
Rumah >Tutorial sistem >LINUX >Mekanisme penjadualan kumpulan proses Linux: cara mengumpulkan dan menjadualkan proses
Mekanisme penjadualan kumpulan proses Linux: cara mengumpulkan dan menjadualkan proses

- 王林ke hadapan
- 2024-02-11 20:30:101536semak imbas
Kumpulan proses ialah cara untuk mengklasifikasikan dan mengurus proses dalam sistem Linux Ia boleh meletakkan proses dengan ciri atau perhubungan yang sama untuk membentuk satu unit logik. Fungsi kumpulan proses adalah untuk memudahkan kawalan, komunikasi dan peruntukan sumber proses untuk meningkatkan kecekapan dan keselamatan sistem. Penjadualan kumpulan proses ialah mekanisme untuk menjadualkan kumpulan proses dalam sistem Linux Ia boleh memperuntukkan masa dan sumber CPU yang sesuai berdasarkan atribut dan keperluan kumpulan proses, dengan itu meningkatkan keselarasan dan responsif sistem. Tetapi, adakah anda benar-benar memahami mekanisme penjadualan kumpulan proses Linux? Adakah anda tahu cara membuat dan mengurus kumpulan proses dalam Linux? Adakah anda tahu cara menggunakan dan mengkonfigurasi mekanisme penjadualan kumpulan proses di bawah Linux? Artikel ini akan memperkenalkan anda kepada pengetahuan berkaitan mekanisme penjadualan kumpulan proses Linux secara terperinci, membolehkan anda menggunakan dan memahami fungsi kernel yang berkuasa ini dengan lebih baik di bawah Linux.

Saya menghadapi satu lagi masalah penjadualan proses ajaib Semasa proses mulakan semula sistem, saya mendapati bahawa sistem telah ditutup, dan ia ditetapkan semula selepas 30 saat proses but semula. Masa set semula rekod anjing perkakasan ditolak ke hadapan sebanyak 30 saat apabila anjing itu tidak diberi makan Apabila menganalisis log rekod port bersiri, log pada masa itu mencetak ayat: "jadual: pendikit RT diaktifkan".
Ia boleh dilihat daripada kod kernel versi linux-3.0.101-0.7.17 yang sched_rt_runtime_exceeded mencetak ayat ini. Dalam proses penjadualan kumpulan proses kernel, penjadualan proses masa nyata dihadkan oleh rt_rq->rt_throttled Mari kita bincangkan tentang mekanisme penjadualan kumpulan proses dalam Linux secara terperinci di bawah.
Memproses penjadualan kumpulan
Penjadualan kumpulan ialah konsep dalam cgroup, yang merujuk kepada merawat proses N secara keseluruhan dan mengambil bahagian dalam proses penjadualan dalam sistem Ini secara khusus ditunjukkan dalam contoh: tugasan A mempunyai 8 proses atau urutan, dan tugasan B mempunyai 2 proses atau utas. Jika masih terdapat proses atau utas lain, anda perlu mengawal penggunaan CPU tugas A tidak melebihi 40%, penggunaan CPU tugas B tidak lebih tinggi daripada 40% dan penghunian tugasan lain. tidak kurang daripada 20%. Kemudian ada hak Untuk menetapkan ambang cgroup, cgroup A ditetapkan kepada 200, cgroup B ditetapkan kepada 200, dan tugas lain lalai kepada 100, dengan itu merealisasikan fungsi kawalan CPU.
Dalam kernel, kumpulan proses diuruskan oleh kumpulan tugas, dan banyak kandungan yang terlibat adalah mekanisme kawalan cgroup Selain itu, unit pembangunan sedang ditulis Di sini kita merujuk kepada bahagian yang memfokuskan pada penjadualan kumpulan .
