasikal antara satu sama lain, itulah cara kami boleh terus bertambah baik.
Saya harap ini akan menjadi kebiasaan baharu kami, mengeluarkan produk pada kadar yang tinggi ini, tetapi sudah tentu, sambil juga sangat bertanggungjawab, perlu diingat bahawa mengeluarkan model selamat adalah keutamaan nombor satu kami.
S: Saya ingin bertanya tentang keluaran besar terbaharu anda, Gemini 1.5 Pro, model Gemini Pro 1.5 baharu anda boleh mengendalikan sehingga satu juta token. Bolehkah anda menerangkan maksud ini dan mengapa tetingkap konteks merupakan penunjuk teknikal yang penting?
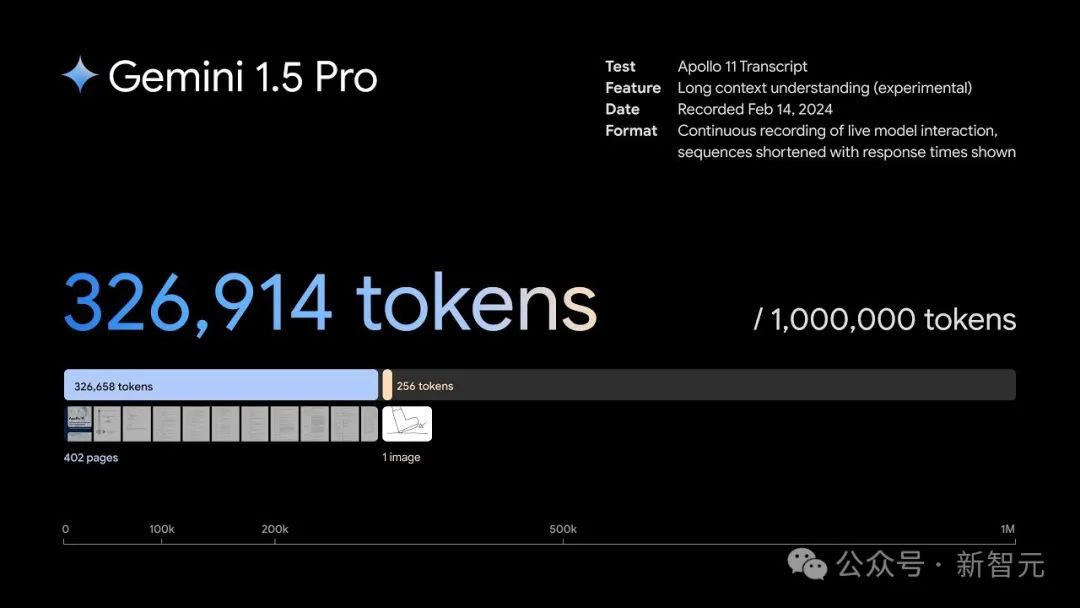
Ya, ini sangat penting. Konteks yang panjang boleh dianggap sebagai memori kerja model, iaitu berapa banyak data yang boleh diingati dan diproses pada satu masa.
Semakin lama konteks yang anda miliki, ketepatannya juga penting, ketepatan mengingat kembali perkara dari konteks yang panjang adalah sama penting, semakin banyak data dan konteks yang boleh anda ambil kira.
Jadi, satu juta bermakna anda boleh mengendalikan buku besar, filem penuh, banyak kandungan audio, seperti pangkalan kod penuh.
Jika anda mempunyai tetingkap konteks yang lebih pendek, katakan hanya seratus ribu tahap, maka anda hanya boleh memproses serpihannya dan model tidak boleh menaakul atau mendapatkan semula keseluruhan korpus yang anda minati.
Jadi ini sebenarnya membuka kemungkinan untuk semua jenis kes penggunaan baharu yang tidak boleh dilakukan dengan konteks kecil.
