Robot ini dinamakan Cassie dan pernah mencipta rekod dunia dalam larian 100 meter. Baru-baru ini, penyelidik di University of California, Berkeley, membangunkan algoritma pembelajaran tetulang yang mendalam untuknya, membolehkannya menguasai kemahiran seperti selekoh tajam dan menentang pelbagai gangguan.
 . Cabaran timbul daripada kerumitan dinamik robot bipedal yang tidak digerakkan dan perancangan berbeza yang dikaitkan dengan setiap kemahiran lokomotor. Persoalan utama yang penyelidik harap dapat selesaikan ialah: Bagaimana untuk membangunkan penyelesaian untuk robot bipedal bersaiz tinggi manusia? Bagaimana untuk mengawal kemahiran pergerakan kaki yang pelbagai, tangkas dan mantap seperti berjalan, berlari dan melompat?
. Cabaran timbul daripada kerumitan dinamik robot bipedal yang tidak digerakkan dan perancangan berbeza yang dikaitkan dengan setiap kemahiran lokomotor. Persoalan utama yang penyelidik harap dapat selesaikan ialah: Bagaimana untuk membangunkan penyelesaian untuk robot bipedal bersaiz tinggi manusia? Bagaimana untuk mengawal kemahiran pergerakan kaki yang pelbagai, tangkas dan mantap seperti berjalan, berlari dan melompat?
Kajian terbaru mungkin memberikan penyelesaian yang baik.
Dalam kerja ini, penyelidik dari Berkeley dan institusi lain menggunakan pembelajaran tetulang (RL) untuk mencipta pengawal bagi robot bipedal bukan linear berdimensi tinggi di dunia nyata untuk menangani cabaran di atas. Pengawal ini boleh memanfaatkan maklumat proprioseptif robot untuk menyesuaikan diri dengan dinamik tidak menentu yang berubah dari semasa ke semasa, sambil dapat menyesuaikan diri dengan persekitaran dan tetapan baharu, memanfaatkan ketangkasan robot dwipedal untuk mempamerkan tingkah laku yang mantap dalam situasi yang tidak dijangka. Tambahan pula, rangka kerja kami menyediakan resipi umum untuk menghasilkan semula pelbagai kemahiran lokomotor dwipedal.
Tajuk kertas: Pembelajaran Pengukuhan untuk Kawalan Pergerakan Dwipedal Serbaguna, Dinamik dan Teguh
-
Pautan kertas: https://arxiv.org/pdf/2401.
-
Dimensi tinggi dan tidak linear robot dwipedal bersaiz manusia yang dikawal tork mungkin pada mulanya kelihatan sebagai halangan untuk pengawal, namun ciri ini mempunyai kelebihan untuk membolehkan pelaksanaan yang kompleks melalui dinamik dimensi tinggi daripada operasi tangkas.
Kemahiran yang diberikan oleh pengawal ini kepada robot ditunjukkan dalam Rajah 1, termasuk berdiri stabil, berjalan, berlari dan melompat. Kemahiran ini juga boleh digunakan untuk melakukan pelbagai tugas yang berbeza, termasuk berjalan pada kelajuan dan ketinggian yang berbeza, berlari pada kelajuan dan arah yang berbeza, dan melompat ke pelbagai sasaran, sambil mengekalkan keteguhan semasa penggunaan sebenar. Untuk tujuan ini, penyelidik menggunakan RL bebas model untuk membolehkan robot belajar melalui percubaan dan kesilapan dinamik pesanan penuh sistem. Sebagai tambahan kepada eksperimen dunia sebenar, faedah menggunakan RL untuk kawalan pergerakan kaki dianalisis secara mendalam, dan cara menstrukturkan proses pembelajaran dengan berkesan untuk mengeksploitasi kelebihan ini, seperti kebolehsuaian dan keteguhan, diperiksa secara terperinci.
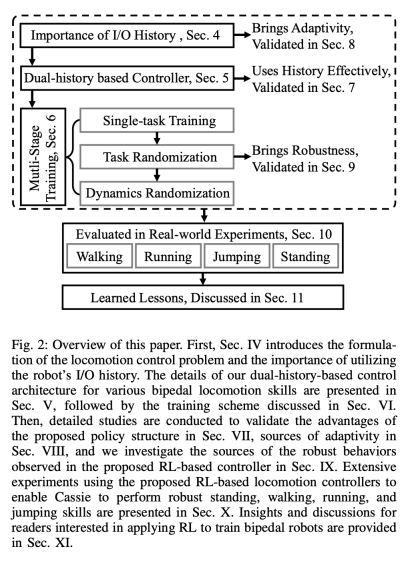
Sistem RL untuk kawalan gerakan dwipedal universal ditunjukkan dalam Rajah 2:
Seksyen 4 mula-mula memperkenalkan kepentingan menggunakan sejarah robot I/O dalam kawalan pergerakan , ia ditunjukkan bahawa sejarah I/O jangka panjang robot boleh mencapai pengenalpastian sistem dan anggaran keadaan dalam proses kawalan masa nyata.
