
Rumah >Tutorial sistem >LINUX >Fahami status kesihatan Linux dalam 61 saat!
Fahami status kesihatan Linux dalam 61 saat!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-14 10:45:021357semak imbas
Sebagai asas kepada semua program, sistem pengendalian mempunyai kesan penting terhadap prestasi aplikasi. Walau bagaimanapun, perbezaan kelajuan antara pelbagai komponen komputer adalah sangat besar. Sebagai contoh, perbezaan kelajuan antara CPU dan cakera keras adalah lebih besar daripada perbezaan kelajuan antara arnab dan kura-kura.
Di bawah, kami akan memperkenalkan secara ringkas asas CPU, memori dan I/O, dan memperkenalkan beberapa arahan untuk menilai prestasinya.
1.CPU
Mula-mula perkenalkan komponen pengkomputeran yang paling penting dalam komputer: unit pemprosesan pusat. Secara amnya kita boleh melihat prestasinya melalui arahan atas.
1.1 arahan teratas
Klik kekuncitop命令可用于观测CPU的一些运行指标。如图,进入top命令之后,按1 untuk melihat status terperinci setiap CPU teras.
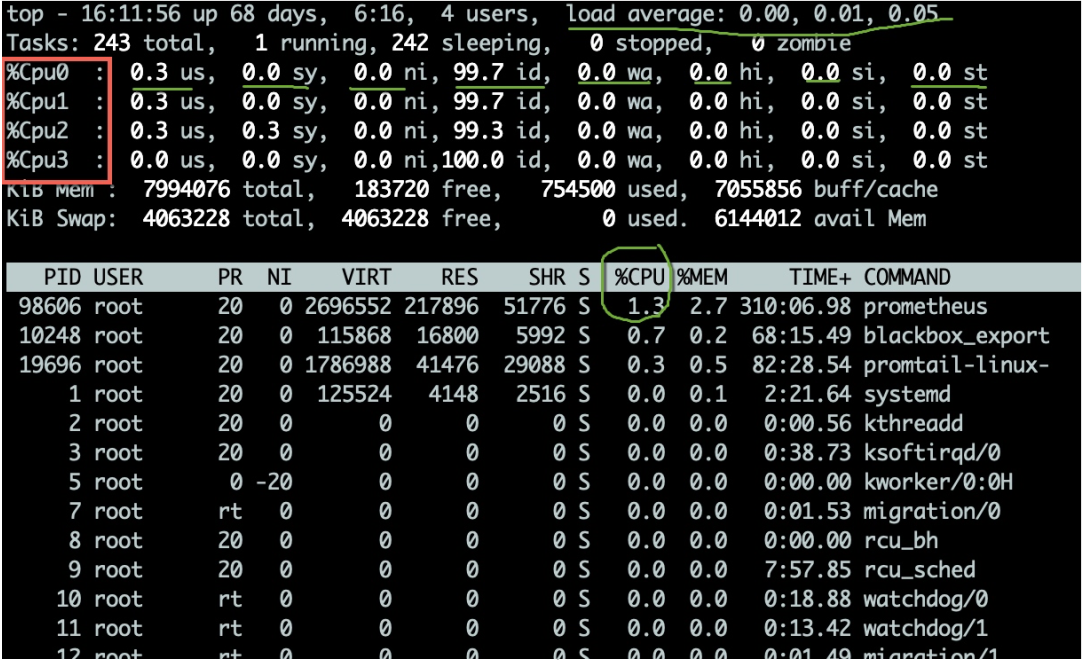
Penggunaan CPU mempunyai berbilang penunjuk, yang dijelaskan di bawah:
- us Peratusan CPU yang diduduki oleh mod pengguna.
- sy Peratusan CPU yang diduduki oleh mod kernel. Jika nilai ini terlalu tinggi, anda perlu bekerjasama dengan arahan vmstat untuk menyemak sama ada penukaran konteks adalah kerap.
- ni Peratusan CPU yang diduduki oleh aplikasi keutamaan tinggi.
- wa Peratusan CPU yang diduduki dengan menunggu peranti I/O. Jika nilai ini sangat tinggi, mungkin terdapat kesesakan yang ketara dalam peranti input dan output.
- hi Peratusan CPU yang diduduki oleh gangguan perkakasan.
- si Peratusan CPU yang diduduki oleh gangguan lembut.
