
Rumah >Peranti teknologi >AI >Model RNN mencabar hegemoni Transformer! 1% kos dan prestasi setanding dengan Mistral-7B, menyokong 100+ bahasa, yang paling banyak di dunia
Model RNN mencabar hegemoni Transformer! 1% kos dan prestasi setanding dengan Mistral-7B, menyokong 100+ bahasa, yang paling banyak di dunia

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-19 21:30:39990semak imbas
Sementara model besar dilancarkan, status Transformer turut dicabar satu demi satu.
Baru-baru ini, RWKV mengeluarkan model Eagle 7B, berdasarkan seni bina RWKV-v5 terkini.
Eagle 7B cemerlang dalam penanda aras berbilang bahasa dan setanding dengan model teratas dalam ujian Bahasa Inggeris.
Pada masa yang sama, Eagle 7B menggunakan seni bina RNN Berbanding dengan model Transformer dengan saiz yang sama, kos inferens dikurangkan lebih daripada 10-100 kali ganda model di dunia.
Memandangkan kertas mengenai RWKV-v5 mungkin tidak akan dikeluarkan sehingga bulan depan, kami mula-mula menyediakan kertas mengenai RWKV, yang merupakan seni bina bukan Transformer pertama yang menskalakan parameter kepada puluhan bilion.
 Pictures
Pictures
paper Alamat: https://arxiv.org/pdf/2305.13048.pdf
emnlp 2023 telah menerima karya ini. dunia.
Berikut adalah gambar rasmi Eagle 7B, yang menunjukkan bahawa helang ini sedang terbang di atas Transformers. .
 Tanda aras termasuk xLAMBDA, xStoryCloze, xWinograd dan xCopa, meliputi 23 bahasa, serta penaakulan akal dalam bahasa masing-masing.
Tanda aras termasuk xLAMBDA, xStoryCloze, xWinograd dan xCopa, meliputi 23 bahasa, serta penaakulan akal dalam bahasa masing-masing.
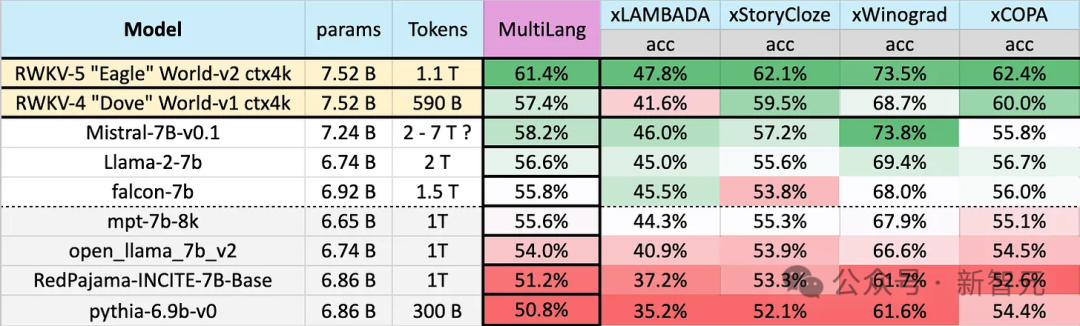
Eagle 7B memenangi tempat pertama dalam tiga daripadanya Walaupun salah seorang daripada mereka tidak menewaskan Mistral-7B dan menduduki tempat kedua, data latihan yang digunakan pihak lawan jauh lebih tinggi daripada Eagle.
Gambar
Ujian Bahasa Inggeris dalam gambar di bawah mengandungi 12 tanda aras berasingan, penaakulan akal dan pengetahuan dunia.
Dalam ujian prestasi Bahasa Inggeris, tahap Eagle 7B adalah hampir dengan Falcon (1.5T), LLaMA2 (2T), Mistral (>2T), dan setanding dengan MPT-7B, yang juga menggunakan kira-kira latihan 1T data.
 Gambar
Gambar
Dan, dalam kedua-dua ujian, seni bina v5 baharu telah membuat lonjakan keseluruhan yang besar berbanding v4 sebelumnya.
Eagle 7B kini dihoskan oleh Yayasan Linux dan dilesenkan di bawah lesen Apache 2.0 untuk kegunaan peribadi atau komersial tanpa had.
