
Rumah >Peranti teknologi >AI >Menggunakan model resapan untuk menjana parameter rangkaian, LeCun memuji penyelidikan baharu pasukan You Yang
Menggunakan model resapan untuk menjana parameter rangkaian, LeCun memuji penyelidikan baharu pasukan You Yang

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-26 08:10:03538semak imbas
Jika anda telah terkejut dengan video yang dihasilkan oleh Sora, maka anda telah melihat potensi besar model resapan dalam penjanaan visual. Sudah tentu, potensi model penyebaran tidak berhenti di sini Ia juga mempunyai prospek aplikasi yang menarik dalam banyak bidang lain, sila rujuk laporan terbaru kami "Teknologi di sebalik letupan Sora, artikel yang meringkaskan penyebaran. arah pembangunan terkini model》.
Penyelidikan terkini yang dijalankan oleh pasukan You Yang di National University of Singapore, University of California, Berkeley, dan Meta AI Research menemui aplikasi baharu model resapan: digunakan untuk menjana parameter model untuk rangkaian saraf.

Alamat kertas: https://arxiv.org/pdf/2402.13144.pdf
Alamat projek: https://github.com/NUS-HPC-AI-Lab/Neural Diffusion
Tajuk kertas: Neural Network Diffusion
Kaedah ini nampaknya memungkinkan untuk menjana model baharu dengan mudah menggunakan rangkaian saraf sedia ada! Yann LeCun menghargai ini dan berkongsinya. Model yang dihasilkan bukan sahaja mengekalkan prestasi model asal, malah mungkin mengatasinya.
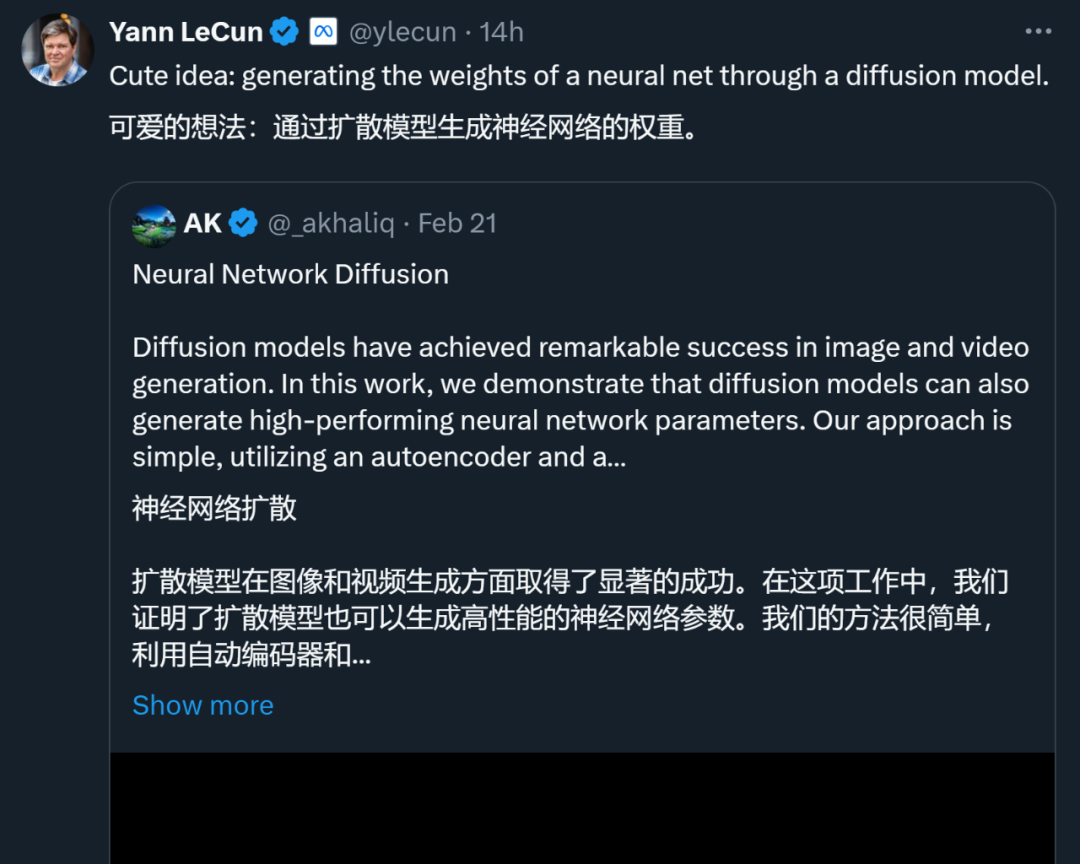
Model resapan pada asalnya berasal daripada konsep termodinamik bukan keseimbangan. Pada tahun 2015, Jascha Sohl-Dickstein et al dalam kertas kerja mereka "Pembelajaran Dalam Tanpa Pengawasan menggunakan Termodinamik Nonequilibrium" mula-mula menggunakan proses resapan untuk mengeluarkan bunyi secara beransur-ansur daripada input, menghasilkan imej yang jelas.
