
Rumah >Peranti teknologi >AI >Memilih model benam yang paling sesuai dengan data anda: Ujian perbandingan OpenAI dan benam berbilang bahasa sumber terbuka
Memilih model benam yang paling sesuai dengan data anda: Ujian perbandingan OpenAI dan benam berbilang bahasa sumber terbuka

- WBOYke hadapan
- 2024-02-26 18:10:15863semak imbas
OpenAI baru-baru ini mengumumkan pelancaran model benam generasi terbaharu mereka yang dibenamkan v3, yang mereka dakwa sebagai model benam paling berprestasi dengan prestasi berbilang bahasa yang lebih tinggi. Kumpulan model ini dibahagikan kepada dua jenis: pembenaman teks-3-kecil yang lebih kecil dan pembenaman teks-3-besar yang lebih berkuasa dan lebih besar.

Sangat sedikit maklumat yang didedahkan tentang cara model ini direka dan dilatih, dan model hanya boleh diakses melalui API berbayar. Jadi terdapat banyak model pembenaman sumber terbuka Tetapi bagaimana model sumber terbuka ini dibandingkan dengan model sumber tertutup OpenAI?
Artikel ini akan membandingkan prestasi model baharu ini secara empirik dengan model sumber terbuka. Kami merancang untuk membina aliran kerja pengambilan data di mana tugas utama adalah untuk mencari dokumen yang paling berkaitan daripada korpus berdasarkan pertanyaan pengguna.
Korpus kami ialah Akta Kepintaran Buatan Eropah, yang kini dalam peringkat pengesahan. Korpus ini ialah rangka kerja undang-undang pertama di dunia yang melibatkan kecerdasan buatan dan unik kerana ia tersedia dalam 24 bahasa. Ini membolehkan kami membandingkan ketepatan pengambilan data dalam latar belakang bahasa yang berbeza, memberikan sokongan penting untuk aplikasi silang budaya kecerdasan buatan.
Kami merancang untuk mencipta set data soalan/jawapan sintetik tersuai menggunakan korpus teks berbilang bahasa dan menggunakan set data ini untuk membandingkan ketepatan OpenAI dan model pembenaman sumber terbuka terkini. Kami akan berkongsi kod penuh kerana pendekatan kami boleh disesuaikan dengan mudah kepada korpora data lain.
Generasi set data Q/A tersuai, kita boleh mulakan dengan membuat soalan dan jawapan tersuai (q/a) set. tidak menjadi sebahagian daripada latihan model Faktor bias untuk mengelakkan situasi yang serupa dengan yang mungkin berlaku dalam rujukan penanda aras seperti MTEB. Selain itu, dengan menjana set data tersuai, kami boleh menyesuaikan proses penilaian kepada korpus data tertentu, yang boleh menjadi penting untuk senario seperti Retrieval Augmentation Applications (RAG).
Kami akan mengikuti proses mudah yang dicadangkan dalam dokumentasi Indeks Llama. Pertama, korpus dibahagikan kepada ketulan. Seterusnya, bagi setiap blok, model bahasa besar (LLM) digunakan untuk menjana satu siri soalan sintetik bagi memastikan jawapan berada dalam blok yang sepadan.