- st Ini biasanya berlaku pada mesin maya dan merujuk kepada peratusan masa CPU maya menunggu CPU sebenar. Jika nilai ini terlalu besar, hos anda mungkin berada di bawah tekanan yang terlalu tinggi. Jika anda adalah hos awan, pembekal perkhidmatan anda mungkin menjual terlalu banyak.
- id Peratusan CPU terbiar.
Secara amnya, kami memberi lebih perhatian kepada peratusan CPU terbiar, yang boleh mencerminkan penggunaan CPU keseluruhan.
1.2 Apa itu beban
Kami juga perlu menilai situasi beratur dalam pelaksanaan tugas CPU, nilai ini adalah 负载(beban). Beban CPU yang dipaparkan oleh arahan atas ialah nilai 1 minit terakhir, 5 minit dan 15 minit masing-masing.
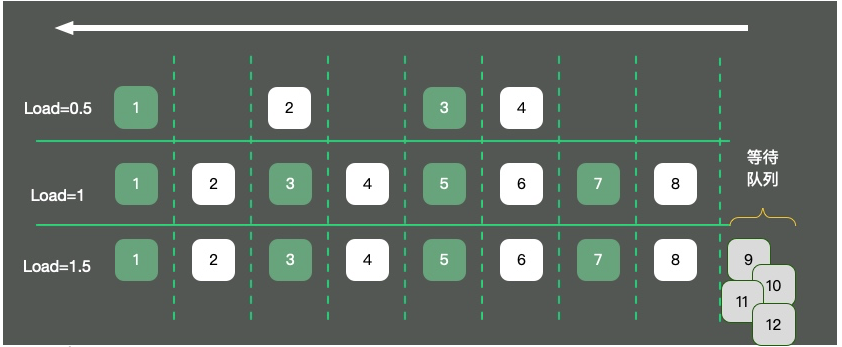
Seperti yang ditunjukkan dalam rajah, mengambil sistem pengendalian teras tunggal sebagai contoh, sumber CPU diabstrakkan ke jalan sehala. Tiga situasi akan berlaku:
-
Hanya ada
4kereta di jalan raya, lalu lintas lancar, dan muatannya lebih kurang 0.5. - Terdapat 8 kereta di jalan raya, yang boleh melalui dengan selamat dari hujung ke hujung Pada masa ini, muatannya adalah kira-kira 1.
- Terdapat 12 kereta di jalan raya Selain 8 kereta di jalan raya, terdapat 4 kereta menunggu di luar jalan dan perlu beratur. Pada masa ini beban adalah kira-kira 1.5.
Apakah maksud beban 1? Masih banyak salah faham tentang isu ini.
Ramai pelajar percaya bahawa apabila beban mencapai 1, sistem mencapai kesesakan Ini tidak sepenuhnya betul. Nilai beban berkait rapat dengan bilangan teras CPU. Contohnya seperti berikut:
- Beban teras tunggal mencapai 1, dan jumlah nilai beban adalah kira-kira 1.
- Beban pada setiap teras dwi-teras mencapai 1, dan jumlah beban adalah kira-kira 2.
- Setiap daripada empat teras mempunyai beban 1, dan jumlah beban adalah kira-kira 4.
Jadi, untuk mesin 16 teras dengan muatan 10, sistem anda jauh daripada mencapai had muatan. Melalui arahan uptime, anda juga boleh melihat status beban.
1.3 vmstat
Untuk melihat betapa sibuknya CPU, anda juga boleh menggunakan arahan vmstat. Berikut ialah beberapa maklumat output daripada arahan vmstat.
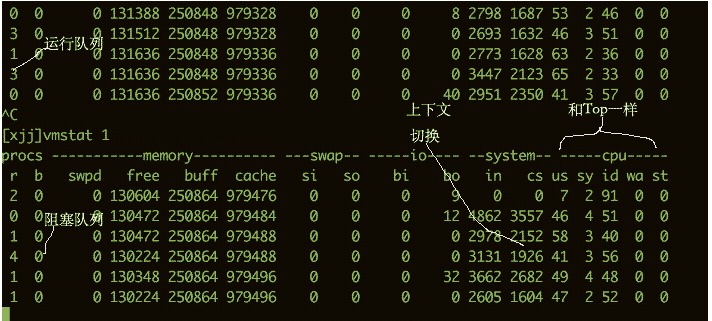
Kami lebih mengambil berat tentang ruangan berikut:
-
bBilangan utas kernel yang ada dalam baris gilir menunggu, seperti menunggu I/O, dsb. Jika bilangannya terlalu besar, CPU akan menjadi terlalu sibuk. -
csmewakili bilangan suis konteks. Jika suis konteks dilakukan dengan kerap, anda perlu mempertimbangkan sama ada bilangan utas terlalu banyak. -
si/soMenunjukkan beberapa penggunaan partition swap mempunyai kesan yang lebih besar pada prestasi dan memerlukan perhatian khusus.
