
Rumah >Peranti teknologi >AI >Universiti Fudan dan lain-lain mengeluarkan AnyGPT: sebarang input dan output mod, termasuk imej, muzik, teks dan suara.
Universiti Fudan dan lain-lain mengeluarkan AnyGPT: sebarang input dan output mod, termasuk imej, muzik, teks dan suara.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-03-05 09:19:171074semak imbas
Baru-baru ini, model penjanaan video OpenAI Sora telah menjadi popular, dan keupayaan pelbagai mod model AI generatif sekali lagi menarik perhatian meluas.
Dunia sebenar sememangnya bersifat multimodal, dengan organisma mengesan dan bertukar maklumat melalui saluran yang berbeza, termasuk penglihatan, bahasa, bunyi dan sentuhan. Satu hala tuju yang menjanjikan untuk membangunkan sistem multimodal adalah untuk meningkatkan keupayaan persepsi multimodal LLM, yang terutamanya melibatkan penyepaduan pengekod multimodal dengan model bahasa, dengan itu membolehkan mereka memproses maklumat merentasi pelbagai modaliti dan memanfaatkan keupayaan pemprosesan teks LLM untuk menghasilkan tindak balas yang koheren.
Walau bagaimanapun, strategi ini hanya terpakai kepada penjanaan teks dan tidak meliputi output berbilang modal. Beberapa penyelidikan perintis telah mencapai kemajuan yang ketara dalam mencapai pemahaman dan penjanaan pelbagai mod dalam model bahasa, tetapi model ini terhad kepada satu modaliti bukan teks, seperti imej atau audio.
Untuk menyelesaikan masalah di atas, pasukan Qiu Xipeng Universiti Fudan, bersama penyelidik dari Multimodal Art Projection (MAP) dan Makmal Kepintaran Buatan Shanghai, mencadangkan model bahasa pelbagai mod yang dipanggil AnyGPT, yang boleh digunakan dalam mana-mana mod. Kombinasi modal digunakan