S: Saya pernah mendengar daripada penyelidik AI bahawa masalah dengan tetingkap konteks yang besar ini ialah ia sangat intensif dari segi pengiraan. Contohnya, jika anda memuat naik keseluruhan filem atau buku teks biologi dan bertanya soalan mengenainya, ia memerlukan lebih kuasa pemprosesan untuk memproses semua itu dan bertindak balas. Jika ramai orang melakukan ini, kos boleh ditambah dengan cepat. Adakah Google DeepMind menghasilkan beberapa inovasi pintar untuk menjadikan tetingkap konteks yang besar ini lebih cekap, atau adakah Google hanya menanggung kos semua pengiraan tambahan ini?
Ya, ini adalah inovasi baharu kerana tanpa inovasi anda tidak boleh mempunyai konteks yang begitu panjang.
Tetapi ini masih memerlukan kos pengiraan yang tinggi, jadi kami berusaha keras untuk mengoptimumkannya.
Jika anda mengisi keseluruhan tetingkap konteks. Pemprosesan awal data yang dimuat naik mungkin mengambil masa beberapa minit.
Tetapi tidak terlalu buruk jika anda menganggap bahawa ia seperti menonton keseluruhan filem atau membaca keseluruhan Perang dan Keamanan dalam satu atau dua minit dan kemudian anda akan dapat menjawab sebarang soalan yang anda ada tentangnya.
Maka perkara yang ingin kami pastikan ialah sebaik sahaja anda memuat naik dan mengerjakan dokumen, video atau audio, soalan dan jawapan yang berikutnya hendaklah lebih pantas.
Inilah yang sedang kami usahakan dan kami amat yakin bahawa kami boleh menyelesaikannya dalam beberapa saat sahaja.
S: Anda berkata anda telah menguji sistem dengan sehingga 10 juta token. Bagaimanakah kesannya?
Berfungsi dengan baik dalam ujian kami. Oleh kerana kos pengkomputeran masih agak tinggi, perkhidmatan itu tidak tersedia pada masa ini.
Tetapi dari segi ketepatan dan ingatan, ia berfungsi dengan sangat baik.
S: Saya ingin bertanya kepada anda tentang Gemini Apakah perkara istimewa yang boleh Gemini lakukan yang tidak dapat dilakukan oleh model bahasa Google atau model lain?
Nah, saya rasa apa yang menarik tentang Gemini, terutamanya versi 1.5, ialah ia sememangnya berbilang modal dan kami membinanya dari bawah untuk dapat mengendalikan sebarang jenis input: teks, imej, kod, video .
Jika anda menggabungkannya dengan konteks yang panjang, anda boleh melihat potensinya. Sebagai contoh, anda boleh bayangkan bahawa anda sedang mendengar keseluruhan syarahan, atau terdapat konsep penting yang anda ingin fahami dan anda ingin teruskan ke sana.
Jadi sekarang kita boleh meletakkan keseluruhan pangkalan kod ke dalam tetingkap konteks, yang sangat berguna untuk pengaturcara baharu bermula. Katakan anda seorang jurutera baharu yang mula bekerja pada hari Isnin Biasanya anda mempunyai ratusan ribu baris kod untuk dilihat.
Anda perlu bertanya kepada pakar mengenai asas kod. Tetapi kini anda sebenarnya boleh menggunakan Gemini sebagai pembantu pengekodan, dengan cara yang menyeronokkan ini. Ia akan mengembalikan beberapa ringkasan yang memberitahu anda di mana bahagian penting kod itu, dan anda boleh mula bekerja.
Saya rasa memiliki keupayaan ini sangat membantu dan menjadikan aliran kerja harian anda lebih cekap.
Saya sangat tidak sabar untuk melihat prestasi Gemini apabila disepadukan ke dalam sesuatu seperti slack dan aliran kerja am anda. Apakah rupa aliran kerja masa hadapan? Saya rasa kita baru mula mengalami perubahan.
