
 Peranti teknologiAIKelajuan penjanaan adalah dua kali lebih pantas daripada SDXL, dan ia juga boleh berjalan pada 9GB Stable Cascade di sini untuk meningkatkan nisbah harga/prestasi.
Peranti teknologiAIKelajuan penjanaan adalah dua kali lebih pantas daripada SDXL, dan ia juga boleh berjalan pada 9GB Stable Cascade di sini untuk meningkatkan nisbah harga/prestasi.
Keperluan perkakasan semakin rendah dan kelajuan penjanaan semakin pantas.
Stability AI, sebagai perintis dalam teks-ke-imej, bukan sahaja menerajui trend, tetapi juga terus membuat penemuan baharu dalam kualiti model. Kali ini, ia mencapai kejayaan dalam prestasi kos.
Hanya beberapa hari yang lalu, Stability AI membuat satu lagi langkah baharu: versi pratonton penyelidikan Stable Cascade telah dilancarkan. Model teks-ke-imej ini berinovasi dengan memperkenalkan pendekatan tiga peringkat yang menetapkan penanda aras baharu untuk kualiti, fleksibiliti, penalaan halus dan kecekapan, dengan tumpuan untuk menghapuskan lagi halangan perkakasan. Selain itu, Stability AI mengeluarkan latihan dan kod inferens, membolehkan penyesuaian lanjut model dan outputnya. Model ini tersedia untuk inferens dalam perpustakaan penyebar. Model ini dikeluarkan di bawah lesen bukan komersial, membenarkan penggunaan bukan komersial sahaja.

- Pautan asal: https://stability.ai/news/introducing-stable-cascade
- Alamat kod: https://github.com/Stability-AI/StableCascade
Experience
Alamat: https://huggingface.co/spaces/multimodalart/stable-cascade - Seperti biasa, anda boleh menjana imej sasaran dengan operasi mudah: hanya masukkan perihalan teks imej.

dijana dengan sangat pantas. Pengguna platform X @GozukaraFurkan menyiarkan bahawa ia hanya memerlukan kira-kira 9GB memori GPU, dan kelajuannya masih boleh dikekalkan dengan baik. . ketepatan menghasilkan perkataan/frasa yang lebih pendek agak tinggi, ayat yang panjang juga boleh dilengkapkan dengan kebarangkalian tertentu (Bahasa Inggeris sahaja), dan integrasi teks dan imej juga sangat baik.

Pengguna @AIWarper mencuba beberapa ujian gaya artis yang berbeza.

prompt: Mimpi ngeri di Elm Street. Rujukan gaya artis adalah seperti berikut: Makoto Shinkai di atas kiri, Tomer Hanuka di bawah kiri, Raphael Kirchner di atas kanan, Takato Yamamoto di bawah kanan.
 Namun, apabila menjana wajah watak, anda boleh mendapati bahawa butiran kulit watak itu tidak begitu baik, dan ia terasa seperti "pengisaran kulit peringkat sepuluh".
Namun, apabila menjana wajah watak, anda boleh mendapati bahawa butiran kulit watak itu tidak begitu baik, dan ia terasa seperti "pengisaran kulit peringkat sepuluh".
... 1757511080287355093

