
Rumah >Peranti teknologi >AI >jarang! Alat penyunting imej sumber terbuka Apple MGIE, adakah ia akan tersedia pada iPhone?
jarang! Alat penyunting imej sumber terbuka Apple MGIE, adakah ia akan tersedia pada iPhone?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-05 15:33:291271semak imbas
Ambil foto, masukkan arahan teks, dan telefon anda akan mula menyentuh semula foto secara automatik?
Ciri ajaib ini datang daripada alat penyunting imej sumber terbuka Apple "MGIE" yang baru.

Alih keluar orang di latar belakang
Tambahkan piza di atas meja
Baru-baru ini, AI telah mencapai kemajuan yang ketara dalam pengeditan gambar. Di satu pihak, melalui model besar berbilang modal (MLLM), AI boleh mengambil imej sebagai input dan memberikan respons persepsi visual, dengan itu mencapai penyuntingan gambar yang lebih semula jadi. Sebaliknya, teknologi penyuntingan berasaskan arahan menjadikan proses penyuntingan tidak lagi bergantung pada penerangan terperinci atau topeng kawasan, tetapi membenarkan pengguna untuk terus mengeluarkan arahan untuk menyatakan kaedah dan matlamat penyuntingan. Kaedah ini sangat praktikal kerana ia lebih sesuai dengan cara intuitif manusia. Melalui teknologi inovatif ini, AI secara beransur-ansur menjadi pembantu kanan orang ramai dalam bidang penyuntingan gambar.
Berdasarkan inspirasi teknologi di atas, Apple mencadangkan MGIE (MLLM-Guided Image Editing), menggunakan MLLM untuk menyelesaikan masalah bimbingan arahan yang tidak mencukupi. . ://mllm-ie.github.io/

- Berpandukan arahan manusia, MGIE boleh melakukan pengubahsuaian gaya Photoshop, pengoptimuman foto global dan pengubahsuaian objek tempatan. Ambil gambar di bawah sebagai contoh Sukar untuk menangkap makna "sihat" tanpa konteks tambahan, tetapi MGIE boleh mengaitkan "topping sayur-sayuran" dengan piza dan mengeditnya mengikut jangkaan manusia dengan tepat.
Ini mengingatkan kita tentang "cita-cita" yang Cook nyatakan dalam panggilan pendapatan tidak lama dahulu: "Saya fikir Apple mempunyai peluang besar dalam AI generatif, tetapi saya tidak mahu bercakap lebih lanjut. Lagi butiran.” Maklumat yang didedahkannya termasuk Apple sedang giat membangunkan ciri perisian AI generatif dan ciri ini akan tersedia kepada pelanggan pada tahun 2024.
 Digabungkan dengan satu siri hasil penyelidikan teori AI generatif yang dikeluarkan oleh Apple sejak kebelakangan ini, nampaknya kami menantikan ciri AI baharu yang akan dikeluarkan Apple seterusnya.
Digabungkan dengan satu siri hasil penyelidikan teori AI generatif yang dikeluarkan oleh Apple sejak kebelakangan ini, nampaknya kami menantikan ciri AI baharu yang akan dikeluarkan Apple seterusnya.
