
Rumah >Peranti teknologi >AI >Belajar dan berkembang daripada kritikan seperti manusia, 1317 komen meningkatkan kadar kemenangan LLaMA2 sebanyak 30 kali ganda
Belajar dan berkembang daripada kritikan seperti manusia, 1317 komen meningkatkan kadar kemenangan LLaMA2 sebanyak 30 kali ganda

- PHPzke hadapan
- 2024-02-04 09:20:38786semak imbas
Kaedah penjajaran model besar sedia ada termasuk penalaan halus terselia (SFT) berasaskan contoh dan maklum balas skor pembelajaran pengukuhan berasaskan (RLHF). Walau bagaimanapun, skor hanya boleh mencerminkan kualiti tindak balas semasa dan tidak dapat menunjukkan dengan jelas kelemahan model. Sebaliknya, kita manusia biasanya belajar dan menyesuaikan corak tingkah laku kita daripada maklum balas lisan. Sama seperti ulasan ulasan bukan sekadar skor, tetapi juga termasuk banyak sebab untuk penerimaan atau penolakan.
Jadi, bolehkah model bahasa besar menggunakan maklum balas bahasa untuk memperbaiki diri seperti manusia?
Para penyelidik dari Chinese University of Hong Kong dan Tencent AI Lab baru-baru ini mencadangkan satu penyelidikan inovatif yang dipanggil Contrastive Unlikelihood Learning (CUT). Penyelidikan menggunakan maklum balas bahasa untuk menyesuaikan model bahasa supaya mereka boleh belajar dan menambah baik daripada kritikan yang berbeza, sama seperti manusia. Penyelidikan ini bertujuan untuk meningkatkan kualiti dan ketepatan model bahasa untuk menjadikannya lebih konsisten dengan cara manusia berfikir. Dengan membandingkan latihan tidak berkemungkinan, penyelidik berharap untuk membolehkan model bahasa memahami dan menyesuaikan diri dengan situasi penggunaan bahasa yang pelbagai, dengan itu meningkatkan prestasinya dalam tugas pemprosesan bahasa semula jadi. Penyelidikan inovatif ini menjanjikan kaedah yang mudah dan berkesan untuk model bahasa
CUT ialah kaedah yang mudah dan berkesan. Dengan menggunakan hanya 1317 keping data maklum balas bahasa, CUT dapat meningkatkan dengan ketara kadar kemenangan LLaMA2-13b pada AlpacaEval, melonjak daripada 1.87% kepada 62.56%, dan berjaya mengalahkan 175B DaVinci003. Apa yang menarik ialah CUT juga boleh melaksanakan kitaran berulang penerokaan, kritikan dan penambahbaikan seperti pembelajaran pengukuhan dan rangka kerja maklum balas pengukuhan pembelajaran pengukuhan (RLHF) yang lain. Dalam proses ini, peringkat kritikan boleh diselesaikan oleh model penilaian automatik untuk mencapai penilaian kendiri dan penambahbaikan keseluruhan sistem.
Pengarang menjalankan empat pusingan lelaran pada LLaMA2-chat-13b, secara beransur-ansur meningkatkan prestasi model pada AlpacaEval daripada 81.09% kepada 91.36%. Berbanding dengan teknologi penjajaran berdasarkan maklum balas skor (DPO), CUT berprestasi lebih baik di bawah saiz data yang sama. Hasilnya mendedahkan bahawa maklum balas bahasa mempunyai potensi besar untuk pembangunan dalam bidang penjajaran, membuka kemungkinan baharu untuk penyelidikan penjajaran masa hadapan. Penemuan ini mempunyai implikasi penting untuk meningkatkan ketepatan dan kecekapan teknik penjajaran dan menyediakan panduan untuk mencapai tugas pemprosesan bahasa semula jadi yang lebih baik.

- Tajuk kertas: Sebab Menolak? Pautan Github: https://github.com/wwxu21/CUT
- Penjajaran model besar
- Berdasarkan kerja sedia ada, penyelidik telah merumuskan dua cara biasa untuk menjajarkan
Belajar daripada Demonstrasi: Berdasarkan pasangan arahan-balas sedia dibuat, gunakan kaedah latihan diselia untuk menjajarkan model besar.