Stable Cascade berbeza daripada siri model Stable Diffusion Ia dibina pada tiga berbeza model Pada saluran paip yang terdiri daripada: peringkat A, B dan C. Seni bina ini boleh melakukan pemampatan hierarki imej dan menggunakan ruang terpendam yang sangat mampat untuk mencapai output yang unggul. Bagaimanakah bahagian-bahagian ini sesuai bersama?
Peringkat penjana imej terpendam (peringkat C) menukar input pengguna kepada perwakilan terpendam 24x24 padat, yang kemudiannya dihantar ke peringkat penyahkod terpendam (peringkat A dan B) untuk memampatkan imej, yang serupa dengan kerja VAE dalam Resapan Stabil, Tetapi boleh mencapai pemampatan yang lebih tinggi.
Dengan menyahganding penjanaan keadaan teks (peringkat C) daripada penyahkodan kepada ruang piksel resolusi tinggi (peringkat A dan B), kami boleh melengkapkan latihan tambahan atau penalaan halus pada peringkat C, termasuk ControlNets dan LoRA, serupa dengan latihan Berbanding dengan Model Resapan Stabil dengan saiz yang sama, kos boleh dikurangkan kepada satu per enam belas. Peringkat A dan B secara pilihan boleh diperhalusi untuk kawalan tambahan, tetapi ini akan serupa dengan memperhalusi VAE dalam model Resapan Stabil. Dalam kebanyakan kes, faedah berbuat demikian adalah minimum. Oleh itu, untuk kebanyakan tujuan, Stability AI secara rasmi mengesyorkan latihan hanya Fasa C dan menggunakan keadaan asal daripada Fasa A dan B.
Fasa C dan B akan mengeluarkan dua model berbeza: model parameter 1B dan 3.6B untuk Fasa C dan model parameter 700M dan 1.5B untuk Fasa B. Model dengan parameter 3.6B disyorkan untuk Peringkat C kerana model ini mempunyai output kualiti tertinggi. Walau bagaimanapun, bagi mereka yang ingin mempunyai keperluan perkakasan minimum, versi parameter 1B tersedia. Untuk Fasa B, kedua-dua keluaran mencapai hasil yang baik, tetapi versi parameter 1.5B menunjukkan prestasi yang lebih baik dari segi perincian pembinaan semula. Terima kasih kepada pendekatan modular Stable Cascade, keperluan VRAM yang dijangkakan untuk inferens boleh dikekalkan kepada kira-kira 20GB. Ini boleh dikurangkan lagi dengan menggunakan varian yang lebih kecil, dengan kaveat bahawa ini juga boleh mengurangkan kualiti keluaran akhir.
Perbandingan
Dalam penilaian, Stable Cascade menunjukkan prestasi terbaik dari segi penjajaran segera dan kualiti estetik berbanding hampir semua model yang dibandingkan. Rajah di bawah menunjukkan hasil penilaian manusia menggunakan gabungan gesaan separa dan gesaan estetik:

Lata Stabil (30 langkah inferens) lwn. Taman Permainan v2 (50 langkah inferens), SDXL (50 langkah inferens ) , SDXL Turbo (1 langkah penaakulan) dan Würstchen V2 (30 langkah penaakulan) dibandingkan

Stable Cascade, SDXL, Playground V2 dan SDXL Turbo Stable Cascade's menunjukkan kecekapan dan kecekapannya potensi mampatan yang lebih tinggi. Walaupun model terbesar mempunyai 1.4B lebih parameter daripada Stable Diffusion XL, ia masih mempunyai masa inferens yang lebih pantas.
Ciri Ditambah
Selain penjanaan teks-ke-imej standard, Lata Stable juga boleh menjana variasi imej dan penjanaan imej-ke-imej.
Varian imej mengekstrak benam imej daripada imej tertentu dengan menggunakan CLIP dan kemudian mengembalikannya kepada model. Imej di bawah adalah contoh output. Imej di sebelah kiri menunjukkan imej asal, manakala empat di sebelah kanannya ialah varian yang dijana.Imej ke Imej dengan hanya menambah hingar pada imej yang diberikan dan kemudian menjana imej daripada itu sebagai titik permulaan. Di bawah ialah contoh menambah hingar pada imej di sebelah kiri dan kemudian menjananya dari sana. 
 Kod untuk latihan, penalaan halus, ControlNet dan LoRA
Kod untuk latihan, penalaan halus, ControlNet dan LoRA
Dengan keluaran Stable Cascade, Stability AI akan mengeluarkan semua kod untuk latihan, penalaan halus, ControlNet dan LoRA untuk mengurangkan keperluan untuk percubaan selanjutnya dengan seni bina ini. Berikut ialah beberapa ControlNets yang akan dikeluarkan bersama model:
Tampal/Kembangkan: Masukkan imej dan tambah topeng untuk memadankan gesaan teks. Model kemudiannya akan mengisi bahagian bertopeng pada imej berdasarkan pembayang teks yang disediakan.Canny Edge: Menghasilkan imej baharu berdasarkan tepi imej sedia ada yang dimasukkan ke dalam model. Mengikut ujian Stability AI, ia juga boleh membuat skala lakaran.型 Bahagian atas 型 ialah lakaran model input, dan bahagian bawah ialah hasil output 
2x Super-Resolution: Meningkatkan resolusi imej kepada 2x panjang sisinya, mis.