Kerja penyelidikan seterusnya seperti DDPM dan DDIM mengoptimumkan model resapan dan memberikan paradigma latihannya ciri-ciri berbeza bagi proses ke hadapan dan belakang.
Ketika itu, kualiti imej yang dihasilkan oleh model penyebaran masih belum mencapai tahap yang ideal.
GuidedDiffusion Kerja ini menjalankan kajian ablasi yang meluas dan menemui seni bina yang lebih baik ini mula membenarkan model resapan mengatasi kaedah berasaskan GAN dalam kualiti imej. Model kemudian seperti GLIDE, Imagen, DALL·E 2 dan Stable Diffusion sudah boleh menjana imej fotorealistik.
Walaupun model penyebaran telah mencapai kejayaan besar dalam bidang penjanaan wawasan, potensi mereka dalam bidang lain agak kurang diterokai.
Kajian terbaru oleh National University of Singapore, University of California, Berkeley dan Meta AI Research ini telah menemui keupayaan menakjubkan model resapan: menjana parameter model berprestasi tinggi.
Anda mesti tahu bahawa tugas ini pada asasnya berbeza daripada tugas penjanaan visual tradisional! Tugas penjanaan parameter memberi tumpuan kepada mencipta parameter rangkaian saraf yang berfungsi dengan baik pada tugasan tertentu. Para penyelidik sebelum ini telah meneroka tugas ini dari perspektif pemodelan priori dan kemungkinan, seperti rangkaian saraf stokastik dan rangkaian saraf Bayesian. Walau bagaimanapun, tiada siapa sebelum ini mengkaji penggunaan model resapan untuk menjana parameter.
Seperti yang ditunjukkan dalam Rajah 1, memerhati dengan teliti proses latihan dan model resapan rangkaian saraf, kita dapati bahawa kaedah penjanaan imej berasaskan resapan dan proses pembelajaran keturunan kecerunan stokastik (SGD) mempunyai beberapa persamaan: 1) Proses latihan dan resapan rangkaian saraf Proses terbalik model boleh dilihat sebagai proses menukar daripada hingar/permulaan rawak kepada pengedaran tertentu 2) Dengan menambah hingar beberapa kali, imej berkualiti tinggi dan parameter berprestasi tinggi; boleh diturunkan taraf kepada pengagihan mudah, seperti pengagihan Gaussian.
Berdasarkan pemerhatian di atas, pasukan mencadangkan kaedah baharu untuk penjanaan parameter: resapan rangkaian saraf, disingkatkan sebagai p-diff, dengan p merujuk kepada parameter.
Idea kaedah ini sangat mudah, iaitu menggunakan model resapan tersirat standard untuk mensintesis set parameter rangkaian saraf, kerana model resapan boleh menukar taburan rawak yang diberikan kepada taburan tertentu.
Pendekatan mereka adalah mudah: gunakan gabungan pengekod auto dan model resapan terpendam standard untuk mempelajari taburan parameter berprestasi tinggi.
Pertama, untuk subset parameter model yang dilatih menggunakan pengoptimum SGD, pengekod automatik dilatih untuk mengekstrak perwakilan terpendam bagi parameter ini. Kemudian, model resapan terpendam standard digunakan untuk mensintesis perwakilan terpendam bermula daripada hingar. Akhir sekali, pengekod auto terlatih digunakan untuk memproses perwakilan terpendam yang disintesis untuk mendapatkan parameter model berprestasi tinggi baharu.