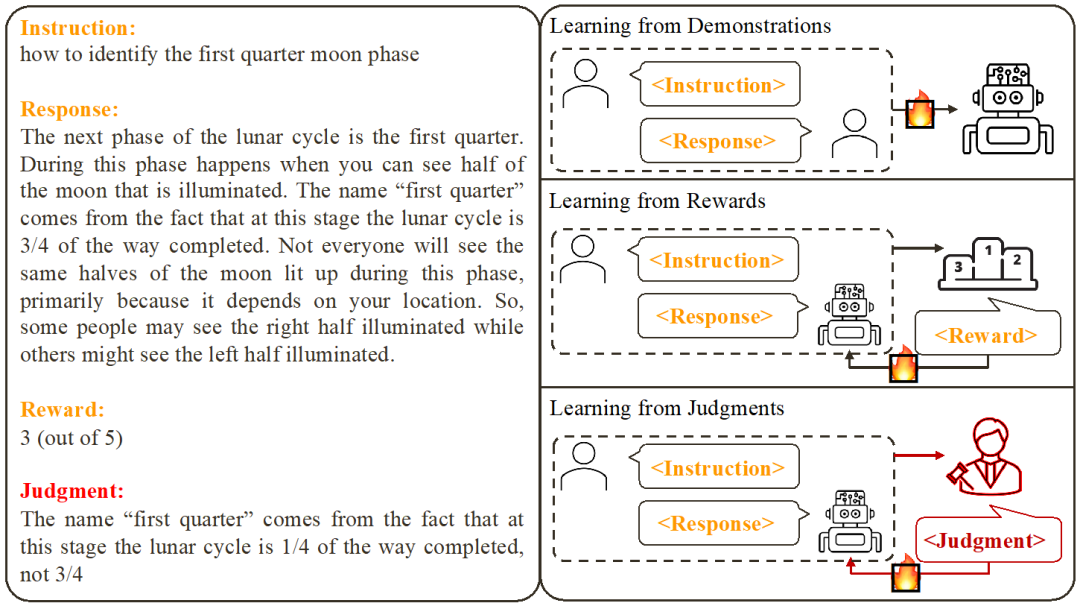 Kelebihan: latihan yang stabil;
Kelebihan: latihan yang stabil;
Kelemahan: Mengumpul data contoh yang berkualiti tinggi dan pelbagai tidak boleh belajar daripada respons ralat selalunya tidak berkaitan dengan model.
2 Belajar daripada Ganjaran: Skor pada pasangan arahan-balas dan gunakan pembelajaran pengukuhan untuk melatih model untuk memaksimumkan skor balasannya.
- Kebaikan: Boleh menggunakan kedua-dua respons yang betul dan isyarat maklum balas yang berkaitan dengan model.
- Kelemahan: isyarat maklum balas adalah jarang;
Kajian ini tertumpu kepada pembelajaran daripada Maklum balas bahasa (Belajar daripada Penghakiman): memberi arahan - membalas untuk menulis komen, berdasarkan maklum balas bahasa untuk memperbaiki kelemahan model, mengekalkan kelebihan model, dan seterusnya meningkatkan prestasi model.
- Dapat dilihat bahawa maklum balas bahasa mewarisi kelebihan maklum balas skor. Berbanding dengan maklum balas skor, maklum balas lisan adalah lebih bermaklumat: daripada membiarkan model meneka perkara yang dilakukan dengan betul dan perkara yang salah, maklum balas lisan boleh secara langsung menunjukkan kekurangan terperinci dan arahan untuk penambahbaikan. Malangnya, bagaimanapun, penyelidik mendapati bahawa pada masa ini tiada cara yang berkesan untuk menggunakan maklum balas lisan sepenuhnya. Untuk tujuan ini, penyelidik telah mencadangkan rangka kerja inovatif, CUT, yang direka bentuk untuk memanfaatkan sepenuhnya maklum balas bahasa.
