
Rumah >Peranti teknologi >AI >Kertas 6 halaman Microsoft meletup: ternary LLM, sangat lazat!
Kertas 6 halaman Microsoft meletup: ternary LLM, sangat lazat!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-29 22:01:02607semak imbas
Ini adalah kesimpulan yang dikemukakan oleh Microsoft dan Akademi Sains Universiti China dalam kajian terkini -
Semua LLM akan menjadi 1.58 bit.

Secara khusus, kaedah yang dicadangkan dalam kajian ini dipanggil BitNet b1.58, yang boleh dikatakan bermula daripada parameter "root" model bahasa besar.
Storan tradisional dalam bentuk nombor titik terapung 16-bit (seperti FP16 atau BF16) telah ditukar kepada ternary , iaitu {-1, 0, 1}.
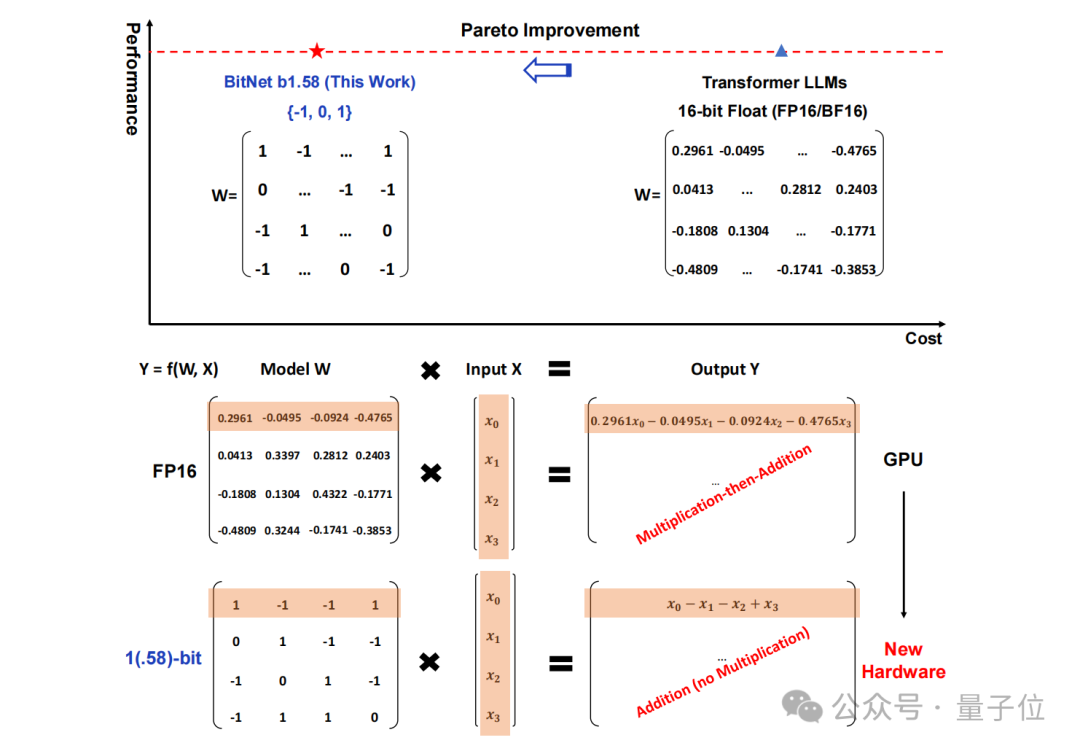
Perlu diingat bahawa "1.58 bit" tidak bermakna setiap parameter menduduki 1.58 bait ruang storan, tetapi setiap parameter boleh dikodkan dengan 1.58 bit maklumat.
Selepas penukaran sedemikian, pengiraan dalam matriks hanya akan melibatkan penambahan integer, sekali gus membolehkan model besar mengurangkan ruang storan dan sumber pengkomputeran yang diperlukan dengan ketara sambil mengekalkan ketepatan tertentu.
Sebagai contoh, BitNet b1.58 dibandingkan dengan Llama apabila saiz model ialah 3B Walaupun kelajuan meningkat sebanyak 2.71 kali, penggunaan memori GPU hampir hanya satu perempat daripada asal. Dan apabila saiz model lebih besar(contohnya, 70B) , peningkatan kelajuan dan penjimatan memori akan menjadi lebih ketara!
Idea subversif ini benar-benar menarik perhatian netizen, dan kertas itu juga mendapat perhatian tinggi tentang Jenaka lama kertas itu:1 bit sahaja yang ANDA perlukan.
