
Rumah >Peranti teknologi >AI >SOTA baharu Vincent Tu! Pika, Universiti Peking dan Stanford bersama-sama melancarkan RPG, multi-modal untuk membantu menyelesaikan dua masalah utama Wenshengtu
SOTA baharu Vincent Tu! Pika, Universiti Peking dan Stanford bersama-sama melancarkan RPG, multi-modal untuk membantu menyelesaikan dua masalah utama Wenshengtu

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-19 09:06:14625semak imbas
Baru-baru ini, Universiti Peking, Stanford, dan Pika Labs yang popular bersama-sama menerbitkan satu kajian yang telah meningkatkan keupayaan graf Vincentian model besar ke tahap yang baharu.

Alamat kertas: https://arxiv.org/pdf/2401.11708.pdf
Alamat kod: https://github.com/YangLing0818/RPG🜎 pengarang makalah Pendekatan inovatif diambil untuk menambah baik rangka kerja penjanaan/penyuntingan teks kepada imej dengan memanfaatkan keupayaan inferens model bahasa besar berbilang mod (MLLM).
Dalam erti kata lain, kaedah ini bertujuan untuk meningkatkan prestasi model penjanaan teks apabila memproses gesaan teks kompleks yang mengandungi berbilang atribut, perhubungan dan objek.
Tanpa berlengah lagi, inilah gambarnya:
 Seorang gadis twintail hijau berpakaian oren sedang duduk di atas sofa manakala meja yang tidak kemas di bawah tingkap besar di sebelah kiri, akuarium yang meriah berada di sebelah kiri. atas sebelah kanan sofa, gaya realistik.
Seorang gadis twintail hijau berpakaian oren sedang duduk di atas sofa manakala meja yang tidak kemas di bawah tingkap besar di sebelah kiri, akuarium yang meriah berada di sebelah kiri. atas sebelah kanan sofa, gaya realistik.
Seorang gadis berekor berkembar berbaju oren sedang duduk di atas sofa di sebelah tingkap besar terdapat sebuah meja yang bersepah-sepah di bahagian atas sebelah kanan iaitu bilik adalah gaya realistik.
Berdepan dengan pelbagai objek dengan hubungan yang kompleks, struktur keseluruhan gambar dan hubungan antara orang dan objek yang diberikan oleh model adalah sangat munasabah, menjadikan mata penonton cerah.
Untuk gesaan yang sama, mari kita lihat prestasi SDXL terkini dan DALL·E 3:
Mari kita lihat rangka kerja baharu apabila ia datang untuk mengikat berbilang atribut kepada berbilang objek Prestasi: 
 Dari kiri ke kanan, seorang gadis Eropah ekor kuda berambut perang berbaju putih, seorang gadis Afrika berambut kerinting coklat berbaju biru bercetak dengan seekor burung, seorang anak muda Asia. lelaki berambut pendek hitam dalam sut sedang berjalan di dalam kampus dengan gembira.
Dari kiri ke kanan, seorang gadis Eropah ekor kuda berambut perang berbaju putih, seorang gadis Afrika berambut kerinting coklat berbaju biru bercetak dengan seekor burung, seorang anak muda Asia. lelaki berambut pendek hitam dalam sut sedang berjalan di dalam kampus dengan gembira.
Dari kiri ke kanan, seorang gadis Eropah memakai baju putih dengan ekor kuda berambut perang, seorang gadis Afrika berambut kerinting coklat memakai baju biru dengan cetakan burung itu, dan seorang gadis yang memakai sut, lelaki Asia muda dengan rambut hitam pendek berjalan dengan gembira di kampus.
Para penyelidik menamakan rangka kerja ini RPG (Recaption, Plan and Generate), menggunakan MLLM sebagai perancang global untuk menguraikan proses penjanaan imej yang kompleks kepada berbilang tugas penjanaan yang lebih mudah dalam sub-rantau.
