
Rumah >Peranti teknologi >AI >Model matematik sumber terbuka 7B mengalahkan berbilion GPT-4, yang dihasilkan oleh pasukan China
Model matematik sumber terbuka 7B mengalahkan berbilion GPT-4, yang dihasilkan oleh pasukan China

- 王林ke hadapan
- 2024-02-07 17:03:28867semak imbas
Model sumber terbuka 7B, kuasa matematik melebihi 100 bilion skala GPT-4!
Prestasinya boleh dikatakan telah menembusi had model sumber terbuka Malah penyelidik dari Alibaba Tongyi mengeluh sama ada undang-undang penskalaan telah gagal.

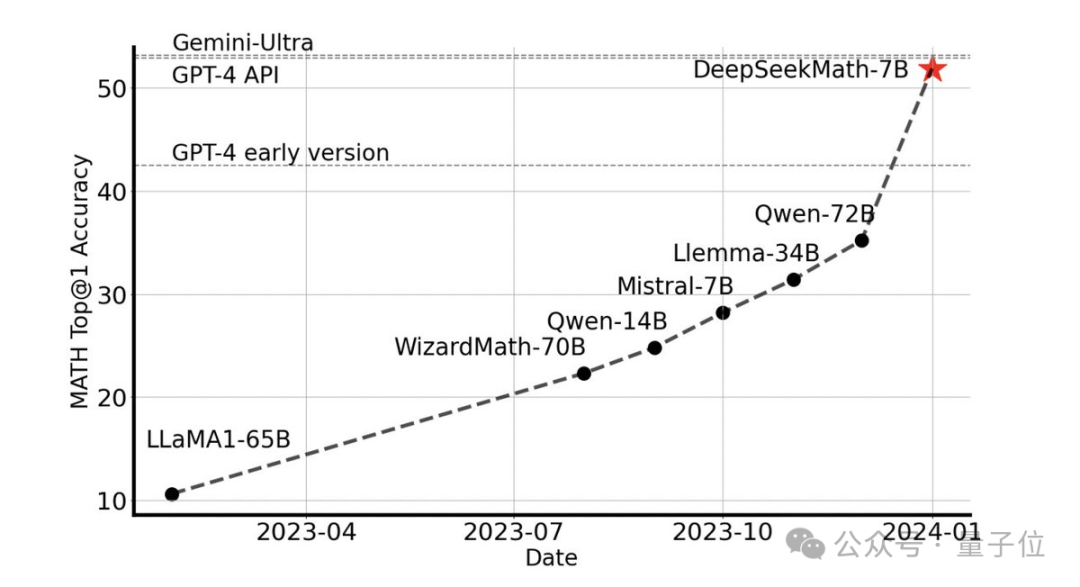
Tanpa sebarang alat luaran, ia boleh mencapai ketepatan 51.7% pada set data MATH peringkat pertandingan.
Antara model sumber terbuka, ia adalah yang pertama mencapai separuh ketepatan pada set data ini, malah mengatasi versi awal dan API GPT-4.
Persembahan ini mengejutkan seluruh komuniti sumber terbuka Emad Mostaque, pengasas Stability AI, memuji pasukan R&D sebagai mengagumkan dan dengan potensi yang dipandang rendah.
Ia adalah model matematik besar 7B DeepSeekMath sumber terbuka terbaharu pasukan Deep Search.
