
Rumah >Peranti teknologi >AI >Universiti Tsinghua dan Ideal mencadangkan DriveVLM, model bahasa besar visual untuk meningkatkan keupayaan pemanduan autonomi
Universiti Tsinghua dan Ideal mencadangkan DriveVLM, model bahasa besar visual untuk meningkatkan keupayaan pemanduan autonomi

- 王林ke hadapan
- 2024-02-24 08:37:15820semak imbas
Dalam bidang pemanduan autonomi, penyelidik juga meneroka arah model besar seperti GPT/Sora.
Berbanding dengan AI generatif, pemanduan autonomi juga merupakan salah satu bidang penyelidikan dan pembangunan paling aktif dalam AI baru-baru ini. Cabaran utama dalam membina sistem pemanduan autonomi sepenuhnya ialah pemahaman adegan AI, yang melibatkan senario yang kompleks dan tidak dapat diramalkan seperti cuaca buruk, susun atur jalan yang kompleks dan tingkah laku manusia yang tidak dapat diramalkan.
Sistem pemanduan autonomi semasa biasanya terdiri daripada tiga bahagian: persepsi 3D, ramalan gerakan dan perancangan. Secara khusus, persepsi 3D digunakan terutamanya untuk mengesan dan menjejak objek biasa, tetapi keupayaannya untuk mengenal pasti objek yang jarang ditemui dan atributnya adalah terhad manakala ramalan dan perancangan gerakan tertumpu terutamanya pada tindakan trajektori objek, tetapi biasanya mengabaikan hubungan antara objek dan kenderaan; Interaksi peringkat keputusan antara Had ini boleh menjejaskan ketepatan dan keselamatan sistem pemanduan autonomi apabila mengendalikan senario trafik yang kompleks. Oleh itu, teknologi pemanduan autonomi masa hadapan perlu dipertingkatkan lagi untuk mengenal pasti dan meramal pelbagai jenis objek dengan lebih baik, dan untuk merancang laluan pemanduan kenderaan dengan lebih berkesan untuk meningkatkan kecerdasan dan kebolehpercayaan sistem
Kunci untuk mencapai pemanduan autonomi Matlamatnya ialah untuk mengubah pendekatan dipacu data kepada pendekatan dipacu pengetahuan, yang memerlukan latihan model besar dengan keupayaan penaakulan logik. Hanya dengan cara ini sistem pemanduan autonomi boleh benar-benar menyelesaikan masalah ekor panjang dan bergerak ke arah keupayaan L4. Pada masa ini, apabila model berskala besar seperti GPT4 dan Sora terus muncul, kesan skala juga telah menunjukkan keupayaan beberapa pukulan/sifar pukulan yang kuat, yang telah mendorong orang ramai untuk mempertimbangkan arah pembangunan baharu.
Kertas penyelidikan terkini datang daripada Tsinghua University Cross Information Institute dan Li Auto, di mana mereka memperkenalkan model baharu yang dipanggil DriveVLM. Model ini diilhamkan oleh model bahasa visual (VLM) yang muncul dalam bidang kecerdasan buatan generatif. DriveVLM telah menunjukkan keupayaan cemerlang dalam pemahaman visual dan penaakulan.
Kerja ini adalah yang pertama dalam industri yang mencadangkan sistem kawalan kelajuan pemanduan autonomi. Kaedahnya menggabungkan sepenuhnya proses pemanduan autonomi arus perdana dengan proses model berskala besar dengan keupayaan pemikiran logik, dan merupakan kali pertama berjaya menggunakan sistem besar. -model skala ke terminal untuk ujian (Berdasarkan platform Orin).
DriveVLM merangkumi proses Chain-of-Though (CoT), termasuk tiga modul utama: penerangan senario, analisis senario dan perancangan hierarki. Dalam modul penerangan tempat kejadian, bahasa digunakan untuk menerangkan persekitaran pemanduan dan mengenal pasti objek utama di tempat kejadian, modul analisis pemandangan mengkaji secara mendalam ciri-ciri objek utama ini dan kesannya pada kenderaan autonomi manakala modul perancangan hierarki secara beransur-ansur merumuskan rancangan; elemen Tindakan dan keputusan diterangkan kepada titik laluan.
Modul ini sepadan dengan persepsi, ramalan dan langkah perancangan sistem pemanduan autonomi tradisional, tetapi perbezaannya ialah ia mengendalikan persepsi objek, ramalan tahap niat dan perancangan peringkat tugas, yang sangat mencabar pada masa lalu.