Adakah anda suka nilai untuk wang ini?
Atas ialah kandungan terperinci Kelajuan penjanaan adalah dua kali lebih pantas daripada SDXL, dan ia juga boleh berjalan pada 9GB Stable Cascade di sini untuk meningkatkan nisbah harga/prestasi.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

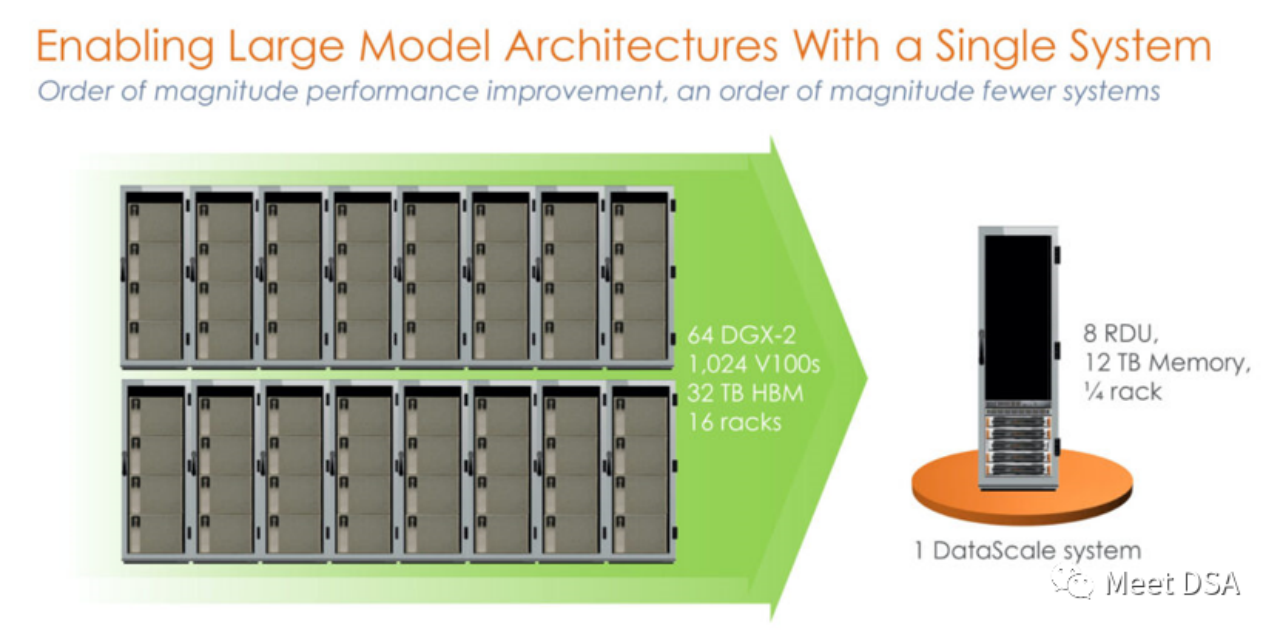 DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM
DSA如何弯道超车NVIDIA GPU?Sep 20, 2023 pm 06:09 PM你可能听过以下犀利的观点:1.跟着NVIDIA的技术路线,可能永远也追不上NVIDIA的脚步。2.DSA或许有机会追赶上NVIDIA,但目前的状况是DSA濒临消亡,看不到任何希望另一方面,我们都知道现在大模型正处于风口位置,业界很多人想做大模型芯片,也有很多人想投大模型芯片。但是,大模型芯片的设计关键在哪,大带宽大内存的重要性好像大家都知道,但做出来的芯片跟NVIDIA相比,又有何不同?带着问题,本文尝试给大家一点启发。纯粹以观点为主的文章往往显得形式主义,我们可以通过一个架构的例子来说明Sam
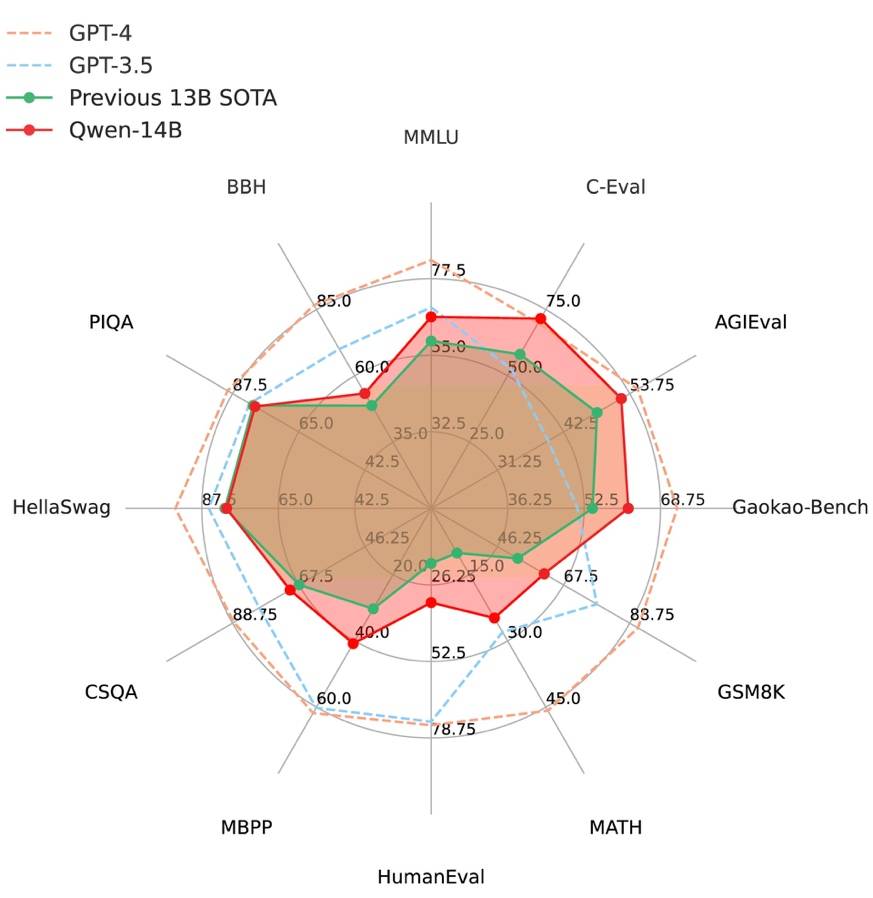 阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM
阿里云通义千问14B模型开源!性能超越Llama2等同等尺寸模型Sep 25, 2023 pm 10:25 PM2021年9月25日,阿里云发布了开源项目通义千问140亿参数模型Qwen-14B以及其对话模型Qwen-14B-Chat,并且可以免费商用。Qwen-14B在多个权威评测中表现出色,超过了同等规模的模型,甚至有些指标接近Llama2-70B。此前,阿里云还开源了70亿参数模型Qwen-7B,仅一个多月的时间下载量就突破了100万,成为开源社区的热门项目Qwen-14B是一款支持多种语言的高性能开源模型,相比同类模型使用了更多的高质量数据,整体训练数据超过3万亿Token,使得模型具备更强大的推
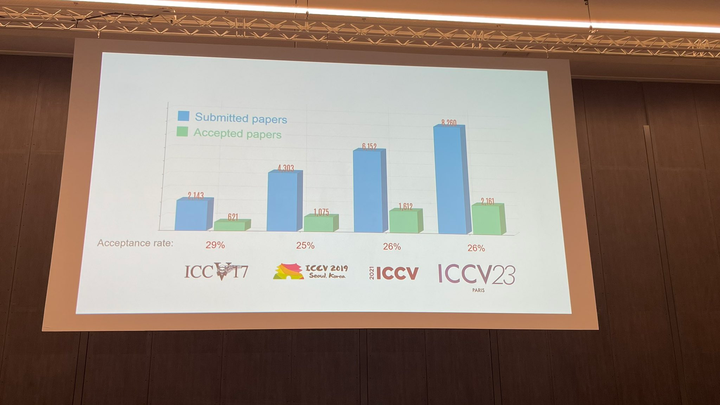 ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM
ICCV 2023揭晓:ControlNet、SAM等热门论文斩获奖项Oct 04, 2023 pm 09:37 PM在法国巴黎举行了国际计算机视觉大会ICCV(InternationalConferenceonComputerVision)本周开幕作为全球计算机视觉领域顶级的学术会议,ICCV每两年召开一次。ICCV的热度一直以来都与CVPR不相上下,屡创新高在今天的开幕式上,ICCV官方公布了今年的论文数据:本届ICCV共有8068篇投稿,其中有2160篇被接收,录用率为26.8%,略高于上一届ICCV2021的录用率25.9%在论文主题方面,官方也公布了相关数据:多视角和传感器的3D技术热度最高在今天的开
 复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM
复旦大学团队发布中文智慧法律系统DISC-LawLLM,构建司法评测基准,开源30万微调数据Sep 29, 2023 pm 01:17 PM随着智慧司法的兴起,智能化方法驱动的智能法律系统有望惠及不同群体。例如,为法律专业人员减轻文书工作,为普通民众提供法律咨询服务,为法学学生提供学习和考试辅导。由于法律知识的独特性和司法任务的多样性,此前的智慧司法研究方面主要着眼于为特定任务设计自动化算法,难以满足对司法领域提供支撑性服务的需求,离应用落地有不小的距离。而大型语言模型(LLMs)在不同的传统任务上展示出强大的能力,为智能法律系统的进一步发展带来希望。近日,复旦大学数据智能与社会计算实验室(FudanDISC)发布大语言模型驱动的中