Model 7B mengatasi yang lain
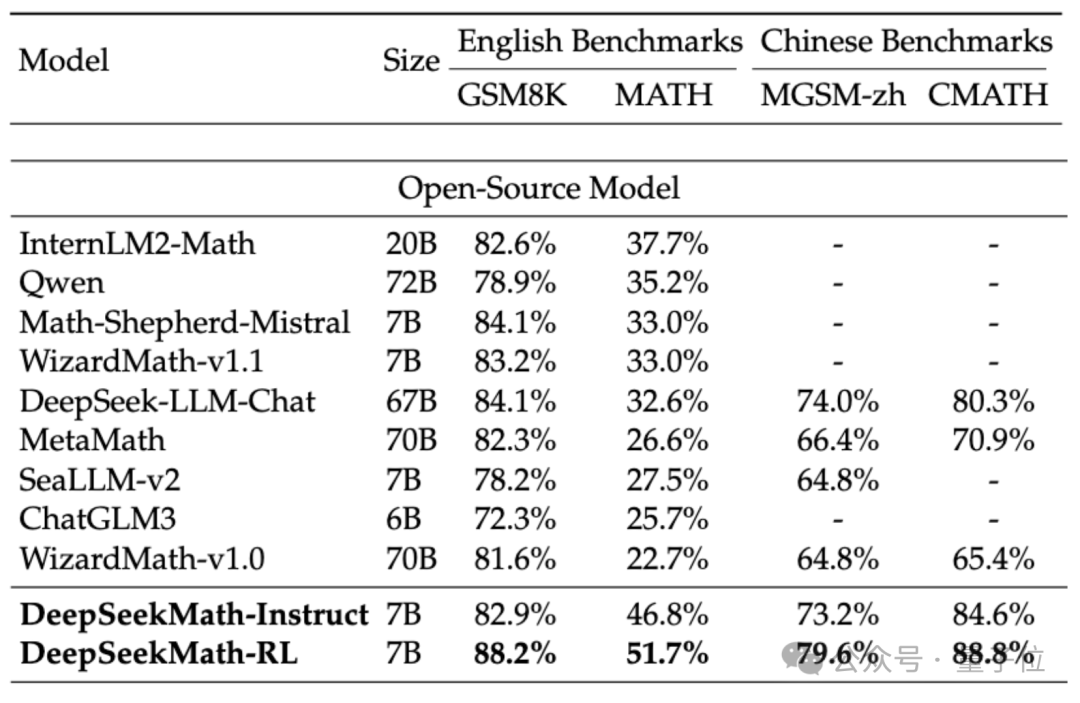
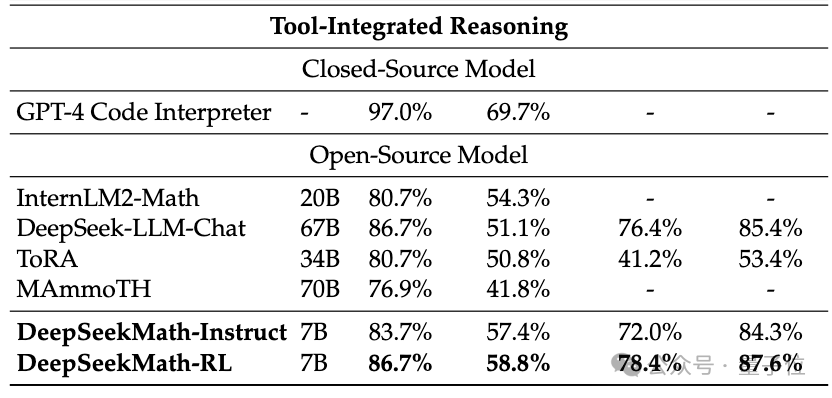
Untuk menilai keupayaan matematik DeepSeekMath, pasukan penyelidik menggunakan bahasa Cina (MGSM-zh, CMATH) Bahasa Inggeris (GSM8K, MATH) set data dwibahasa untuk ujian.
Tanpa menggunakan alat bantu dan hanya bergantung pada gesaan rantaian pemikiran(CoT), DeepSeekMath mengatasi model sumber terbuka lain, termasuk model matematik besar 70B MetaMATH.
Berbanding dengan model besar universal 67B yang dilancarkan sendiri, keputusan DeepSeekMath juga telah dipertingkatkan dengan ketara.