 Sokongan berbilang bahasa
Sokongan berbilang bahasa
Seperti yang dinyatakan sebelum ini, data latihan Eagle 7B datang daripada lebih daripada 100 bahasa, manakala 4 penanda aras berbilang bahasa yang digunakan di atas hanya merangkumi 23 bahasa. .
Kos latihan tambahan tidak akan membantu anda meningkatkan kedudukan anda Jika anda fokus pada bahasa Inggeris, anda mungkin mendapat keputusan yang lebih baik daripada yang anda lakukan sekarang.
——Jadi, mengapa RWKV melakukan ini? Pegawai itu berkata:
Membina AI inklusif untuk semua orang di dunia ini —— bukan hanya bahasa Inggeris
Di antara banyak maklum balas tentang model RWKV, yang paling biasa ialah: 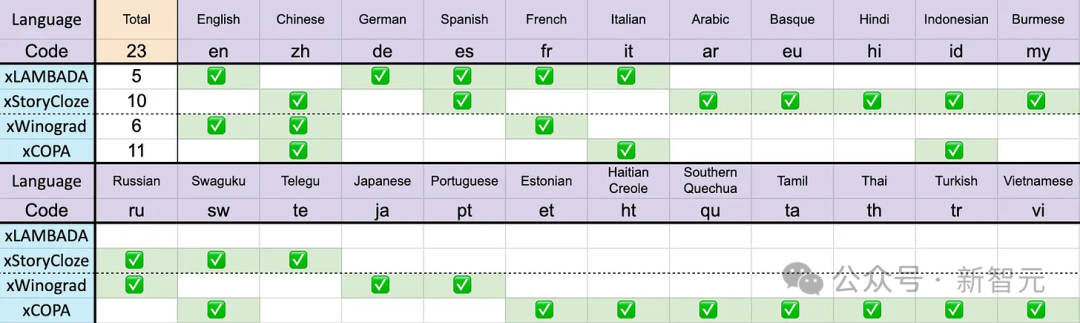
Adalah tidak adil untuk membandingkan prestasi berbilang bahasa dengan model Inggeris tulen
Secara rasmi menyatakan, "Dalam kebanyakan kes, kami Setuju dengan ini. pendapat,"
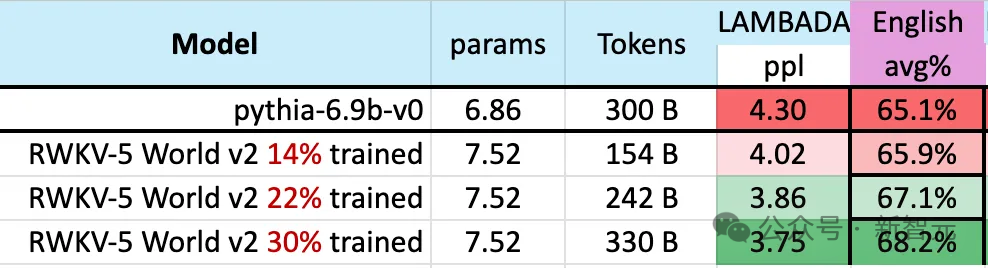
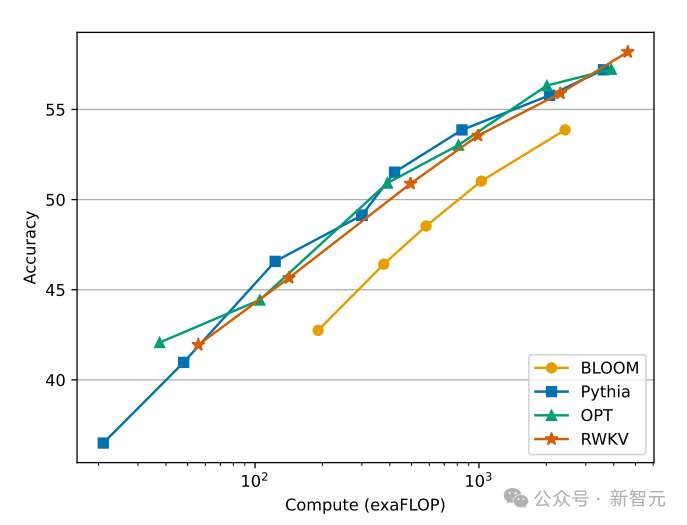
"Tetapi kami tidak bercadang untuk mengubahnya, kerana kami sedang membina AI untuk dunia - dan ia bukan hanya dunia berbahasa Inggeris Pada tahun 2023, hanya 17% daripada 17%." penduduk dunia bahasa Inggeris dituturkan (kira-kira 1.3 bilion orang), tetapi dengan menyokong 25 bahasa teratas dunia, model ini boleh mencapai kira-kira 4 bilion orang, atau 50% daripada populasi dunia. Pasukan berharap kecerdasan buatan masa hadapan dapat membantu semua orang, seperti membenarkan model berjalan pada perkakasan kelas rendah pada harga yang rendah, seperti menyokong lebih banyak bahasa. Pasukan akan mengembangkan set data berbilang bahasa secara beransur-ansur untuk menyokong julat bahasa yang lebih luas dan perlahan-lahan mengembangkan liputan kepada 100% wilayah dunia - memastikan tiada bahasa yang tertinggal. Semasa proses latihan model, terdapat fenomena