Kaedah baharu ini mempamerkan dua ciri ini: 1) Pada pelbagai set data dan seni bina, prestasinya adalah setanding dengan data latihannya (iaitu, model yang dilatih oleh pengoptimum SGD) dalam beberapa saat, dan lebih baik mengatasinya; model agak berbeza daripada model terlatih, yang menunjukkan bahawa kaedah baharu boleh mensintesis parameter baharu dan bukannya menghafal sampel latihan.
Neural Network Diffusion
Pengenalan kepada Model Diffusion
Model resapan biasanya terdiri daripada proses ke hadapan dan belakang yang membentuk proses rantaian berbilang langkah dan boleh diindeks mengikut langkah masa.
Proses ke hadapan. Diberi sampel x_0 ∼ q(x), proses ke hadapan adalah untuk menambah secara beransur-ansur hingar Gaussian dalam langkah T untuk mendapatkan x_1, x_2...x_T.
Proses terbalik. Tidak seperti proses ke hadapan, matlamat proses ke belakang adalah untuk melatih rangkaian denoising yang boleh secara rekursif mengeluarkan bunyi dalam x_t. Proses ini adalah kebalikan daripada beberapa langkah, di mana t berkurangan dari T hingga ke 0.
Gambaran Keseluruhan Kaedah Resapan Rangkaian Neural
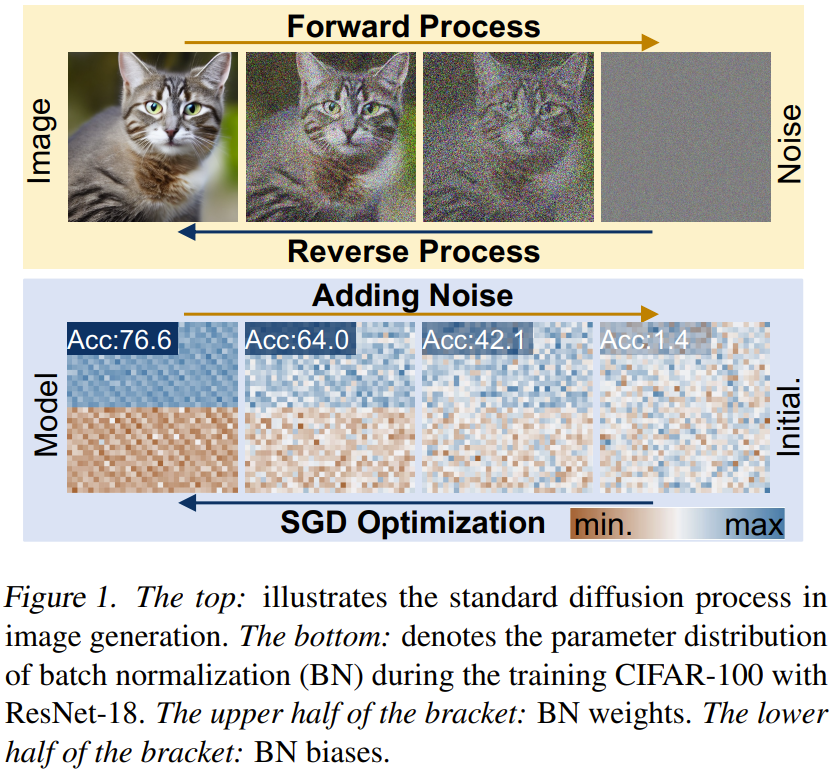
Resapan Rangkaian Neural (p-diff) Matlamat kaedah baharu ini adalah untuk menjana parameter berprestasi tinggi berdasarkan hingar rawak. Seperti yang ditunjukkan dalam Rajah 2, kaedah ini terdiri daripada dua proses: pengekod auto parameter dan penjanaan parameter.