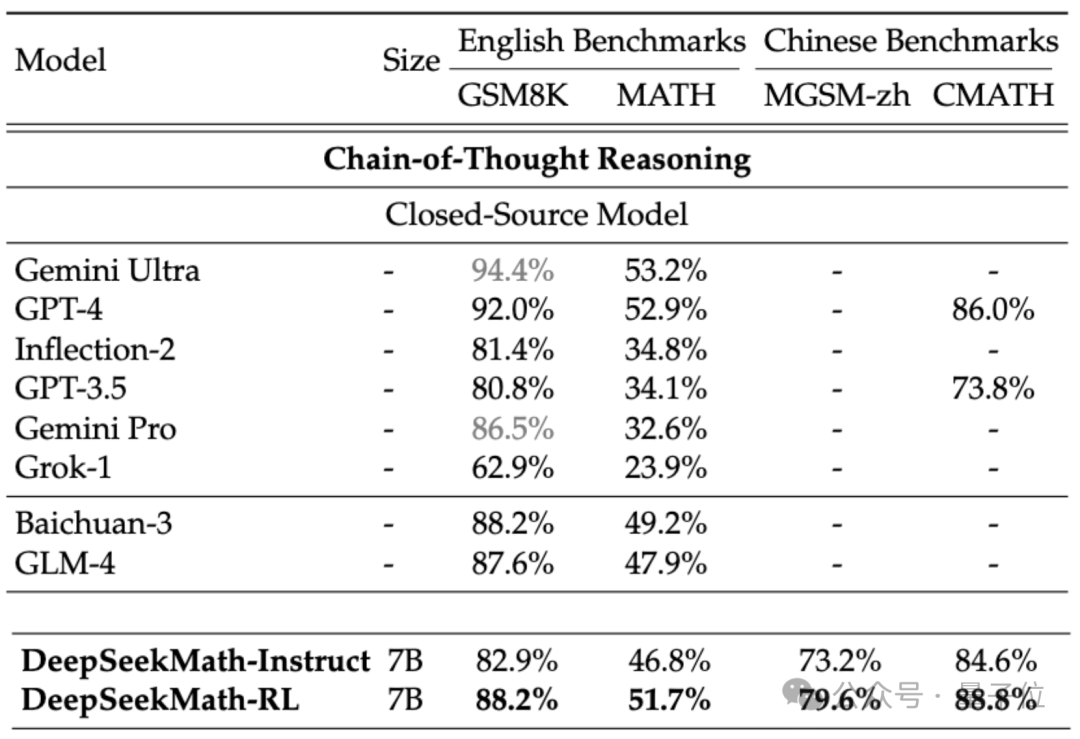
Jika kita menganggap model sumber tertutup, DeepSeekMath juga mengatasi Gemini Pro dan GPT-3.5 pada beberapa set data, mengatasi GPT-4 pada CMATH Cina dan prestasinya pada MATH juga hampir dengannya.
Tetapi harus diingat bahawa GPT-4 adalah raksasa dengan ratusan bilion parameter mengikut spesifikasi yang dibocorkan, manakala DeepSeekMath hanya mempunyai parameter 7B.
Jika alat (Python) dibenarkan digunakan untuk bantuan, prestasi DeepSeekMath mengenai kesukaran pertandingan (MATH) set data boleh dipertingkatkan dengan 7 mata peratusan lagi.
Jadi, apakah teknologi yang digunakan di sebalik prestasi cemerlang DeepSeekMath?
Dibina berdasarkan model kod
Untuk mendapatkan keupayaan matematik yang lebih baik daripada model umum, pasukan penyelidik menggunakan model kod DeepSeek-Coder-v1.5 untuk memulakannya.
Oleh kerana pasukan mendapati bahawa latihan kod boleh meningkatkan keupayaan matematik model berbanding latihan data am, sama ada dalam latihan dua peringkat atau tetapan latihan satu peringkat.