untuk memahami dan menaakul tentang kandungan pelbagai modaliti. Secara khusus, AnyGPT boleh memahami arahan yang dijalin dengan pelbagai modaliti seperti teks, suara, imej, muzik, dsb., dan boleh dengan mahir memilih gabungan berbilang modal yang sesuai untuk bertindak balas.
Sebagai contoh, diberikan gesaan suara, AnyGPT boleh menjana respons menyeluruh dalam bentuk suara, imej dan muzik:
Memandangkan gesaan dalam bentuk teks + imej, AnyGPT boleh menjana muzik mengikut keperluan segera:

- Alamat kertas: https://arxiv.org/pdf/222 Laman utama projek: https ://junzhan2000 .github.io/ AnyGPT.github.io/
- Pengenalan Kaedah
AnyGPT memanfaatkan perwakilan diskret untuk memproses pelbagai modaliti, termasuk muzik, teks, dan pertuturan secara seragam.
Untuk menyelesaikan tugas penjanaan mana-mana modaliti kepada mana-mana modaliti, penyelidikan ini mencadangkan rangka kerja komprehensif yang boleh dilatih secara seragam. Seperti yang ditunjukkan dalam Rajah 1 di bawah, rangka kerja itu terdiri daripada tiga komponen utama, termasuk:
Multimodal tokenizer
- Model bahasa berbilang modal sebagai rangkaian tulang belakang
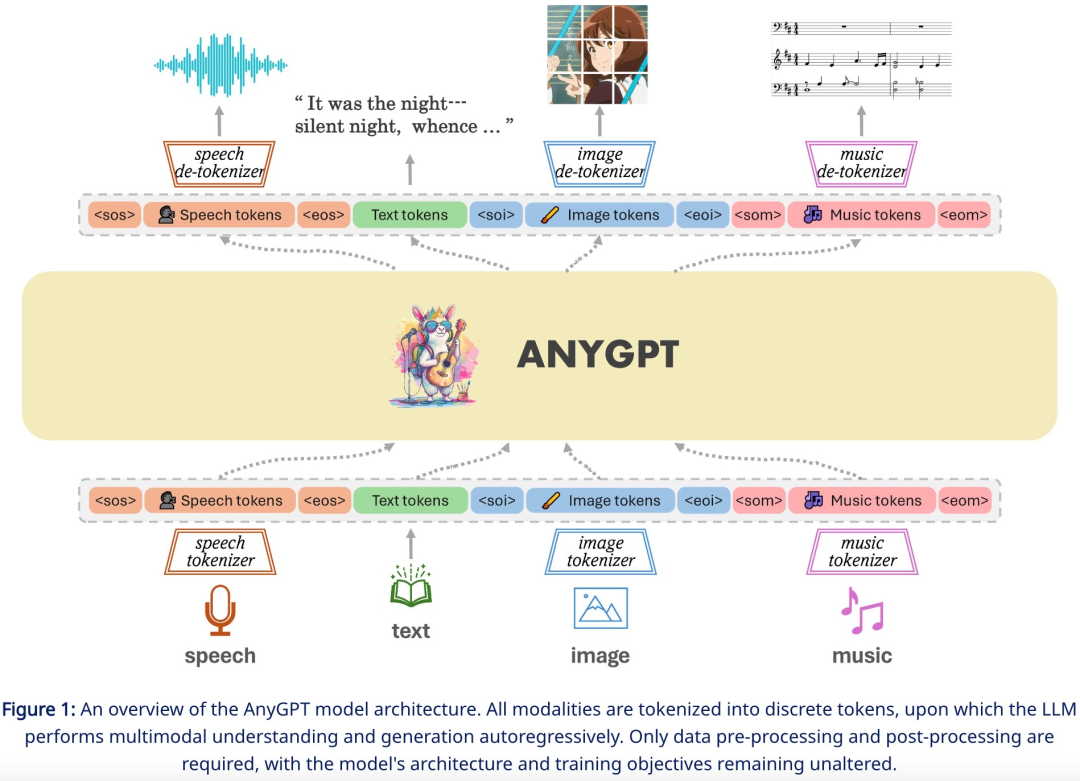
Antaranya, tokenizer menukar modaliti bukan teks berterusan kepada token diskret, dan seterusnya menyusunnya ke dalam jujukan bersilang berbilang modal. Model bahasa kemudiannya dilatih menggunakan sasaran latihan ramalan token seterusnya. Semasa inferens, token multimodal dinyahkod kembali kepada perwakilan asalnya oleh penyahtokenisasi yang berkaitan. Untuk memperkayakan kualiti penjanaan, modul peningkatan pelbagai mod boleh digunakan untuk memproses pasca hasil yang dijana, termasuk aplikasi seperti pengklonan pertuturan atau resolusi super imej.