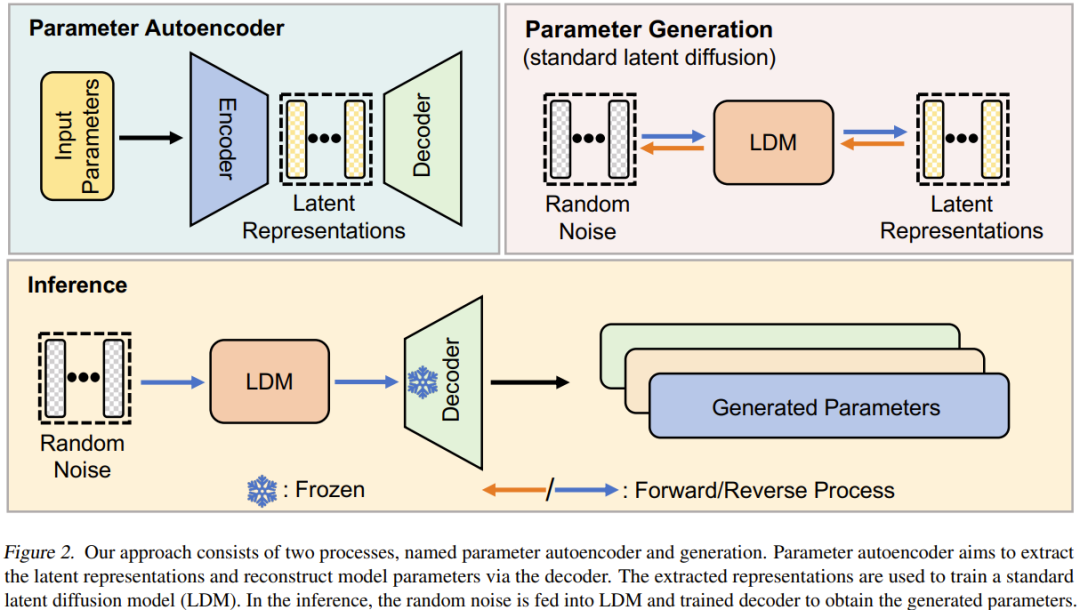
Memandangkan satu set model berprestasi tinggi terlatih, mula-mula pilih subset parameternya dan ratakannya menjadi vektor satu dimensi.
Selepas itu, pengekod digunakan untuk mengekstrak perwakilan tersirat bagi vektor ini, dan penyahkod bertanggungjawab untuk membina semula parameter berdasarkan perwakilan tersirat ini.
Kemudian, model resapan terpendam standard dilatih untuk mensintesis perwakilan terpendam ini berdasarkan hingar rawak.
Selepas latihan, anda boleh menggunakan p-diff untuk menjana parameter baharu melalui proses rantaian sedemikian: hingar rawak → proses terbalik → penyahkod terlatih → parameter yang dijana.
Eksperimen
Pasukan memberikan tetapan percubaan terperinci dalam kertas itu, yang boleh membantu penyelidik lain menghasilkan semula keputusan mereka.
Keputusan
Jadual 1 ialah perbandingan hasil dengan dua kaedah garis dasar pada 8 set data dan 6 seni bina.

Berdasarkan keputusan ini, pemerhatian berikut boleh dibuat: 1) Dalam kebanyakan kes eksperimen, kaedah baharu boleh mencapai hasil yang setanding atau lebih baik daripada dua kaedah asas. Ini menunjukkan bahawa kaedah yang baru dicadangkan boleh mempelajari pengedaran parameter berprestasi tinggi dengan cekap dan menjana model yang lebih baik berdasarkan hingar rawak. 2) Kaedah baharu berfungsi dengan baik pada berbilang set data yang berbeza, yang menunjukkan bahawa kaedah ini mempunyai prestasi generalisasi yang baik.
Kajian dan Analisis Ablasi
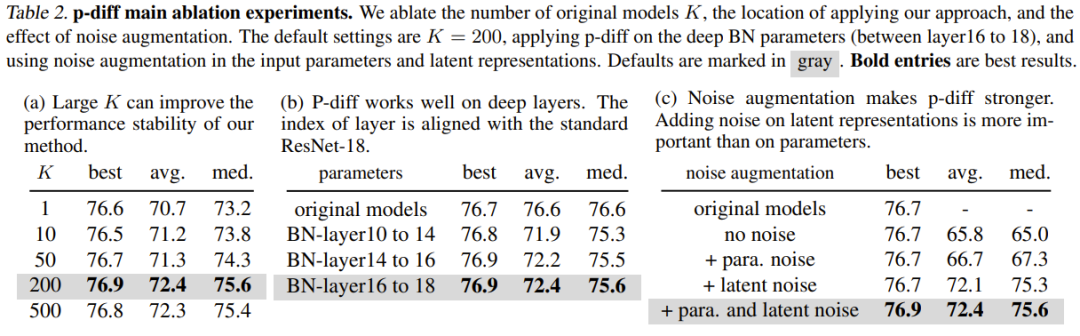
Jadual 2(a) menunjukkan kesan saiz data latihan yang berbeza (iaitu bilangan model asal). Seperti yang dapat dilihat, perbezaan prestasi antara hasil terbaik untuk bilangan model asal yang berbeza sebenarnya tidak begitu besar.
