
Rumah >Peranti teknologi >AI >Tiga kertas menyelesaikan masalah 'Pengoptimuman dan Penilaian Segmentasi Semantik'! Leuven/Tsinghua/Oxford dan lain-lain bersama-sama mencadangkan kaedah baharu
Tiga kertas menyelesaikan masalah 'Pengoptimuman dan Penilaian Segmentasi Semantik'! Leuven/Tsinghua/Oxford dan lain-lain bersama-sama mencadangkan kaedah baharu

- 王林ke hadapan
- 2024-02-06 21:15:17992semak imbas
Fungsi kehilangan yang biasa digunakan untuk mengoptimumkan model segmentasi semantik termasuk kehilangan Soft Jaccard, kehilangan Soft Dice dan kehilangan Soft Tversky. Walau bagaimanapun, fungsi kehilangan ini tidak serasi dengan label lembut dan oleh itu tidak dapat menyokong beberapa teknik latihan penting seperti pelicinan label, penyulingan pengetahuan, pembelajaran separa penyeliaan dan berbilang annotator. Teknik latihan ini sangat penting untuk meningkatkan prestasi dan keteguhan model segmentasi semantik, jadi kajian lanjut dan pengoptimuman fungsi kehilangan diperlukan untuk menyokong aplikasi teknik latihan ini.
Sebaliknya, penunjuk penilaian segmentasi semantik yang biasa digunakan termasuk mAcc dan mIoU. Walau bagaimanapun, penunjuk ini mempunyai keutamaan untuk objek yang lebih besar, yang memberi kesan serius kepada penilaian prestasi keselamatan model.
Untuk menyelesaikan masalah ini, penyelidik di Universiti Leuven dan Tsinghua mula-mula mencadangkan kerugian JDT. Kehilangan JDT ialah penalaan halus bagi fungsi kehilangan asal, yang merangkumi kerugian Jaccard Metric, Dice Semimetric loss dan Compatible Tversky loss. Kehilangan JDT adalah bersamaan dengan fungsi kehilangan asal apabila berurusan dengan label keras, dan juga terpakai sepenuhnya untuk label lembut. Peningkatan ini menjadikan latihan model lebih tepat dan stabil.
Penyelidik berjaya menggunakan kehilangan JDT dalam empat senario penting: pelicinan label, penyulingan pengetahuan, pembelajaran separa penyeliaan dan berbilang annotator. Aplikasi ini menunjukkan kuasa kehilangan JDT untuk meningkatkan ketepatan dan penentukuran model.
 Gambar
Gambar
Pautan kertas: https://arxiv.org/pdf/2302.05666.pdf
 Pictures
Pictures
:v/pdf 03.16296 .pdf
Selain itu, penyelidik juga mencadangkan penunjuk penilaian yang terperinci. Metrik penilaian yang terperinci ini kurang berat sebelah terhadap objek bersaiz besar, memberikan maklumat statistik yang lebih kaya dan boleh memberikan cerapan berharga untuk pengauditan model dan set data.
Dan, para penyelidik menjalankan kajian penanda aras yang meluas yang menekankan keperluan untuk tidak mengasaskan penilaian pada satu metrik dan menemui peranan penting struktur rangkaian saraf dan kehilangan JDT dalam mengoptimumkan metrik yang terperinci.
 Gambar
Gambar
Pautan kertas: https://arxiv.org/pdf/2310.19252.pdf
Pautan kod: https://github.com/zifuwanggg/Function
LossesLosses
JDTMemandangkan Jaccard Index dan Dice Score ditakrifkan pada set, ia tidak boleh dibezakan. Untuk menjadikannya boleh dibezakan, pada masa ini terdapat dua pendekatan biasa: satu ialah menggunakan hubungan antara set dan modul Lp bagi vektor yang sepadan, seperti kehilangan Soft Jaccard (SJL), kehilangan Dadu Lembut (SDL) dan Tversky Lembut. kerugian (STL). Mereka menulis saiz set sebagai modul L1 bagi vektor yang sepadan, dan menulis persilangan dua set sebagai hasil dalam dua vektor yang sepadan. Yang lain ialah menggunakan sifat submodular Indeks Jaccard untuk melakukan pengembangan Lovasz pada fungsi yang ditetapkan, seperti kehilangan Lovasz-Softmax (LSL).