Mana-manaGPT boleh dilatih secara stabil tanpa sebarang perubahan pada seni bina Model Bahasa Besar (LLM) semasa atau paradigma latihan. Sebaliknya, ia bergantung sepenuhnya pada prapemprosesan peringkat data, membenarkan modaliti baharu disepadukan dengan lancar ke dalam LLM, sama seperti menambahkan bahasa baharu.
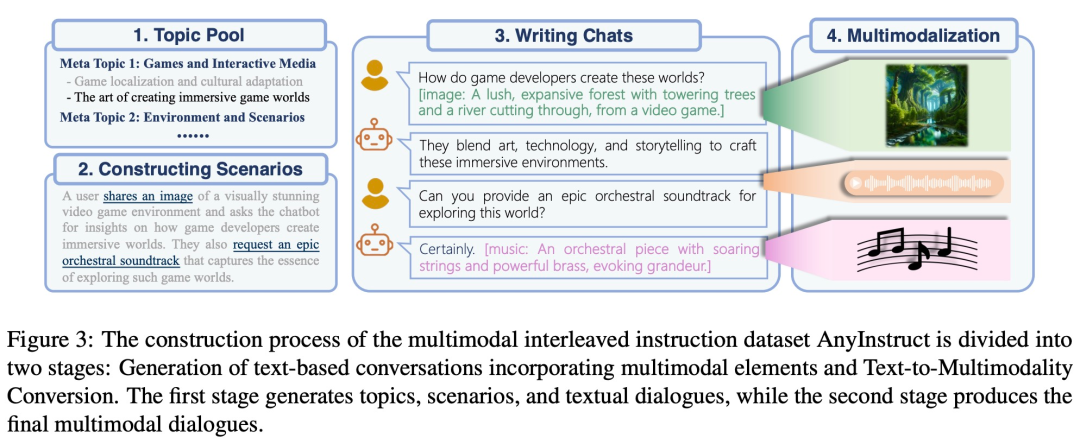
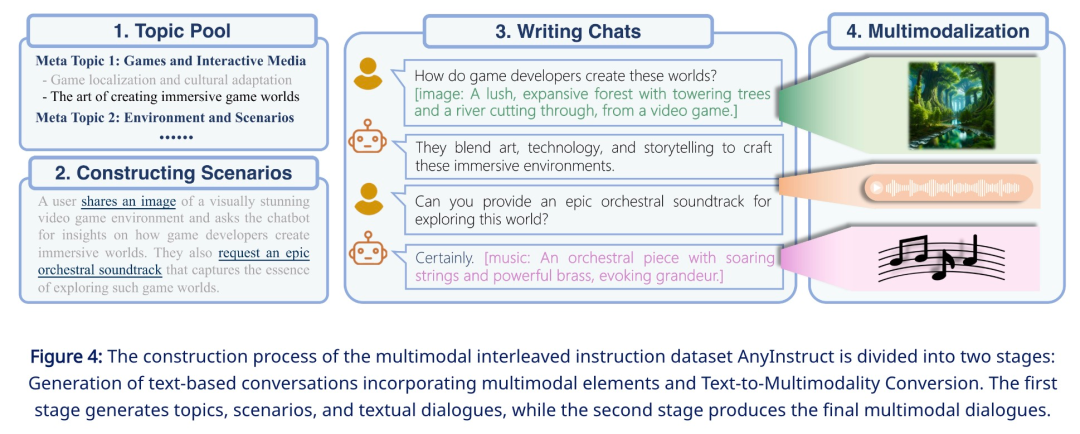
Cabaran utama penyelidikan ini ialah kekurangan data penjejakan arahan bersilang berbilang modal. Untuk melengkapkan pra-latihan penjajaran berbilang mod, pasukan penyelidik menggunakan model generatif untuk mensintesis set data arahan berbilang mod "mana-mana kepada mana-mana" berskala besar pertama - AnyInstruct-108k. Ia terdiri daripada 108k sampel dialog berbilang pusingan yang saling berkait dengan pelbagai modaliti, membolehkan model mengendalikan sebarang gabungan input dan output berbilang modal.
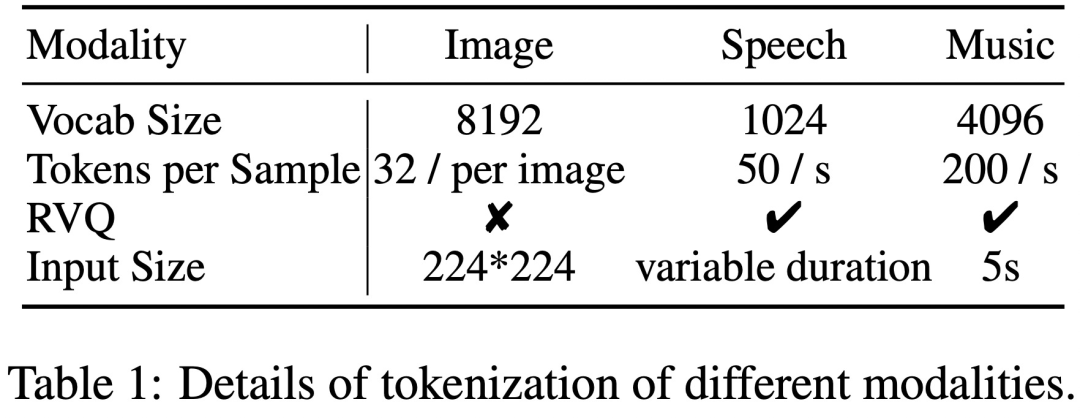

Data ini biasanya memerlukan sejumlah besar bit untuk diwakili dengan tepat, menghasilkan jujukan yang panjang, yang sangat menuntut model bahasa kerana kerumitan pengiraan meningkat secara eksponen dengan panjang jujukan. Untuk menyelesaikan masalah ini, kajian ini menggunakan rangka kerja penjanaan kesetiaan tinggi dua peringkat, termasuk pemodelan maklumat semantik dan pemodelan maklumat persepsi. Pertama, model bahasa ditugaskan untuk menghasilkan kandungan yang digabungkan dan diselaraskan pada tahap semantik. Kemudian, model bukan autoregresif menukarkan token semantik berbilang modal kepada kandungan berbilang modal kesetiaan tinggi pada tahap persepsi, memberikan keseimbangan antara prestasi dan kecekapan.