Walaupun VLM berprestasi baik dalam pemahaman visual, mereka mempunyai had dalam asas spatial dan penaakulan, dan keperluan kuasa pengkomputeran mereka menimbulkan cabaran kepada kelajuan penaakulan bahagian akhir. Oleh itu, penulis seterusnya mencadangkan DriveVLMDual, sistem hibrid yang menggabungkan kelebihan DriveVLM dan sistem tradisional. DriveVLM-Dual secara pilihan menyepadukan DriveVLM dengan persepsi 3D tradisional dan modul perancangan seperti pengesan objek 3D, rangkaian penghunian dan perancang gerakan, membolehkan sistem mencapai pembumian 3D dan keupayaan perancangan frekuensi tinggi. Reka bentuk dwi-sistem ini adalah serupa dengan proses pemikiran perlahan dan pantas otak manusia dan boleh menyesuaikan diri dengan berkesan kepada kerumitan yang berbeza dalam senario pemanduan.
Penyelidikan baharu juga menjelaskan lagi takrifan tugasan pemahaman dan perancangan (SUP) adegan dan mencadangkan beberapa metrik penilaian baharu untuk menilai keupayaan DriveVLM dan DriveVLM-Dual dalam analisis adegan dan perancangan meta-tindakan. Selain itu, pengarang melakukan kerja perlombongan dan anotasi data yang meluas untuk membina set data SUP-AD dalaman untuk tugasan SUP.
Percubaan meluas pada set data nuScenes dan set data kami sendiri menunjukkan keunggulan DriveVLM, terutamanya dengan sebilangan kecil tangkapan. Tambahan pula, DriveVLM-Dual mengatasi kaedah perancangan gerakan hujung ke hujung yang canggih.
Kertas "DriveVLM: Konvergensi Pemanduan Autonomi dan Model Bahasa Penglihatan Besar"

Pautan kertas: https://arxiv.org/abs/2402.12289
pautan:-mar-Projectsinghua lab.github.io/DriveVLM/
Proses keseluruhan DriveVLM ditunjukkan dalam Rajah 1:
Enkodkan imej visual bingkai berterusan, berinteraksi dengan LMM melalui modul penjajaran ciri
Panduan dari tempat kejadian; memikirkan model VLM, mula-mula membimbing pemandangan statik seperti masa, pemandangan, persekitaran lorong, dsb., dan kemudian membimbing halangan utama yang mempengaruhi keputusan pemanduan
Menganalisis halangan utama dan memadankannya melalui pengesanan 3D tradisional; halangan yang difahami oleh VLM , mengesahkan lagi keberkesanan halangan dan menghapuskan ilusi, menerangkan ciri-ciri halangan utama dalam adegan ini dan kesannya terhadap pemanduan kami
Memberi "meta-keputusan", seperti memperlahankan, meletak kenderaan, membelok ke kiri dan kanan, dsb., dan kemudian memberikan penerangan tentang strategi pemanduan berdasarkan keputusan meta, dan akhirnya memberikan trajektori pemanduan masa hadapan kenderaan tuan rumah.
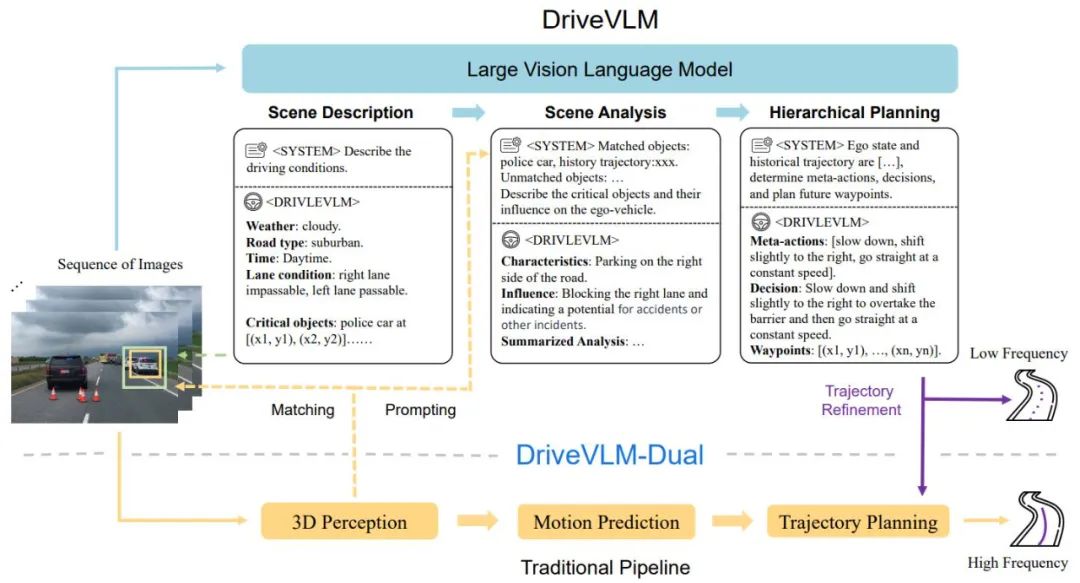
Rajah 1. DriveVLM dan DriveVLM-Dual model saluran paip. Urutan imej diproses oleh model bahasa visual yang besar (VLM) untuk melaksanakan penaakulan rantaian pemikiran (CoT) khas untuk memperoleh hasil perancangan pemanduan. VLM besar melibatkan pengekod pengubah visual dan model bahasa besar (LLM). Pengekod visual menghasilkan teg imej; pengekstrak berasaskan perhatian kemudian menjajarkan teg ini dengan LLM dan akhirnya, LLM melakukan inferens CoT. Proses CoT boleh dibahagikan kepada tiga modul: penerangan senario, analisis senario, dan perancangan hierarki.