2. Ingatan
2.1 Arahan pemerhatian
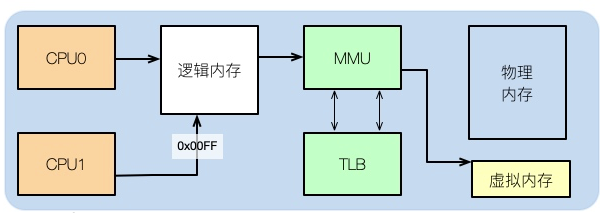
Untuk memahami beberapa kesan memori terhadap prestasi, anda perlu melihat pengagihan memori dari peringkat sistem pengendalian.
Selepas kita selesai menulis kod, contohnya, jika kita menulis program C++, jika kita melihat pemasangannya, kita dapat melihat bahawa alamat memori di dalamnya bukan alamat memori fizikal sebenar.
Maka apa yang digunakan oleh aplikasi adalah ingatan logik Pelajar yang telah mempelajari struktur komputer semua tahu ini.
Alamat logik boleh dipetakan kepada ingatan fizikal dan ingatan maya. Contohnya, jika memori fizikal anda ialah 8GB dan partition SWAP 16GB diperuntukkan, maka jumlah memori yang tersedia untuk aplikasi ialah 24GB.
Anda boleh melihat beberapa lajur data dari arahan atas Perhatikan tiga kawasan yang disertakan dengan petak Penjelasan adalah seperti berikut:
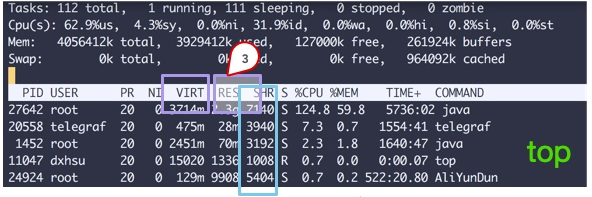
- VIRT Ini adalah ingatan maya, yang secara amnya agak besar, jadi anda tidak perlu memberi terlalu banyak perhatian kepadanya.
- RES Perkara yang biasa kita perhatikan ialah nilai dalam lajur ini, yang mewakili memori yang sebenarnya diduduki oleh proses tersebut. Biasanya apabila melakukan pemantauan, nilai ini dipantau terutamanya.
- SHR merujuk kepada memori yang dikongsi, seperti beberapa fail yang boleh digunakan semula.
2.2 CPU cache
Memandangkan perbezaan kelajuan antara teras CPU dan memori adalah sangat besar, penyelesaiannya adalah dengan menambah cache. Sebenarnya, cache ini selalunya mempunyai berbilang lapisan, seperti yang ditunjukkan dalam rajah di bawah.
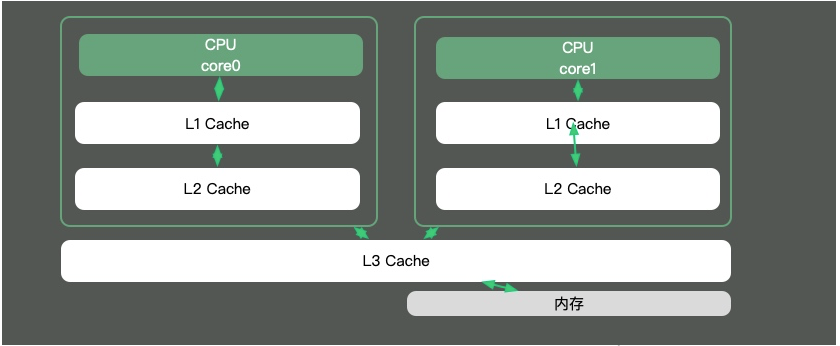
Kebanyakan titik pengetahuan di Java adalah sekitar multi-threading Ini kerana jika potongan masa sesuatu thread menjangkau berbilang CPU, maka akan ada masalah penyegerakan.