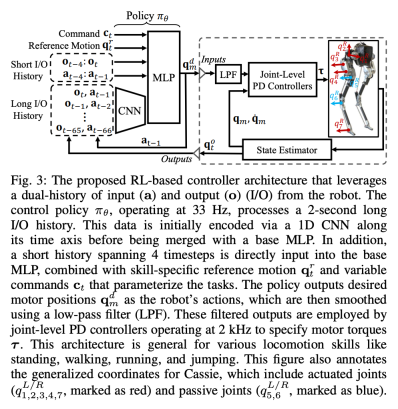
Bahagian 5 memperkenalkan teras penyelidikan: seni bina kawalan baharu yang menggunakan sejarah dwi I/O jangka panjang dan jangka pendek robot dwipedal. Secara khusus, seni bina kawalan ini memanfaatkan bukan sahaja sejarah jangka panjang robot, tetapi juga sejarah jangka pendeknya.
Rangka kerja kawalan adalah seperti yang ditunjukkan di bawah:
Dalam struktur dwi sejarah ini, sejarah jangka panjang membawa kebolehsuaian (disahkan dalam Bahagian 8), dan sejarah jangka pendek lebih baik dilaksanakan oleh The utilization sejarah jangka panjang dilengkapi dengan kawalan masa nyata (disahkan dalam Bahagian 7).
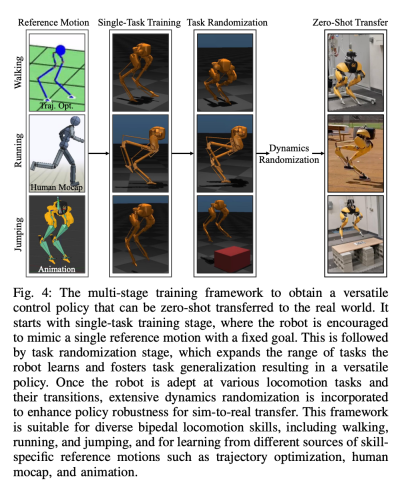
Seksyen 6 memperkenalkan cara strategi kawalan yang diwakili oleh rangkaian neural dalam boleh dioptimumkan melalui RL tanpa model. Memandangkan penyelidik bertujuan untuk membangunkan pengawal yang mampu menggunakan kemahiran motor yang sangat dinamik untuk menyelesaikan pelbagai tugas, latihan dalam bahagian ini dicirikan oleh latihan simulasi berbilang peringkat. Strategi latihan ini menyediakan kursus berstruktur, bermula dengan latihan tugasan tunggal, di mana robot memfokuskan pada tugas tetap, kemudian rawak tugas, yang mempelbagaikan tugas latihan yang diterima robot, dan akhirnya rawak dinamik, yang mengubah parameter dinamik robot.Strategi
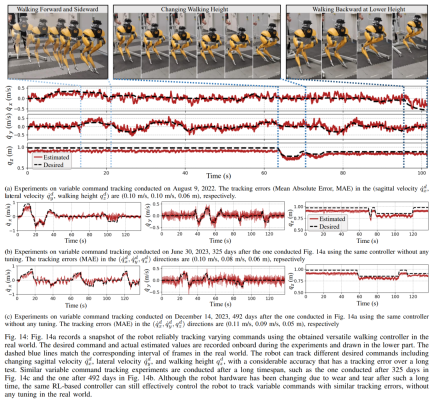
ditunjukkan dalam rajah di bawah: Strategi latihan ini boleh menyediakan strategi kawalan serba boleh yang boleh melaksanakan pelbagai tugas dan mencapai penghijrahan sampel sifar perkakasan robot. Tambahan pula, rawak tugas juga meningkatkan keteguhan dasar yang terhasil dengan membuat generalisasi merentas tugasan pembelajaran yang berbeza. Penyelidikan menunjukkan bahawa keteguhan ini boleh membolehkan robot berkelakuan mematuhi gangguan, yang "ortogon" kepada gangguan yang disebabkan oleh rawak dinamik. Ini akan disahkan dalam Seksyen 9. Menggunakan rangka kerja ini, penyelidik memperoleh strategi pelbagai fungsi untuk kemahiran berjalan, berlari dan melompat robot berkaki dua Cassie. Bab 10 menilai keberkesanan strategi kawalan ini dalam dunia sebenar. Penyelidik menjalankan eksperimen yang meluas pada robot, termasuk menguji pelbagai kebolehan seperti berjalan, berlari dan melompat di dunia nyata. Strategi yang digunakan semuanya mampu mengawal robot dunia sebenar dengan berkesan selepas latihan simulasi tanpa pelarasan selanjutnya. Walking Eksperimen yang ditunjukkan dalam Rajah 14a, strategi berjalan menunjukkan kawalan yang berkesan terhadap robot berikut arahan yang berbeza. ditentukan oleh nilai MAE untuk dinilai). Selain itu, strategi robot secara konsisten menunjukkan prestasi yang baik dalam tempoh masa yang lebih lama, dengan keupayaan untuk mengekalkan pengesanan arahan berubah-ubah walaupun selepas 325 dan 492 hari, seperti yang ditunjukkan dalam Rajah 14c dan Rajah 14b, masing-masing. Walaupun perubahan terkumpul yang ketara dalam dinamik robot dalam tempoh ini, pengawal yang sama dalam Rajah 14a terus menguruskan tugas berjalan yang berbeza dengan berkesan dengan kemerosotan minimum dalam ralat pengesanan.