Eksperimen
Hasil eksperimen menunjukkan bahawa AnyGPT dapat melengkapkan mana-mana mod-ke-mana-mana-mana-mana-mengandingkan prestasi model dischieving yang berdedikasi dalam model Dischie yang berdedikasi, untuk melakukan semua mod komparatif perwakilan boleh menyatukan pelbagai modaliti dengan berkesan dan mudah dalam model bahasa.
Kajian ini menilai keupayaan asas AnyGPT asas pra-latihan, meliputi pemahaman pelbagai mod dan tugas penjanaan merentas semua modaliti. Penilaian ini bertujuan untuk menguji ketekalan antara modaliti yang berbeza semasa proses pra-latihan Secara khusus, tugasan teks-ke-X dan X-ke-teks bagi setiap modaliti, di mana X ialah imej, muzik dan suara.
Untuk mensimulasikan senario sebenar, semua penilaian dijalankan dalam mod sifar sampel. Ini bermakna AnyGPT tidak memperhalusi atau melatih sampel latihan hiliran semasa proses penilaian. Tetapan penilaian yang mencabar ini memerlukan model untuk digeneralisasikan kepada pengedaran ujian yang tidak diketahui.
Hasil penilaian menunjukkan bahawa AnyGPT, sebagai model bahasa multi-modal umum, mencapai prestasi yang membanggakan dalam pelbagai tugas pemahaman dan penjanaan pelbagai mod.
Imej
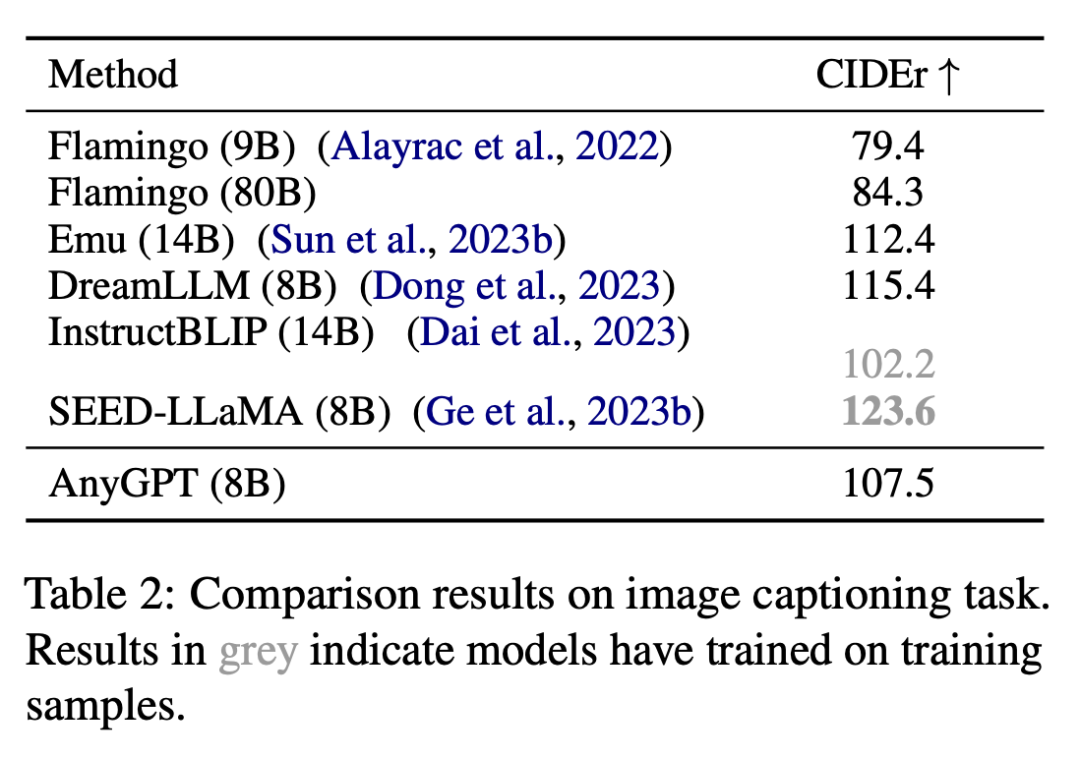
Kajian ini menilai keupayaan pemahaman imej AnyGPT pada tugas penerangan imej, dan hasilnya ditunjukkan dalam Jadual 2.