Tukar semua parameter kepada ternaryJadi bagaimanakah BitNet b1.58 dilaksanakan? Jom teruskan membaca.
 Penyelidikan ini sebenarnya adalah pengoptimuman yang dilakukan oleh pasukan asal berdasarkan kertas yang diterbitkan sebelum ini, iaitu, nilai tambahan 0 ditambahkan pada BitNet asal.
Penyelidikan ini sebenarnya adalah pengoptimuman yang dilakukan oleh pasukan asal berdasarkan kertas yang diterbitkan sebelum ini, iaitu, nilai tambahan 0 ditambahkan pada BitNet asal.
(Transformer)
, menggantikan nn.Linear dengan BitLinear. Bagi pengoptimuman terperinci, perkara pertama ialah "menambah 0" yang baru kami sebutkan, iaitu,
Bagi pengoptimuman terperinci, perkara pertama ialah "menambah 0" yang baru kami sebutkan, iaitu,
(pengkuantiti berat).
Berat model BitNet b1.58 dikuantasikan ke dalam nilai terner {-1, 0, 1}, yang bersamaan dengan menggunakan 1.58 bit untuk mewakili setiap berat dalam sistem binari. Kaedah kuantifikasi ini mengurangkan jejak ingatan model dan memudahkan proses pengiraan.
Kedua, dari segireka bentuk fungsi kuantisasi
, untuk mengehadkan berat kepada -1, 0 atau +1, penyelidik menggunakan fungsi kuantisasi yang dipanggil absmean.
Fungsi ini mula-mula menskalakan mengikut purata nilai mutlak matriks berat, dan kemudian membundarkan setiap nilai kepada integer terdekat (-1, 0, +1).
Langkah seterusnya ialahkuantisasi pengaktifan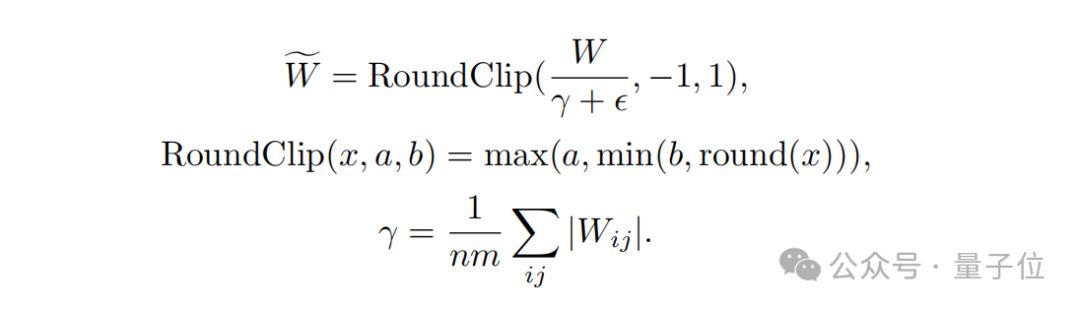
.
Kuantisasi nilai pengaktifan adalah sama seperti pelaksanaan dalam BitNet, tetapi nilai pengaktifan tidak diskalakan kepada julat [0, Qb] sebelum fungsi tak linear. Sebaliknya, pengaktifan diskalakan kepada julat [−Qb, Qb] untuk menghapuskan pengkuantitian titik sifar. Perlu dinyatakan bahawa untuk menjadikan BitNet b1.58 serasi dengan komuniti sumber terbuka, pasukan penyelidik menggunakan komponen model LLaMA, seperti RMSNorm, SwiGLU, dll., supaya ia boleh disepadukan dengan mudah ke dalam arus perdana terbuka. perisian sumber. Akhir sekali, dari segi perbandingan prestasi percubaan, pasukan membandingkan BitNet b1.58 dan FP16 LLaMA LLM pada model yang berbeza saiz. Hasilnya menunjukkan bahawa BitNet b1.58 mula memadankan LLaMA berketepatan penuh LLM dalam kebingungan pada saiz model 3B, sambil mencapai peningkatan ketara dalam kependaman, penggunaan memori dan daya pemprosesan. Dan apabila saiz model menjadi lebih besar, peningkatan