DriveVLM-Dual ialah sistem hibrid yang menggunakan pemahaman menyeluruh DriveVLM tentang persekitaran dan cadangan untuk trajektori keputusan untuk meningkatkan keupayaan membuat keputusan dan perancangan Pipeline pemanduan autonomi tradisional. Ia menggabungkan hasil persepsi 3D ke dalam isyarat lisan untuk meningkatkan pemahaman pemandangan 3D dan memperhalusi lagi titik laluan trajektori dengan perancang gerakan masa nyata.
Walaupun VLM pandai mengenal pasti objek berekor panjang dan memahami adegan yang kompleks, mereka sering bergelut untuk memahami lokasi spatial dan status pergerakan terperinci objek secara tepat, kelemahan yang menimbulkan cabaran yang ketara. Lebih memburukkan keadaan, saiz model VLM yang besar menghasilkan kependaman yang tinggi, menghalang keupayaan tindak balas masa nyata pemanduan autonomi. Untuk menangani cabaran ini, penulis mencadangkan DriveVLM-Dual, yang membolehkan DriveVLM dan sistem pemanduan autonomi tradisional bekerjasama. Pendekatan baharu ini melibatkan dua strategi utama: analisis objek utama digabungkan dengan persepsi 3D untuk memberikan maklumat keputusan pemanduan berdimensi tinggi, dan penghalusan trajektori frekuensi tinggi.
Selain itu, untuk merealisasikan sepenuhnya potensi DriveVLM dan DriveVLMDual dalam mengendalikan senario pemanduan yang kompleks dan ekor panjang, para penyelidik secara rasmi mentakrifkan tugas yang dipanggil perancangan pemahaman adegan, serta satu set metrik penilaian. Tambahan pula, pengarang mencadangkan protokol perlombongan dan anotasi data untuk mengurus pemahaman adegan dan set data perancangan.
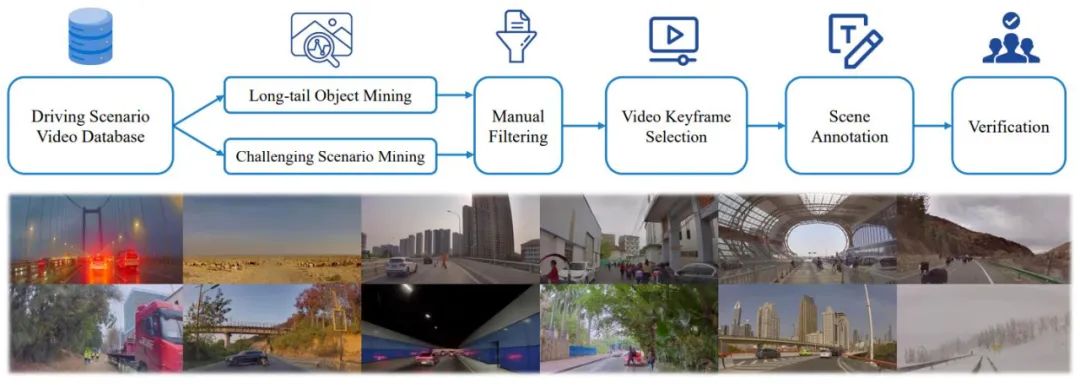
Untuk melatih model sepenuhnya, penulis telah membangunkan satu set alat anotasi Drive LLM dan penyelesaian anotasi Melalui gabungan perlombongan automatik, pra-memberus persepsi, ringkasan model besar GPT-4 dan anotasi manual, model semasa telah dibentuk Dengan skema anotasi yang cekap ini, setiap data Klip mengandungi berpuluh-puluh kandungan anotasi. -Rajah 2. Sampel pengumuman set data SUP-AD.