Makalah ini mencadangkan penyebaran wilayah pelengkap untuk mencapai penjanaan gabungan wilayah, dan juga menyepadukan penjanaan imej berpandukan teks dan penyuntingan ke dalam rangka kerja RPG secara gelung tertutup, dengan itu meningkatkan keupayaan generalisasi. 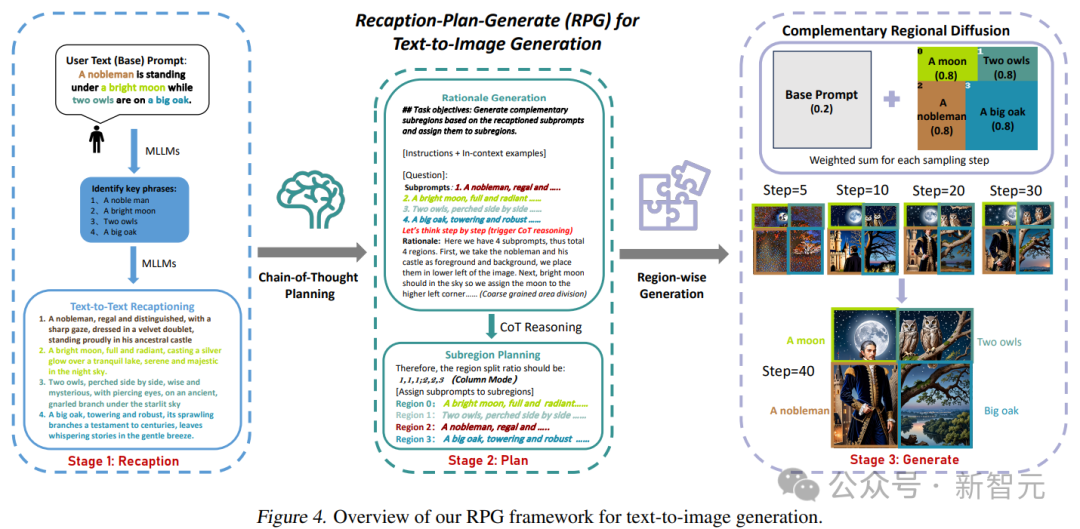
Percubaan menunjukkan bahawa rangka kerja RPG yang dicadangkan dalam kertas kerja ini mengatasi model penyebaran imej teks terkini, termasuk DALL·E 3 dan SDXL, terutamanya dalam sintesis objek berbilang kategori dan penjajaran semantik imej teks.
Perlu diingat bahawa rangka kerja RPG serasi secara meluas dengan pelbagai seni bina MLLM (seperti MiniGPT-4) dan rangkaian tulang belakang resapan (seperti ControlNet).
RPG
Terdapat dua masalah utama dengan model graf Vincentian semasa: 1. Kaedah berasaskan reka letak atau berasaskan perhatian hanya boleh memberikan panduan spatial yang kasar dan mengalami kesukaran mengendalikan objek bertindih 2. Kaedah berasaskan maklum balas memerlukan Kumpul data maklum balas berkualiti tinggi dan menanggung kos latihan tambahan.Untuk menyelesaikan masalah ini, penyelidik mencadangkan tiga strategi teras RPG, seperti yang ditunjukkan dalam rajah di bawah:
Memandangkan gesaan teks kompleks yang mengandungi berbilang entiti dan perhubungan, mula-mula gunakan MLLM menjadi untuk Ia diurai isyarat asas dan sub-isyarat yang sangat deskriptif kemudiannya, ruang imej dibahagikan kepada sub-rantau pelengkap menggunakan perancangan CoT model berbilang modal akhirnya, penyebaran wilayah pelengkap diperkenalkan untuk menjana imej setiap sub-rantau secara bebas, dan Pengagregatan dilakukan pada setiap langkah persampelan. 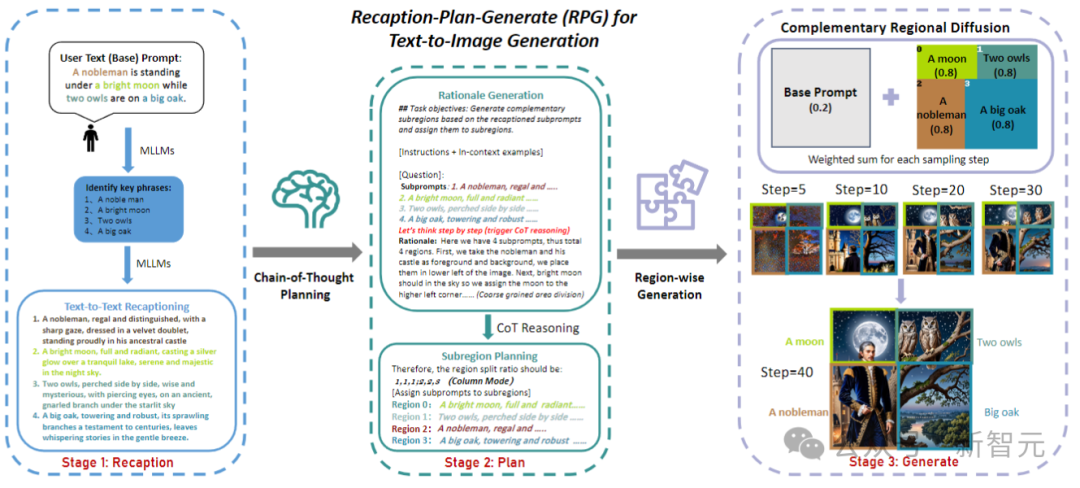
Penalaan semula berbilang modal
mengubah isyarat teks kepada isyarat yang sangat deskriptif, memberikan pemahaman kiu yang dipertingkatkan maklumat dan penjajaran semantik dalam model resapan.