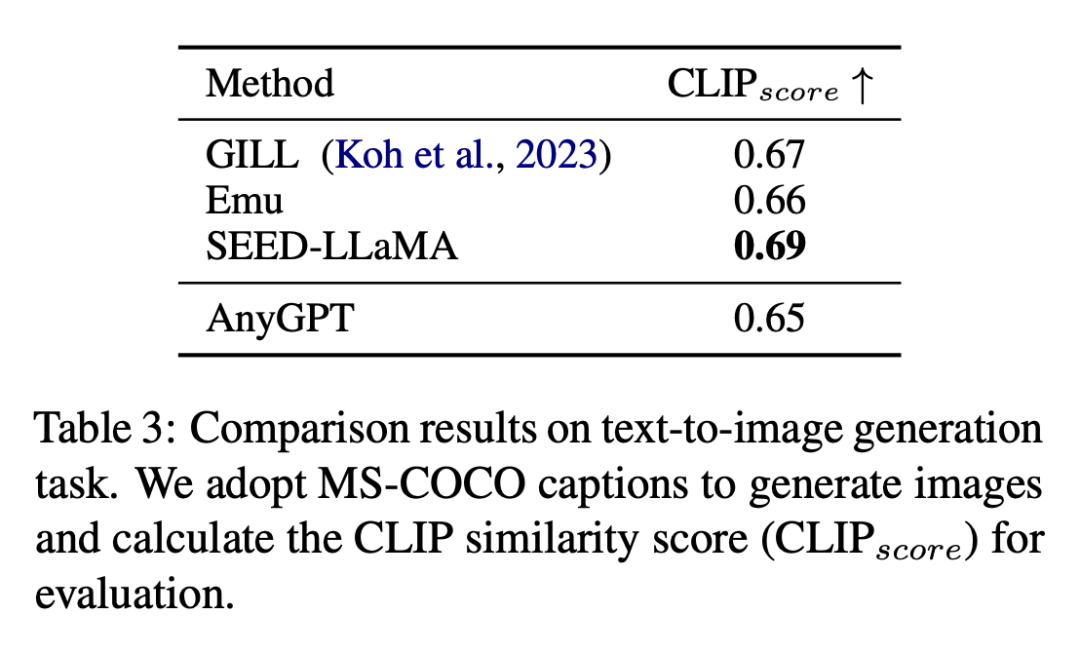
Hasil tugas penjanaan teks ke imej ditunjukkan dalam Jadual 3.
 Speech
Speech
Kajian ini menilai prestasi AnyGPT pada tugasan pengecaman pertuturan automatik (ASR) dengan mengira kadar ralat perkataan (WER) pada subset ujian bagi dataset LibriSpeech2 dan Whisper0. V2 besar sebagai garis dasar, dan keputusan penilaian ditunjukkan dalam Jadual 5.

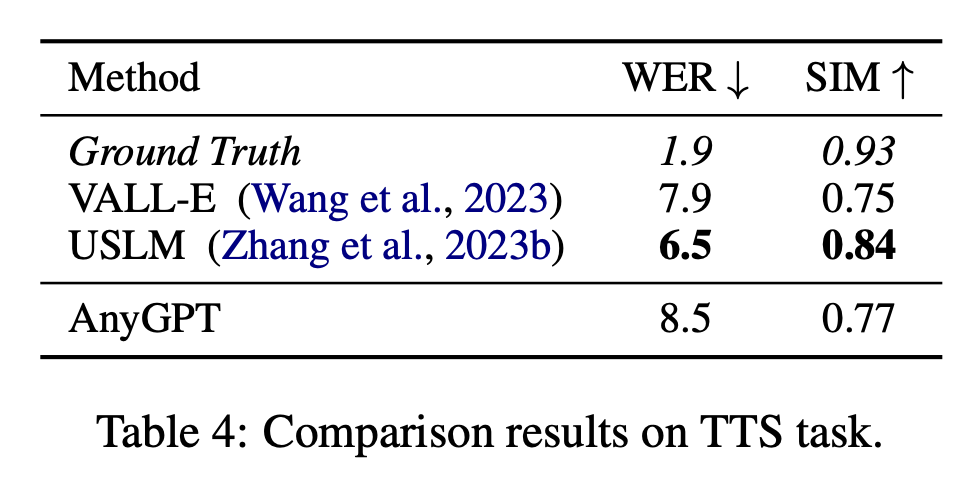
Muzik
Kajian menilai prestasi AnyGPT pada pemahaman muzik dan penanda aras muzik menggunakan CL benchmarks dan Persamaan antara huraian teks, hasil penilaian ditunjukkan dalam Jadual 6.