 百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM
百度文心一言全面向全社会开放,率先迈出重要一步Aug 31, 2023 pm 01:33 PM8月31日,文心一言首次向全社会全面开放。用户可以在应用商店下载“文心一言APP”或登录“文心一言官网”(https://yiyan.baidu.com)进行体验据报道,百度计划推出一系列经过全新重构的AI原生应用,以便让用户充分体验生成式AI的理解、生成、逻辑和记忆等四大核心能力今年3月16日,文心一言开启邀测。作为全球大厂中首个发布的生成式AI产品,文心一言的基础模型文心大模型早在2019年就在国内率先发布,近期升级的文心大模型3.5也持续在十余个国内外权威测评中位居第一。李彦宏表示,当文心
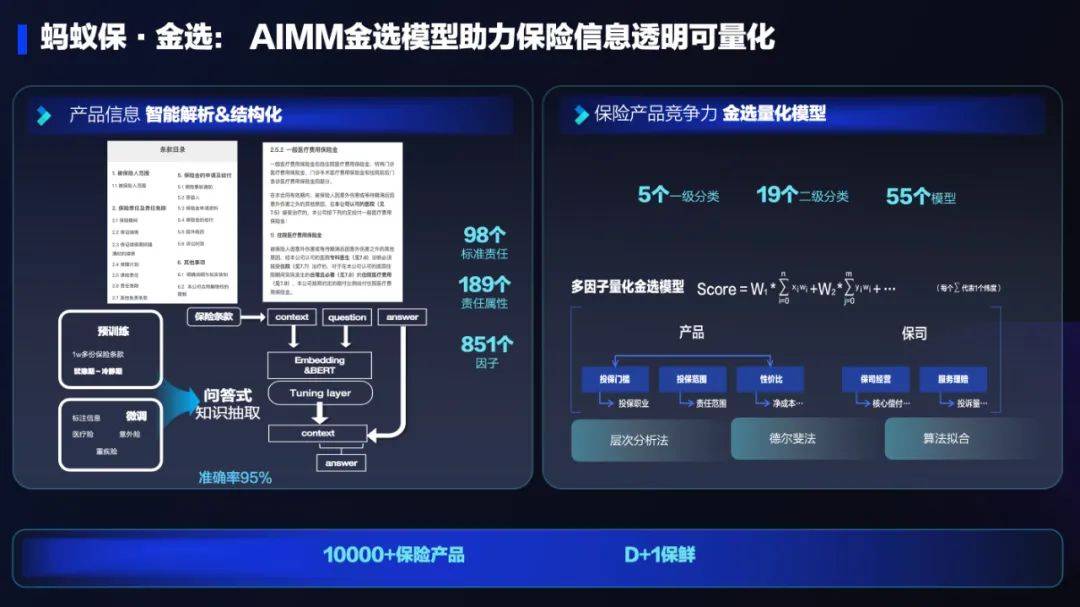 AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM
AI技术在蚂蚁集团保险业务中的应用:革新保险服务,带来全新体验Sep 20, 2023 pm 10:45 PM保险行业对于社会民生和国民经济的重要性不言而喻。作为风险管理工具,保险为人民群众提供保障和福利,推动经济的稳定和可持续发展。在新的时代背景下,保险行业面临着新的机遇和挑战,需要不断创新和转型,以适应社会需求的变化和经济结构的调整近年来,中国的保险科技蓬勃发展。通过创新的商业模式和先进的技术手段,积极推动保险行业实现数字化和智能化转型。保险科技的目标是提升保险服务的便利性、个性化和智能化水平,以前所未有的速度改变传统保险业的面貌。这一发展趋势为保险行业注入了新的活力,使保险产品更贴近人民群众的实际