在Java中,最典型的和CPU缓存相关的知识点,就是并发编程中,针对Cache line的伪共享(false sharing)问题。
伪共享是指:在这些高速缓存中,是以缓存行为单位进行存储的。哪怕你修改了缓存行中一个很小很小的数据,它都会整个的刷新。所以,当多线程修改一些变量的值时,如果这些变量在同一个缓存行里,就会造成频繁刷新,无意中影响彼此的性能。
通过以下命令即可看到当前操作系统的缓存行大小。
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
通过以下命令可以看到不同层次的缓存大小。
[root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index1/size 32K [root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index2/size 256K [root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index3/size 20480K
在JDK8以上的版本,通过开启参数-XX:-RestrictContended,就可以使用注解@sun.misc.Contended进行补齐,来避免伪共享的问题。在并发优化中,我们再详细讲解。
2.3 HugePage
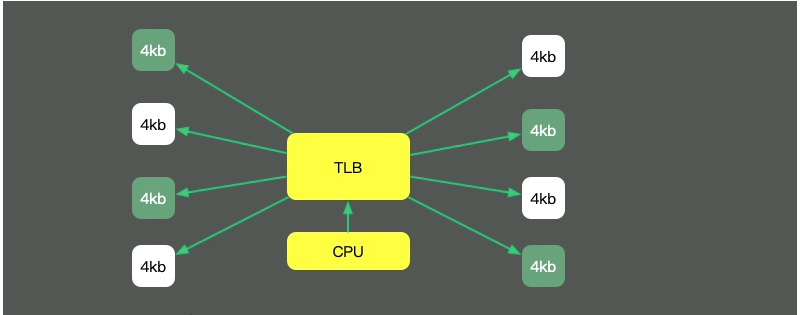
回头看我们最长的那副图,上面有一个叫做TLB的组件,它的速度虽然高,但容量也是有限的。这就意味着,如果物理内存很大,那么映射表的条目将会非常多,会影响CPU的检索效率。
默认内存是以4K的page来管理的。如图,为了减少映射表的条目,可采取的办法只有增加页的尺寸。像这种将Page Size加大的技术,就是Huge Page。
HugePage有一些副作用,比如竞争加剧,Redis还有专门的研究(https://redis.io/topics/latency) ,但在一些大内存的机器上,开启后会一定程度上增加性能。
2.4 预先加载
另外,一些程序的默认行为,也会对性能有所影响。比如JVM的-XX:+AlwaysPreTouch参数。默认情况下,JVM虽然配置了Xmx、Xms等参数,但它的内存在真正用到时,才会分配。
但如果加上这个参数,JVM就会在启动的时候,把所有的内存预先分配。这样,启动时虽然慢了些,但运行时的性能会增加。
3.I/O
3.1 观测命令
I/O设备可能是计算机里速度最差的组件了。它指的不仅仅是硬盘,还包括外围的所有设备。
硬盘有多慢呢?我们不去探究不同设备的实现细节,直接看它的写入速度(数据未经过严格测试,仅作参考)。
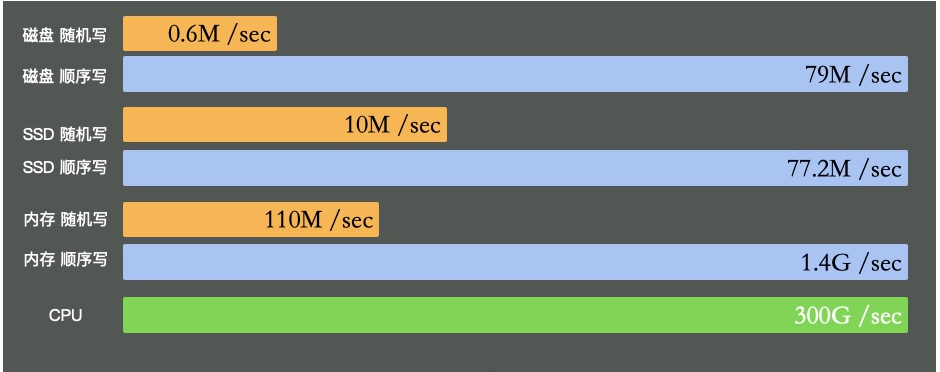
可以看到普通磁盘的随机写和顺序写相差是非常大的。而随机写完全和cpu内存不在一个数量级。
缓冲区依然是解决速度差异的唯一工具,在极端情况比如断电等,就产生了太多的不确定性。这些缓冲区,都容易丢。
Cara terbaik untuk mencerminkan kesibukan I/O ialah arahan teratas dan vmstat命令中的wa%. Jika aplikasi anda menulis banyak log, menunggu I/O mungkin sangat tinggi.