Butiran kertas
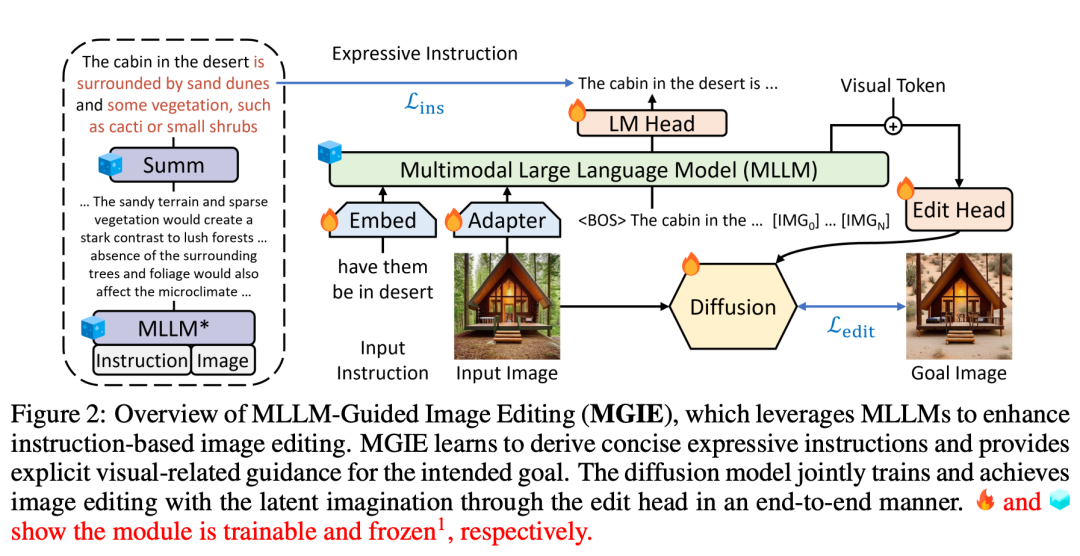
Kaedah MGIE yang dicadangkan dalam kajian ini boleh mengedit imej input V menjadi imej sasaran  melalui arahan X yang diberikan. Untuk arahan yang tidak tepat tersebut, MLLM dalam MGIE akan melakukan derivasi pembelajaran untuk mendapatkan arahan ungkapan ringkas ε. Untuk membina jambatan antara bahasa dan modaliti visual, penyelidik juga menambah token khas [IMG] selepas ε dan menggunakan kepala edit (kepala edit)
melalui arahan X yang diberikan. Untuk arahan yang tidak tepat tersebut, MLLM dalam MGIE akan melakukan derivasi pembelajaran untuk mendapatkan arahan ungkapan ringkas ε. Untuk membina jambatan antara bahasa dan modaliti visual, penyelidik juga menambah token khas [IMG] selepas ε dan menggunakan kepala edit (kepala edit) 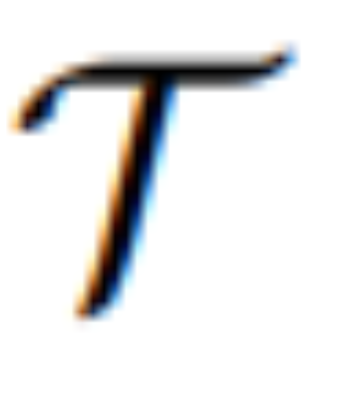 untuk menukarnya. Maklumat yang diubah akan berfungsi sebagai imaginasi visual yang mendasari dalam MLLM, membimbing model resapan untuk mencapai matlamat penyuntingan yang dikehendaki. MGIE kemudiannya dapat memahami arahan kabur yang sedar secara visual untuk melakukan penyuntingan imej yang munasabah (rajah seni bina ditunjukkan dalam Rajah 2 di atas).
untuk menukarnya. Maklumat yang diubah akan berfungsi sebagai imaginasi visual yang mendasari dalam MLLM, membimbing model resapan untuk mencapai matlamat penyuntingan yang dikehendaki. MGIE kemudiannya dapat memahami arahan kabur yang sedar secara visual untuk melakukan penyuntingan imej yang munasabah (rajah seni bina ditunjukkan dalam Rajah 2 di atas). 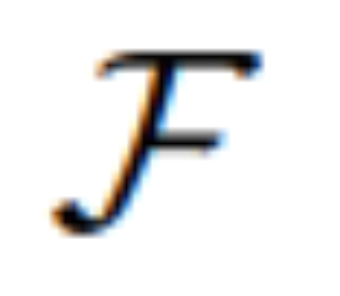