Gunakan MLLM untuk mengenal pasti frasa utama dalam gesaan pengguna y dan dapatkan sub-item di dalamnya:
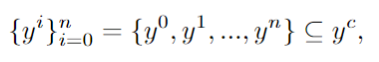
Gunakan LLM untuk menguraikan gesaan teks menjadi gesaan yang berbeza dan menerangkannya semula dengan lebih terperinci :
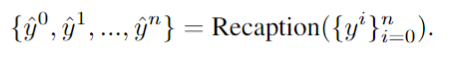
Dengan cara ini, butiran berbutir halus yang lebih padat boleh dijana untuk setiap subkiu untuk meningkatkan kesetiaan imej yang dijana dengan berkesan dan mengurangkan perbezaan semantik antara isyarat dan imej. .
Secara khusus, ruang imej H×W dibahagikan kepada beberapa kawasan pelengkap, dan setiap gesaan penambah diberikan kepada kawasan tertentu R:
Menggunakan keupayaan penaakulan rantai pemikiran yang berkuasa MLLM, pengezonan yang berkesan. Dengan menganalisis hasil perantaraan yang diperoleh, prinsip terperinci dan arahan yang tepat boleh dijana untuk sintesis imej seterusnya.
Resapan Kawasan Tambahan
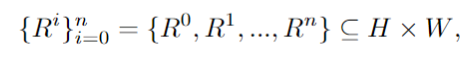
Kaedah ini berkesan menyelesaikan masalah model besar yang mengalami kesukaran mengendalikan objek bertindih. Tambahan pula, kertas kerja ini memanjangkan rangka kerja ini untuk menyesuaikan diri dengan tugasan penyuntingan, menggunakan penyebaran wilayah berasaskan kontur untuk beroperasi dengan tepat pada kawasan tidak konsisten yang memerlukan pengubahsuaian.
Suntingan imej berpandukan teks
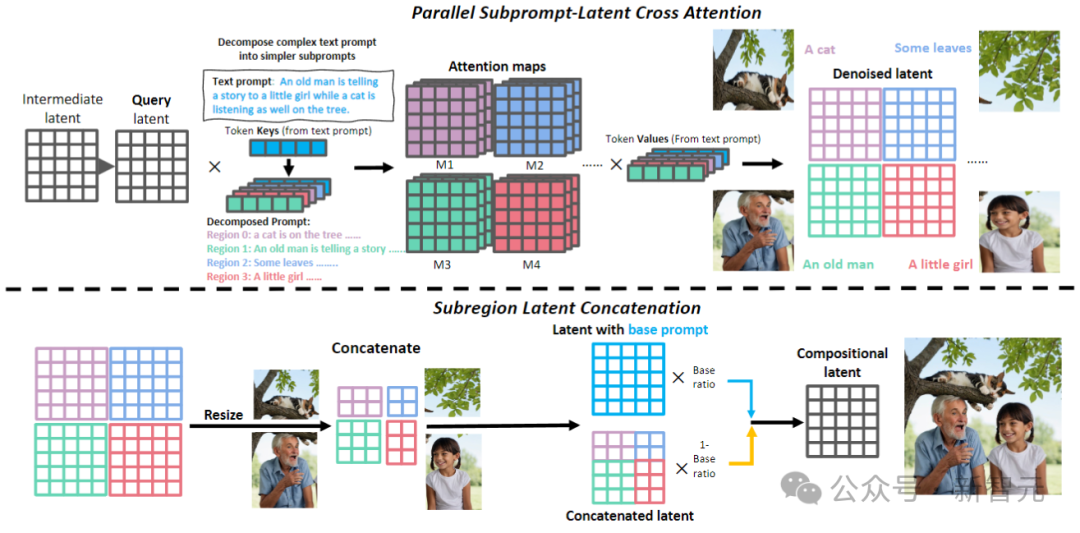
seperti yang ditunjukkan dalam gambar di atas. Dalam peringkat penceritaan semula, RPG menggunakan MLLM sebagai sari kata untuk menceritakan semula imej sumber dan menggunakan keupayaan penaakulan yang berkuasa untuk mengenal pasti perbezaan semantik yang halus antara imej dan kiu sasaran, menganalisis secara langsung cara imej input sejajar dengan kiu sasaran.