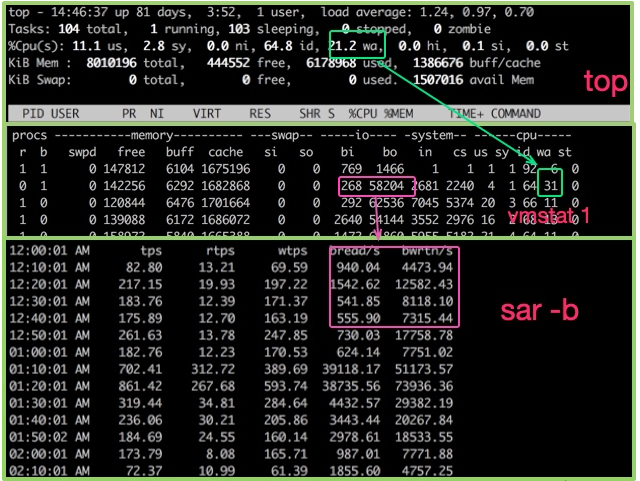
Untuk cakera keras, anda boleh menggunakan arahan iostat untuk melihat penggunaan perkakasan tertentu. Selagi %util melebihi 80%, sistem anda pada dasarnya tidak akan dapat dijalankan.
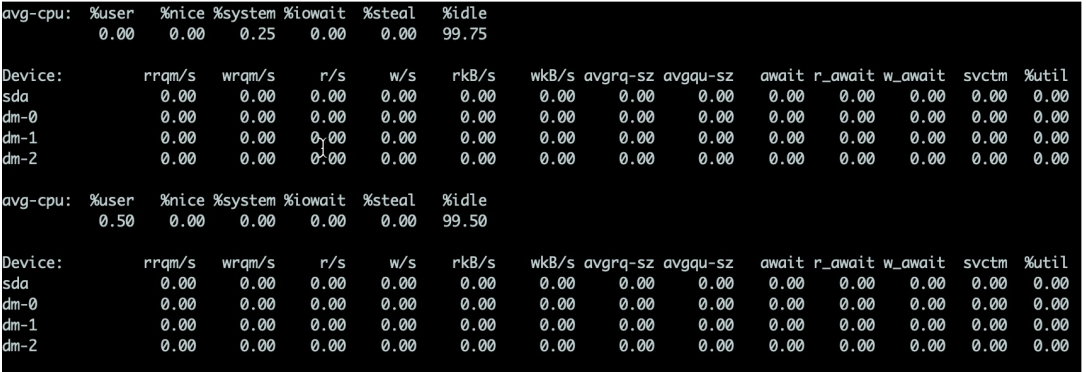
Perincian adalah seperti berikut:
- %util Parameter pertimbangan yang paling penting. Secara amnya, jika parameter ini adalah 100%, ini bermakna peralatan berjalan hampir dengan kapasiti penuh
- Peranti menunjukkan cakera keras yang mana peristiwa itu berlaku. Jika seberapa pantas anda, berbilang baris akan dipaparkan
- avgqu-sz Nilai ini ialah ketepuan baris gilir permintaan, iaitu purata panjang baris gilir permintaan. Tidak syak lagi bahawa lebih pendek panjang giliran, lebih baik.
- tunggu Masa tindak balas hendaklah kurang daripada 5ms, jika lebih daripada 10ms, ia akan menjadi lebih besar. Masa ini termasuk masa giliran dan masa perkhidmatan
-
svctm bermaksud purata giliran menunggu setiap kali peranti
I/O操作的服务时间。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/Oterlalu panjang dan aplikasi yang berjalan pada sistem akan menjadi perlahan.