Melalui penjajaran ciri dan pelarasan arahan, MLLM mampu memberikan respons yang relevan secara visual merentas persepsi modal. Untuk penyuntingan imej, kajian menggunakan gesaan "bagaimana imej ini jika [arahan]" sebagai input bahasa untuk imej dan memperoleh penjelasan terperinci tentang arahan pengeditan. Walau bagaimanapun, penjelasan ini selalunya terlalu panjang dan malah mengelirukan niat pengguna. Untuk mendapatkan penerangan yang lebih ringkas, kajian ini menggunakan ringkasan terlatih untuk membolehkan MLLM belajar menjana output ringkasan. Proses ini boleh diringkaskan seperti berikut:
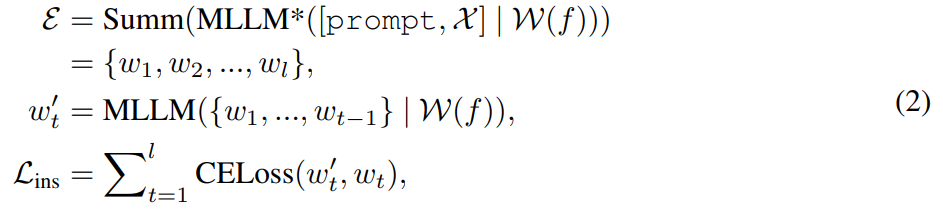
Kajian menggunakan kepala penyuntingan
untuk mengubah [IMG] sebenar. di mana 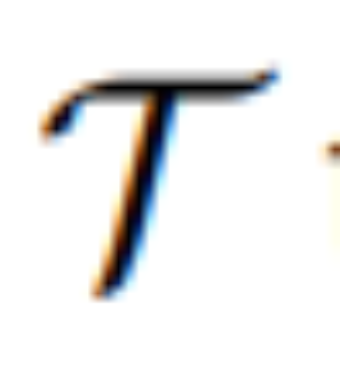 ialah model urutan-ke-jujukan yang memetakan token visual berterusan daripada MLLM kepada U terpendam bermakna secara semantik = {u_1, u_2, ..., u_L} dan berfungsi sebagai panduan editorial:
ialah model urutan-ke-jujukan yang memetakan token visual berterusan daripada MLLM kepada U terpendam bermakna secara semantik = {u_1, u_2, ..., u_L} dan berfungsi sebagai panduan editorial: 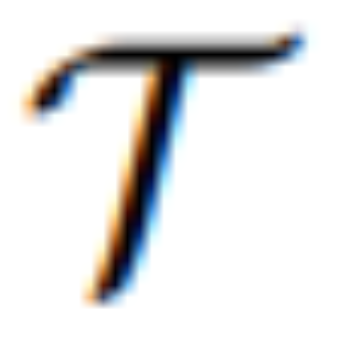
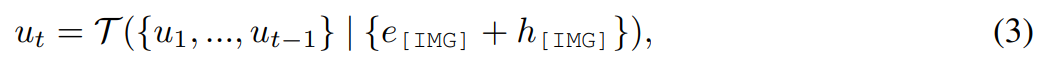
, yang sambil menyertakan pengekod auto variasi (VAE), juga boleh menyelesaikan resapan denoising dalam soalan ruang terpendam. 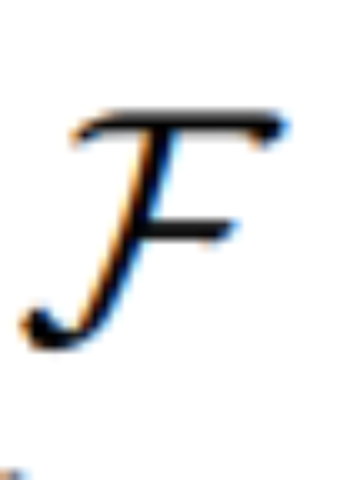
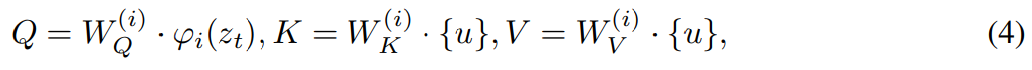
mengubah modaliti dan membimbing 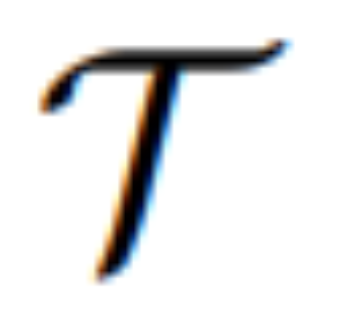 untuk mensintesis imej yang terhasil. Kehilangan edit L_edit digunakan untuk latihan penyebaran. Memandangkan kebanyakan pemberat boleh dibekukan (blok perhatian diri dalam MLLM), latihan hujung ke hujung yang cekap parameter dicapai.