 致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM
致敬TempleOS,有开发者创建了启动Llama 2的操作系统,网友:8G内存老电脑就能跑Oct 07, 2023 pm 10:09 PM不得不说,Llama2的「二创」项目越来越硬核、有趣了。自Meta发布开源大模型Llama2以来,围绕着该模型的「二创」项目便多了起来。此前7月,特斯拉前AI总监、重回OpenAI的AndrejKarpathy利用周末时间,做了一个关于Llama2的有趣项目llama2.c,让用户在PyTorch中训练一个babyLlama2模型,然后使用近500行纯C、无任何依赖性的文件进行推理。今天,在Karpathyllama2.c项目的基础上,又有开发者创建了一个启动Llama2的演示操作系统,以及一个
 快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM
快手黑科技“子弹时间”赋能亚运转播,打造智慧观赛新体验Oct 11, 2023 am 11:21 AM杭州第19届亚运会不仅是国际顶级体育盛会,更是一场精彩绝伦的中国科技盛宴。本届亚运会中,快手StreamLake与杭州电信深度合作,联合打造智慧观赛新体验,在击剑赛事的转播中,全面应用了快手StreamLake六自由度技术,其中“子弹时间”也是首次应用于击剑项目国际顶级赛事。中国电信杭州分公司智能亚运专班组长芮杰表示,依托快手StreamLake自研的4K3D虚拟运镜视频技术和中国电信5G/全光网,通过赛场内部署的4K专业摄像机阵列实时采集的高清竞赛视频,


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

Dreamweaver Mac版
Alat pembangunan web visual

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