3.2 Salinan Sifar
Salah satu sebab kenapa kafka lebih cepat adalah penggunaan zero copy. Salinan sifar yang dipanggil bermaksud bahawa semasa mengendalikan data, tidak perlu menyalin penimbal data dari satu kawasan memori ke kawasan memori yang lain. Kerana terdapat kurang satu salinan memori, kecekapan CPU dipertingkatkan.
Mari kita lihat perbezaan antara mereka:
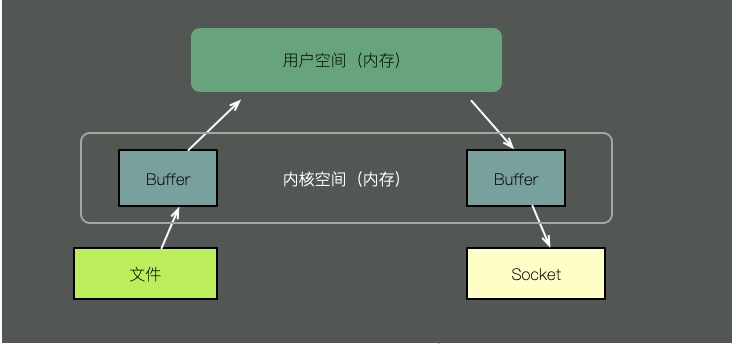
Untuk menghantar kandungan fail melalui soket, kaedah tradisional memerlukan langkah berikut:
- Salin kandungan fail ke ruang kernel.
- Salin kandungan ruang kernel ke memori ruang pengguna, seperti aplikasi Java.
- Ruang pengguna menulis kandungan ke cache ruang kernel.
- Soket membaca kandungan cache kernel dan menghantarnya keluar.
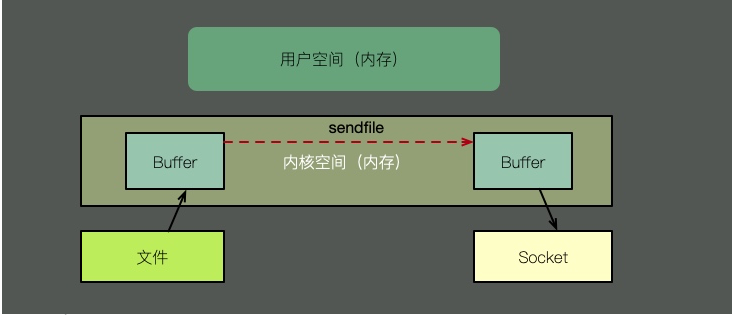
Sifar salinan dan berbilang mod, mari gunakan fail hantar untuk menggambarkan. Seperti yang ditunjukkan dalam rajah di atas, dengan sokongan kernel, salinan sifar mempunyai satu langkah yang kurang, iaitu salinan cache kernel ke ruang pengguna. Maksudnya, ia menjimatkan memori dan masa penjadualan CPU, yang sangat cekap.
4.网络
除了iotop、iostat这些命令外,sar命令可以方便的看到网络运行状况,下面是一个简单的示例,用于描述入网流量和出网流量。
$ sar -n DEV 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00 12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00 12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil 12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00 12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00 12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 ^C
当然,我们可以选择性的只看TCP的一些状态。
$ sar -n TCP,ETCP 1 Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU) 12:17:19 AM active/s passive/s iseg/s oseg/s 12:17:20 AM 1.00 0.00 10233.00 18846.00 12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:17:20 AM 0.00 0.00 0.00 0.00 0.00 12:17:20 AM active/s passive/s iseg/s oseg/s 12:17:21 AM 1.00 0.00 8359.00 6039.00 12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s 12:17:21 AM 0.00 0.00 0.00 0.00 0.00 ^C
5.End
不要寄希望于这些指标,能够立刻帮助我们定位性能问题。这些工具,只能够帮我们大体猜测发生问题的地方,它对性能问题的定位,只是起到辅助作用。想要分析这些bottleneck,需要收集更多的信息。
想要获取更多的性能数据,就不得不借助更加专业的工具,比如基于eBPF的BCC工具,这些牛x的工具我们将在其他文章里展开。读完本文,希望你能够快速的了解Linux的运行状态,对你的系统多一些掌控。
Atas ialah kandungan terperinci Fahami status kesihatan Linux dalam 61 saat!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!