untuk mensintesis imej yang terhasil. Kehilangan edit L_edit digunakan untuk latihan penyebaran. Memandangkan kebanyakan pemberat boleh dibekukan (blok perhatian diri dalam MLLM), latihan hujung ke hujung yang cekap parameter dicapai. 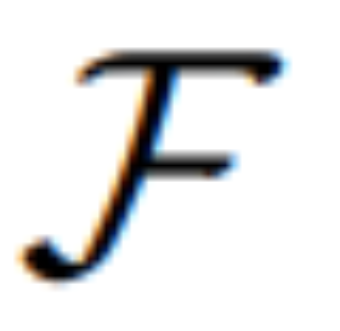

Untuk imej input, perbandingan antara kaedah berbeza di bawah arahan yang sama, seperti baris pertama arahan ialah "jadikan siang menjadi malam":
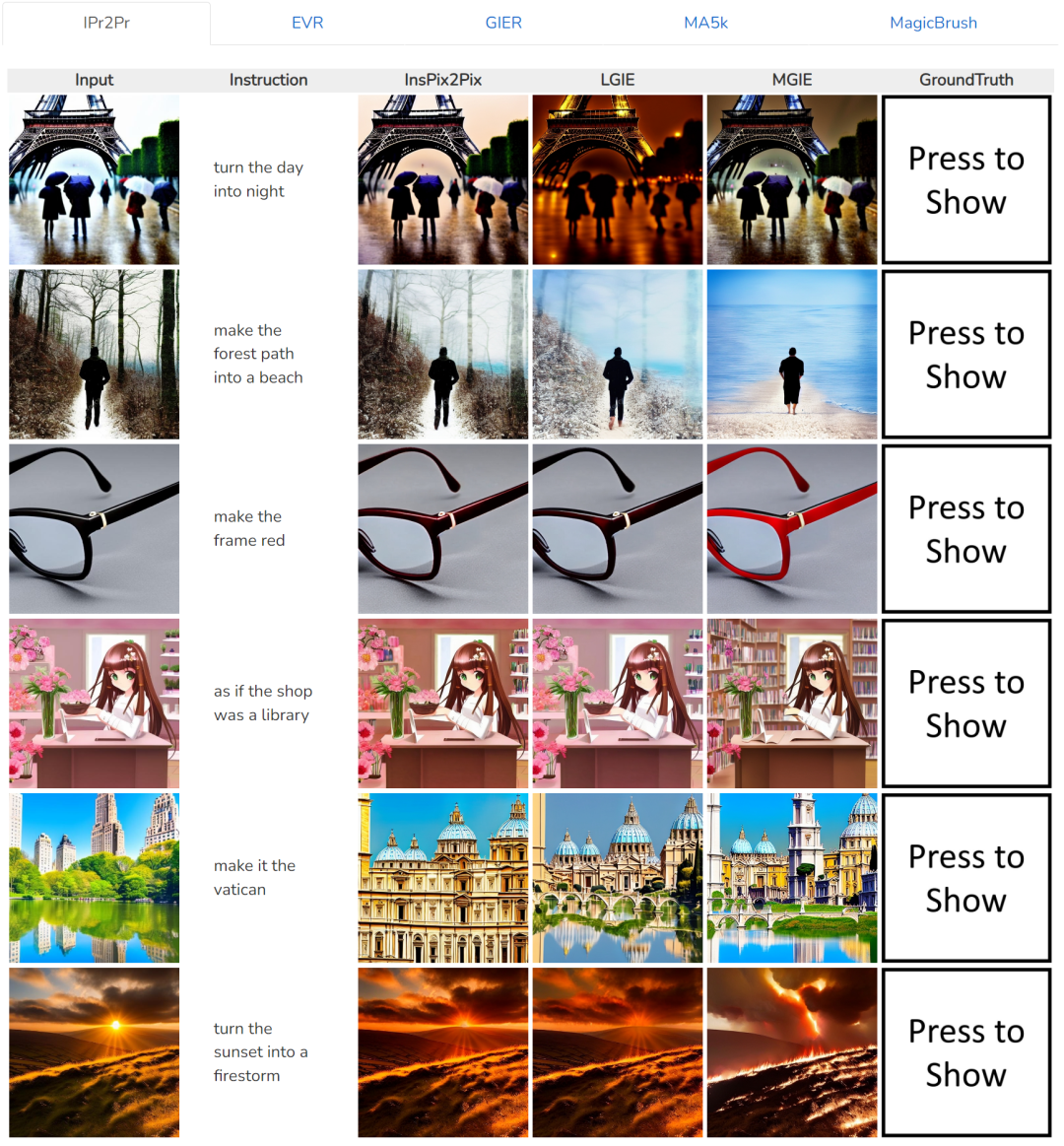
Jadual 1 menunjukkan hasil pengeditan tangkapan sifar bagi model yang dilatih hanya pada set data IPr2Pr. Untuk EVR dan GIER yang melibatkan pengubahsuaian gaya Photoshop, hasil pengeditan adalah lebih dekat dengan niat bootstrap (cth., LGIE mencapai CVS yang lebih tinggi iaitu 82.0 pada EVR). Untuk pengoptimuman imej global pada MA5k, InsPix2Pix sukar dikawal kerana kekurangan latihan tiga kali ganda yang berkaitan. LGIE dan MGIE boleh memberikan penjelasan terperinci melalui pembelajaran LLM, tetapi LGIE masih terhad kepada modaliti tunggalnya. Dengan mengakses imej, MGIE boleh memperoleh arahan eksplisit seperti kawasan mana yang harus dicerahkan atau objek mana yang harus lebih jelas, menghasilkan peningkatan prestasi yang ketara (cth., 66.3 SSIM lebih tinggi dan jarak foto 0.3 yang lebih rendah), dalam Hasil serupa ditemui pada MagicBrush. MGIE juga memperoleh prestasi terbaik daripada imejan visual yang tepat dan pengubahsuaian sasaran yang ditentukan sebagai sasaran (cth., persamaan visual 82.2 DINO yang lebih tinggi dan penjajaran sari kata global 30.4 CTS yang lebih tinggi).