yang perlu diberi perhatian: Apabila skala data latihan terus meningkat, prestasi model secara beransur-ansur bertambah baik. Apabila data latihan mencapai Pada sekitar 300B, model menunjukkan prestasi yang serupa dengan python-6.9b, yang mempunyai saiz data latihan 300B. Fenomena ini adalah sama seperti eksperimen yang dijalankan sebelum ini pada seni bina RWKV-v4 - iaitu, apabila saiz data latihan adalah sama, prestasi Transformer linear seperti RWKV Ia akan menjadi serupa dengan Transformer. Jadi kami tidak boleh tidak bertanya, jika ini benar-benar berlaku, adakah data lebih penting untuk peningkatan prestasi model daripada seni bina yang tepat? Kita tahu bahawa pengiraan dan kos penyimpanan model kelas Transformer adalah paras persegi, manakala dalam rajah di atas, kos pengiraan seni bina RWKV hanya meningkat secara linear dengan bilangan Token. Mungkin kita harus melihat kepada seni bina yang lebih cekap dan berskala untuk meningkatkan kebolehcapaian, mengurangkan kos AI untuk semua orang dan mengurangkan kesan alam sekitar. Senibina RWKV ialah RNN dengan prestasi LLM peringkat GPT, sambil boleh dilatih secara selari seperti Transformer. RWKV menggabungkan kelebihan RNN dan Transformer - prestasi cemerlang, inferens pantas, latihan pantas, penjimatan VRAM, panjang konteks "tidak terhad" dan RWKV tidak menggunakan mekanisme perhatian. Angka berikut menunjukkan perbandingan kos pengiraan antara model RWKV dan Transformer: Untuk menyelesaikan masalah kerumitan masa dan ruang bagi seni bina Transformer, penyelidik telah mencadangkan: . gambar di bawah ialah elemen blok RWKV, dengan blok baki RWKV di sebelah kanan dan pengepala akhir untuk pemodelan bahasa. Rekursi boleh dinyatakan sebagai interpolasi linear antara input semasa dan input langkah masa sebelumnya (seperti yang ditunjukkan