Melaksanakan strategi ini menggunakan bingkai data LLM seperti Indeks Llama adalah sangat mudah, seperti yang ditunjukkan dalam kod di bawah. Korpus 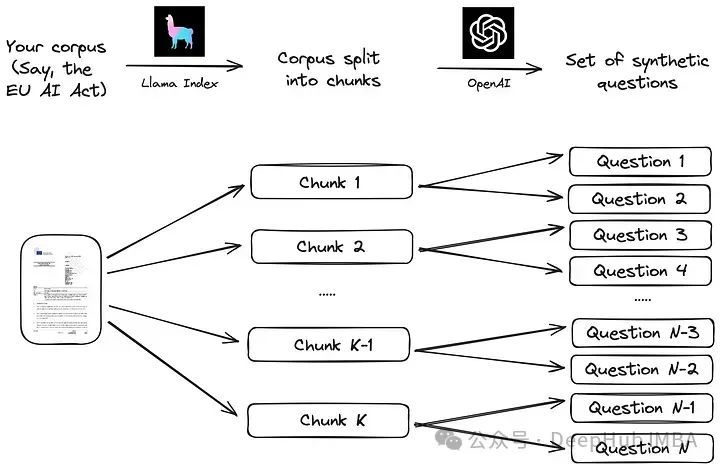
from llama_index.readers.web import SimpleWebPageReader from llama_index.core.node_parser import SentenceSplitter language = "EN" url_doc = "https://eur-lex.europa.eu/legal-content/"+language+"/TXT/HTML/?uri=CELEX:52021PC0206" documents = SimpleWebPageReader(html_to_text=True).load_data([url_doc]) parser = SentenceSplitter(chunk_size=1000) nodes = parser.get_nodes_from_documents(documents, show_progress=True)ialah versi Bahasa Inggeris Akta Kepintaran Buatan EU, yang diperoleh terus daripada web menggunakan URL rasmi ini. Artikel ini menggunakan versi draf dari April 2021, kerana versi akhir belum tersedia dalam semua bahasa Eropah. Jadi versi yang kami pilih boleh menggantikan bahasa dalam URL dengan mana-mana 23 bahasa rasmi EU yang lain, mendapatkan semula teks dalam bahasa berbeza (BG untuk bahasa Bulgaria, ES untuk bahasa Sepanyol, CS untuk bahasa Czech, dll. ).
Gunakan objek SentenceSplitter untuk membahagikan dokumen kepada ketulan 1000 token setiap satu. Untuk bahasa Inggeris, ini menjana kira-kira 100 ketul. Setiap bahagian kemudiannya diberikan sebagai konteks kepada gesaan berikut (gesaan lalai yang dicadangkan dalam perpustakaan Indeks Llama): 
prompts={} prompts["EN"] = """\ Context information is below. --------------------- {context_str} --------------------- Given the context information and not prior knowledge, generate only questions based on the below query. You are a Teacher/ Professor. Your task is to setup {num_questions_per_chunk} questions for an upcoming quiz/examination. The questions should be diverse in nature across the document. Restrict the questions to the context information provided." """
Gesaan ini boleh menjana soalan tentang bahagian dokumen, dengan bilangan soalan yang akan dijana untuk setiap bongkah data sebagai Parameter "num_questions_per_chunk" diluluskan dan kami menetapkannya kepada 2. Soalan kemudiannya boleh dijana dengan memanggil generate_qa_embedding_pairs dalam perpustakaan Indeks Llama:
from llama_index.llms import OpenAI from llama_index.legacy.finetuning import generate_qa_embedding_pairs qa_dataset = generate_qa_embedding_pairs(llm=OpenAI(model="gpt-3.5-turbo-0125",additional_kwargs={'seed':42}),nodes=nodes,qa_generate_prompt_tmpl = prompts[language],num_questions_per_chunk=2 )
我们依靠OpenAI的GPT-3.5-turbo-0125来完成这项任务,结果对象' qa_dataset '包含问题和答案(块)对。作为生成问题的示例,以下是前两个问题的结果(其中“答案”是文本的第一部分):
- What are the main objectives of the proposal for a Regulation laying down harmonised rules on artificial intelligence (Artificial Intelligence Act) according to the explanatory memorandum?
- How does the proposal for a Regulation on artificial intelligence aim to address the risks associated with the use of AI while promoting the uptake of AI in the European Union, as outlined in the context information?