Latihan tanpa kemungkinan kontras
Idea teras CUT ialah belajar daripada kontras. Penyelidik membandingkan tindak balas model besar di bawah keadaan yang berbeza untuk mengetahui bahagian mana yang memuaskan dan harus diselenggara, dan bahagian mana yang cacat dan perlu diubah suai. Berdasarkan ini, penyelidik menggunakan anggaran kemungkinan maksimum (MLE) untuk melatih bahagian yang memuaskan, dan menggunakan latihan tidak mungkin (UT) untuk mengubah suai kelemahan dalam balasan.

1. , respons perlu mematuhi arahan dengan setia dan konsisten dengan jangkaan dan nilai manusia.
b): Senario ini memperkenalkan maklum balas lisan sebagai syarat tambahan. Dalam senario ini, respons mesti memenuhi kedua-dua arahan dan maklum balas lisan. Contohnya, apabila menerima maklum balas negatif, model besar perlu membuat kesilapan berdasarkan isu yang dinyatakan dalam maklum balas yang sepadan.
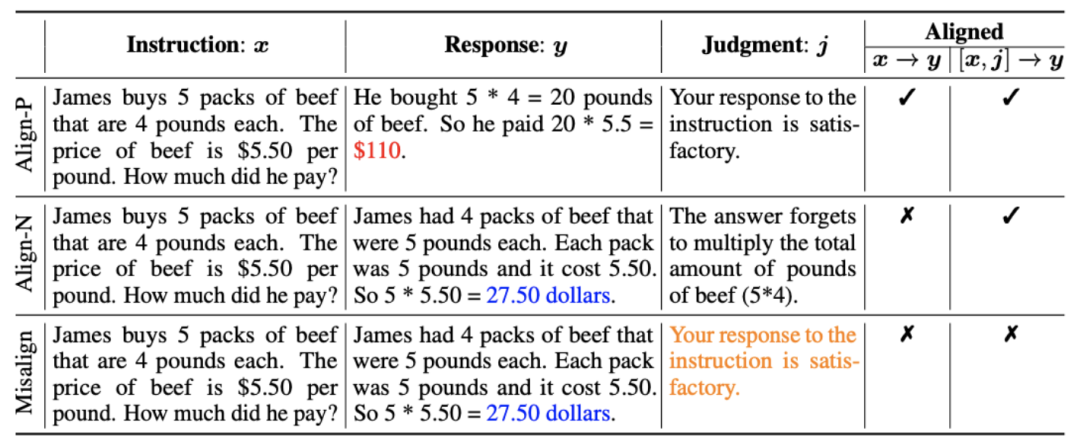
2.Data penjajaran: Seperti yang ditunjukkan dalam rajah di atas, berdasarkan dua senario penjajaran di atas, penyelidik membina tiga jenis data penjajaran:
balasan, oleh itu maklum balas positif. Jelas sekali, Align-P memenuhi penjajaran dalam kedua-dua senarioa) Align-P: Model besar yang dihasilkan Ia adalah luar biasa Puas hati dan .
b) Align-N: Model besar menghasilkan balasan yang cacat (biru tebal) dan oleh itu menerima maklum balas negatif. Untuk Align-N, penjajaran tidak berpuas hati dalam. Tetapi selepas mempertimbangkan maklum balas negatif ini, Align-N masih sejajar dalam senario .
c) Misalign: Maklum balas negatif sebenar dalam Align-N digantikan dengan maklum balas positif palsu. Jelas sekali, Misalign tidak memenuhi penjajaran dalam kedua-dua senariodan
3.. Belajar daripada perbandingan:
a) Align-N lwn.s.: Perbezaan antara dua penjajaran terutamanya terletak pada tahap Memandangkan keupayaan pembelajaran dalam konteks yang kuat bagi model besar, kekutuban penjajaran daripada Align-N ke Misalign biasanya disertai dengan perubahan ketara dalam kebarangkalian penjanaan perkataan tertentu, terutamanya perkataan yang berkait rapat dengan maklum balas negatif sebenar. Seperti yang ditunjukkan dalam rajah di atas, di bawah keadaan Align-N (saluran kiri), kebarangkalian model besar menghasilkan "a" adalah jauh lebih tinggi daripada Misalign (saluran kanan). Dan tempat di mana kebarangkalian berubah dengan ketara ialah di mana model besar membuat kesilapan.