oleh garis pepenjuru dalam rajah di bawah), yang boleh bebas untuk setiap linear unjuran Pelarasan benam input. Satu vektor yang mengendalikan Token semasa secara berasingan juga diperkenalkan di sini untuk mengimbangi potensi kemerosotan. RWKV boleh disejajarkan dengan cekap (pendaraban matriks) dalam apa yang kita panggil mod selari temporal. Dalam rangkaian berulang, output momen sebelumnya biasanya digunakan sebagai input momen semasa. Ini amat jelas dalam inferens penyahkodan autoregresif untuk model bahasa, yang memerlukan setiap token dikira sebelum memasukkan langkah seterusnya, membolehkan RWKV memanfaatkan struktur seperti RNNnya, yang dipanggil mod temporal. Dalam kes ini, RWKV boleh dirumus dengan mudah secara rekursif untuk penyahkodan semasa inferens Ia mengambil kesempatan daripada setiap token keluaran hanya bergantung pada keadaan terkini Saiz keadaan adalah malar, tidak seperti dengan Panjang jujukan tidak relevan. kemudian bertindak sebagai penyahkod RNN, menghasilkan kelajuan malar dan jejak memori berbanding dengan panjang jujukan, membolehkan jujukan yang lebih panjang diproses dengan lebih cekap. Sebaliknya, cache KV perhatian diri berkembang secara berterusan berbanding panjang jujukan, mengakibatkan kecekapan berkurangan dan peningkatan jejak memori dan masa apabila jujukan itu memanjang. Rujukan:  Gambar
GambarSet data + seni bina berskala
 Gambar
Gambar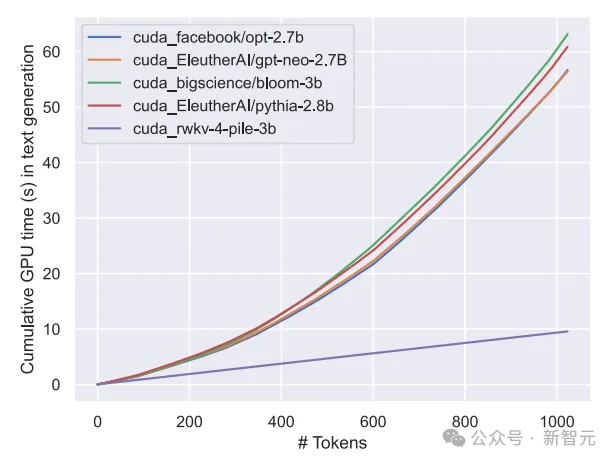 Gambar
Gambar
RWKV
 Gambar
Gambar 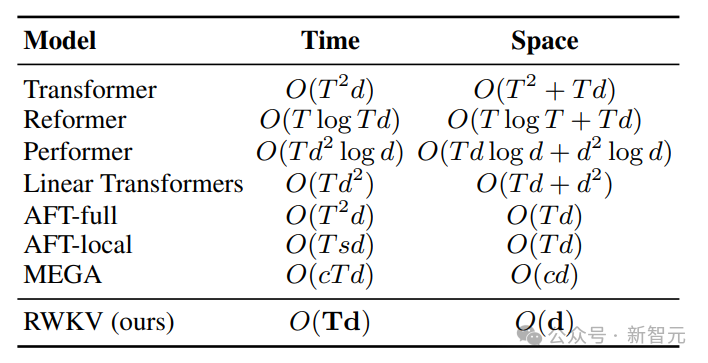 Gambar
Gambar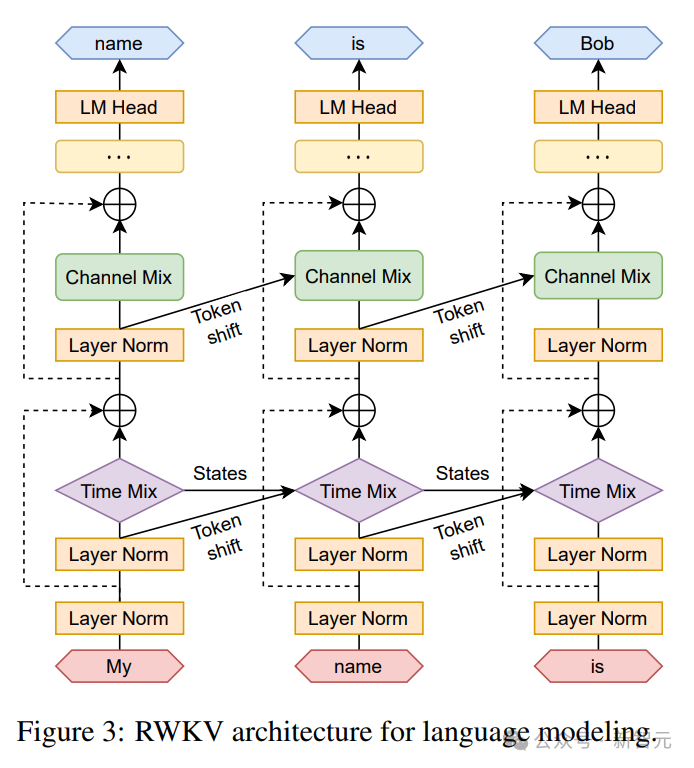 Gambar
Gambar
Atas ialah kandungan terperinci Model RNN mencabar hegemoni Transformer! 1% kos dan prestasi setanding dengan Mistral-7B, menyokong 100+ bahasa, yang paling banyak di dunia. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!