Keutamaan Google untuk sumber terbuka ialah keselamatan
S: Saya ingin beralih sekarang kepada Gemma, satu siri model sumber terbuka ringan yang baru anda keluarkan. Hari ini, sama ada untuk mengeluarkan model asas melalui sumber terbuka, atau menutupnya, nampaknya menjadi salah satu topik yang paling kontroversi. Sehingga kini, Google telah mengekalkan model asasnya dengan sumber tertutup. Mengapa memilih sumber terbuka sekarang? Apakah pendapat anda tentang kritikan yang menjadikan model asas tersedia melalui sumber terbuka meningkatkan risiko dan kemungkinan ia akan digunakan oleh pelakon yang berniat jahat?
Ya, saya sebenarnya sudah banyak kali membincangkan isu ini secara terbuka.
Salah satu kebimbangan utama ialah, secara amnya, penyelidikan sumber terbuka dan terbuka jelas memberi manfaat. Tetapi terdapat masalah khusus di sini, dan itu berkaitan dengan teknologi AGI dan AI, kerana ia adalah universal.
Sebaik sahaja anda menerbitkannya, pelakon yang berniat jahat boleh menggunakannya untuk tujuan berbahaya.
Sudah tentu, sebaik sahaja anda membuka sesuatu sumber, anda tidak mempunyai cara sebenar untuk mengambilnya semula, tidak seperti sesuatu seperti akses API, yang boleh anda potong begitu sahaja jika anda mendapati terdapat kes penggunaan berbahaya di hiliran yang tidak pernah dipertimbangkan oleh sesiapa pun sebelum ini akses.
Saya rasa ini bermakna bar untuk keselamatan, keteguhan dan akauntabiliti adalah lebih tinggi. Apabila kita semakin hampir dengan AGI, mereka akan mempunyai keupayaan yang lebih berkuasa, jadi kita perlu lebih berhati-hati tentang perkara yang mungkin digunakan oleh pelakon berniat jahat.
Saya masih belum mendengar hujah yang baik daripada mereka yang menyokong sumber terbuka, seperti pelampau sumber terbuka, yang kebanyakannya adalah rakan sekerja saya yang dihormati dalam bidang akademik, bagaimana mereka menjawab soalan ini, - selaras Mencegah model sumber terbuka daripada memberikan lebih banyak pelakon berniat jahat akses kepada model itu?
Kita perlu memikirkan lebih lanjut tentang isu ini kerana sistem ini semakin berkuasa.
S: Jadi, kenapa Gemma tidak risaukan anda tentang isu ini?

Ya, sudah tentu, seperti yang anda akan perhatikan, Gemma hanya menawarkan versi ringan, jadi ia agak kecil.
Sebenarnya, saiz yang lebih kecil lebih berguna untuk pembangun kerana biasanya pembangun individu, ahli akademik atau pasukan kecil ingin bekerja dengan cepat pada komputer riba mereka, jadi mereka dioptimumkan untuk itu.
Oleh kerana mereka bukan model canggih, mereka adalah model kecil dan kami berasa yakin bahawa kerana keupayaan model ini telah diuji dengan teliti dan kami tahu dengan baik apa yang mereka mampu, tidak ada risiko besar dengan model sebesar ini.
Mengapa DeepMind bergabung dengan Google Brain
S: Tahun lepas, apabila Google Brain dan DeepMind bergabung, sesetengah orang yang saya kenali dalam industri AI berasa bimbang. Mereka bimbang bahawa Google secara sejarah telah memberikan DeepMind latitud yang besar untuk mengusahakan pelbagai projek penyelidikan yang dianggap penting.
Dengan penggabungan itu, DeepMind mungkin perlu dialihkan kepada perkara yang bermanfaat kepada Google dalam jangka pendek, dan bukannya projek penyelidikan asas jangka panjang ini. Sudah setahun sejak penggabungan, adakah ketegangan antara minat jangka pendek dalam Google dan kemungkinan kemajuan AI jangka panjang telah mengubah perkara yang anda boleh usahakan?
Ya, semuanya hebat pada tahun pertama ini seperti yang anda nyatakan. Satu sebab ialah kita fikir sekarang adalah masa yang sesuai, dan saya fikir ia adalah masa yang sesuai dari perspektif penyelidik.