Untuk belajar daripada perbandingan ini, penyelidik memasukkan data Align-N dan Misalign kepada model besar pada masa yang sama untuk mendapatkan kebarangkalian penjanaan perkataan output di bawah dua syarat
dan masing-masing. Perkataan yang mempunyai kebarangkalian generasi yang jauh lebih tinggi di bawah keadaan berbanding di bawah keadaan ditandakan sebagai perkataan yang tidak sesuai. Secara khusus, penyelidik menggunakan piawaian berikut untuk mengukur definisi perkataan yang tidak sesuai: di mana
ialah hiperparameter yang menimbang ketepatan dan mengingat semula dalam proses pengecaman perkataan yang tidak sesuai. Para penyelidik menggunakan latihan tidak berkemungkinan (UT) pada perkataan yang tidak sesuai yang dikenal pasti ini, sekali gus memaksa model besar untuk meneroka respons yang lebih memuaskan. Untuk perkataan balasan lain, penyelidik masih menggunakan anggaran kemungkinan maksimum (MLE) untuk mengoptimumkan:
di mana
b) ialah hiperparameter yang mengawal perkadaran latihan bukan kemungkinan, balasan ialah bilangan perkataan . Align-P vs. Align-N: Perbezaan antara keduanya terutamanya terletak pada tahap penjajaran di bawah . Pada asasnya, model besar mengawal kualiti balasan output dengan memperkenalkan maklum balas bahasa kekutuban yang berbeza. Oleh itu, perbandingan antara kedua-duanya boleh memberi inspirasi kepada model besar untuk membezakan tindak balas yang memuaskan daripada tindak balas yang rosak. Khususnya, penyelidik belajar daripada set perbandingan ini melalui anggaran kemungkinan maksimum (MLE) kerugian berikut:
di manaialah fungsi penunjuk, mengembalikan 1 jika data memuaskan
penjajaran 0. CUT Matlamat latihan terakhir menggabungkan dua set perbandingan di atas: .
Penilaian eksperimen1. Penjajaran luar talian
Untuk menjimatkan wang, penyelidik mula-mula cuba menggunakan data maklum balas bahasa siap sedia untuk menjajarkan model besar. Eksperimen ini digunakan untuk menunjukkan keupayaan CUT untuk menggunakan maklum balas bahasa.
a) Model universal
Seperti yang ditunjukkan dalam jadual di atas, untuk penjajaran model umum, penyelidik menggunakan data penjajaran 1317 yang disediakan oleh Shepherd untuk membandingkan CUT dengan model hamba sedia ada di bawah keadaan permulaan sejuk (LLaMA2) dan permulaan panas (LLaMA2-sembang). .
Di bawah percubaan permulaan sejuk berdasarkan LLaMA2, CUT mengatasi kaedah penjajaran sedia ada pada platform ujian AlpacaEval dengan ketara, membuktikan sepenuhnya kelebihannya dalam menggunakan maklum balas bahasa. Selain itu, CUT juga telah mencapai peningkatan ketara dalam TruthfulQA berbanding model asas, yang mendedahkan bahawa CUT mempunyai potensi besar dalam mengurangkan masalah halusinasi model besar.
Dalam senario permulaan hangat berdasarkan LLaMA2-chat, kaedah sedia ada berprestasi buruk dalam meningkatkan LLaMA2-chat malah mempunyai kesan negatif. Walau bagaimanapun, CUT boleh meningkatkan lagi prestasi model asas atas dasar ini, sekali lagi mengesahkan potensi besar CUT dalam menggunakan maklum balas bahasa.
b) Model pakar
Para penyelidik juga menguji kesan penjajaran CUT pada tugas pakar tertentu (ringkasan teks). Seperti yang ditunjukkan dalam jadual di atas, CUT juga mencapai peningkatan yang ketara berbanding kaedah penjajaran sedia ada pada tugas pakar.