Untuk mengkaji keberkesanan p-diff pada kedalaman lapisan normalisasi yang lain, pasukan juga meneroka prestasi kaedah baharu untuk mensintesis parameter cetek lain. Untuk menjamin bilangan parameter BN yang sama, pasukan itu melaksanakan kaedah yang baru dicadangkan untuk tiga set lapisan BN (yang terletak di antara lapisan kedalaman yang berbeza). Keputusan eksperimen ditunjukkan dalam Jadual 2(b). Dapat dilihat bahawa prestasi (ketepatan terbaik) kaedah baharu adalah lebih baik daripada model asal pada semua kedalaman tetapan lapisan BN.
Tujuan peningkatan hingar adalah untuk meningkatkan keteguhan dan keupayaan generalisasi autopengekod terlatih. Pasukan itu menjalankan kajian ablasi mengenai aplikasi peningkatan hingar pada parameter input dan perwakilan tersirat. Keputusan ditunjukkan dalam Jadual 2(c).
Sebelum ini, percubaan menilai keberkesanan kaedah baharu dalam mensintesis subset parameter model (iaitu, parameter normalisasi kelompok). Jadi kita tidak boleh tidak bertanya: Bolehkah parameter keseluruhan model disintesis menggunakan kaedah ini?
Untuk menjawab soalan ini, pasukan menjalankan eksperimen menggunakan dua seni bina kecil: MLP-3 dan ConvNet-3. Antaranya, MLP-3 mengandungi tiga lapisan linear dan fungsi pengaktifan ReLU, dan ConvNet-3 mengandungi tiga lapisan konvolusi dan satu lapisan linear. Tidak seperti strategi pengumpulan data latihan yang dinyatakan sebelum ini, pasukan melatih seni bina ini dari awal berdasarkan 200 benih rawak yang berbeza.
Jadual 3 memberikan keputusan eksperimen, di mana kaedah baru dibandingkan dengan dua kaedah asas (kaedah asal dan kaedah ensemble). Ia melaporkan perbandingan keputusan dan bilangan parameter ConvNet-3 pada CIFAR-10/100 dan MLP-3 pada CIFAR-10 dan MNIST.

Eksperimen ini menunjukkan keberkesanan dan keupayaan generalisasi kaedah baharu dalam mensintesis parameter model keseluruhan, yang bermaksud kaedah baharu itu mencapai prestasi yang setanding atau lebih baik daripada kaedah garis dasar. Keputusan ini juga boleh menunjukkan potensi aplikasi praktikal kaedah baharu.
Tetapi pasukan itu juga menunjukkan dalam kertas bahawa ia pada masa ini tidak dapat mensintesis parameter keseluruhan seni bina besar seperti ResNet, ViT dan ConvNeXt. Ini dihadkan terutamanya oleh had memori GPU.
Mengenai sebab kaedah baharu ini boleh menjana parameter rangkaian saraf dengan berkesan, pasukan juga cuba meneroka dan menganalisis sebabnya. Mereka melatih ResNet-18 dari awal menggunakan 3 benih rawak dan memvisualisasikan parameternya seperti yang ditunjukkan dalam Rajah 3.
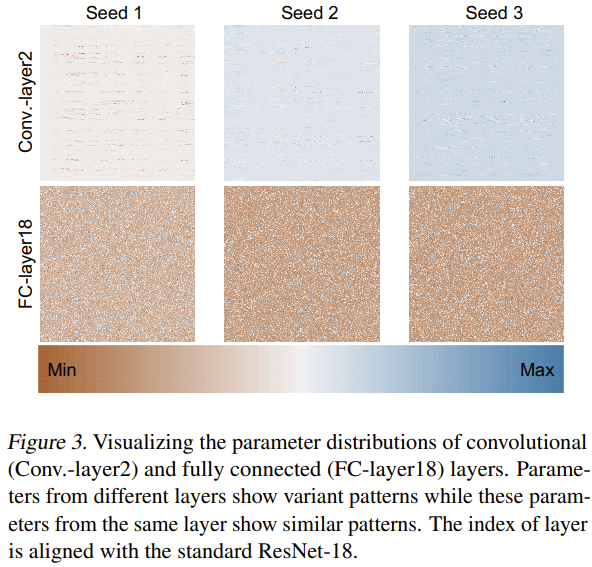
Mereka menggunakan kaedah normalisasi min-maks untuk mendapatkan peta haba bagi taburan parameter lapisan berbeza. Berdasarkan hasil visualisasi lapisan konvolusi (Conv.-layer2) dan lapisan bersambung sepenuhnya (FC-layer18), dapat dilihat bahawa corak parameter tertentu memang wujud dalam lapisan ini. Dengan mempelajari corak ini, kaedah baharu boleh menjana parameter rangkaian saraf berprestasi tinggi.