Rajah 3. Saluran paip data dan anotasi untuk membina pemahaman senario dan merancang set data (di atas). Contoh senario yang diambil secara rawak daripada set data (di bawah) menunjukkan kepelbagaian dan kerumitan set data.
dataset nuScenes ialah set data memandu pemandangan bandar berskala besar dengan 1000 adegan, setiap satu berdurasi kira-kira 20 saat. Bingkai kunci dianotasi secara seragam pada 2Hz merentas keseluruhan set data. Di sini, penulis menggunakan ralat anjakan (DE) dan kadar perlanggaran (CR) sebagai penunjuk untuk menilai prestasi model pada pembahagian pengesahan. Pengarang menunjukkan prestasi DriveVLM dengan beberapa model bahasa visual berskala besar dan membandingkannya dengan GPT-4V, seperti ditunjukkan dalam Jadual 1. DriveVLM menggunakan Qwen-VL sebagai tulang belakangnya, yang mencapai prestasi terbaik berbanding VLM sumber terbuka lain dan dicirikan oleh responsif dan interaksi yang fleksibel. Dua model besar pertama telah menjadi sumber terbuka dan menggunakan data yang sama untuk latihan penalaan halus GPT-4V menggunakan gesaan kompleks untuk kejuruteraan segera. 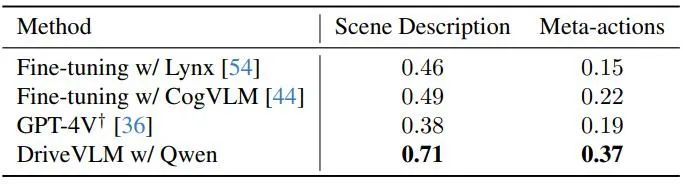
Jadual 1. Keputusan set ujian pada set data SUP-AD. API rasmi GPT-4V digunakan di sini, dan untuk Lynx dan CogVLM, pembahagian latihan digunakan untuk penalaan halus.
Seperti yang ditunjukkan dalam Jadual 2, DriveVLM-Dual mencapai prestasi terkini pada tugas perancangan nuScenes apabila digandingkan dengan VAD. Ini menunjukkan bahawa kaedah baharu, walaupun disesuaikan untuk memahami adegan yang kompleks, juga berfungsi dengan baik dalam adegan biasa. Ambil perhatian bahawa DriveVLM-Dual bertambah baik dengan ketara berbanding UniAD: ralat anjakan perancangan purata dikurangkan sebanyak 0.64 meter dan kadar perlanggaran dikurangkan sebanyak 51%.
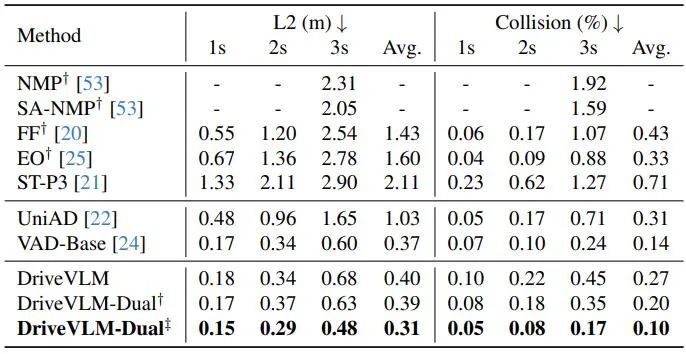
Jadual 2. Keputusan perancangan untuk set data pengesahan nuScenes. DriveVLM-Dual mencapai prestasi optimum. †Mewakili persepsi dan keputusan ramalan penghunian menggunakan Uni-AD. ‡ Menunjukkan bekerja dengan VAD, di mana semua model mengambil keadaan ego sebagai input. Rajah 4. Keputusan kualitatif DriveVLM. Lengkung oren mewakili trajektori masa depan yang dirancang model dalam tempoh 3 saat seterusnya. 
Atas ialah kandungan terperinci Universiti Tsinghua dan Ideal mencadangkan DriveVLM, model bahasa besar visual untuk meningkatkan keupayaan pemanduan autonomi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 世界vr产业大会地址在哪
- Korea Selatan mengumumkan bahawa ia akan melabur 500 bilion won dalam tempoh lima tahun akan datang untuk menyokong industri teras teknologi AI.
- Bagaimanakah robot kolaboratif boleh memperkasakan pembuatan dan peningkatan pintar industri kimia harian? Dengar apa yang pakar katakan
- Liu Qiang: Membina ekosistem kandungan industri pelancongan budaya Internet generasi seterusnya
- Perkembangan pesat sistem pengendalian Hongmeng pada pelbagai peranti akan membuka industri baharu bernilai trilion