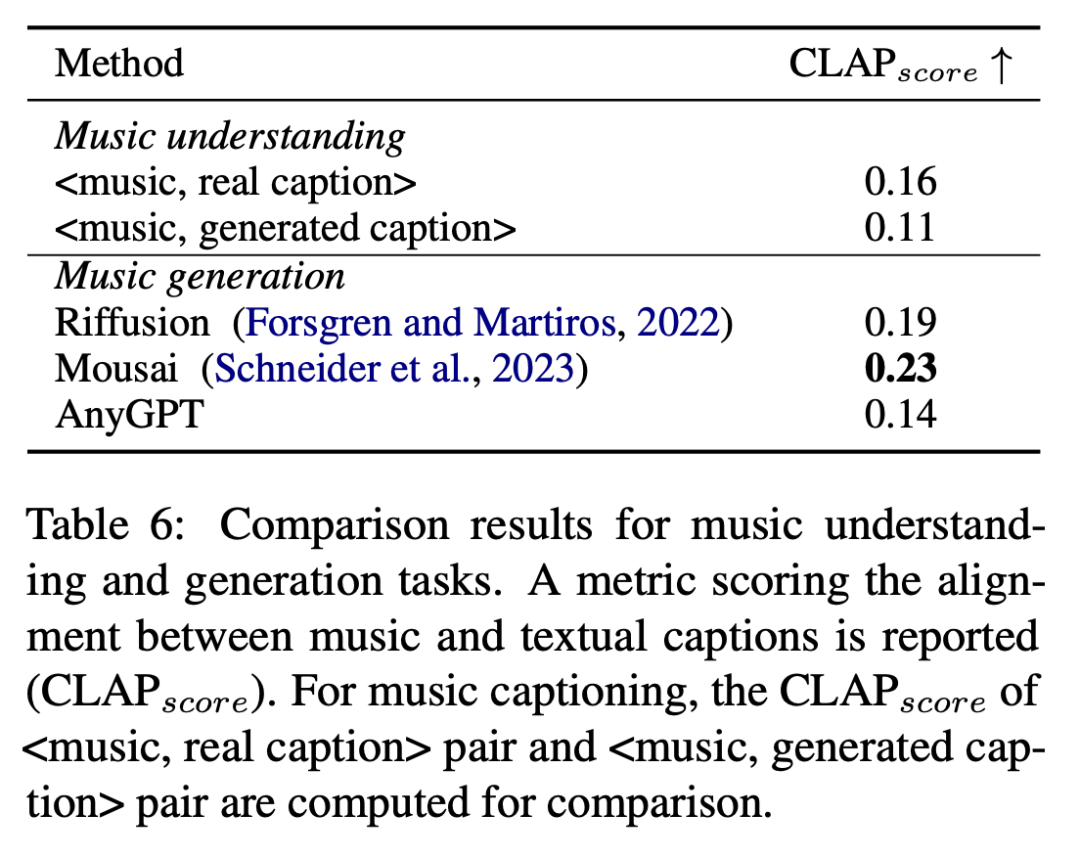
Pembaca yang berminat boleh membaca teks asal kertas kerja untuk mengetahui lebih lanjut tentang kandungan penyelidikan.
Atas ialah kandungan terperinci Universiti Fudan dan lain-lain mengeluarkan AnyGPT: sebarang input dan output mod, termasuk imej, muzik, teks dan suara.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!