
Rumah >Peranti teknologi >AI >CMUÐ mencapai kejayaan: anjing robot mempunyai nilai ketangkasan penuh, boleh merentas halangan pada kelajuan super tinggi dan mempunyai kedua-dua kelajuan dan keselamatan!
CMUÐ mencapai kejayaan: anjing robot mempunyai nilai ketangkasan penuh, boleh merentas halangan pada kelajuan super tinggi dan mempunyai kedua-dua kelajuan dan keselamatan!

- 王林ke hadapan
- 2024-02-05 16:33:15914semak imbas
Pasukan CMU dan ETH Zurich bekerjasama untuk membangunkan rangka kerja baharu yang dipanggil "Agile But Safe" (ABS), yang menyediakan penyelesaian untuk robot berkaki empat untuk mencapai pergerakan berkelajuan tinggi dalam persekitaran yang kompleks. Rangka kerja ini bukan sahaja menunjukkan kecekapan tinggi dalam mengelakkan perlanggaran, tetapi juga mencapai kelajuan 3.1 milisaat yang tidak pernah berlaku sebelum ini. Inovasi ini membawa kemajuan baharu kepada bidang robot berkaki.
Dalam bidang pergerakan robot berkelajuan tinggi, mengekalkan kelajuan dan keselamatan pada masa yang sama sentiasa menjadi cabaran besar. Walau bagaimanapun, pasukan penyelidik di Carnegie Mellon University (CMU) dan ETH Zurich (ETH) baru-baru ini mencapai kejayaan. Algoritma robot berkaki empat baharu yang mereka bangunkan bukan sahaja boleh bergerak pantas dalam persekitaran yang kompleks, tetapi juga dengan mahir mengelak halangan, benar-benar mencapai matlamat "ketangkasan dan keselamatan". Inovasi algoritma ini terletak pada keupayaannya untuk mengenal pasti dan menganalisis persekitaran sekeliling dengan cepat dan membuat keputusan bijak berdasarkan data masa nyata. Dengan menggunakan penderia termaju dan kuasa pengkomputeran yang berkuasa, robot dapat mengesan halangan di sekelilingnya dengan tepat dan mengelakkannya dengan melaraskan gaya berjalan dan trajektorinya. Kejayaan penerapan teknologi ini akan sangat menggalakkan pembangunan robot berkelajuan tinggi

Alamat kertas: https://arxiv.org/pdf/2401.17583.pdf
Dengan sokongan ABS, anjing robot itu boleh melakukan dalam pelbagai senario Semua telah menunjukkan keupayaan mengelak halangan berkelajuan tinggi yang menakjubkan:
Koridor sempit yang dipenuhi halangan:

Adegan dalaman yang kucar-kacir:






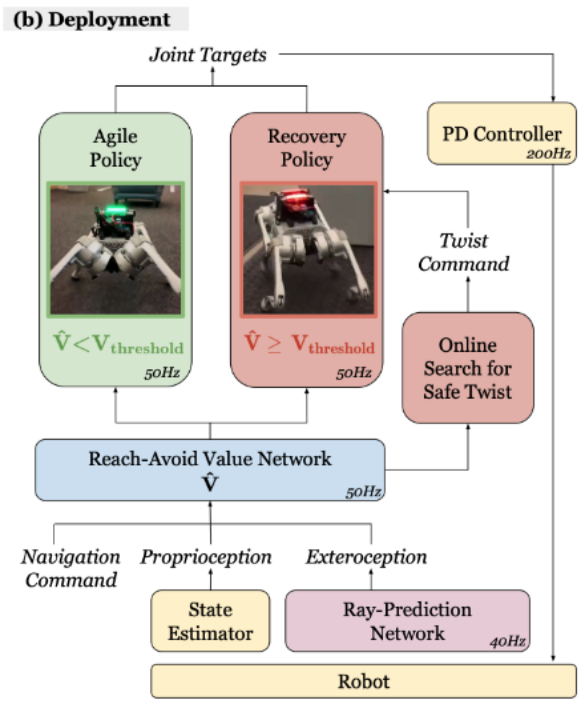
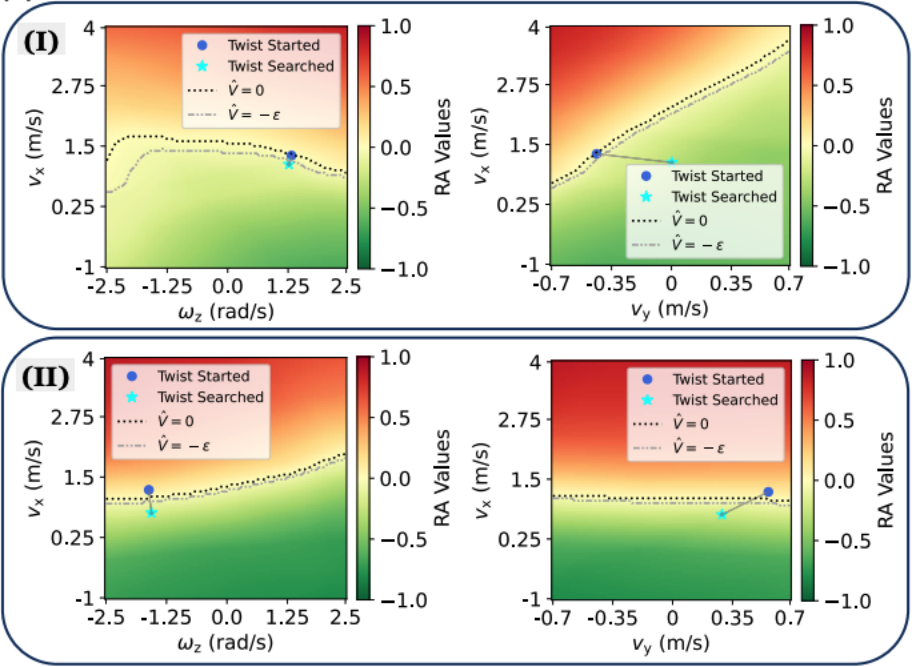
🎜🎜🎜🎜 anjing boleh mengendalikannya dengan tenang : 🎜🎜🎜🎜🎜 Apabila terserempak dengan kereta sorong, anjing robot itu mengelak dengan cekap: 🎜🎜🎜🎜🎜 Tanda amaran, kotak dan kerusi juga tidak menjadi masalah: 🎜🎜🎜🎜🎜🎜 dengan mudah. dengan kemunculan secara tiba-tiba tikar dan kaki manusia Bypass: 🎜🎜🎜🎜🎜Anjing robot pun boleh bermain helang dan menangkap ayam: 🎜🎜🎜🎜🎜🎜Teknologi Terobosan ABS: 🎜🎜🎜 Model Pembelajaran Tanpa Nilai RL+IDvo 🎜🎜🎜ABS menggunakan tetapan A dwi dasar, termasuk "Dasar Tangkas" dan "Dasar Pemulihan". Strategi ketangkasan membolehkan robot bergerak dengan pantas melalui halangan, manakala strategi pemulihan melangkah masuk untuk memastikan keselamatan robot sebaik sahaja Anggaran Nilai Jangkauan-Elak mengesan potensi bahaya (seperti kemunculan kereta sorong secara tiba-tiba). 🎜


Atas ialah kandungan terperinci CMUÐ mencapai kejayaan: anjing robot mempunyai nilai ketangkasan penuh, boleh merentas halangan pada kelajuan super tinggi dan mempunyai kedua-dua kelajuan dan keselamatan!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 人工智能产业链包括
- Memperkasakan industri fesyen dengan teknologi untuk membantu Daerah Futian membina 'Pusat Ibu Pejabat Fesyen Bay Area'
- Apakah sempadan seterusnya dalam kecerdasan buatan dan robotik?
- Tesla merancang untuk menubuhkan sebuah kilang kenderaan elektrik di India untuk mengaktifkan industri kenderaan elektrik India
- Memfokuskan pada perubahan dan kegigihan, Web3 dan AI membentuk semula dialog sidang kemuncak industri filem yang diadakan