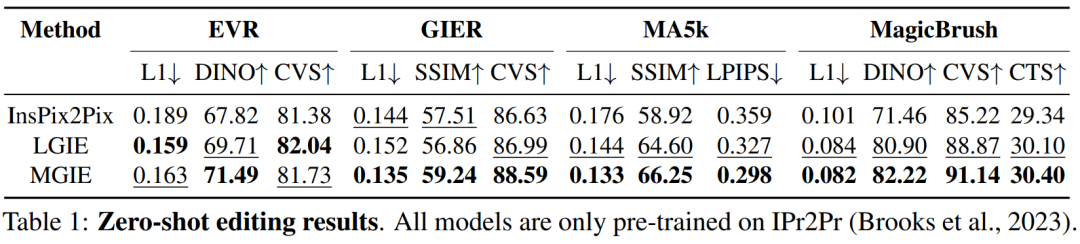
Untuk mengkaji penyuntingan imej berasaskan arahan untuk tujuan tertentu, Jadual 2 memperhalusi model pada setiap set data. Untuk EVR dan GIER, semua model bertambah baik selepas menyesuaikan diri dengan tugas penyuntingan gaya Photoshop. MGIE secara konsisten mengatasi LGIE dalam setiap aspek penyuntingan. Ini juga menggambarkan bahawa pembelajaran menggunakan arahan ekspresif boleh meningkatkan penyuntingan imej dengan berkesan, dan persepsi visual memainkan peranan penting dalam mendapatkan panduan yang jelas untuk peningkatan maksimum.
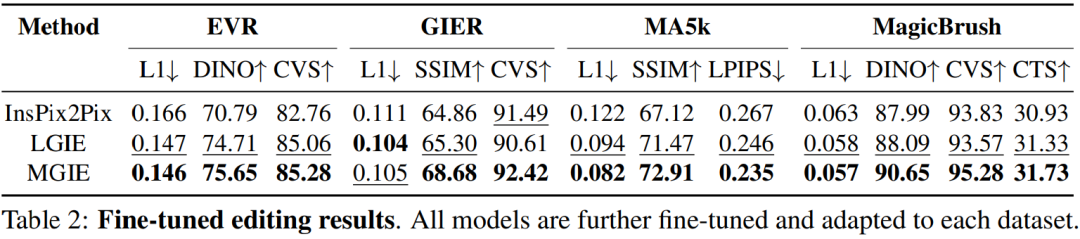
Perdagangan antara α_X dan α_V. Penyuntingan imej mempunyai dua matlamat: memanipulasi sasaran sebagai arahan dan mengekalkan baki imej input. Rajah 3 menunjukkan keluk tukar ganti antara arahan (α_X) dan ketekalan input (α_V). Kajian ini menetapkan α_X pada 7.5 dan α_V berbeza dalam julat [1.0, 2.2]. Semakin besar α_V, semakin serupa hasil pengeditan dengan input, tetapi semakin kurang konsisten dengan arahan. Paksi-X mengira persamaan arah CLIP, iaitu, sejauh mana hasil pengeditan adalah konsisten dengan arahan paksi-Y ialah persamaan ciri antara pengekod visual CLIP dan imej input. Dengan arahan ungkapan khusus, percubaan mengatasi InsPix2Pix dalam semua tetapan. Di samping itu, MGIE boleh belajar melalui bimbingan visual yang jelas, membolehkan peningkatan keseluruhan. Ini menyokong penambahbaikan yang mantap sama ada memerlukan input yang lebih besar atau perkaitan pengeditan.