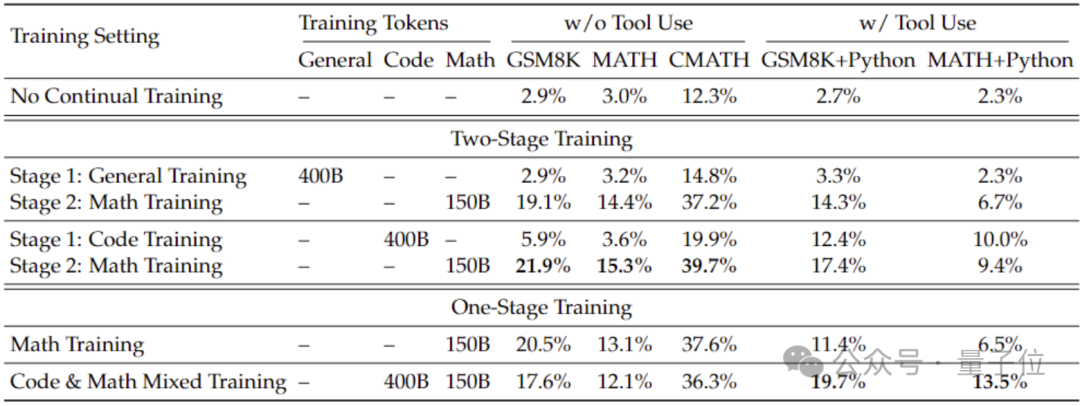
Berdasarkan Coder, pasukan penyelidik terus melatih 500 bilion token Pengedaran data adalah seperti berikut:
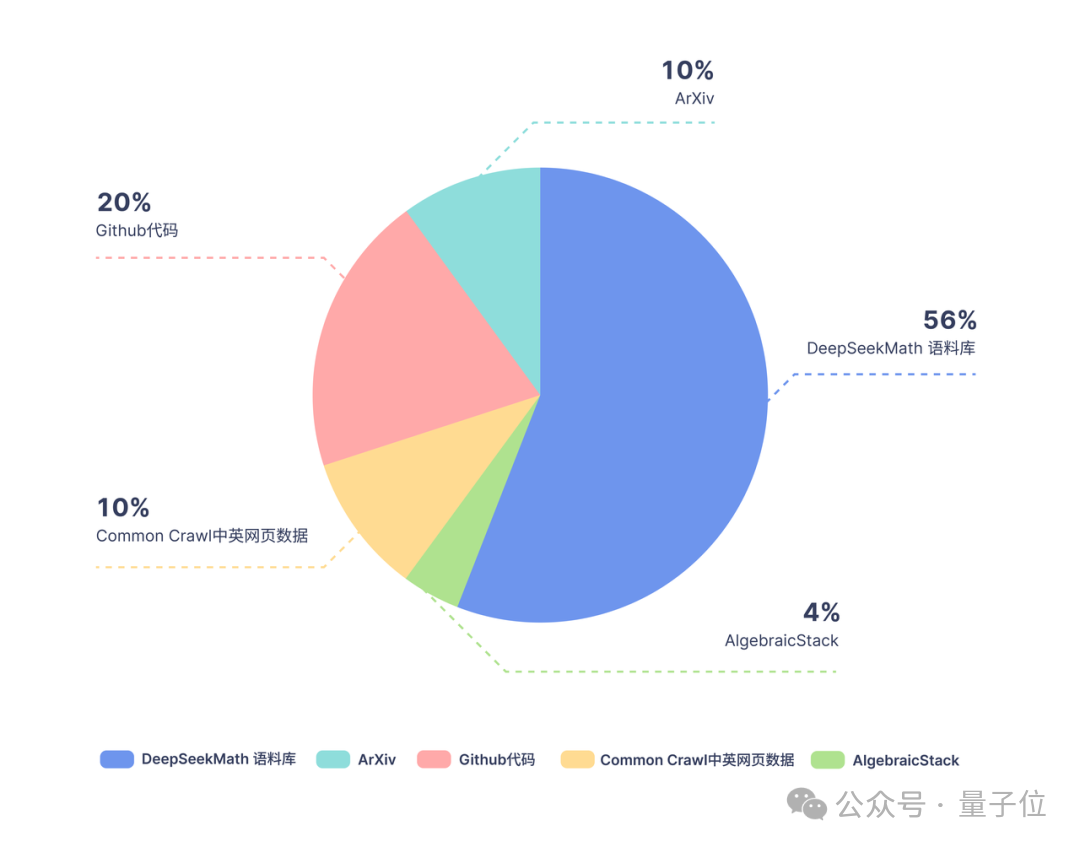
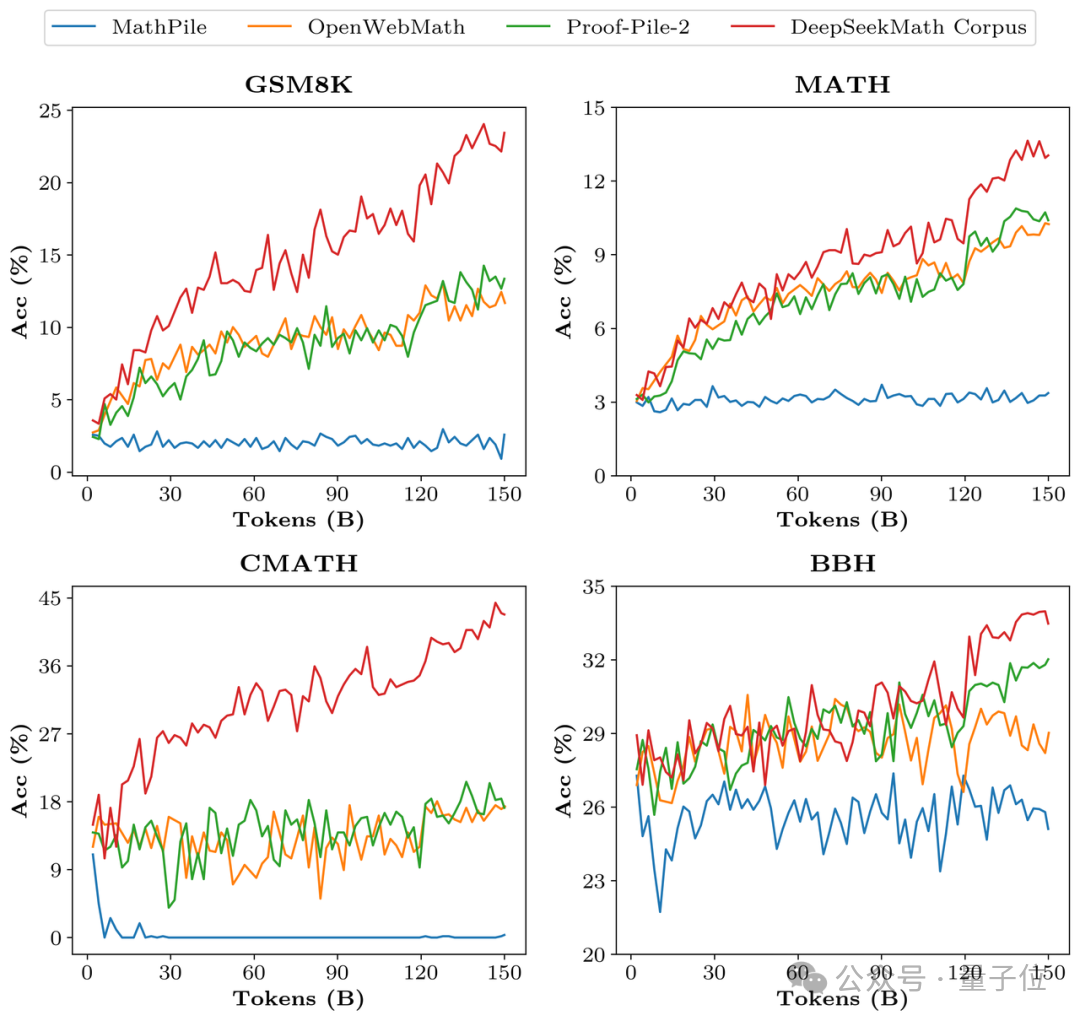
Dari segi data latihan, DeepSeekMath menggunakan 120B data bermutu tinggi dari laman web Crawl Common. . DeepSeekMath Corpus telah diperoleh, dan jumlah volum data adalah 9 kali ganda daripada kumpulan data sumber terbuka OpenWebMath.
Proses pengumpulan data dijalankan secara berulang Selepas empat lelaran, pasukan penyelidik mengumpul lebih daripada 35 juta halaman web matematik, dan bilangan Token mencapai 120 bilion.