Adakah p-diff hanya bergantung pada ingatan?
p-diff nampaknya dapat menjana parameter rangkaian saraf, tetapi adakah ia menjana parameter atau hanya mengingatinya? Pasukan melakukan beberapa penyelidikan tentang perkara ini dan membandingkan perbezaan antara model asal dan model yang dijana.
Untuk perbandingan kuantitatif, mereka mencadangkan indeks persamaan. Ringkasnya, penunjuk ini menentukan persamaan antara dua model dengan mengira nisbah Intersection over Union (IoU) hasil ramalan yang salah. Kemudian mereka melakukan beberapa kajian perbandingan dan visualisasi berdasarkan itu. Keputusan perbandingan ditunjukkan dalam Rajah 4.
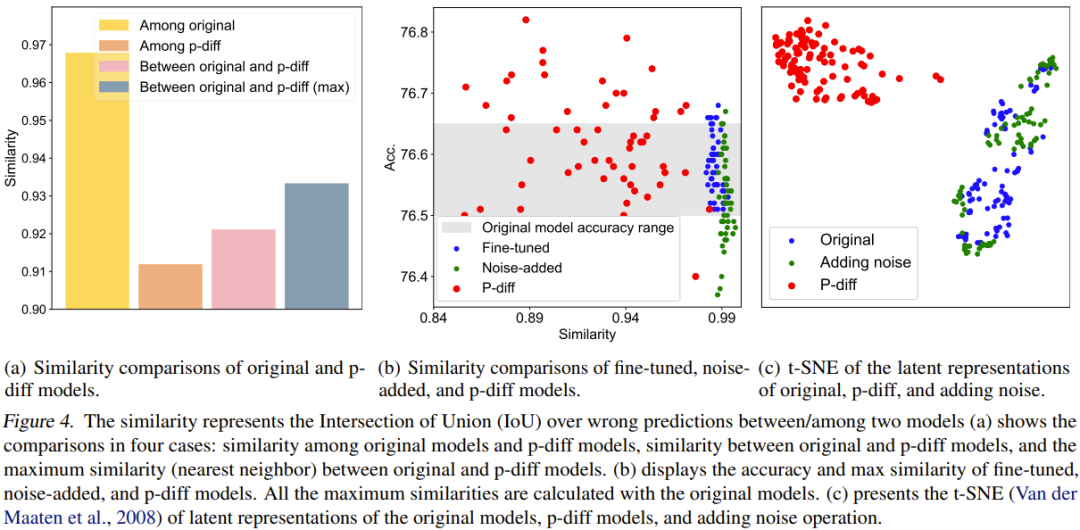
Rajah 4(a) melaporkan perbandingan persamaan antara model asal dan model p-diff, yang melibatkan 4 skema perbandingan.
Seperti yang anda lihat, perbezaan antara model yang dihasilkan adalah jauh lebih besar daripada perbezaan antara model asal. Selain itu, persamaan maksimum antara model asal dan model yang dihasilkan juga lebih rendah daripada persamaan antara model asal. Ini sudah cukup untuk menunjukkan bahawa p-diff boleh menjana parameter baharu yang berbeza daripada data latihannya (iaitu model asal).
Pasukan juga membandingkan kaedah baharu dengan model dan model yang diperhalusi dengan bunyi tambahan. Keputusan ditunjukkan dalam Rajah 4(b).
Dapat dilihat sukar untuk model yang ditala halus dan model dengan bunyi tambahan untuk mengatasi model asal. Tambahan pula, persamaan antara model yang ditala halus atau model dengan bunyi tambahan dan model asal adalah sangat tinggi, menunjukkan bahawa kedua-dua kaedah pengendalian ini tidak boleh mendapatkan model yang baru sepenuhnya dan berprestasi tinggi. Walau bagaimanapun, model yang dihasilkan oleh kaedah baru menunjukkan pelbagai persamaan dan prestasi yang lebih baik daripada model asal.