OpenAI嵌入模型
评估函数也是遵循Llama Index文档:首先所有答案(文档块)的嵌入都存储在VectorStoreIndex中,以便有效检索。然后评估函数循环遍历所有查询,检索前k个最相似的文档,并根据MRR (Mean Reciprocal Rank)评估检索的准确性,代码如下:
def evaluate(dataset, embed_model, insert_batch_size=1000, top_k=5):# Get corpus, queries, and relevant documents from the qa_dataset objectcorpus = dataset.corpusqueries = dataset.queriesrelevant_docs = dataset.relevant_docs # Create TextNode objects for each document in the corpus and create a VectorStoreIndex to efficiently store and retrieve embeddingsnodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()]index = VectorStoreIndex(nodes, embed_model=embed_model, insert_batch_size=insert_batch_size)retriever = index.as_retriever(similarity_top_k=top_k) # Prepare to collect evaluation resultseval_results = [] # Iterate over each query in the dataset to evaluate retrieval performancefor query_id, query in tqdm(queries.items()):# Retrieve the top_k most similar documents for the current query and extract the IDs of the retrieved documentsretrieved_nodes = retriever.retrieve(query)retrieved_ids = [node.node.node_id for node in retrieved_nodes] # Check if the expected document was among the retrieved documentsexpected_id = relevant_docs[query_id][0]is_hit = expected_id in retrieved_ids # assume 1 relevant doc per query # Calculate the Mean Reciprocal Rank (MRR) and append to resultsif is_hit:rank = retrieved_ids.index(expected_id) + 1mrr = 1 / rankelse:mrr = 0eval_results.append(mrr) # Return the average MRR across all queries as the final evaluation metricreturn np.average(eval_results)
嵌入模型通过' embed_model '参数传递给评估函数,对于OpenAI模型,该参数是一个用模型名称和模型维度初始化的OpenAIEmbedding对象。
from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model=model_spec['model_name'],dimensinotallow=model_spec['dimensions'])
dimensions参数可以缩短嵌入(即从序列的末尾删除一些数字),而不会失去嵌入的概念表示属性。OpenAI在他们的公告中建议,在MTEB基准测试中,嵌入可以缩短到256大小,同时仍然优于未缩短的text-embedding-ada-002嵌入(大小为1536)。
我们在四种不同的嵌入模型上运行评估函数:
两个版本的text-embedding-3-large:一个具有最低可能维度(256),另一个具有最高可能维度(3072)。它们被称为“OAI-large-256”和“OAI-large-3072”。
OAI-small:text-embedding-3-small,维数为1536。
OAI-ada-002:传统的文本嵌入text-embedding-ada-002,维度为1536。