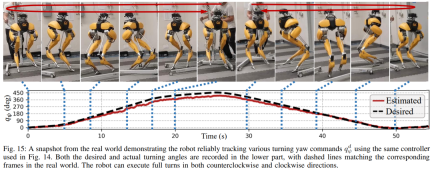
Seperti yang ditunjukkan dalam Rajah 15, strategi yang digunakan dalam kajian ini menunjukkan kawalan robot yang boleh dipercayai, membolehkan robot menjejaki arahan pusingan yang berbeza dengan tepat, mengikut arah jam atau lawan jam.
Percubaan berjalan pantas. Selain kelajuan berjalan yang sederhana, eksperimen juga menunjukkan keupayaan strategi yang digunakan untuk mengawal robot untuk melakukan tindakan berjalan pantas ke hadapan dan ke belakang, seperti yang ditunjukkan dalam Rajah 16. Robot boleh beralih daripada keadaan statik untuk mencapai kelajuan berjalan ke hadapan dengan cepat, dengan kelajuan purata 1.14 m/s (1.4 m/s diperlukan dalam arahan pengesanan Robot juga boleh dengan cepat kembali ke postur berdiri mengikut arahan). , seperti yang ditunjukkan dalam Rajah 16a, rekod data Dalam Rajah 16c.
Di kawasan yang tidak rata (tanpa latihan), robot juga boleh berjalan ke belakang dengan berkesan di atas tangga atau menuruni bukit, seperti yang ditunjukkan dalam gambar di bawah.
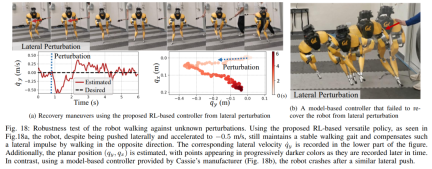
Anti gangguan. Dalam kes gangguan nadi, sebagai contoh, penyelidik memperkenalkan gangguan luaran jangka pendek kepada robot dari semua arah semasa robot berjalan. Seperti yang direkodkan dalam Rajah 18a, daya gangguan sisi yang besar dikenakan pada robot semasa berjalan di tempatnya, dengan halaju sisi puncak 0.5 m/s. Walaupun terdapat gangguan, robot itu cepat pulih daripada sisihan sisi. Seperti yang ditunjukkan dalam Rajah 18a, robot itu bergerak dengan mahir ke arah sisi yang bertentangan, secara berkesan mengimbangi gangguan dan memulihkan pergerakan berjalan di tempat yang stabil.
Semasa ujian gangguan berterusan, manusia menggunakan daya gangguan pada pangkalan robot dan menyeret robot ke arah rawak sambil mengarahkan robot berjalan di tempatnya. Seperti yang ditunjukkan dalam Rajah 19a, apabila robot berjalan seperti biasa, daya seret sisi berterusan dikenakan pada tapak Cassie. Keputusan menunjukkan bahawa robot mempamerkan pematuhan dengan daya luaran ini dengan mengikut arah mereka tanpa kehilangan keseimbangannya. Ini juga menunjukkan kelebihan strategi berasaskan pembelajaran pengukuhan yang dicadangkan dalam kertas kerja ini dalam aplikasi yang berpotensi seperti mengawal robot bipedal untuk mencapai interaksi robot manusia yang selamat.