struct task_group {
struct cgroup_subsys_state css;
//下面是普通进程调度使用
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each cpu */
//普通进程调度单元,之所以用调度单元,因为被调度的可能是一个进程,也可能是一组进程
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu */
//公平调度队列
struct cfs_rq **cfs_rq;
//下面就是如上示例的控制阀值
unsigned long shares;
atomic_t load_weight;
#endif
#ifdef CONFIG_RT_GROUP_SCHED
//实时进程调度单元
struct sched_rt_entity **rt_se;
//实时进程调度队列
struct rt_rq **rt_rq;
//实时进程占用CPU时间的带宽(或者说比例)
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
//task_group呈树状结构组织,有父节点,兄弟链表,孩子链表,内核里面的根节点是root_task_group
struct task_group *parent;
struct list_head siblings;
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
};
Terdapat dua jenis unit penjadualan iaitu unit penjadualan biasa dan unit penjadualan proses masa nyata.
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
#ifdef CONFIG_SCHEDSTATS
struct sched_statistics statistics;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
//当前调度单元归属于某个父调度单元
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
//当前调度单元归属的父调度单元的调度队列,即当前调度单元插入的队列
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
//当前调度单元的调度队列,即管理子调度单元的队列,如果调度单元是task_group,my_q才会有值
//如果当前调度单元是task,那么my_q自然为NULL
struct cfs_rq *my_q;
#endif
void *suse_kabi_padding;
};
struct sched_rt_entity {
struct list_head run_list;
unsigned long timeout;
unsigned int time_slice;
int nr_cpus_allowed;
struct sched_rt_entity *back;
#ifdef CONFIG_RT_GROUP_SCHED
//实时进程的管理和普通进程类似,下面三项意义参考普通进程
struct sched_rt_entity *parent;
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq;
/* rq "owned" by this entity/group: */
struct rt_rq *my_q;
#endif
};
Mari kita lihat baris gilir penjadualan, kerana pilihan yang perlu dijelaskan untuk penjadualan masa nyata dan baris gilir penjadualan biasa adalah serupa
struct rt_rq {
struct rt_prio_array active;
unsigned long rt_nr_running;
#if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED
struct {
int curr; /* highest queued rt task prio */
#ifdef CONFIG_SMP
int next; /* next highest */
#endif
} highest_prio;
#endif
#ifdef CONFIG_SMP
unsigned long rt_nr_migratory;
unsigned long rt_nr_total;
int overloaded;
struct plist_head pushable_tasks;
#endif
//当前队列的实时调度是否受限
int rt_throttled;
//当前队列的累计运行时间
u64 rt_time;
//当前队列的最大运行时间
u64 rt_runtime;
/* Nests inside the rq lock: */
raw_spinlock_t rt_runtime_lock;
#ifdef CONFIG_RT_GROUP_SCHED
unsigned long rt_nr_boosted;
//当前实时调度队列归属调度队列
struct rq *rq;
struct list_head leaf_rt_rq_list;
//当前实时调度队列归属的调度单元
struct task_group *tg;
#endif
};
Melalui analisis ketiga-tiga struktur di atas, gambar berikut boleh diperolehi (klik untuk besarkan gambar):
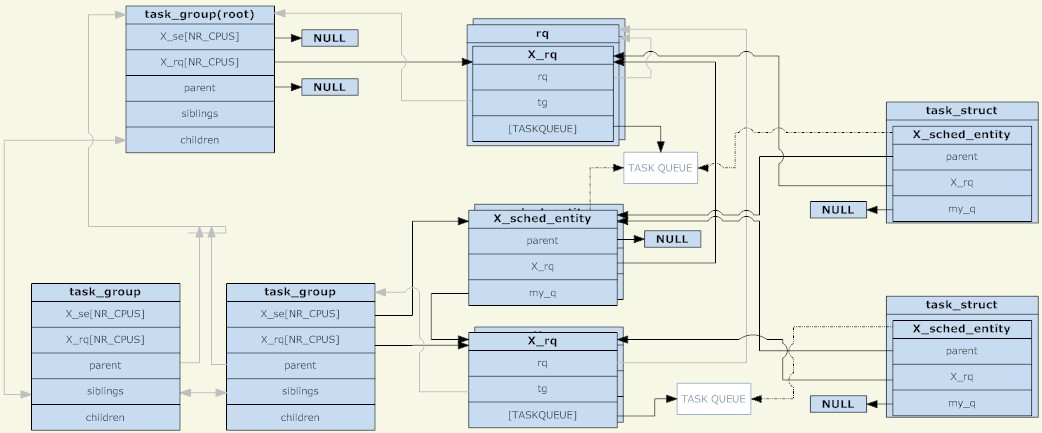 kumpulan_tugas
kumpulan_tugasSeperti yang dapat dilihat dari rajah, unit penjadualan dan baris gilir penjadualan digabungkan menjadi satu nod pokok, yang merupakan satu lagi struktur pokok yang berasingan Walau bagaimanapun, perlu diingatkan bahawa unit penjadualan hanya akan diletakkan apabila terdapat proses TASK_RUNNING. dalam unit penjadualan ke dalam baris gilir penghantaran.