每个模型在四种不同的语言上进行评估:英语(EN),法语(FR),捷克语(CS)和匈牙利语(HU),分别涵盖日耳曼语,罗曼语,斯拉夫语和乌拉尔语的例子。
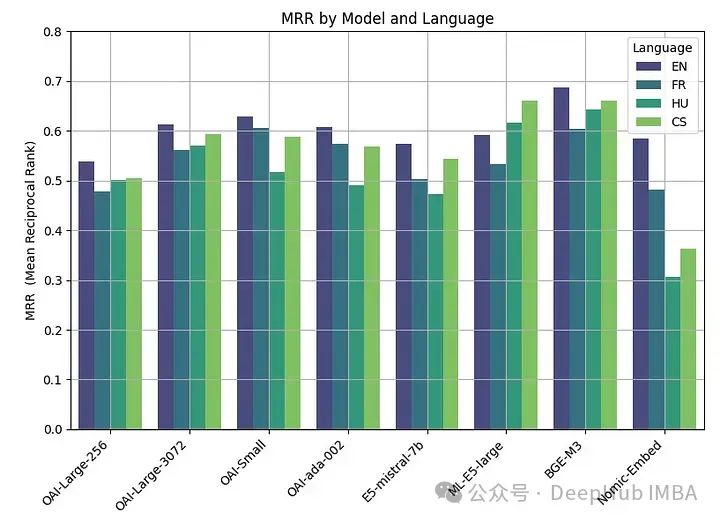
embeddings_model_spec = { } embeddings_model_spec['OAI-Large-256']={'model_name':'text-embedding-3-large','dimensions':256} embeddings_model_spec['OAI-Large-3072']={'model_name':'text-embedding-3-large','dimensions':3072} embeddings_model_spec['OAI-Small']={'model_name':'text-embedding-3-small','dimensions':1536} embeddings_model_spec['OAI-ada-002']={'model_name':'text-embedding-ada-002','dimensions':None} results = [] languages = ["EN", "FR", "CS", "HU"] # Loop through all languages for language in languages: # Load datasetfile_name=language+"_dataset.json"qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name) # Loop through all modelsfor model_name, model_spec in embeddings_model_spec.items(): # Get modelembed_model = OpenAIEmbedding(model=model_spec['model_name'],dimensinotallow=model_spec['dimensions']) # Assess embedding score (in terms of MRR)score = evaluate(qa_dataset, embed_model) results.append([language, model_name, score]) df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR"])MRR精度如下:
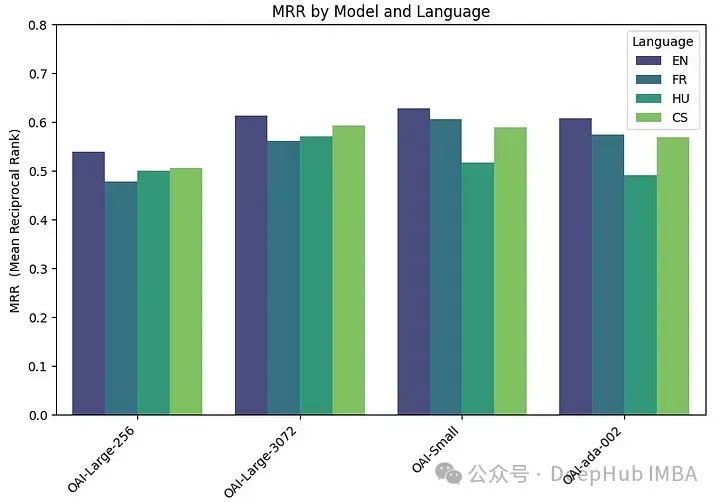
嵌入尺寸越大,性能越好。
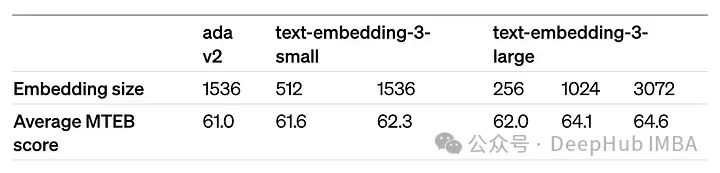
开源嵌入模型
围绕嵌入的开源研究也是非常活跃的,Hugging Face 的 MTEB leaderboard会经常发布最新的嵌入模型。
为了在本文中进行比较,我们选择了一组最近发表的四个嵌入模型(2024)。选择的标准是他们在MTEB排行榜上的平均得分和他们处理多语言数据的能力。所选模型的主要特性摘要如下。

e5-mistral-7b-instruct:微软的这个E5嵌入模型是从Mistral-7B-v0.1初始化的,并在多语言混合数据集上进行微调。模型在MTEB排行榜上表现最好,但也是迄今为止最大的(14GB)。
multilingual-e5-large-instruct(ML-E5-large):微软的另一个E5模型,可以更好地处理多语言数据。它从xlm-roberta-large初始化,并在多语言数据集的混合上进行训练。它比E5-Mistral小得多(10倍),上下文大小也小得多(514)。
BGE-M3:该模型由北京人工智能研究院设计,是他们最先进的多语言数据嵌入模型,支持100多种工作语言。截至2024年2月22日,它还没有进入MTEB排行榜。
nomic-embed-text-v1 (Nomic- embed):该模型由Nomic设计,其性能优于OpenAI Ada-002和text-embedding-3-small,而且大小仅为0.55GB。该模型是第一个完全可复制和可审计的(开放数据和开源训练代码)的模型。
用于评估这些开源模型的代码类似于用于OpenAI模型的代码。主要的变化在于模型参数:
embeddings_model_spec = { } embeddings_model_spec['E5-mistral-7b']={'model_name':'intfloat/e5-mistral-7b-instruct','max_length':32768, 'pooling_type':'last_token', 'normalize': True, 'batch_size':1, 'kwargs': {'load_in_4bit':True, 'bnb_4bit_compute_dtype':torch.float16}} embeddings_model_spec['ML-E5-large']={'model_name':'intfloat/multilingual-e5-large','max_length':512, 'pooling_type':'mean', 'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}} embeddings_model_spec['BGE-M3']={'model_name':'BAAI/bge-m3','max_length':8192, 'pooling_type':'cls', 'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}} embeddings_model_spec['Nomic-Embed']={'model_name':'nomic-ai/nomic-embed-text-v1','max_length':8192, 'pooling_type':'mean', 'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'trust_remote_code' : True}} results = [] languages = ["EN", "FR", "CS", "HU"] # Loop through all models for model_name, model_spec in embeddings_model_spec.items(): print("Processing model : "+str(model_spec)) # Get modeltokenizer = AutoTokenizer.from_pretrained(model_spec['model_name'])embed_model = AutoModel.from_pretrained(model_spec['model_name'], **model_spec['kwargs']) if model_name=="Nomic-Embed":embed_model.to('cuda') # Loop through all languagesfor language in languages: # Load datasetfile_name=language+"_dataset.json"qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name) start_time_assessment=time.time() # Assess embedding score (in terms of hit rate at k=5)score = evaluate(qa_dataset, tokenizer, embed_model, model_spec['normalize'], model_spec['max_length'], model_spec['pooling_type']) # Get duration of score assessmentduration_assessment = time.time()-start_time_assessment results.append([language, model_name, score, duration_assessment]) df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR", "Duration"])Keputusannya adalah seperti berikut:
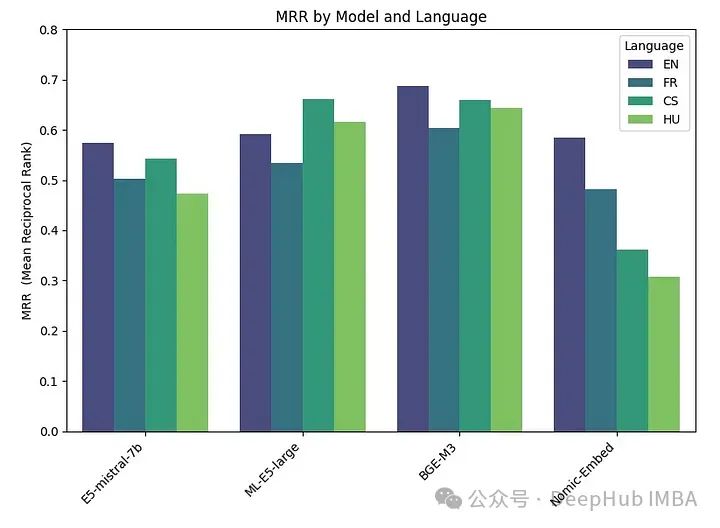
BGE-M3 menunjukkan prestasi terbaik, diikuti oleh ML-E5-Large, E5-mistral-7b dan Nomic-Embed. Model BGE-M3 belum lagi ditanda aras pada penarafan MTEB, dan keputusan kami menunjukkan bahawa ia mungkin berkedudukan lebih tinggi daripada model lain. Walaupun BGE-M3 dioptimumkan untuk data berbilang bahasa, ia juga berprestasi lebih baik dalam bahasa Inggeris berbanding model lain.