Penyelidikan ablasi
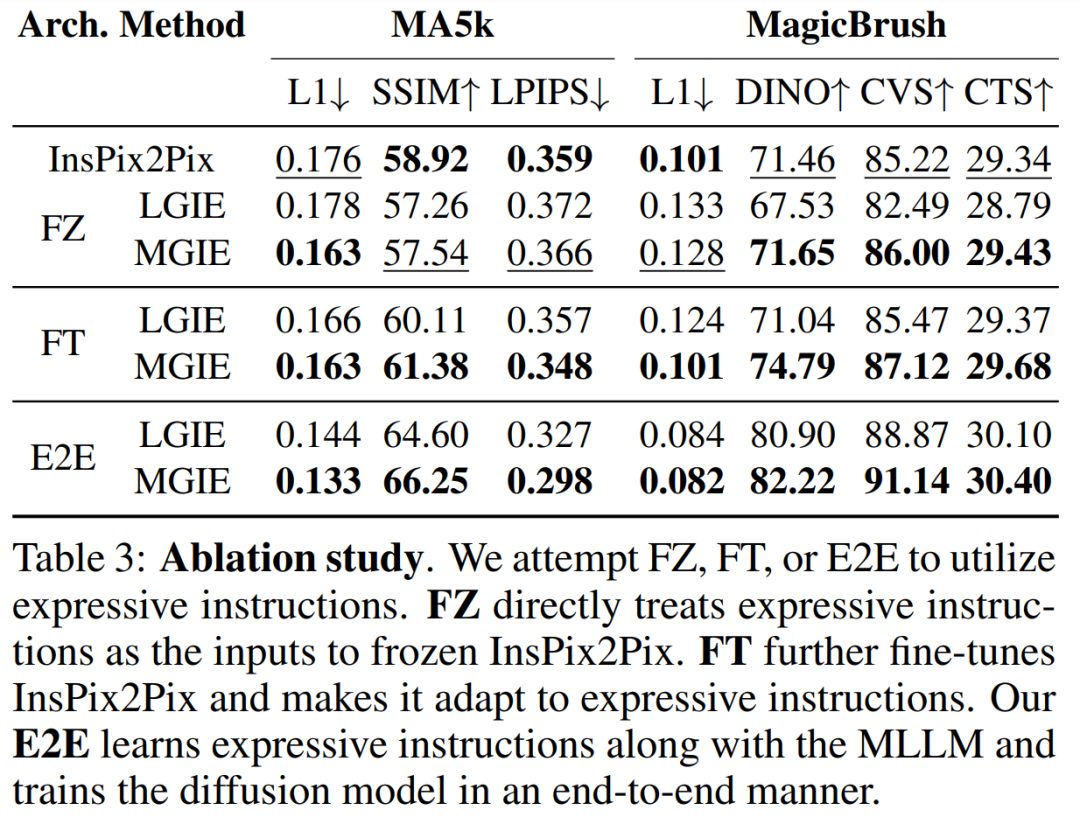
Selain itu, penyelidik juga menjalankan eksperimen ablasi untuk mempertimbangkan prestasi seni bina yang berbeza FZ, FT dan E2E dalam menyatakan arahan. Keputusan menunjukkan bahawa MGIE secara konsisten melebihi LGIE dalam FZ, FT, dan E2E. Ini menunjukkan bahawa arahan ekspresif dengan persepsi visual kritikal mempunyai kelebihan yang konsisten merentas semua tetapan ablasi.
Mengapa MLLM bootstrap berguna? Rajah 5 menunjukkan nilai CLIP-Score antara input atau imej sasaran kebenaran tanah dan arahan ekspresi. Skor CLIP-S yang lebih tinggi untuk imej input menunjukkan bahawa arahan adalah berkaitan dengan sumber pengeditan, manakala penjajaran yang lebih baik dengan imej sasaran memberikan panduan pengeditan yang jelas dan relevan. Seperti yang ditunjukkan, MGIE lebih konsisten dengan input/matlamat, yang menerangkan sebab arahan ekspresifnya membantu. Dengan naratif yang jelas tentang hasil yang dijangkakan, MGIE boleh mencapai peningkatan terbaik dalam penyuntingan imej.