Perkara lain ialah sebelum ada penjadualan kumpulan, hanya terdapat satu baris gilir penjadualan pada setiap CPU Pada masa itu, boleh difahami bahawa semua proses berada dalam satu kumpulan penjadualan Kini, setiap kumpulan penjadualan mempunyai baris gilir penjadualan pada setiap CPU. Semasa proses penjadualan, sistem pada asalnya memilih proses untuk dijalankan Pada masa ini, ia memilih unit penjadualan untuk dijalankan Apabila penjadualan berlaku, proses jadual bermula dari root_task_group dan mencari unit penjadualan yang ditentukan oleh dasar penjadualan unit ialah kumpulan_tugas, ia memasuki kumpulan_tugasan Barisan gilir memilih unit penjadualan yang sesuai dan akhirnya menemui unit penjadualan tugas yang sesuai. Keseluruhan proses ialah traversal pokok Kumpulan tugas dengan proses TASK_RUNNING ialah nod pokok, dan unit penjadualan tugas ialah daun pokok.
Strategi penjadualan proses kumpulan
Tujuan penjadualan proses berkumpulan tidak berbeza dengan yang asal, iaitu untuk melengkapkan penjadualan proses masa nyata dan penjadualan proses biasa, iaitu penjadualan rt dan cfs.
CFS组调度策略:
文章前面示例中提到的任务分配CPU,说的就是cfs调度,对于CFS调度而言,调度单元和普通调度进程没有多大区别,调度单元由自己的调度优先级,而且不受调度进程的影响,每个task_group都有一个shares,share并非我们说的进程优先级,而是调度权重,这个是cfs调度管理的概念,但在cfs中最终体现到调度优先排序上。shares值默认都是相同的,所有没有设置权重的值,CPU都是按旧有的cfs管理分配的。总结的说,就是cfs组调度策略没变化。具体到cgroup的CPU控制机制上再说。
RT组调度策略:
实时进程的优先级是设置固定,调度器总是选择优先级最高的进程运行。而在组调度中,调度单元的优先级则是组内优先级最高的调度单元的优先级值,也就是说调度单元的优先级受子调度单元影响,如果一个进程进入了调度单元,那么它所有的父调度单元的调度队列都要重排。实际上我们看到的结果是,调度器总是选择优先级最高的实时进程调度,那么组调度对实时进程控制机制是怎么样的?
在前面的rt_rq实时进程运行队列里面提到rt_time和rt_runtime,一个是运行累计时间,一个是最大运行时间,当运行累计时间超过最大运行时间的时候,rt_throttled则被设置为1,见sched_rt_runtime_exceeded函数。
if (rt_rq->rt_time > runtime) {
rt_rq->rt_throttled = 1;
if (rt_rq_throttled(rt_rq)) {
sched_rt_rq_dequeue(rt_rq);
return 1;
}
}
设置为1意味着实时队列中被限制了,如__enqueue_rt_entity函数,不能入队。
static inline int rt_rq_throttled(struct rt_rq *rt_rq)
{
return rt_rq->rt_throttled && !rt_rq->rt_nr_boosted;
}
static void __enqueue_rt_entity(struct sched_rt_entity *rt_se, bool head)
{
/*
* Don't enqueue the group if its throttled, or when empty.