Oleh kerana model sumber terbuka secara amnya perlu dijalankan secara tempatan, kami juga sengaja merekodkan masa pemprosesan setiap model terbenam.
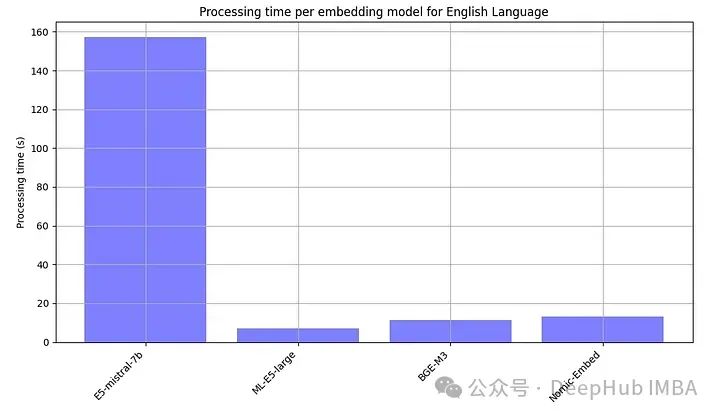
E5-mistral-7b adalah lebih daripada 10 kali ganda lebih besar daripada model lain, jadi yang paling perlahan adalah perkara biasa Terbaik prestasi dicapai menggunakan model sumber terbuka, dengan model BGE-M3 menunjukkan prestasi terbaik. Model ini mempunyai panjang konteks yang sama (8K) seperti model OpenAI dan bersaiz 2.2GB.
Prestasi model OpenAI yang besar(3072), kecil dan ada sangat serupa. Mengurangkan saiz benam yang besar (256) mengakibatkan kemerosotan prestasi dan tidak sebaik yang ada seperti yang dikatakan OpenAI.
Hampir semua model (kecuali ML-E5-large) berprestasi terbaik dalam bahasa Inggeris. Dalam bahasa seperti Czech dan Hungary, terdapat perbezaan yang ketara dalam prestasi, mungkin kerana terdapat kurang data untuk dilatih.
Pelarasan harga OpenAI baru-baru ini telah menjadikan API mereka lebih berpatutan, kini berharga $0.13 setiap juta token. Jika anda memproses sejuta pertanyaan sebulan (dengan mengandaikan setiap pertanyaan melibatkan kira-kira 1K token), kosnya ialah kira-kira $130. Oleh itu, anda boleh memilih sama ada untuk mengehoskan model pembenaman sumber terbuka berdasarkan keperluan sebenar.
Sudah tentu keberkesanan kos bukan satu-satunya pertimbangan. Faktor lain seperti kependaman, privasi dan kawalan ke atas aliran kerja pemprosesan data juga mungkin perlu dipertimbangkan. Model sumber terbuka menawarkan kelebihan kawalan data yang lengkap, privasi dan penyesuaian yang dipertingkatkan.
Bercakap tentang kependaman, API OpenAI juga mempunyai isu kependaman, yang kadangkala mengakibatkan masa tindak balas yang dilanjutkan, jadi kadangkala API OpenAI tidak semestinya pilihan terpantas.
Kesimpulannya, memilih antara model sumber terbuka dan penyelesaian proprietari seperti OpenAI bukanlah jawapan yang mudah. Pembenaman sumber terbuka menawarkan pilihan hebat yang menggabungkan prestasi dengan kawalan yang lebih besar ke atas data anda. Dan produk OpenAI mungkin masih menarik minat mereka yang mengutamakan kemudahan, terutamanya jika kebimbangan privasi adalah yang kedua.
Kod artikel ini: https://github.com/Yannael/multilingual-embeddings
Atas ialah kandungan terperinci Memilih model benam yang paling sesuai dengan data anda: Ujian perbandingan OpenAI dan benam berbilang bahasa sumber terbuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!