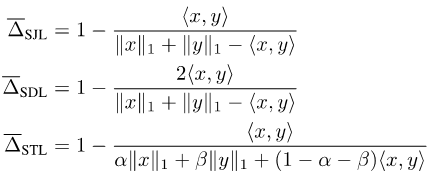 Gambar
Gambar
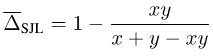 picture
picture
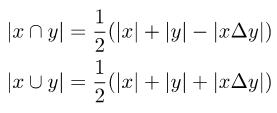 Gambar
Gambar
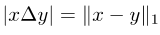 Gambar
Gambar
Menyatukan perkara di atas, kami mencadangkan kerugian JDT. Ia adalah varian SJL, Jaccard Metric loss (JML), varian SDL, Dice Semimetric loss (DML) dan varian STL, Compatible Tversky loss (CTL).
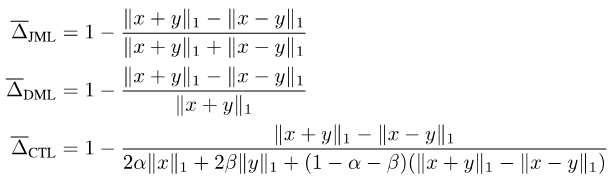 Gambar
Gambar
Sifat kehilangan JDT
Kami membuktikan kerugian JDT mempunyai sifat berikut.
Sifat 1: JML ialah metrik dan DML ialah semimetrik.
Harta 2: Apabila y ialah label keras, JML bersamaan dengan SJL, DML bersamaan dengan SDL dan CTL bersamaan dengan STL.
Sifat 3: Apabila y ialah label lembut, JML, DML dan CTL semuanya serasi dengan label lembut, iaitu x = y ó f(x, y) = 0.
Disebabkan Harta 1, mereka juga dipanggil kerugian Jaccard Metric dan Dice Semimetric loss. Harta 2 menunjukkan bahawa dalam senario umum di mana hanya label keras digunakan untuk latihan, kehilangan JDT boleh digunakan terus untuk menggantikan fungsi kehilangan sedia ada tanpa menyebabkan sebarang perubahan.
Cara menggunakan kehilangan JDT
Kami telah menjalankan banyak eksperimen dan merumuskan beberapa langkah berjaga-jaga untuk menggunakan kehilangan JDT.
Nota 1: Pilih fungsi kerugian yang sepadan berdasarkan indeks penilaian. Jika indeks penilaian ialah Indeks Jaccard, maka JML hendaklah dipilih jika indeks penilaian ialah Skor Dadu, maka DML hendaklah dipilih jika anda ingin memberikan pemberat yang berbeza kepada positif palsu dan negatif palsu, maka CTL harus dipilih; Kedua, apabila mengoptimumkan petunjuk penilaian yang terperinci, kerugian JDT juga harus diubah dengan sewajarnya.
Nota 2: Gabungkan kehilangan JDT dan fungsi kehilangan tahap piksel (seperti kehilangan Cross Entropy, Kehilangan Fokus). Artikel ini mendapati bahawa 0.25CE + 0.75JDT pada umumnya adalah pilihan yang baik.
Nota 3: Sebaik-baiknya gunakan zaman yang lebih pendek untuk latihan. Selepas menambah kerugian JDT, ia secara amnya hanya memerlukan separuh tempoh latihan kehilangan Cross Entropy.
Nota 4: Apabila melaksanakan latihan teragih pada berbilang GPU, jika tiada komunikasi tambahan antara GPU, kehilangan JDT akan tersalah mengoptimumkan metrik penilaian halus, mengakibatkan prestasi lemah pada mIoU tradisional.
Nota 5: Apabila latihan pada set data dengan ketidakseimbangan kategori melampau, sila ambil perhatian bahawa kerugian JDL dikira secara berasingan pada setiap kategori dan kemudian dipuratakan, yang mungkin menjadikan latihan tidak stabil.
Hasil eksperimen
Eksperimen telah membuktikan bahawa, berbanding garis dasar kehilangan Cross Entropy, menambah kehilangan JDT boleh meningkatkan ketepatan model dengan berkesan apabila berlatih dengan label keras. Ketepatan dan penentukuran model boleh dipertingkatkan lagi dengan memperkenalkan label lembut.