2. Penjajaran Dalam Talian
Penyelidikan mengenai penjajaran luar talian telah berjaya menunjukkan prestasi penjajaran berkuasa CUT. Kini, penyelidik meneroka lebih lanjut senario penjajaran dalam talian yang lebih dekat dengan aplikasi praktikal. Dalam senario ini, penyelidik secara berulang-ulang mencatatkan maklum balas model besar sasaran dengan maklum balas bahasa supaya model sasaran boleh diselaraskan dengan lebih tepat berdasarkan maklum balas bahasa yang berkaitan dengannya. Proses khusus adalah seperti berikut:
-
Langkah 1: Kumpul arahan , dan dapatkan respons daripada model besar sasaran.
-
Langkah 2: Sebagai tindak balas kepada pasangan arahan-balas di atas, tandakan maklum balas bahasa .
-
Langkah 3: Gunakan CUT untuk memperhalusi model besar sasaran berdasarkan data triplet yang dikumpul.
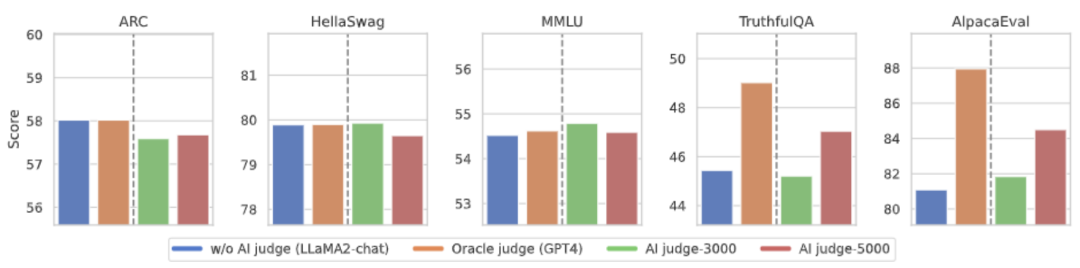
Seperti yang ditunjukkan dalam rajah di atas, selepas empat pusingan lelaran penjajaran dalam talian, CUT masih boleh mencapai hasil yang mengagumkan dengan hanya 4000 data latihan dan saiz model 13B yang kecil. Pencapaian ini seterusnya menunjukkan prestasi cemerlang dan potensi besar CUT. 3. Model Komen AI Seperti yang ditunjukkan dalam rajah di atas, penyelidik menggunakan 5,000 keping (AI Judge-5000) dan 3,000 keping (AI Judge-3000) data maklum balas bahasa untuk melatih dua model semakan. Kedua-dua model semakan telah mencapai hasil yang luar biasa dalam mengoptimumkan model berskala besar sasaran, terutamanya kesan AI Judge-5000.
Ini membuktikan kebolehlaksanaan menggunakan model semakan AI untuk menjajarkan model besar sasaran, dan juga menyerlahkan kepentingan kualiti model semakan dalam keseluruhan proses penjajaran. Set percubaan ini juga memberikan sokongan yang kuat untuk mengurangkan kos anotasi pada masa hadapan.
4. Maklum balas bahasa lwn. Maklum balas skor
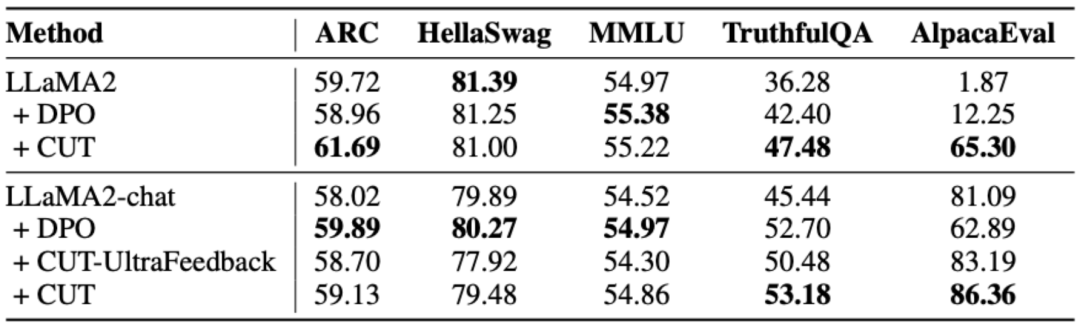
Untuk meneroka secara mendalam potensi besar maklum balas bahasa dalam penjajaran model besar, penyelidik membandingkan CUT berasaskan maklum balas bahasa dengan kaedah berasaskan maklum balas skor (DPO). Untuk memastikan perbandingan yang saksama, penyelidik memilih 4,000 set pasangan arahan-tindak balas yang sama sebagai sampel percubaan, membolehkan CUT dan DPO belajar daripada maklum balas skor dan maklum balas bahasa yang sepadan dengan data ini masing-masing.