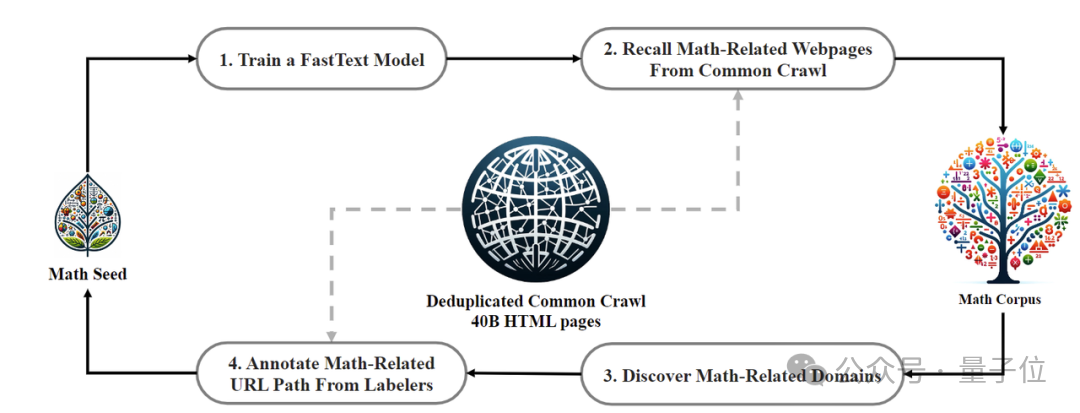
Untuk memastikan data latihan tidak mengandungi kandungan set ujian (kerana kandungan dalam GSM8K dan MATH wujud dalam kuantiti yang banyak di Internet), pasukan penyelidik juga melakukan penapisan khas.
Untuk mengesahkan kualiti data DeepSeekMath Corpus, pasukan penyelidik melatih 150 bilion token menggunakan berbilang set data seperti MathPile Akibatnya, Corpus berada di hadapan dengan ketara dalam pelbagai penanda aras matematik.
Dalam peringkat penjajaran, pasukan penyelidik mula-mula membina set data 776K sampel matematik Cina dan Inggeris penalaan halus (SFT) yang diawasi, yang merangkumi tiga format: CoT, PoT dan inferens bersepadu alatan.
Dalam peringkat pembelajaran pengukuhan (RL) , pasukan penyelidik menggunakan algoritma yang cekap dipanggil "Pengoptimuman Dasar Relatif Kumpulan (GRPO) ".
GRPO ialah varian Pengoptimuman Dasar Proksimal(PPO) , di mana fungsi nilai tradisional digantikan dengan anggaran ganjaran relatif berasaskan kumpulan, yang boleh mengurangkan keperluan pengiraan dan ingatan semasa latihan.
Pada masa yang sama, GRPO dilatih melalui proses berulang, dan model ganjaran dikemas kini secara berterusan berdasarkan output model dasar untuk memastikan penambahbaikan berterusan polisi.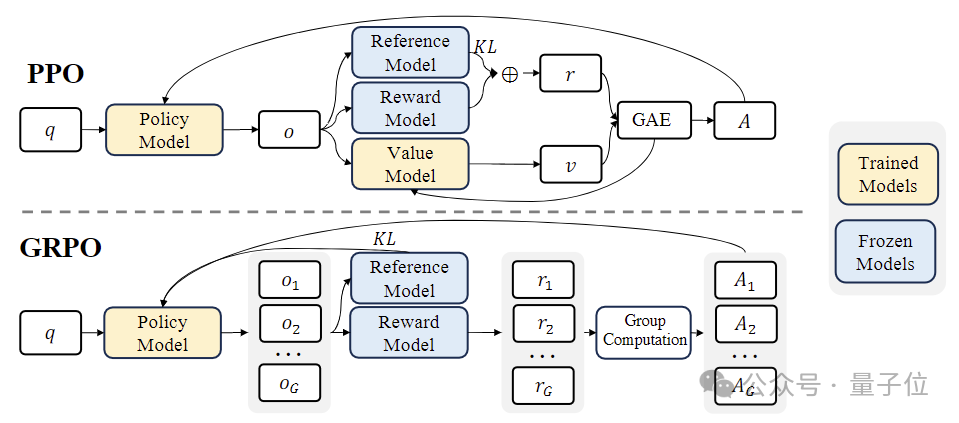

Alamat kertas: https://arxiv.org/abs/2402.03300
Atas ialah kandungan terperinci Model matematik sumber terbuka 7B mengalahkan berbilion GPT-4, yang dihasilkan oleh pasukan China. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!