 Gambar
Gambar
Hanya menambah istilah kehilangan JDT semasa latihan, artikel ini telah mencapai SOTA dalam penyulingan pengetahuan, pembelajaran separa penyeliaan dan multi-annotator dalam segmentasi semantik. .
Segmentasi semantik ialah tugas pengelasan tahap piksel, jadi setiap ketepatan Pixel: piksel keseluruhan- ketepatan bijak (Acc). Walau bagaimanapun, kerana Acc memihak kepada kategori majoriti, PASCAL VOC 2007 mengguna pakai indeks penilaian yang mengira ketepatan piksel bagi setiap kategori secara berasingan dan kemudian puratanya: min ketepatan mengikut piksel (mAcc).
 Tetapi memandangkan mAcc tidak menganggap positif palsu, sejak PASCAL VOC 2008, purata persimpangan dan nisbah kesatuan (per-dataset mIoU, mIoUD) telah digunakan sebagai indeks penilaian. PASCAL VOC ialah set data pertama yang memperkenalkan tugas pembahagian semantik, dan penunjuk penilaian yang digunakan digunakan secara meluas dalam pelbagai set data berikutnya.
Tetapi memandangkan mAcc tidak menganggap positif palsu, sejak PASCAL VOC 2008, purata persimpangan dan nisbah kesatuan (per-dataset mIoU, mIoUD) telah digunakan sebagai indeks penilaian. PASCAL VOC ialah set data pertama yang memperkenalkan tugas pembahagian semantik, dan penunjuk penilaian yang digunakan digunakan secara meluas dalam pelbagai set data berikutnya.
Untuk mengira mIoUD, kita perlu mengira positif benar (TP) dan positif palsu (FP) semua foto I dalam keseluruhan set data untuk setiap kategori c. FN): Selepas mempunyai nilai berangka untuk setiap kategori, kami purata mengikut kategori, sekali gus menghapuskan keutamaan untuk kategori majoriti: Gambar Untuk setiap kategori c, kami mula-mula mengisih nilai IoU bagi semua foto yang telah dipaparkan (dengan mengandaikan terdapat Ic foto sedemikian) dalam tertib menaik. Seterusnya, kita tetapkan q menjadi nombor kecil, seperti 1 atau 5. Kemudian, kami hanya menggunakan Ic * q% atas foto yang diisih untuk mengira nilai akhir: Selepas mempunyai nilai setiap kelas c, kita boleh mengisih mengikut kategori seperti sebelum ini Purata ini untuk mendapatkan metrik kes terburuk mIoUC. Kami melatih 15 model pada 12 set data dan menemui fenomena berikut. Fenomena 1: Tiada model boleh mencapai hasil terbaik pada semua penunjuk penilaian. Setiap indeks penilaian mempunyai fokus yang berbeza, jadi kita perlu mempertimbangkan beberapa indeks penilaian pada masa yang sama untuk menjalankan penilaian yang komprehensif. Fenomena 2: Terdapat beberapa foto dalam beberapa set data yang menyebabkan hampir semua model mencapai nilai IoU yang sangat rendah. Ini sebahagiannya kerana foto itu sendiri sangat mencabar, seperti beberapa objek yang sangat kecil dan kontras yang kuat antara terang dan gelap, dan sebahagiannya kerana terdapat masalah dengan label foto ini. Oleh itu, metrik penilaian yang terperinci boleh membantu kami menjalankan audit model (mencari senario di mana model melakukan kesilapan) dan audit set data (mencari label yang salah). Fenomena 3: Struktur rangkaian saraf memainkan peranan penting dalam mengoptimumkan petunjuk penilaian yang terperinci. Di satu pihak, peningkatan