Seperti yang ditunjukkan dalam jadual di atas, dalam percubaan permulaan sejuk (LLaMA2), CUT menunjukkan prestasi yang lebih baik daripada DPO. Dalam percubaan permulaan hangat (LLaMA2-chat), CUT boleh mencapai hasil yang setanding dengan DPO pada tugasan seperti ARC, HellaSwag, MMLU dan TruthfulQA, dan jauh mendahului DPO pada tugas AlpacaEval. Eksperimen ini mengesahkan potensi dan kelebihan maklum balas linguistik yang lebih besar berbanding maklum balas pecahan semasa penjajaran model besar.
Ringkasan dan Cabaran
Dalam kerja ini, penyelidik secara sistematik meneroka situasi semasa maklum balas bahasa dalam penjajaran model besar dan secara inovatif mencadangkan rangka kerja penjajaran CUT berdasarkan maklum balas bahasa, mendedahkan Maklum balas bahasa mempunyai potensi dan kelebihan yang besar dalam bidang penjajaran model besar. Selain itu, terdapat beberapa hala tuju dan cabaran baharu dalam penyelidikan maklum balas bahasa, seperti:
1 Kualiti model ulasan: Walaupun penyelidik telah berjaya mengesahkan kebolehlaksanaan melatih model ulasan, dalam. pemerhatian Apabila model dikeluarkan, mereka masih mendapati bahawa model kajian sering memberikan penilaian yang tidak tepat. Oleh itu, meningkatkan kualiti model semakan adalah sangat penting untuk penggunaan skala besar maklum balas bahasa untuk penjajaran pada masa hadapan.
2. Pengenalan pengetahuan baharu: Apabila maklum balas bahasa melibatkan pengetahuan yang kekurangan model besar, walaupun model besar dapat mengenal pasti ralat dengan tepat, tiada arah yang jelas untuk pengubahsuaian. Oleh itu, adalah sangat penting untuk menambah pengetahuan bahawa model besar tidak mempunyai semasa menjajarkan.
3. Penjajaran pelbagai modal : Kejayaan model bahasa telah menggalakkan penyelidikan model besar berbilang modal, seperti gabungan bahasa, pertuturan, imej dan video. Dalam senario pelbagai modal ini, mengkaji maklum balas bahasa dan maklum balas modaliti yang sepadan telah membawa kepada definisi dan cabaran baharu.
-
Langkah 1: Kumpul arahan

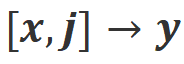 a) Align-P: Model besar yang dihasilkan Ia adalah luar biasa Puas hati
a) Align-P: Model besar yang dihasilkan Ia adalah luar biasa Puas hati 
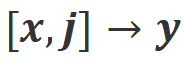
 .