prestasi ini akan menjadi lebih ketara. Seperti yang dinyatakan di atas, kaedah unik kajian ini telah menyebabkan banyak perbincangan hangat di Internet. Pengarang DeepLearning.scala Yang Bo berkata: Berbanding dengan BitNet asal, ciri terbesar BitNet b1.58 ialah ia membenarkan 0 parameter. Saya berpendapat bahawa dengan mengubah sedikit fungsi pengkuantitian, kita mungkin dapat mengawal perkadaran parameter 0. Apabila perkadaran 0 parameter adalah besar, pemberat boleh disimpan dalam format yang jarang, supaya purata memori video yang diduduki oleh setiap parameter adalah kurang daripada 1 bit. Ini bersamaan dengan MoE peringkat berat. Saya rasa ia lebih elegan daripada KPM biasa. Pada masa yang sama, dia juga membangkitkan kekurangan BitNet: Kelemahan terbesar BitNet ialah walaupun ia boleh mengurangkan overhed memori semasa inferens, keadaan pengoptimum dan kecerunan masih menggunakan nombor titik terapung, dan latihan masih sangat memakan ingatan. Saya fikir jika BitNet boleh digabungkan dengan teknologi yang menjimatkan memori video semasa latihan, maka berbanding dengan rangkaian separuh ketepatan tradisional, ia boleh menyokong lebih banyak parameter dengan kuasa pengkomputeran dan memori video yang sama, yang akan mempunyai kelebihan yang besar. Cara semasa untuk menyimpan overhed memori grafik bagi keadaan pengoptimum sedang memunggah. Satu cara untuk menyimpan penggunaan memori kecerunan mungkin ReLoRA. Walau bagaimanapun, percubaan kertas ReLoRA hanya menggunakan model dengan satu bilion parameter, dan tidak ada bukti bahawa ia boleh digeneralisasikan kepada model dengan puluhan atau ratusan bilion parameter. . 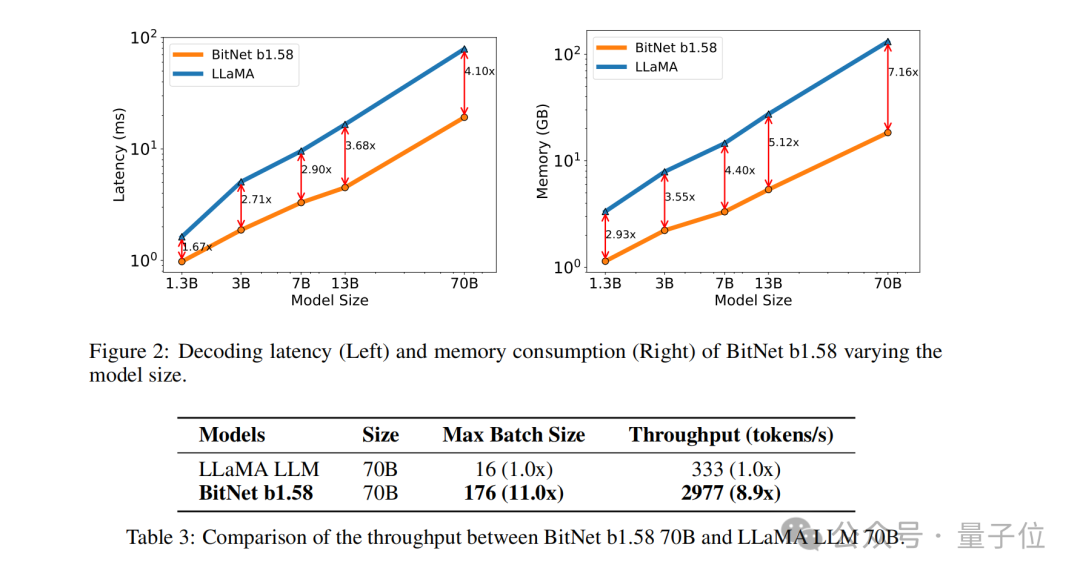
Netizen: Ada kemungkinan untuk menjalankan model besar 120B pada GPU gred pengguna
Jadi apa pendapat anda tentang kaedah baharu ini? 
Atas ialah kandungan terperinci Kertas 6 halaman Microsoft meletup: ternary LLM, sangat lazat!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- ai顶部属性栏不见了怎么解决?
- ai属性栏怎么调出来
- Google juga melakukannya? Bard didedahkan menggunakan data ChatGPT untuk latihan Model besar itu benar-benar ketinggalan langkah demi langkah.
- Laksanakan latihan kelebihan dengan memori kurang daripada 256KB dan kosnya kurang daripada seperseribu PyTorch
- Penjelasan terperinci tentang model pra-latihan pembelajaran mendalam dalam Python