dalam bidang penerimaan yang dibawa oleh struktur seperti ASPP (diguna pakai oleh DeepLabV3 dan DeepLabV3+) boleh membantu model mengenali objek bersaiz besar, dengan itu meningkatkan nilai mIoUD secara berkesan, sebaliknya, jurang antara pengekod dan penyahkod Sambungan panjang (diguna pakai oleh UNet dan DeepLabV3+) membolehkan model mengenali objek bersaiz kecil, dengan itu meningkatkan nilai penunjuk penilaian yang terperinci. Fenomena 4: Nilai penunjuk kes terburuk jauh lebih rendah daripada nilai penunjuk purata yang sepadan. Jadual berikut menunjukkan mIoUC dan nilai penunjuk kes terburuk yang sepadan DeepLabV3-ResNet101 pada berbilang set data. Soalan yang patut dipertimbangkan pada masa hadapan ialah, bagaimanakah kita harus mereka bentuk struktur rangkaian saraf dan kaedah pengoptimuman untuk meningkatkan prestasi model di bawah penunjuk kes terburuk? Fenomena 5: Fungsi kehilangan memainkan peranan penting dalam mengoptimumkan petunjuk penilaian yang terperinci. Berbanding dengan penanda aras kehilangan Cross Entropy, seperti yang ditunjukkan dalam (0, 0, 0) dalam jadual berikut, apabila penunjuk penilaian menjadi halus, menggunakan fungsi kehilangan sepadan boleh meningkatkan prestasi model pada butiran halus. penunjuk penilaian. Sebagai contoh, pada ADE20K, perbezaan dalam kehilangan mIoUC antara JML dan Cross Entropy akan lebih besar daripada 7%. . Kedua, kerugian JDT hanya digunakan dalam ruang label, tetapi kami percaya ia boleh digunakan untuk meminimumkan jarak antara mana-mana dua vektor dalam ruang ciri, seperti menggantikan modul Lp dan jarak kosinus. 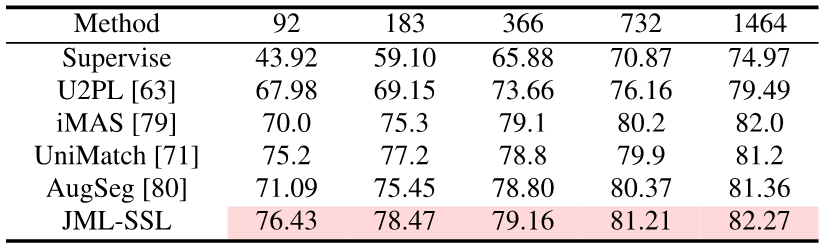
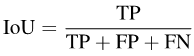 Gambar
Gambar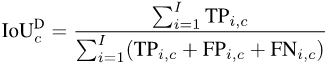 Gambar
Gambar 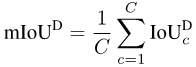

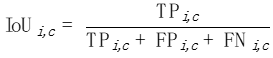 Akhir sekali, kami purata nilai semua foto:
Akhir sekali, kami purata nilai semua foto: 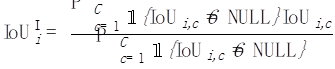
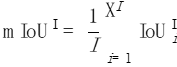
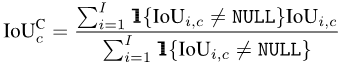
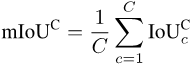
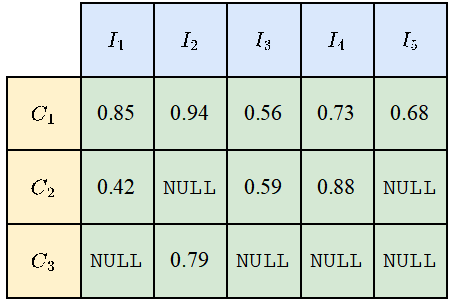 Bagi sesetengah senario aplikasi yang memfokuskan keselamatan, kami selalunya lebih mementingkan kes-kes yang paling teruk dalam segmen kualiti. keupayaan untuk mengira penunjuk kes terburuk yang sepadan. Mari kita ambil mIoUC sebagai contoh Kaedah yang serupa juga boleh mengira penunjuk kes terburuk yang sepadan bagi mIoUI.
Bagi sesetengah senario aplikasi yang memfokuskan keselamatan, kami selalunya lebih mementingkan kes-kes yang paling teruk dalam segmen kualiti. keupayaan untuk mengira penunjuk kes terburuk yang sepadan. Mari kita ambil mIoUC sebagai contoh Kaedah yang serupa juga boleh mengira penunjuk kes terburuk yang sepadan bagi mIoUI. 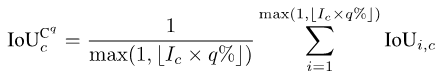 Gambar
GambarHasil eksperimen
 Gambar
Gambar
Atas ialah kandungan terperinci Tiga kertas menyelesaikan masalah 'Pengoptimuman dan Penilaian Segmentasi Semantik'! Leuven/Tsinghua/Oxford dan lain-lain bersama-sama mencadangkan kaedah baharu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!