Pasukan juga membandingkan perwakilan tersirat. Keputusan ditunjukkan dalam Rajah 4(c). Seperti yang dapat dilihat, p-diff boleh menjana perwakilan terpendam yang baharu sepenuhnya, sambil menambah kaedah hingar hanya interpolasi di sekitar perwakilan terpendam model asal.
Pasukan juga menggambarkan trajektori proses p-diff. Secara khusus, mereka memplot trajektori parameter yang dijana pada langkah masa yang berbeza bagi fasa inferens. Rajah 5(a) menunjukkan 5 trajektori (menggunakan 5 permulaan hingar rawak yang berbeza). Pusat merah dalam rajah ialah parameter purata model asal, dan kawasan kelabu ialah sisihan piawainya (std).
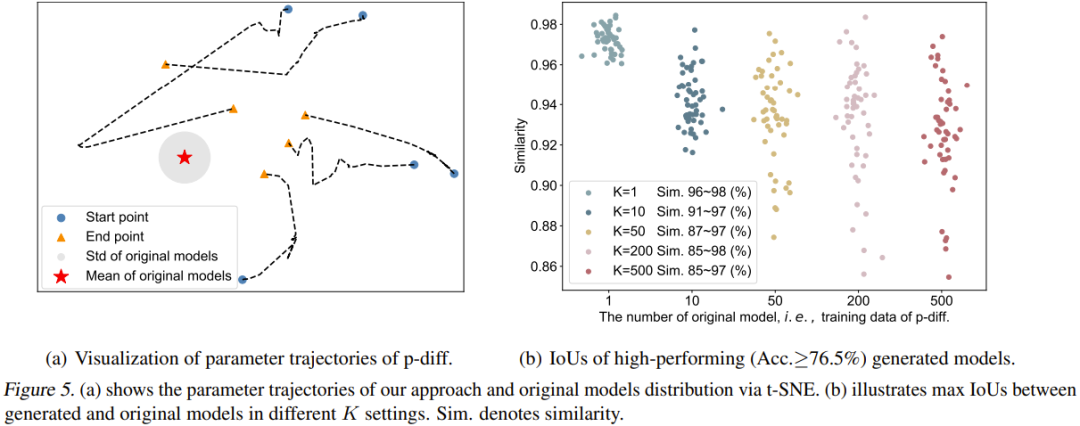
Apabila langkah masa meningkat, parameter yang dijana akan lebih hampir kepada model asal secara keseluruhan. Walau bagaimanapun, ia juga boleh dilihat bahawa titik akhir trajektori ini (segi tiga oren) masih agak jauh dari parameter purata. Selain itu, bentuk lima trajektori ini juga sangat pelbagai.
Akhir sekali, pasukan mengkaji kesan bilangan model asal (K) terhadap kepelbagaian model yang dihasilkan. Rajah 5(b) secara visual menunjukkan persamaan maksimum antara model asal dan model yang dijana untuk K yang berbeza. Khususnya, mereka menjana 50 model dengan terus menjana parameter sehingga 50 model yang dihasilkan berprestasi lebih baik daripada 76.5% dalam semua kes.
Dapat dilihat apabila K=1, persamaan adalah sangat tinggi dan julatnya sempit, menunjukkan bahawa model yang dihasilkan pada masa ini pada asasnya menghafal parameter model asal. Apabila K meningkat, julat persamaan juga menjadi lebih besar, menunjukkan bahawa kaedah baharu boleh menjana parameter yang berbeza daripada model asal.
Atas ialah kandungan terperinci Menggunakan model resapan untuk menjana parameter rangkaian, LeCun memuji penyelidikan baharu pasukan You Yang. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- python开发工程师是做什么的
- 如何创建vscode工程
- Tak sehebat GAN! Artikel yang dikeluarkan oleh Google, DeepMind dan lain-lain: Model penyebaran 'disalin' terus daripada set latihan
- Digabungkan dengan enjin fizik, model resapan GPT-4+ menghasilkan video yang realistik, koheren dan munasabah
- Analisis komprehensif model resapan stabil (termasuk prinsip, teknik, aplikasi dan kesilapan biasa)