Mungkin mari kita kembali ke masa lima atau enam tahun, semasa kami melakukan perkara seperti AlphaGo, dalam bidang AI, kami telah meneroka secara mendalam bagaimana untuk sampai ke AGI, apa kejayaan yang diperlukan, apa yang harus dipertaruhkan, dan dalam itu Terdapat pelbagai perkara yang anda mahu lakukan, jadi saya fikir itu adalah peringkat yang sangat penerokaan.
Saya rasa sejak dua atau tiga tahun lalu sudah jelas apakah komponen utama AGI, seperti yang saya nyatakan sebelum ini, walaupun kita masih memerlukan inovasi baru.

Saya rasa anda baru sahaja melihat konteks panjang Gemini1.5, dan saya fikir terdapat banyak inovasi baharu seperti ini yang akan diperlukan, jadi penyelidikan asas masih sama pentingnya.
Tetapi sekarang kita juga perlu bekerja keras dalam arah kejuruteraan, iaitu, mengembangkan dan memanfaatkan teknologi yang diketahui dan mendorongnya ke hadnya Ini memerlukan kejuruteraan yang sangat kreatif pada skala, daripada perkakasan peringkat prototaip hingga skala pusat data. dan isu kecekapan yang terlibat.
Sebab lain ialah jika anda mengeluarkan beberapa produk dipacu AI lima atau enam tahun lalu, anda perlu membina AI yang berbeza sama sekali daripada landasan penyelidikan AGI.
Ia hanya boleh melaksanakan tugas dalam senario khas untuk produk tertentu Ia adalah sejenis AI tersuai, "AI buatan tangan".
Tetapi perkara berbeza hari ini Untuk melakukan AI untuk produk, cara terbaik sekarang ialah menggunakan teknologi dan sistem AI umum kerana ia telah mencapai tahap kerumitan dan keupayaan yang mencukupi.
Jadi sebenarnya ini adalah titik penumpuan, jadi anda boleh lihat sekarang bahawa trek penyelidikan dan trek produk telah digabungkan bersama.
Sebagai contoh, kami kini akan membuat pembantu suara AI Sebaliknya adalah chatbot yang benar-benar memahami bahasa Mereka kini disepadukan, jadi tidak perlu mempertimbangkan dikotomi atau hubungan yang diselaraskan dan tegang.
Sebab kedua ialah mempunyai gelung maklum balas yang ketat antara penyelidikan dan aplikasi dunia sebenar sebenarnya sangat bermanfaat untuk penyelidikan.
Oleh kerana cara produk membolehkan anda benar-benar memahami prestasi model anda, anda boleh mempunyai metrik akademik, tetapi ujian sebenar ialah apabila berjuta-juta pengguna menggunakan produk anda, adakah mereka mendapati ia berguna, adakah mereka mendapati ia berguna Adakah ia membantu dan adakah ia baik untuk dunia.
Anda pasti akan mendapat banyak maklum balas, dan itu akan membawa kepada peningkatan yang sangat pantas pada model asas, jadi saya fikir kita berada dalam tahap yang sangat, sangat menarik sekarang.
Atas ialah kandungan terperinci Ketua Pegawai Eksekutif DeepMind: LLM+tree search ialah rangkaian teknologi AGI yang bergantung pada keupayaan kejuruteraan Model sumber tertutup adalah lebih selamat daripada model sumber terbuka.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- java软件系统功能设计实战训练视频教程
- 两个表格如何对比筛选出相同数据?
- 如何快速选中一列数据
- Latihan ViT dan MAE mengurangkan jumlah pengiraan sebanyak separuh! Sea dan Universiti Peking bersama-sama mencadangkan Adan pengoptimum yang cekap, yang boleh digunakan untuk model dalam
- Musk mengisytiharkan dia akan menyaman Microsoft kerana menggunakan data Twitter untuk melatih sistem kecerdasan buatan