Penilaian manusia. Selain penunjuk automatik, penyelidik juga melakukan penilaian manual. Rajah 6 menunjukkan kualiti arahan ungkapan yang dijana, dan Rajah 7 membandingkan hasil pengeditan imej InsPix2Pix, LGIE dan MGIE dari segi arahan mengikut, perkaitan kebenaran asas dan kualiti keseluruhan.
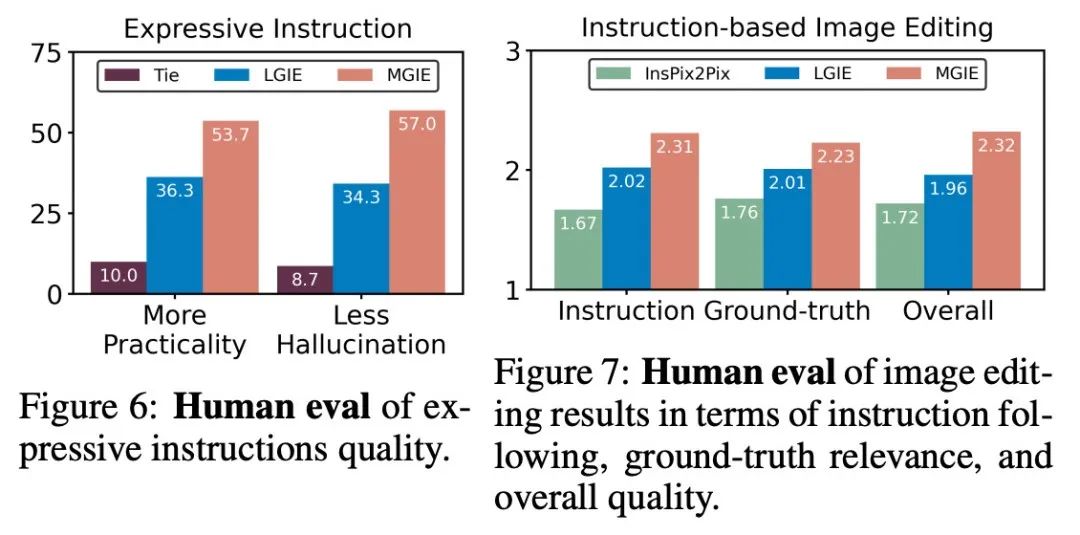
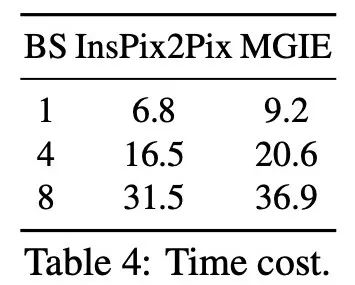
Kecekapan inferens. Walaupun MGIE bergantung pada MLLM untuk memacu penyuntingan imej, ia hanya memperkenalkan arahan ekspresi ringkas (kurang daripada 32 token), jadi kecekapan adalah setanding dengan InsPix2Pix. Jadual 4 menyenaraikan kos masa inferens pada GPU NVIDIA A100. Untuk satu input, MGIE boleh menyelesaikan tugas penyuntingan dalam 10 saat. Dengan lebih banyak keselarian data, masa yang diperlukan adalah serupa (37 saat dengan saiz kelompok 8). Keseluruhan proses boleh diselesaikan dengan hanya satu GPU (40GB).
Perbandingan kualitatif. Rajah 8 menunjukkan perbandingan visual bagi semua set data yang digunakan, dan Rajah 9 membandingkan lagi arahan ungkapan untuk LGIE atau MGIE.


Di laman utama projek, penyelidik juga menyediakan lebih banyak demo (https://mllm-ie.github.io/). Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci jarang! Alat penyunting imej sumber terbuka Apple MGIE, adakah ia akan tersedia pada iPhone?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- baidunetdisk是什么文件夹
- Penyelidik meta membuat percubaan baharu pada AI: mengajar robot untuk menavigasi secara fizikal tanpa peta atau latihan
- Kembali ke masa depan! Menggunakan diari zaman kanak-kanak untuk melatih AI, pengaturcara ini menggunakan GPT-3 untuk mencapai dialog dengan 'diri masa lalu'nya
- Penjelasan terperinci tentang model pra-latihan pembelajaran mendalam dalam Python
- Apakah perbezaan antara iPhone versi AS dan versi Cina?