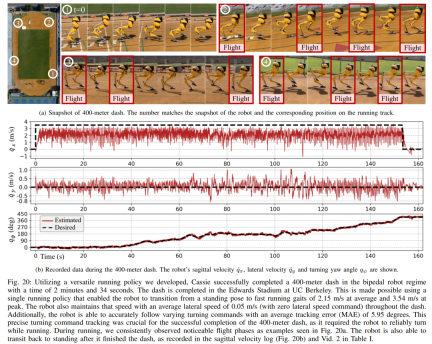
Apabila robot menggunakan strategi larian dwipedal, ia mencapai larian pecut 400 meter dalam 2 minit 34 saat, dan larian 100 saat, 2 meter 7. kecenderungan sehingga 10° dsb. 400 Meter Dash: Kajian pertama kali menilai strategi larian umum untuk melengkapkan larian 400 meter di trek luar standard, seperti yang ditunjukkan dalam Rajah 20.Sepanjang ujian, robot telah diarahkan untuk bertindak balas serentak kepada arahan pusingan berbeza yang dikeluarkan oleh pengendali pada kelajuan 3.5 m/s. Robot dapat beralih dengan lancar daripada postur berdiri kepada berjalan berjalan (Gamb. 20a 1). Robot itu berjaya memecut ke anggaran kelajuan operasi purata 2.15 m/s, mencapai anggaran kelajuan puncak 3.54 m/s, seperti ditunjukkan dalam Rajah 20b. Strategi ini membolehkan robot berjaya mengekalkan kelajuan yang diingini sepanjang keseluruhan larian 400 meter sambil mematuhi arahan pusingan yang berbeza dengan tepat.
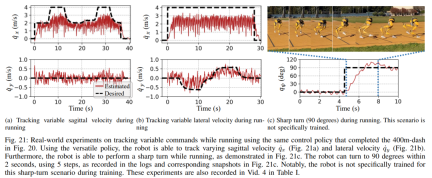
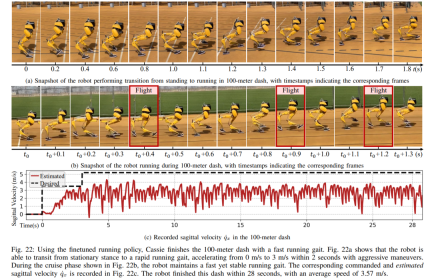
Di bawah kawalan strategi larian yang dicadangkan, Cassie berjaya menamatkan larian pecut 400m dalam masa 2 minit dan 34 saat dan seterusnya dapat beralih ke posisi berdiri. Kajian selanjutnya dijalankan dengan ujian pusingan tajam, di mana robot diberi perubahan langkah dalam arahan yaw, daripada 0 darjah terus kepada 90 darjah, seperti yang direkodkan dalam Rajah 21c. Robot boleh bertindak balas kepada arahan langkah sedemikian dan melengkapkan pusingan tajam 90 darjah dalam 2 saat dan 5 langkah. Larian 100 meter: Seperti yang ditunjukkan dalam Rajah 22, dengan menggunakan strategi larian yang dicadangkan, robot itu menyelesaikan larian 100 meter dalam kira-kira 28 saat, mencapai masa larian terpantas 27.06 saat. . , termasuk boleh melompat 1.4 meter dan melompat ke platform bertingkat 0.44 meter. Melompat dan berpusing: Seperti yang ditunjukkan dalam Rajah 25a, menggunakan strategi lompatan tunggal, robot boleh melakukan pelbagai lompatan sasaran yang diberikan, seperti melompat di tempat semasa berputar 60°, melompat ke belakang dan mendarat 0.3 meter di belakang .
Lompat ke platform tinggi: Seperti yang ditunjukkan dalam Rajah 25b, robot boleh melompat dengan tepat ke sasaran di lokasi berbeza, seperti 1 meter di hadapan atau 1.4 meter di hadapan Ia juga boleh melompat ke lokasi pada ketinggian yang berbeza, termasuk melompat ke ketinggian 0.44 meter (memandangkan robot itu sendiri hanya setinggi 1.1 meter). Untuk maklumat lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Berlari dengan anda adalah pantas dan stabil, rakan kongsi larian robot ada di sini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!


 . Cabaran timbul daripada kerumitan dinamik robot bipedal yang tidak digerakkan dan perancangan berbeza yang dikaitkan dengan setiap kemahiran lokomotor.
. Cabaran timbul daripada kerumitan dinamik robot bipedal yang tidak digerakkan dan perancangan berbeza yang dikaitkan dengan setiap kemahiran lokomotor.