* The latter is a consequence of the former when a child group
* get throttled and the current group doesn't have any other
* active members.
*/
if (group_rq && (rt_rq_throttled(group_rq) || !group_rq->rt_nr_running))
return;
.....
}
其实还有一个隐藏的时间概念,即sched_rt_period_us,意味着sched_rt_period_us时间内,实时进程可以占用CPU rt_runtime时间,如果实时进程每个时间周期内都没有调度,则在do_sched_rt_period_timer定时器函数中将rt_time减去一个周期,然后比较rt_runtime,恢复rt_throttled。
//overrun来自对周期时间定时器误差的校正 rt_rq->rt_time -= min(rt_rq->rt_time, overrun*runtime); if (rt_rq->rt_throttled && rt_rq->rt_time rt_throttled = 0; enqueue = 1;
则对于cgroup控制实时进程的占用比则是通过rt_runtime实现的,对于root_task_group,也即是所有进程在一个cgroup下,则是通过/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us接口设置的,默认值是1s和0.95s。这么看以为实时进程只能占用95%CPU,那么实时进程占用CPU100%导致进程挂死的问题怎么出现了?
原来实时进程所在的CPU占用超时了,实时进程的rt_runtime可以向别的cpu借用,将其他CPU剩余的rt_runtime-rt_time的值借过来,如此rt_time可以最大等于rt_runtime,造成事实上的单核CPU达到100%。这样做的目的自然规避了实时进程缺少CPU时间而向其他核迁移的成本,未绑核的普通进程自然也可以迁移其他CPU上,不会得不到调度,当然绑核进程仍然是个杯具。
static int do_balance_runtime(struct rt_rq *rt_rq)
{
struct rt_bandwidth *rt_b = sched_rt_bandwidth(rt_rq);
struct root_domain *rd = cpu_rq(smp_processor_id())->rd;
int i, weight, more = 0;
u64 rt_period;
weight = cpumask_weight(rd->span);
raw_spin_lock(&rt_b->rt_runtime_lock);
rt_period = ktime_to_ns(rt_b->rt_period);
for_each_cpu(i, rd->span) {
struct rt_rq *iter = sched_rt_period_rt_rq(rt_b, i);
s64 diff;
if (iter == rt_rq)
continue;
raw_spin_lock(&iter->rt_runtime_lock);
/*
* Either all rqs have inf runtime and there's nothing to steal
* or __disable_runtime() below sets a specific rq to inf to
* indicate its been disabled and disalow stealing.
*/
if (iter->rt_runtime == RUNTIME_INF)
goto next;
/*
* From runqueues with spare time, take 1/n part of their
* spare time, but no more than our period.
*/
diff = iter->rt_runtime - iter->rt_time;
if (diff > 0) {
diff = div_u64((u64)diff, weight);
if (rt_rq->rt_runtime + diff > rt_period)
diff = rt_period - rt_rq->rt_runtime;
iter->rt_runtime -= diff;
rt_rq->rt_runtime += diff;
more = 1;
if (rt_rq->rt_runtime == rt_period) {
raw_spin_unlock(&iter->rt_runtime_lock);
break;
}
}
next:
raw_spin_unlock(&iter->rt_runtime_lock);
}
raw_spin_unlock(&rt_b->rt_runtime_lock);
return more;
}
通过本文,你应该对 Linux 进程组调度机制有了一个深入的了解,知道了它的定义、原理、流程和优化方法。你也应该明白了进程组调度机制的作用和影响,以及如何在 Linux 下正确地使用和配置进程组调度机制。我们建议你在使用 Linux 系统时,使用进程组调度机制来提高系统的效率和安全性。同时,我们也提醒你在使用进程组调度机制时要注意一些潜在的问题和挑战,如进程组类型、优先级、限制等。希望本文能够帮助你更好地使用 Linux 系统,让你在 Linux 下享受进程组调度机制的优势和便利。
Atas ialah kandungan terperinci Mekanisme penjadualan kumpulan proses Linux: cara mengumpulkan dan menjadualkan proses. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!