Gunakan MLLM (GPT-4, Gemini Pro, dll.) untuk menyemak perbezaan antara input dan sasaran mengenai ketepatan berangka, pengikatan sifat dan perhubungan objek. Maklum balas pemahaman multimodal yang terhasil akan dihantar kepada MLLM untuk perancangan penyuntingan inferens.
Kita boleh lihat dalam semua. tiga ujian Daripada permainan, hanya RPG yang paling tepat menggambarkan perkara yang diterangkan oleh gesaan.
Kemudian ada ketepatan berangka, susunan paparan adalah sama seperti di atas (SDXL, DALL·E 3, LMD+, RPG):

-Tak sangka kira agak sukar untuk model figura Vincent yang besar Ya, RPG dengan mudah mengalahkan lawan.
Item terakhir adalah untuk memulihkan hubungan yang kompleks dalam gesaan:

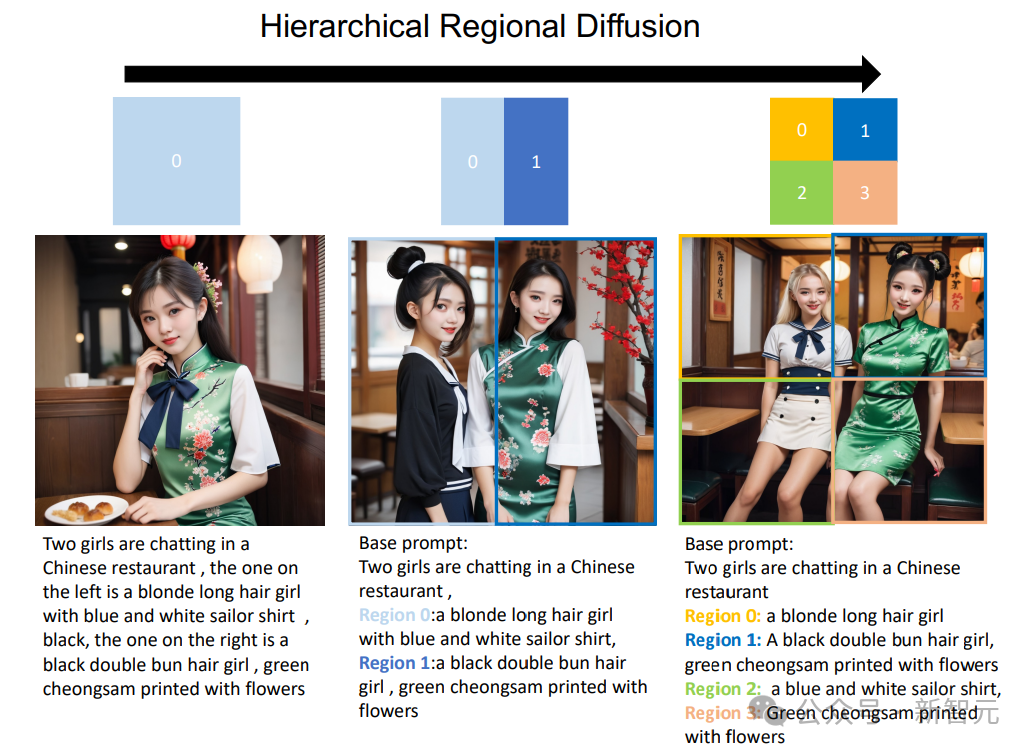
Selain itu, penyebaran zon boleh dilanjutkan kepada format hierarki, membahagikan sub-rantau tertentu kepada sub-rantau yang lebih kecil.
Seperti yang ditunjukkan dalam rajah di bawah, RPG boleh mencapai peningkatan ketara dalam penjanaan teks-ke-imej apabila menambahkan hierarki pembahagian wilayah. Ini memberikan perspektif baharu untuk mengendalikan tugas penjanaan yang kompleks, membolehkan anda menjana imej komposisi sewenang-wenangnya.
Atas ialah kandungan terperinci SOTA baharu Vincent Tu! Pika, Universiti Peking dan Stanford bersama-sama melancarkan RPG, multi-modal untuk membantu menyelesaikan dua masalah utama Wenshengtu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!