. 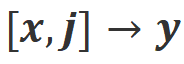

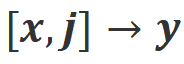
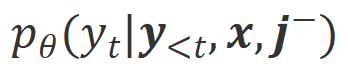
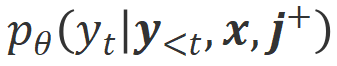

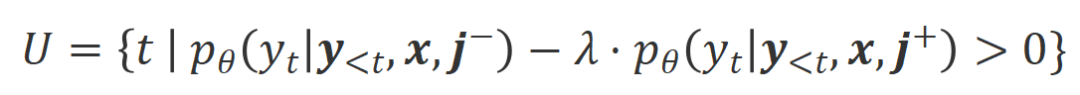
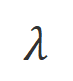
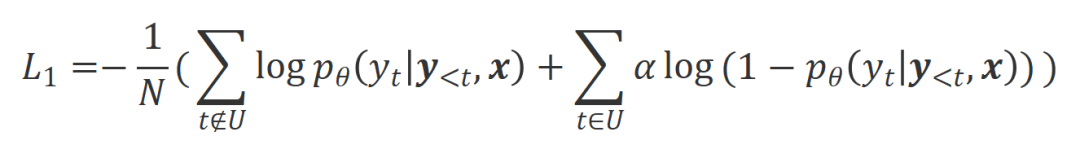
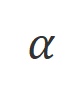

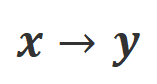
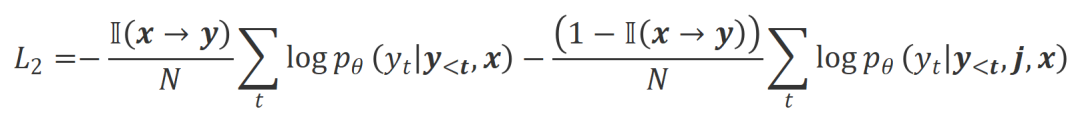
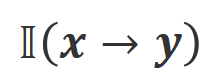
 CUT Matlamat latihan terakhir menggabungkan dua set perbandingan di atas:
CUT Matlamat latihan terakhir menggabungkan dua set perbandingan di atas: 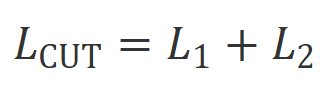 Penilaian eksperimen
Penilaian eksperimen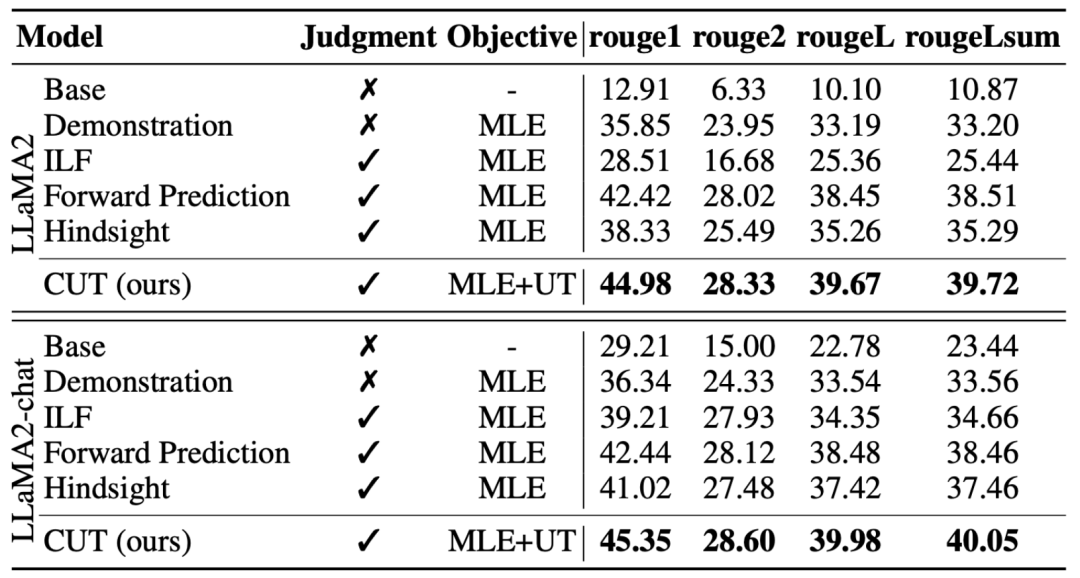


Atas ialah kandungan terperinci Belajar dan berkembang daripada kritikan seperti manusia, 1317 komen meningkatkan kadar kemenangan LLaMA2 sebanyak 30 kali ganda. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!